深入剖析(JDK)ArrayQueue源码
深入剖析(JDK)ArrayQueue源码
前言
在本篇文章当中主要给大家介绍一个比较简单的JDK为我们提供的容器ArrayQueue,这个容器主要是用数组实现的一个单向队列,整体的结构相对其他容器来说就比较简单了。
ArrayQueue内部实现
在谈ArrayQueue的内部实现之前我们先来看一个ArrayQueue的使用例子:
public void testQueue() {
ArrayQueue<Integer> queue = new ArrayQueue<>(10);
queue.add(1);
queue.add(2);
queue.add(3);
queue.add(4);
System.out.println(queue);
queue.remove(0); // 这个参数只能为0 表示删除队列当中第一个元素,也就是队头元素
System.out.println(queue);
queue.remove(0);
System.out.println(queue);
}
// 输出结果
[1, 2, 3, 4]
[2, 3, 4]
[3, 4]
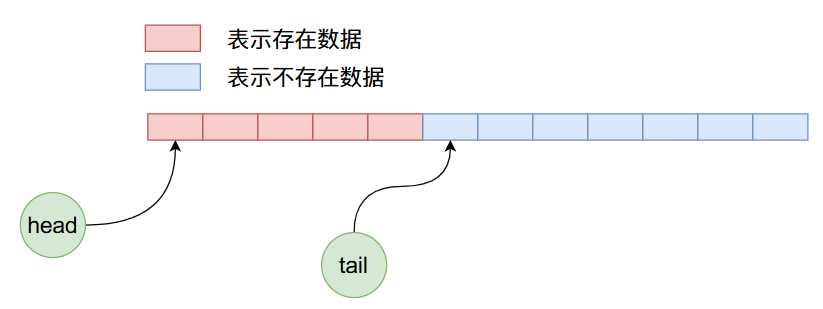
首先ArrayQueue内部是由循环数组实现的,可能保证增加和删除数据的时间复杂度都是\(O(1)\),不像ArrayList删除数据的时间复杂度为\(O(n)\)。在ArrayQueue内部有两个整型数据head和tail,这两个的作用主要是指向队列的头部和尾部,它的初始状态在内存当中的布局如下图所示:

因为是初始状态head和tail的值都等于0,指向数组当中第一个数据。现在我们向ArrayQueue内部加入5个数据,那么他的内存布局将如下图所示:
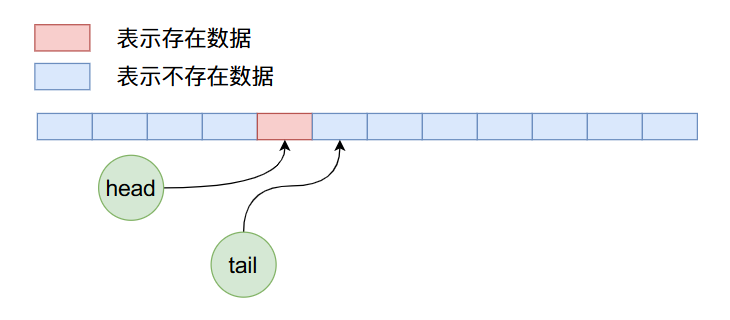
现在我们删除4个数据,那么上图经过4次删除操作之后,ArrayQueue内部数据布局如下:
在上面的状态下,我们继续加入8个数据,那么布局情况如下:
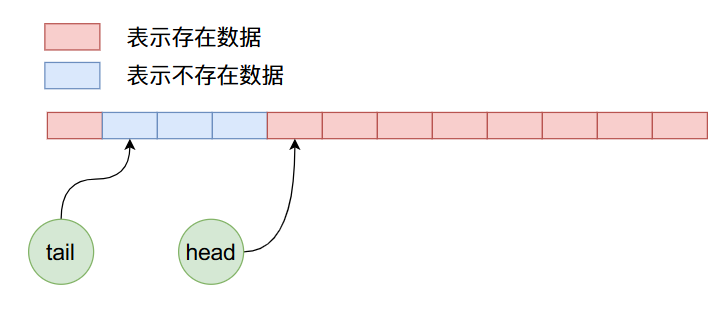
我们知道上图在加入数据的时候不仅将数组后半部分的空间使用完了,而且可以继续使用前半部分没有使用过的空间,也就是说在ArrayQueue内部实现了一个循环使用的过程。
ArrayQueue源码剖析
构造函数
public ArrayQueue(int capacity) {
this.capacity = capacity + 1;
this.queue = newArray(capacity + 1);
this.head = 0;
this.tail = 0;
}
@SuppressWarnings("unchecked")
private T[] newArray(int size) {
return (T[]) new Object[size];
}
上面的构造函数的代码比较容易理解,主要就是根据用户输入的数组空间长度去申请数组,不过他具体在申请数组的时候会多申请一个空间。
add函数
public boolean add(T o) {
queue[tail] = o;
// 循环使用数组
int newtail = (tail + 1) % capacity;
if (newtail == head)
throw new IndexOutOfBoundsException("Queue full");
tail = newtail;
return true; // we did add something
}
上面的代码也相对比较容易看懂,在上文当中我们已经提到了ArrayQueue可以循环将数据加入到数组当中去,这一点在上面的代码当中也有所体现。
remove函数
public T remove(int i) {
if (i != 0)
throw new IllegalArgumentException("Can only remove head of queue");
if (head == tail)
throw new IndexOutOfBoundsException("Queue empty");
T removed = queue[head];
queue[head] = null;
head = (head + 1) % capacity;
return removed;
}
从上面的代码当中可以看出,在remove函数当中我们必须传递参数0,否则会抛出异常。而在这个函数当中我们只会删除当前head下标所在位置的数据,然后将head的值进行循环加1操作。
get函数
public T get(int i) {
int size = size();
if (i < 0 || i >= size) {
final String msg = "Index " + i + ", queue size " + size;
throw new IndexOutOfBoundsException(msg);
}
int index = (head + i) % capacity;
return queue[index];
}
get函数的参数表示得到第i个数据,这个第i个数据并不是数组位置的第i个数据,而是距离head位置为i的位置的数据,了解这一点,上面的代码是很容易理解的。
resize函数
public void resize(int newcapacity) {
int size = size();
if (newcapacity < size)
throw new IndexOutOfBoundsException("Resizing would lose data");
newcapacity++;
if (newcapacity == this.capacity)
return;
T[] newqueue = newArray(newcapacity);
for (int i = 0; i < size; i++)
newqueue[i] = get(i);
this.capacity = newcapacity;
this.queue = newqueue;
this.head = 0;
this.tail = size;
}
在resize函数当中首先申请新长度的数组空间,然后将原数组的数据一个一个的拷贝到新的数组当中,注意在这个拷贝的过程当中,重新更新了head与tail,而且并不是简单的数组拷贝,因为在之前的操作当中head可能已经不是了0,因此新的拷贝需要我们一个一个的从就数组拿出来,然后放到新数组当中。下图可以很直观的看出这个过程:
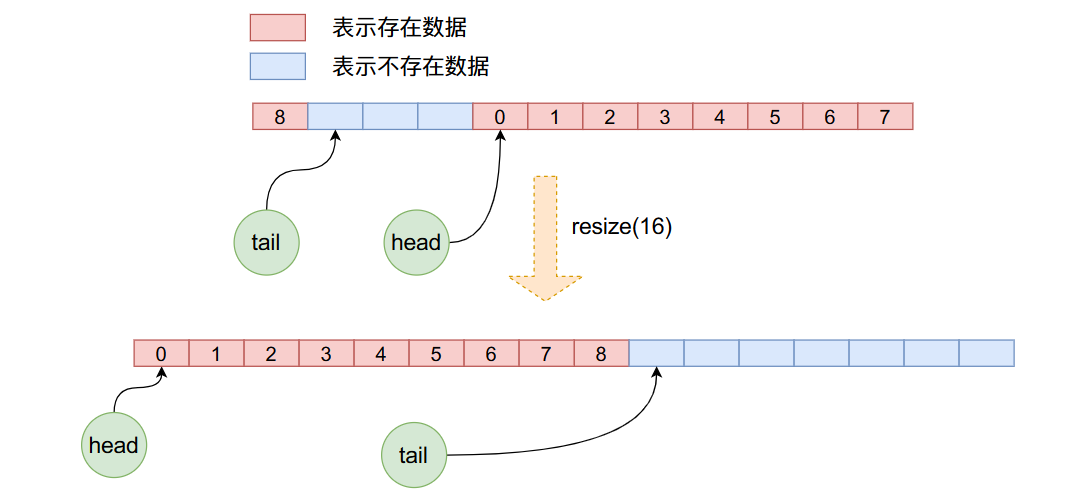
总结
在本篇文章当中主要给大家介绍了ArrayQueue的内部实现过程和原理,并且看了ArrayQueue的源代码,有图的辅助整个阅读的过程应该是比较清晰的,ArrayQueue也是一个比较简单的容器,JDK对他的实现也比较简单。
以上就是本文所有的内容了,希望大家有所收获,我是LeHung,我们下期再见!!!(记得点赞收藏哦!)
更多精彩内容合集可访问项目:https://github.com/Chang-LeHung/CSCore
关注公众号:一无是处的研究僧,了解更多计算机(Java、Python、计算机系统基础、算法与数据结构)知识。
深入剖析(JDK)ArrayQueue源码的更多相关文章
- 转:【Java集合源码剖析】Hashtable源码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/36191279 Hashtable简介 Hashtable同样是基于哈希表实现的,同样每个元 ...
- 转:【Java集合源码剖析】ArrayList源码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/35568011 本篇博文参加了CSDN博文大赛,如果您觉得这篇博文不错,希望您能帮我投一 ...
- 【Java集合源码剖析】Hashtable源码剖析
转载出处:http://blog.csdn.net/ns_code/article/details/36191279 Hashtable简介 Hashtable同样是基于哈希表实现的,同样每个元素是一 ...
- JDK Collection 源码分析(2)—— List
JDK List源码分析 List接口定义了有序集合(序列).在Collection的基础上,增加了可以通过下标索引访问,以及线性查找等功能. 整体类结构 1.AbstractList 该类作为L ...
- 转:【Java集合源码剖析】HashMap源码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/36034955 您好,我正在参加CSDN博文大赛,如果您喜欢我的文章,希望您能帮我投一票 ...
- 转:【Java集合源码剖析】Vector源码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/35793865 Vector简介 Vector也是基于数组实现的,是一个动态数组,其容量 ...
- 转:【Java集合源码剖析】LinkedList源码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/35787253 您好,我正在参加CSDN博文大赛,如果您喜欢我的文章,希望您能帮我投一票 ...
- JDK AtomicInteger 源码分析
@(JDK)[AtomicInteger] JDK AtomicInteger 源码分析 Unsafe 实例化 Unsafe在创建实例的时候,不能仅仅通过new Unsafe()或者Unsafe.ge ...
- Eclipse导入jdk的源码
eclipse导入JDK源码 前言:这件事情的重要性不言而喻,对于学习和观摩优秀的代码非常的有用,我喜欢想看什么代码都能 Ctrl+鼠标一点 就能够看到,不过这个不常操作,在这里小记一笔,以备后用.( ...
随机推荐
- java自学中出现的问题或者?
自学java之路,是如此的坎坷.经过一段时间的自学,我得出一些总结! 总结如下: 1. 在学习编程之路(Java)的,最基本的还是学习之路,对编程前程深感迷茫2. 网络中有许许多多的编程 ...
- 自己在ubuntu16.04 上用的软件和配置
软件: 1.WPS2019: 这个不用多说了,真的是比之前的wps好太多了. 2.Chrom的画图插件: http://Draw.io,非常强,Draw.io 是一款在线图表编辑工具, 可以用来编辑工 ...
- C# Thread.Sleep 不精准的问题以及解决方案
1.问题 最近在写一个熔断的 SDK,其中一种策略是根据慢请求来进行熔断. 我们在测试的时候,在对应 API 里面采用了 Thread.Sleep(ms) 来模拟慢请求. 设置的慢请求阈值是 RT 1 ...
- 并查集——以nuist OJ P1648炼丹术为例
并查集 定义:并查集是一种树形的数据结构,用于处理一些不相交集合的合并及查询问题 主要构成: 并查集主要由一个整型数组pre[]和两个函数find().join()构成. 数组pre[]记录了每个点的 ...
- DEDECMS登录后台,无法连接数据库的原因
在CMS的网页模块中,当迁移网站出现后台无法登录的时候 最可能的情况有下列几种: 1. 数据库服务器宕机.如果是云上的数据库时,需要联系客服进行解决.是有自己的搭建的数据库,需要查看服务是否正常启动 ...
- 好客租房48-组件的props(基本使用)
组件是封闭的 要接受外部数据应该通过props来实现 props的作用:接受传递给组件的数据 传递数据:给组件标签添加属性 接收数据:函数组件通过参数props接收数据 类组件通过this.props ...
- 好客租房32-事件绑定this指向(class实例方法)
class实例方法 利用箭头函数的class实例方法 //导入react import React from 'react' import ReactDOM from 'react-dom' // ...
- unity---克隆/贴图/平移/旋转
克隆 GameObject clone =Instantiate(gameObject,new Vector3(10,10,10),Quaternion.identity); Destroy(clon ...
- 前端向后端传递formData类型的二进制文件
// 获取到的文件file类型转换为formData类型 let formData = new FormData(); formData.append("file", file文件 ...
- Go中rune类型浅析
一.字符串简单遍历操作 在很多语言中,字符串都是不可变类型,golang也是. 1.访问字符串字符 如下代码,可以实现访问字符串的单个字符和单个字节 package main import ( &qu ...