spark 执行架构
术语定义
- Application:Spark Application的概念和Hadoop MapReduce中的类似,指的是用户编写的Spark应用程序,包含了一个Driver 功能的代码和分布在集群中多个节点上运行的Executor代码;
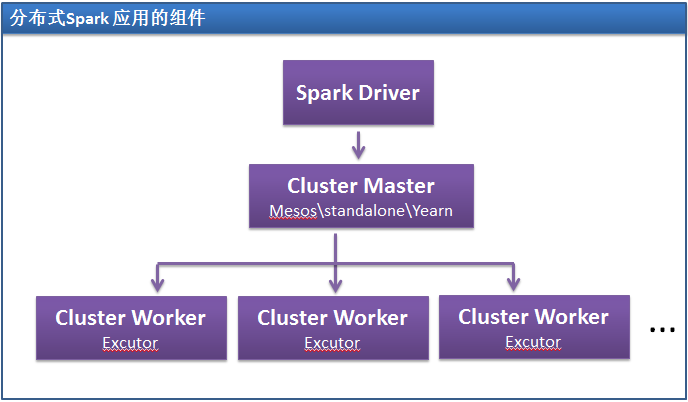
- Driver:Spark中的Driver即运行上述Application的main()函数并且创建SparkContext,其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;当Executor部分运行完毕后,Driver负责将SparkContext关闭。通常用SparkContext代表Drive;
- Executor:Application运行在Worker 节点上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的一批Executor。在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutorBackend,类似于Hadoop MapReduce中的YarnChild。一个CoarseGrainedExecutorBackend进程有且仅有一个executor对象,它负责将Task包装成taskRunner,并从线程池中抽取出一个空闲线程运行Task。每个CoarseGrainedExecutorBackend能并行运行Task的数量就取决于分配给它的CPU的个数了;
- Cluster Manager:指的是在集群上获取资源的外部服务,目前有:
- Ø Standalone:Spark原生的资源管理,由Master负责资源的分配;
- Ø Hadoop Yarn:由YARN中的ResourceManager负责资源的分配;
- Worker:集群中任何可以运行Application代码的节点,类似于YARN中的NodeManager节点。在Standalone模式中指的就是通过Slave文件配置的Worker节点,在Spark on Yarn模式中指的就是NodeManager节点;
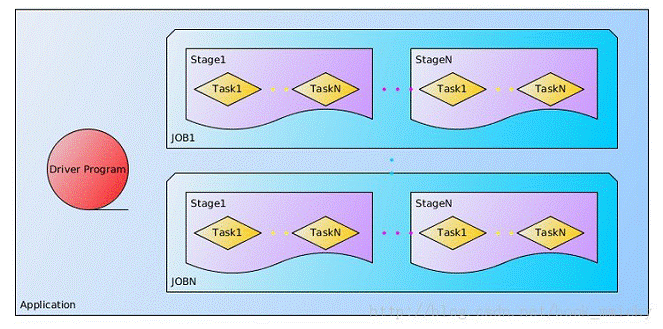
- 作业(Job):包含多个Task组成的并行计算,往往由Spark Action催生,一个JOB包含多个RDD及作用于相应RDD上的各种Operation;
- 阶段(Stage):每个Job会被拆分很多组Task,每组任务被称为Stage,也可称TaskSet,一个作业分为多个阶段;
- 任务(Task): 被送到某个Executor上的工作任务;
1、Spark分布式计算执行模型
RDD为Spark抽象了分布式计算的操作,即将任务进行分布式计算转成RDD的转换和行为上。通过spark-submit提交Driver应用程序给Spark集群,通过同Cluster Manager和Worker Node进行交互,
得到该Driver所需要的Executor资源,然后再由Spark应用程序通过分析RDD DAG依赖关系,以及各个RDD之间partition的依赖关系来生成不同的Stage,再将Stage中的任务,
按照RDD的partition个数生成相同数目的Task提交给Executor来执行,从而实现了Task在不同的Executor中进行分布式计算,最终实现整个Driver应用程序的分布式计算。
Spark执行模型分如下三步:
- 创建应用程序计算RDD DAG (Directed acyclic graph,有向无环图)
- 创建RDD DAG逻辑执行方案,即将整个计算过程对应到Stage上
- 获取到Executor来进行调度并执行各个Stage对应的ShuffleMapResult和ResultTask等任务。必须是执行一个Stage完成之后,才能往下执行接下来的Stage
RDD DAG
RDD DAG描述的是各个RDD之间的依赖关系。
举例从RDD DAG的角度来看如下:
即该RDD DAG主要是包括有MappedRDD->FlatMappedRDD->MappedRDD->ShuffledRDD四个RDD的转换(Transform), 根据Spark实现,RDD的转换操作是不会提交给Spark集群来执行的,
因此,上面的操作必须要由Spark的行为(Action)来触发,因此,在最后调用saveAsTextFile这个行为来将整个WordCount Job提交到Spark集群中来执行。
RDD DAG逻辑执行方案
RDD DAG只是从整体的RDD角度来查看整个Job的执行过程。在RDD DAG逻辑执行方案,需要查看各个RDD中各个Partition的情况,以及各个RDD的Partition的依赖情况来决定如何划分Stage。
在RDD中将依赖划分成了两种类型:
窄依赖(narrow dependencies)和宽依赖(wide dependencies)
窄依赖是指父RDD的每个分区都只被子RDD的一个分区所使用
宽依赖就是指父RDD的分区被多个子RDD的分区所依赖。例如,map就是一种窄依赖,而join则会导致宽依赖(除非父RDD是hash-partitioned)。
若在Job中存在有宽依赖,就划分为不同的Stage。
RDD Task执行
Spark通过分析各个RDD的依赖关系生成了RDD DAG,然后再通过分析各个RDD中的partition之间的依赖关系来将执行过程进行逻辑划分成不同的Stage。
有了这些Stage的依赖关系之后,从最parent stage开始执行,执行完了parent stage的所有的task再执行child stage中的所有的task,直到所有的Stage都执行完成。
RDD的Partition数目决定了执行过程中生成多少个Task,即决定于并行计算的数目,该参数是Spark应用程序中非常重要的参数,Partition设置的越大,并行度越高,
在Executor资源有限的情况下,任务之间调度开销会变大,同时若有Wide Dependencies的时候,Shuffle的代价也比较多。
Spark作者推荐的“比较合理的partition数目”为:
- 100-10000
- 最少要有2倍于申请的CPU核数
- 每个Partition对应的Task最少要运行100ms以上
2、Spark的shuffle实现
spark 执行架构的更多相关文章
- Spark 宏观架构&执行步骤
Spark 使用主从架构,有一个中心协调器和许多分布式worker. 中心协调器被称为driver.Driver 和被称为executor 的大量分布式worker 通信 Driver 运行在它自己的 ...
- Spark入门实战系列--4.Spark运行架构
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1. Spark运行架构 1.1 术语定义 lApplication:Spark Appli ...
- Spark Streaming 架构
图 1 Spark Streaming 架构图 组件介绍: Network Input Tracker : 通 过 接 收 器 接 收 流 数 据, 并 将 流 数 据 映 射 为 输 入DSt ...
- Spark SQL概念学习系列之Spark SQL 架构分析(四)
Spark SQL 与传统 DBMS 的查询优化器 + 执行器的架构较为类似,只不过其执行器是在分布式环境中实现,并采用的 Spark 作为执行引擎. Spark SQL 的查询优化是Catalyst ...
- 【转载】Spark运行架构
1. Spark运行架构 1.1 术语定义 lApplication:Spark Application的概念和Hadoop MapReduce中的类似,指的是用户编写的Spark应用程序,包含了一个 ...
- Spark运行架构
http://blog.csdn.net/pipisorry/article/details/52366288 1. Spark运行架构 1.1 术语定义 lApplication:Spark App ...
- Spark基本架构
Spark基本架构图如下: Client:客户端进程,负责提交作业. Driver:一个Spark作业有一个spark context,一个Spark Context对应一个Driver进程,作业的 ...
- Spark基本架构及原理
Hadoop 和 Spark 的关系 Spark 运算比 Hadoop 的 MapReduce 框架快的原因是因为 Hadoop 在一次 MapReduce 运算之后,会将数据的运算结果从内存写入到磁 ...
- spark 运行架构
spark 运行架构基本由三部分组成,包括SparkContext(驱动程序),ClusterManager(集群资源管理器)和Executor(任务执行过程)组成. 其中SparkContext负责 ...
随机推荐
- MVVM的本质:视图逻辑处理、视图管理、视数中间层
MVVM的核心是将原来Controller中的视图逻辑.视图管理.视数中间层的功能剥离出来,形成单独的模块: 大部分功能与视图相关.少部分与数据相关: 视图逻辑和业务逻辑不通: 解决的问题:UIVie ...
- Pollard_rho 因数分解
Int64以内Rabin-Miller强伪素数测试和Pollard 因数分解的算法实现 选取随机数\(a\) 随机数\(b\),检查\(gcd(a - b, n)\)是否大于1,若大于1则\(a - ...
- 十八、IntelliJ IDEA 常用快捷键 之 Windows 版
IntelliJ IDEA(简称 IDEA),是 Java 语言开发的集成环境,IDEA 在业界被公认为最好的 Java 开发工具之一,尤其在智能代码助手.代码自动提示.重构.J2EE 支持.各类版本 ...
- openmax component类的继承关系
向OpenCORE里继承一个新的codec时,需要用到OpenMAX接口规范对该codec进行封装,即要定义一个用于封装的类(wrapper),实现OpenMAX规定的集中核心方法(omx core ...
- 基于DCT的图片数字水印实验
1. 实验类别 设计型实验:MATLAB设计并实现基于DCT的图像数字水印算法. 2. 实验目的 了解基于DCT的图像数字水印技术,掌握基于DCT系数关系的图像水印算法原理,设计并实现一种基于DCT的 ...
- 关于因为git仓库无法克隆的问题;
有时候会遇见一种情况: 在git clone 时,遇见断开连接或者无法连接git源仓库:连接超时的时候: git clone url(git 仓库源) --depth=n // n 为想要克隆的层 ...
- eclipse 安装 lombok
转载自http://bbs.itmayiedu.com/article/1527769518449 由于项目中有 @Slf4j 注解等,而 eclipse 需要安装 lombok 插件才能正常编译.由 ...
- PHP封装CURL
CURL是一个非常强大的开源库,支持很多协议,包括HTTP.FTP.TELNET等,我们使用它来发送HTTP请求.它给我 们带来的好处是可以通过灵活的选项设置不同的HTTP协议参数,并且支持HTTPS ...
- Win7装在其他盘 (非C盘)办法
Win7装在其他盘 (非C盘)办法 1]将GHO还原到其他盘(非C盘),如H盘 2]用进U盘系统,里的工具,恢复启动H盘 3]将H盘的Boot文件夹,及其他根目录的所有文件复制到C盘根目录,重启即可开 ...
- django基本配置项-5
目录 BASE_DIR 项目路径 DEBUG 模式 ROOT_URLCONF DATABASES 数据库设置 国际化 静态文件 访问静态文件示例 ALLOWED_HOSTS TEMPLATES 模板设 ...