C基础 大文件读取通过标准库
引言 - 问题的构建
C大部分读取文件的时候采用fgetc, 最近在使用过程中发现性能不是很理想.都懂得fgetc每次只能读取一个字符, IO操作太频繁.
所以性能低. 本文希望通过标准库函数fread 函数构建读取缓冲区来优化这个瓶颈.
在正式开始实验总结之前, 传一个VS C/C++ 开发的技巧给大家, 天外飞仙~ .
M$忽略C++太久了,对于C直接放弃, 在其Visual Studio IDE中. 但是吧在Window 还是它的IDE写C 系列语言最爽.
现在很流行一个低端套路是, Window VS 开发, Linux上部署. 而我们的问题就是关于这个, 这种不同平台的开发和部署,
存在一个坑就是编码问题. 而这里就是希望完美的解决这个编码问题.
解决基准是选用UTF-8 带签名的编码, VS , GCC都能编译通过. 那就一言不合上图了, 首先定位VC模板文件
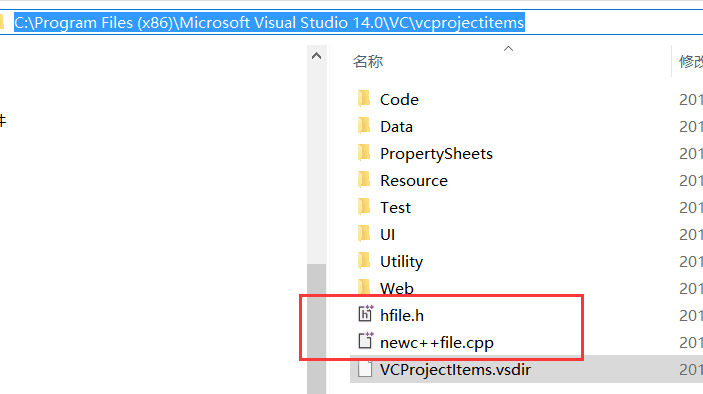
将上面模板文件备份一份, 复制一份, 用VS打开复制的那份
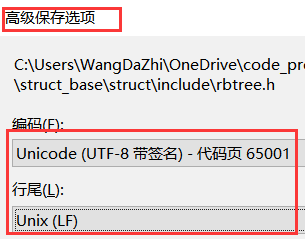
高级选项另存为上面编码格式. 最终保存替换原先的模板文件. 从此以后, 编码问题 perfect! 继续扯一点, 随着写代码时间增长, VS的依赖已经不重要的.
可惜喜欢打游戏, 还是被window 游戏机绑定了. 真的是离开I可以, 请付出代价~ /(ㄒoㄒ)/~~
前言 - 实验验证
这里验证的是fgetc 和 fread读取性能的对比. 在说之前, 先介绍个测试宏
// 简单的time帮助宏
#ifndef TIME_PRINT
#define _STR_TIME_PRINT "The current code block running time:%lf seconds\n"
#define TIME_PRINT(code) \
do {\
clock_t __st, __et;\
__st = clock();\
code\
__et = clock();\
printf(_STR_TIME_PRINT, (0.0 + __et - __st) / CLOCKS_PER_SEC);\
} while()
#endif // !TIME_PRINT
非常还用, 将代码块插入到 code中, 就可以使用了. 那继续了, 第一个测试的主体内容是, 实验一 fread对比fgetc
#include <stdio.h>
#include <time.h>
#include <stdlib.h> #define _STR_DATA "data.txt"
#define _INT_DATA (1024*1024*32) // 测试 fgetc 性能
void test_fgetc(void); // 测试 fread 性能
void test_fread(void); //
// 测试C大文件处理方式
//
int main(int argc, char * argv[]) { // 先构建测试环境
FILE * txt = fopen(_STR_DATA, "r");
if (NULL == txt) {
txt = fopen(_STR_DATA, "w");
if (NULL == txt) {
fprintf(stderr, "main fopen w " _STR_DATA " error!\n");
exit(EXIT_FAILURE);
} // 开始写入数据
for (int i = ; i < _INT_DATA; ++i)
fprintf(txt, "%d", i);
}
fclose(txt); // 开始测试数据, 分批测试
TIME_PRINT({
test_fgetc();
}); TIME_PRINT({
test_fread();
}); return ;
}
其中两个测试函数如下.
//
// 测试 fgetc 性能
//
void
test_fgetc(void) {
FILE * txt = fopen(_STR_DATA, "r");
if (NULL == txt) {
fprintf(stderr, "test_fgetc fopen w " _STR_DATA " error!\n");
return;
} size_t cnt = ;
int c; while ((c = fgetc(txt)) != EOF)
++cnt; fclose(txt); printf("test_fgetc cnt = %d\n", cnt);
} //
// 测试 fread 性能
//
void test_fread(void) {
FILE * txt = fopen(_STR_DATA, "r");
if (NULL == txt) {
fprintf(stderr, "test_fread fopen w " _STR_DATA " error!\n");
return;
} size_t cnt = ;
char buf[BUFSIZ]; for (;;) {
int rn = fread(buf, sizeof(char), BUFSIZ, txt);
// 存在信号中断情况, 不考虑
cnt += rn;
if (rn < BUFSIZ)
break;
} fclose(txt); printf("test_fread cnt = %d\n", cnt);
}
测试主要思路是.
a. 构建差不多是200-300Mb的数据文件
b. 通过fgetc 完毕, 输出时间
c. 通过fread 完毕, 输出时间
测试结果如下
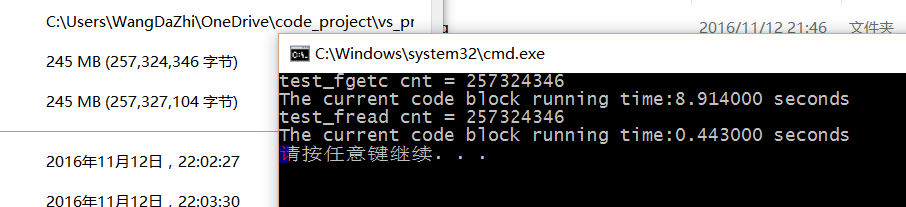
我们发现, fread构建缓冲区有质的飞跃.
附录测试完整内容 file_test.c
#include <stdio.h>
#include <time.h>
#include <stdlib.h> #define _STR_DATA "data.txt"
#define _INT_DATA (1024*1024*32) // 简单的time帮助宏
#ifndef TIME_PRINT
#define _STR_TIME_PRINT "The current code block running time:%lf seconds\n"
#define TIME_PRINT(code) \
do {\
clock_t __st, __et;\
__st = clock();\
code\
__et = clock();\
printf(_STR_TIME_PRINT, (0.0 + __et - __st) / CLOCKS_PER_SEC);\
} while()
#endif // !TIME_PRINT // 测试 fgetc 性能
void test_fgetc(void); // 测试 fread 性能
void test_fread(void); //
// 测试C大文件处理方式
//
int main(int argc, char * argv[]) { // 先构建测试环境
FILE * txt = fopen(_STR_DATA, "r");
if (NULL == txt) {
txt = fopen(_STR_DATA, "w");
if (NULL == txt) {
fprintf(stderr, "main fopen w " _STR_DATA " error!\n");
exit(EXIT_FAILURE);
} // 开始写入数据
for (int i = ; i < _INT_DATA; ++i)
fprintf(txt, "%d", i);
}
fclose(txt); // 开始测试数据, 分批测试
TIME_PRINT({
test_fgetc();
}); TIME_PRINT({
test_fread();
}); return ;
} //
// 测试 fgetc 性能
//
void
test_fgetc(void) {
FILE * txt = fopen(_STR_DATA, "r");
if (NULL == txt) {
fprintf(stderr, "test_fgetc fopen w " _STR_DATA " error!\n");
return;
} size_t cnt = ;
int c; while ((c = fgetc(txt)) != EOF)
++cnt; fclose(txt); printf("test_fgetc cnt = %d\n", cnt);
} //
// 测试 fread 性能
//
void test_fread(void) {
FILE * txt = fopen(_STR_DATA, "r");
if (NULL == txt) {
fprintf(stderr, "test_fread fopen w " _STR_DATA " error!\n");
return;
} size_t cnt = ;
char buf[BUFSIZ]; for (;;) {
int rn = fread(buf, sizeof(char), BUFSIZ, txt);
// 存在信号中断情况, 不考虑
cnt += rn;
if (rn < BUFSIZ)
break;
} fclose(txt); printf("test_fread cnt = %d\n", cnt);
}
实验二 fread最优解
这里测试的主要思路是基于fread设置不同的缓冲区, 开始测试性能对比情况. 首先test_file_define.c
#include <stdio.h>
#include <time.h>
#include <stdlib.h> #define _STR_DATA "data.txt"
#define _INT_DATA (1024*1024*128)
#define _INT_SZS (64)
#define _INT_SZE (4096) // 测试 fread 性能
void test_fread(int sz); //
// 测试C大文件处理方式
//
int main(int argc, char * argv[]) { // 先构建测试环境
FILE * txt = fopen(_STR_DATA, "r");
if (NULL == txt) {
txt = fopen(_STR_DATA, "w");
if (NULL == txt) {
fprintf(stderr, "main fopen w " _STR_DATA " error!\n");
exit(EXIT_FAILURE);
} // 开始写入数据
for (int i = ; i < _INT_DATA; ++i)
fprintf(txt, "%d", i);
}
fclose(txt); // 开始测试数据, 分批测试
for (int sz = _INT_SZS; sz <= _INT_SZE; sz <<= ) {
clock_t st, et;
st = clock();
test_fread(sz);
et = clock();
printf("sz = %6d => time:%lf seconds\n", sz, (0.0 + et - st) / CLOCKS_PER_SEC);
} return ;
} //
// 测试 fread 性能
//
void test_fread(int sz) {
FILE * txt = fopen(_STR_DATA, "r");
if (NULL == txt) {
fprintf(stderr, "test_fread fopen w " _STR_DATA " error!\n");
return;
} size_t cnt = ;
char buf[_INT_SZE]; for (;;) {
int rn = fread(buf, sizeof(char), sz, txt);
// 存在信号中断情况, 不考虑
cnt += rn;
if (rn < sz)
break;
} fclose(txt); printf("test_fread cnt = %d\n", cnt);
}
最终测试结果如下

直接说我得到的结论是
1). fread读取的时候, buf 和 文件大小, 机器等共同影响了最优解
2). 在设置缓冲大小为BUFSIZ左右, 性能都是可以接受的.
通过上面两个实验, 最终得到的一个结论. 处理大文件IO读取时候, 设计缓冲区可以采用下面套路将会获得更好的性能.
char buf[BUFSIZ];
size_t rn; do {
rn = fread(buf, sizeof(char), BUFSIZ, txt);
if (rn < ) {
// 初始失败的情况
....
} // 处理合法情况
.... } while(rn == BUFSIZ);
正文 - 构建一个成果
到这里, 通过上面结论, 开始构建一个成果, 例如读取全部文件内容. 当然限定文件大小在100mb以内吧, 太大需要采用分量读取算法了.
会使用到的辅助操作宏
//
// 控制台输出完整的消息提示信息, 其中fmt必须是 "" 包裹的字符串
// CERR -> 简单的消息打印
// CERR_EXIT -> 输出错误信息, 并推出当前进程
// CERR_IF -> if语句检查, 如果符合标准错误直接退出
//
#ifndef _H_CERR
#define _H_CERR #define CERR(fmt, ...) \
fprintf(stderr, "[%s:%s:%d][errno %d:%s]" fmt "\n",\
__FILE__, __func__, __LINE__, errno, strerror(errno), ##__VA_ARGS__) #define CERR_EXIT(fmt,...) \
CERR(fmt, ##__VA_ARGS__), exit(EXIT_FAILURE) #define CERR_IF(code) \
if((code) < ) \
CERR_EXIT(#code) #endif
首先声明读取文件的接口部分.
#ifndef _STRUCT_TSTR
#define _STRUCT_TSTR struct tstr {
char * str; // 字符串实际保存的内容
size_t len; // 当前字符串长度
size_t cap; // 字符池大小
}; // 定义的字符串类型
typedef struct tstr * tstr_t; #endif // !_STRUCT_TSTR //
// 简单的文件读取类,会读取完毕这个文件内容返回,失败返回NULL.
// path : 文件路径
// return : 创建好的字符串内容, 返回NULL表示读取失败
//
extern tstr_t tstr_freadend(const char * path);
这么设计方面, 后续操作, 读取内容长度, 继续添加内容方便些. 详细的实现如下
//
// 简单的文件读取类,会读取完毕这个文件内容返回,失败返回NULL.
// path : 文件路径
// return : 创建好的字符串内容, 返回NULL表示读取失败
//
tstr_t
tstr_freadend(const char * path) {
tstr_t tstr;
char buf[BUFSIZ];
size_t rn;
char * ctmp;
FILE * txt = fopen(path, "r");
if (NULL == txt) {
CERR("tstr_freadend fopen r %s is error!", path);
return NULL;
} // 分配内存
tstr = malloc(sizeof(struct tstr));
if (NULL == tstr) {
fclose(txt);
CERR("tstr_freadend malloc is error! path = %s.", path);
return NULL;
}
tstr->len = ;
tstr->cap = _INT_TSTRING;
tstr->str = NULL; // 读取文件内容
do {
rn = fread(buf, sizeof(char), BUFSIZ, txt);
if (rn < ) {
CERR("tstr_freadend fread is error! path = %s. rn = %d.", path, rn);
fclose(txt);
free(tstr->str);
free(tstr);
return NULL;
} // 构建数据
if (tstr->cap < tstr->len + rn) {
do
tstr->cap <<= ;
while (tstr->cap < tstr->len + rn);
ctmp = realloc(tstr->str, tstr->cap);
if (NULL == ctmp) {
CERR("tstr_freadend realloc is error! path = %s!", path);
fclose(txt);
free(tstr->str);
free(tstr);
return NULL;
}
tstr->str = ctmp;
} // 开始拷贝数据
memcpy(tstr->str + tstr->len, buf, rn);
tstr->len += rn;
} while (rn == BUFSIZ); fclose(txt); // 继续构建数据, 最后一行补充一个\0
if (tstr->cap < tstr->len + ) {
do
tstr->cap <<= ;
while (tstr->cap < tstr->len + );
ctmp = realloc(tstr->str, tstr->cap);
if (NULL == ctmp) {
CERR("tstr_freadend realloc is end error! path = %s!", path);
free(tstr->str);
free(tstr);
return NULL;
}
} tstr->str[tstr->len] = '\0';
tstr->len += ; return tstr;
}
最终测试文件 file_test_build.c
#include <stdio.h>
#include <errno.h>
#include <stdlib.h>
#include <assert.h>
#include <stdint.h>
#include <stddef.h>
#include <string.h> #ifndef _STRUCT_TSTR
#define _STRUCT_TSTR struct tstr {
char * str; // 字符串实际保存的内容
size_t len; // 当前字符串长度
size_t cap; // 字符池大小
}; // 定义的字符串类型
typedef struct tstr * tstr_t; #endif // !_STRUCT_TSTR //
// 控制台输出完整的消息提示信息, 其中fmt必须是 "" 包裹的字符串
// CERR -> 简单的消息打印
// CERR_EXIT -> 输出错误信息, 并推出当前进程
// CERR_IF -> if语句检查, 如果符合标准错误直接退出
//
#ifndef _H_CERR
#define _H_CERR #define CERR(fmt, ...) \
fprintf(stderr, "[%s:%s:%d][errno %d:%s]" fmt "\n",\
__FILE__, __func__, __LINE__, errno, strerror(errno), ##__VA_ARGS__) #define CERR_EXIT(fmt,...) \
CERR(fmt, ##__VA_ARGS__), exit(EXIT_FAILURE) #define CERR_IF(code) \
if((code) < ) \
CERR_EXIT(#code) #endif //
// 简单的文件读取类,会读取完毕这个文件内容返回,失败返回NULL.
// path : 文件路径
// return : 创建好的字符串内容, 返回NULL表示读取失败
//
extern tstr_t tstr_freadend(const char * path); //
// 测试文件读取, 推荐都是50mb以下文件好处理一点
//
int main(int argc, char * argv[]) { const char * path = "顾城 - 没有名字的诗歌.txt";
tstr_t str = tstr_freadend(path);
if (NULL == str)
CERR_EXIT("日狗吗? 这都读不出来`!"); // 这里打出数据
printf("当前总字符数:%d, 当前容量:%d.\n\n", str->len, str->cap);
puts(str->str); free(str->str);
free(str);
return ;
} // 文本字符串创建的初始化大小
#define _INT_TSTRING (32) //
// 简单的文件读取类,会读取完毕这个文件内容返回,失败返回NULL.
// path : 文件路径
// return : 创建好的字符串内容, 返回NULL表示读取失败
//
tstr_t
tstr_freadend(const char * path) {
tstr_t tstr;
char buf[BUFSIZ];
size_t rn;
char * ctmp;
FILE * txt = fopen(path, "r");
if (NULL == txt) {
CERR("tstr_freadend fopen r %s is error!", path);
return NULL;
} // 分配内存
tstr = malloc(sizeof(struct tstr));
if (NULL == tstr) {
fclose(txt);
CERR("tstr_freadend malloc is error! path = %s.", path);
return NULL;
}
tstr->len = ;
tstr->cap = _INT_TSTRING;
tstr->str = NULL; // 读取文件内容
do {
rn = fread(buf, sizeof(char), BUFSIZ, txt);
if (rn < ) {
CERR("tstr_freadend fread is error! path = %s. rn = %d.", path, rn);
fclose(txt);
free(tstr->str);
free(tstr);
return NULL;
} // 构建数据
if (tstr->cap < tstr->len + rn) {
do
tstr->cap <<= ;
while (tstr->cap < tstr->len + rn);
ctmp = realloc(tstr->str, tstr->cap);
if (NULL == ctmp) {
CERR("tstr_freadend realloc is error! path = %s!", path);
fclose(txt);
free(tstr->str);
free(tstr);
return NULL;
}
tstr->str = ctmp;
} // 开始拷贝数据
memcpy(tstr->str + tstr->len, buf, rn);
tstr->len += rn;
} while (rn == BUFSIZ); fclose(txt); // 继续构建数据, 最后一行补充一个\0
if (tstr->cap < tstr->len + ) {
do
tstr->cap <<= ;
while (tstr->cap < tstr->len + );
ctmp = realloc(tstr->str, tstr->cap);
if (NULL == ctmp) {
CERR("tstr_freadend realloc is end error! path = %s!", path);
free(tstr->str);
free(tstr);
return NULL;
}
} tstr->str[tstr->len] = '\0';
tstr->len += ; return tstr;
}
测试结果是通过的
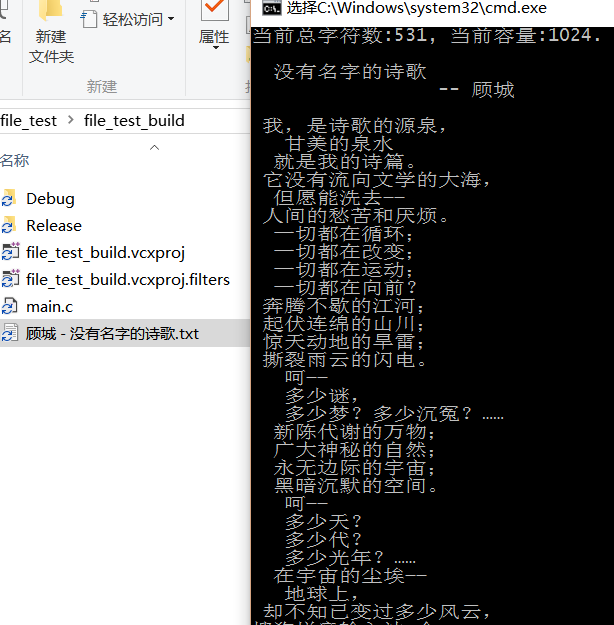
到这里基本上, 我们已经通过验证,构建了最终的操作代码, 欢迎尝试用于性能提升上.
后记 - 扯淡以后
错误是难免的, 欢迎指正, 交流提高. O(∩_∩)O哈哈~
笑傲江湖曲 http://music.163.com/#/song?id=30031035

C基础 大文件读取通过标准库的更多相关文章
- PHP大文件读取操作
简单的文件读取,一般我们会使用 file_get_contents() 这类方式来直接获取文件的内容.不过这种函数有个严重的问题是它会把文件一次性地加载到内存中,也就是说,它会受到内存的限制.因此,加 ...
- linux大文件读取
在生产环境中有时候可能会遇到大文件的读取问题,但是大文件读取如果按照一般的手法.如cat这种都是对io的一个挑战,如果io扛得住还好,如果扛不住 造成的后果,如服务器内存奔溃,日志损坏 方法一: se ...
- python大文件读取
python大文件读取 https://stackoverflow.com/questions/8009882/how-to-read-a-large-file-line-by-line-in-pyt ...
- TCP协议传输大文件读取时候的问题
TCP协议传输大文件读取时候的问题 大文件传不完的bug 我们在定义的时候定义服务端每次文件读取大小为10240, 客户端每次接受大小为10240 我们想当然的认为客户端每次读取大小就是10240而把 ...
- Java解决大文件读取的内存问题以及文件流的比较
Java解决大文件读取的内存问题以及文件流的比较 传统方式 读取文件的方式一般是是从内存中读取,官方提供了几种方式,如BufferedReader, 以及InputStream 系列的,也有封装好的如 ...
- 单片机stm32零基础入门之--初识STM32 标准库
CMSIS 标准及库层次关系 因为基于Cortex 系列芯片采用的内核都是相同的,区别主要为核外的片上外设的差异,这些差异却导致软件在同内核,不同外设的芯片上移植困难.为了解决不同的芯片厂商生产的Co ...
- 大文件读取方法(C#)
之前都是用StreamReader.ReadLine方法逐行读取文件,自从.NET4有了File.ReadLines这一利器,就再也不用为大文件发愁了. File.ReadLines在整个文件读取到内 ...
- php 大文件读取
当你需要处理一个5G的文件里面的数据时,你会怎么做,将文件里面的内容全部读取到一个数组里面去? 显然这种做法对小文件是没有问题的,但是对于大文件还是不行的 这时就需要用到 yield 了 ,注意这是 ...
- dart 大文件读取
dart 中不可避免会出现文件读取的情况, 甚至是很大的文件, 比如 200M 的文件 如果一次性读入内存,虽然也行得通, 但是如果在 flutter 中开启个 200M 大小的字节数组, 一不小心可 ...
随机推荐
- 【刷题】BZOJ 2038 [2009国家集训队]小Z的袜子(hose)
Description 作为一个生活散漫的人,小Z每天早上都要耗费很久从一堆五颜六色的袜子中找出一双来穿.终于有一天,小Z再也无法忍受这恼人的找袜子过程,于是他决定听天由命-- 具体来说,小Z把这N只 ...
- Hyperledger Fabric 实战(十): Fabric node SDK 样例 - 投票DAPP
Fabric node SDK 样例 - 投票DAPP 参考 fabric-samples 下的 fabcar 加以实现 目录结构 . ├── app │ ├── controllers │ │ └─ ...
- Android Appliction 使用解析
Application Base class for those who need to maintain global application state. You can provide your ...
- 洛谷4578 & LOJ2520:[FJOI2018]所罗门王的宝藏——题解
https://www.luogu.org/problemnew/show/P4578 https://loj.ac/problem/2520 有点水的. 先转换成图论模型,即每个绿宝石,横坐标向纵坐 ...
- spring全局异常处理 自定义返回数据结构
在写api接口中,正常返回和异常错误返回我们都希望很清楚的将这些信息清楚的返回给用户,出现异常情况下需要清楚的知道是参数异常还是未知异常,而不是返回一个不正确的数据结构. 所以此处只针对写api接口时 ...
- jdbcType和javaType
MyBatis 通过包含的jdbcType类型 BIT FLOAT CHAR TIMESTAMP OTHER UNDEFINED TINYINT REAL VARCHAR BINARY BLOB NV ...
- 【题解】Crash的数字表格 BZOJ 2154 莫比乌斯反演
题目传送门 http://www.lydsy.com/JudgeOnline/problem.php?id=2154 人生中第一道自己做出来的莫比乌斯反演 人生中第一篇用LaTeX写数学公式的博客 大 ...
- 000 Python常识与快捷键(未完)
1.Python控制台IDLE的快捷键 Alt + N :返回开始输入的第一条语句 Alt + P :返回刚刚输入的上一条语句 Tab:制表符,用于缩进或补全内容,是Python语法格式的灵魂,作用涵 ...
- phpstorm license 解决
http://idea.lanyus.com/ sudo vim /etc/hosts 最后添加: 0.0.0.0 account.jetbrains.com 然后把获得的注册码,复制到,licen ...
- 分析一个贴图社交app的失败原因:FORK(相机)
FORK(相机)是一个通过分享图片来建立社交的app,它有着鲜明的配色,还算不错的贴图创新,细腻的产品设计,但是由于产品定位不清晰.设计亮点不多以及推广不利,从2014年5月第一版开始就没有火过.所以 ...