R_Studio(贷款)数据规范化处理[最小-最大规范化、零-均值规范化、小数定标规范化]
农场申请贷款.csv
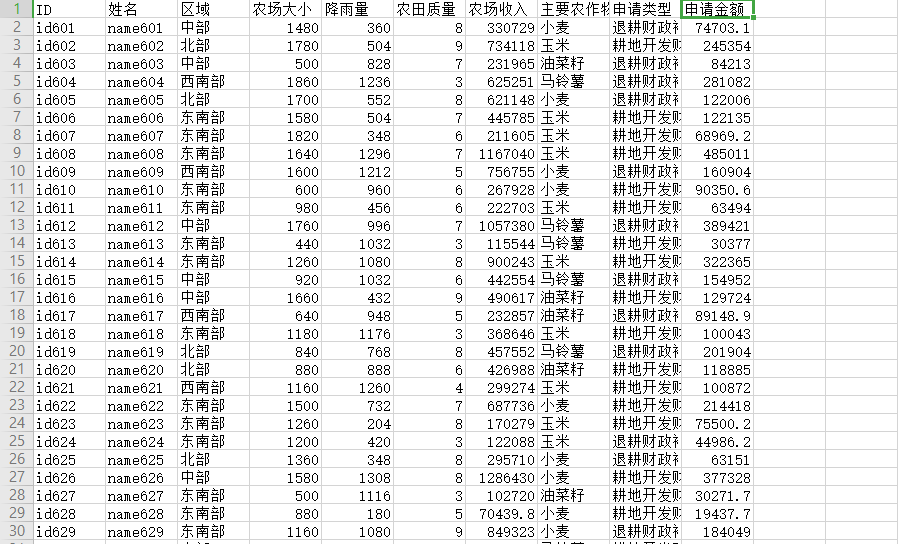
对“农场申请贷款.csv”中农场大小、降雨量、农场质量、农场收入进行数据规范化处理 行数[4 5 6 7]
“农场申请贷款.csv”中存在缺失值,已对数据进行预处理
setwd('D:\\data')
list.files()
#数据读取
dat=read.csv(file="农场申请贷款.csv",header=TRUE)
sub=which(is.na(dat[5]$'降雨量'))#识别缺失值所在行数
#将数据集分成完整数据和缺失数据两部分
inputfile1=dat[-sub,] #缺失部分
inputfile2=dat[sub,] #不缺失部分
dat=inputfile1
#最小-最大规范化
b1=(dat[,4]-min(dat[,4]))/(max(dat[,4])-min(dat[,4]))
b2=(dat[,5]-min(dat[,5]))/(max(dat[,5])-min(dat[,5]))
b3=(dat[,6]-min(dat[,6]))/(max(dat[,6])-min(dat[,6]))
b4=(dat[,7]-min(dat[,7]))/(max(dat[,7])-min(dat[,7]))
data_scatter=cbind(b1,b2,b3,b4)
newdata=dat
for(i in 4:7){
newdata[,i] =(dat[,i]-min(dat[,i]))/(max(dat[,i])-min(dat[,i]))
}
data_scatter=cbind(b1,b2,b3,b4)
data_scatter=cbind(b1,b2,b3,b4)
#零-均值规范化
data_zscore=scale(data_scatter)
data_zscore
#小数定标规范化
i1=ceiling(log(max(abs(dat[,4])),10))#小数定标的指数
c1=dat[,4]/10^i1
i2=ceiling(log(max(abs(dat[,5])),10))
c2=dat[,5]/10^i2
i3=ceiling(log(max(abs(dat[,6])),10))
c3=dat[,6]/10^i3
i4=ceiling(log(max(abs(dat[,6])),10))
c4=dat[,7]/10^i4
data_dot=cbind(c1,c2,c3,c4)
#打印结果
options(digits = 4)#控制输出结果的有效位数
data;data_scatter;data_zscore;data_dot
Gary.R
最小-最大规范化:对原始数据的线性变换,将数值映射到[0,1]

setwd('D:\\data')
list.files()
#数据读取
dat=read.csv(file="农场申请贷款.csv",header=TRUE)
sub=which(is.na(dat[5]$'降雨量'))#识别缺失值所在行数
#将数据集分成完整数据和缺失数据两部分
inputfile1=dat[-sub,] #缺失部分
inputfile2=dat[sub,] #不缺失部分
dat=inputfile1 #将清洗过的数据保存回dat中
#最小-最大规范化
b1=(dat[,4]-min(dat[,4]))/(max(dat[,4])-min(dat[,4]))
b2=(dat[,5]-min(dat[,5]))/(max(dat[,5])-min(dat[,5]))
b3=(dat[,6]-min(dat[,6]))/(max(dat[,6])-min(dat[,6]))
b4=(dat[,7]-min(dat[,7]))/(max(dat[,7])-min(dat[,7]))
data_scatter=cbind(b1,b2,b3,b4)
newdata=dat
for(i in 4:7){
newdata[,i] =(dat[,i]-min(dat[,i]))/(max(dat[,i])-min(dat[,i]))
}
data_scatter=cbind(b1,b2,b3,b4)
data_scatter
Gary.R
零-均值规范化:标准差规范化,经过处理的数据的均值位0,标准差位1

scale方法中的两个参数center和scale的解释:
center和scale默认为真,即T或者TRUE
center为真表示数据中心化(只减去均值不做其他处理)
scale为真表示数据标准化
setwd('D:\\data')
list.files()
#数据读取
dat=read.csv(file="农场申请贷款.csv",header=TRUE)
sub=which(is.na(dat[5]$'降雨量'))#识别缺失值所在行数
#将数据集分成完整数据和缺失数据两部分
inputfile1=dat[-sub,] #缺失部分
inputfile2=dat[sub,] #不缺失部分
dat=inputfile1 #将清洗过的数据保存回dat中
#零-均值规范化
data_zscore=scale(data_scatter)
data_zscore
data_zscore
Gary.R
小数定标规范化:最小-最大规范化保持原有数据之间的联系
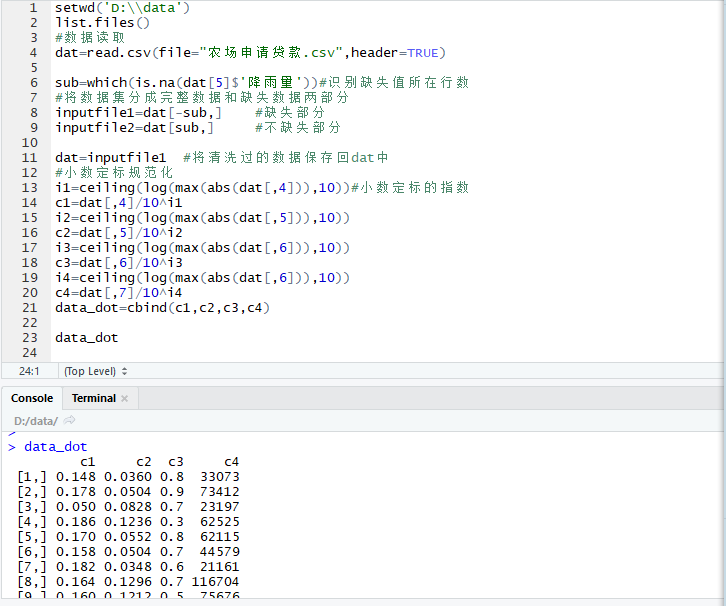
setwd('D:\\data')
list.files()
#数据读取
dat=read.csv(file="农场申请贷款.csv",header=TRUE)
sub=which(is.na(dat[5]$'降雨量'))#识别缺失值所在行数
#将数据集分成完整数据和缺失数据两部分
inputfile1=dat[-sub,] #缺失部分
inputfile2=dat[sub,] #不缺失部分
dat=inputfile1 #将清洗过的数据保存回dat中
#小数定标规范化
i1=ceiling(log(max(abs(dat[,4])),10))#小数定标的指数
c1=dat[,4]/10^i1
i2=ceiling(log(max(abs(dat[,5])),10))
c2=dat[,5]/10^i2
i3=ceiling(log(max(abs(dat[,6])),10))
c3=dat[,6]/10^i3
i4=ceiling(log(max(abs(dat[,6])),10))
c4=dat[,7]/10^i4
data_dot=cbind(c1,c2,c3,c4)
data_dot
Gary.R
R_Studio(贷款)数据规范化处理[最小-最大规范化、零-均值规范化、小数定标规范化]的更多相关文章
- R语言-来自Prosper的贷款数据探索
案例分析:Prosper是美国的一家P2P在线借贷平台,网站撮合了一些有闲钱的人和一些急用钱的人.用户若有贷款需求,可在网站上列出期望数额和可承受的最大利率.潜在贷方则为数额和利率展开竞价. 本项目拟 ...
- MySQL 查询重复数据,删除重复数据保留id最小的一条作为唯一数据
开发背景: 最近在做一个批量数据导入到MySQL数据库的功能,从批量导入就可以知道,这样的数据在插入数据库之前是不会进行重复判断的,因此只有在全部数据导入进去以后在执行一条语句进行删除,保证数据唯一性 ...
- 多线程外排序解决大数据排序问题2(最小堆并行k路归并)
转自:AIfred 事实证明外排序的效率主要依赖于磁盘,归并阶段采用K路归并可以显著减少IO量,最小堆并行k路归并,效率倍增. 二路归并的思路会导致非常多冗余的磁盘访问,两组两组合并确定的是当前的相对 ...
- 为mysql数据备份建立最小权限的用户
mysqldump 备份所需要的最小权限说明: 1.对于table,mysqldump 最少要有select权限 2.如果要产生一份一致的备份,mysqldump 要有lock tables权限 3. ...
- R_Studio(癌症)数据连续属性离散化处理
对“癌症.csv”中的肾细胞癌组织内微血管数进行连续属性的等宽离散化处理(分为3类),并用宽值找替原来的值 癌症.csv setwd('D:\\data') list.files() dat=read ...
- 删除表中重复数据,只删除重复数据中ID最小的
delete t_xxx_user where recid in ( select recid from t_xxx_user where recid in ( select min(recid) f ...
- caffe 图片数据的转换成lmdb和数据集均值(转)
转自网站: http://blog.csdn.net/muyiyushan/article/details/70578077 1.准备数据 使用dog/cat数据集,在训练项目根目录下分别建立trai ...
- MySql数据库列表数据分页查询、全文检索API零代码实现
数据条件查询和分页 前面文档主要介绍了元数据配置,包括表单定义和表关系管理,以及表单数据的录入,本文主要介绍数据查询和分页在crudapi中的实现. 概要 数据查询API 数据查询主要是指按照输入条件 ...
- R语言︱数据规范化、归一化
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:规范化主要是因为数据受着单位的影响较 ...
随机推荐
- 2019中山纪念中学夏令营-Day2[JZOJ]
博客的开始,先聊聊代码实现: 每次比赛以后,要有归纳错误的习惯. 错误小结: 1.读入:scanf(“%c”)会读入回车和空格,但cin不会. 2.对于二维数组的输入,不能把m,n搞混了,会引起严重的 ...
- python多任务——协程的使用
使用yield完成多任务 import time def test1(): while True: print("--1--") time.sleep(0.5) yield Non ...
- Docker 容器简介与部署
关于Docker容器技术 参考文献:<docker 从入门到精通> Docker容器简介 Docker的构想是要实现 "Build,Ship and Run Any App,An ...
- spring boot本地开发与docker容器化部署的差异
spring boot本地开发与docker容器化部署的差异: 1. 文件路径及文件名区别大小写: 本地开发环境为windows操作系统,是忽略大小写的,但容器中区分大小写 2. docker中的容器 ...
- 关于redis的几件小事(八)缓存与数据库双写时的数据一致性
1.Cache aside pattern 这是最经典的 缓存+数据库 读写模式,操作如下: ①读的时候,先读缓存,缓存没有就读数据库,然后将取出的数据放到缓存,同时返回请求响应. ②更新的时候,先删 ...
- cookie和session的详解和区别
会话(Session)跟踪是Web程序中常用的技术,用来跟踪用户的整个会话.常用的会话跟踪技术是Cookie与Session.Cookie通过在客户端记录信息确定用户身份,Session通过在服务器端 ...
- js动态添加行和列(table)
function AddTableRow() { var Table = document.getElementById("NewTable"); //取得自定义的表对象 NewR ...
- 第十九篇 jQuery初步学习
jQuery 初步学习 jQuery可以理解为是一种脚本,需要到网上下载,它是一个文件,后缀当然是js的文件,它里面封装了很多函数方法,我们直接调用即可,就比方说,我们用JS,写一个显示与隐藏,通 ...
- 关于catopen函数
关于catopen函数: 参考网址:http://pubs.opengroup.org/onlinepubs/009695399/functions/catopen.html 1)编辑消息文件 [ro ...
- upupw : Apache Php5.5 的使用
1. 官网下载 1. 官网下载 apache php5.5点击下载 但是 现在有时候打不开,所以提供以下方法 2. 百度云网盘下载 https://pan.baidu.com/s/1eQ2k1Su ...