SQL查询优化的步骤
官方文档:Understanding the Query Execution Plan
SQL优化的一般步骤:先查询mysql数据库运行状况,然后定位慢查询,再分析sql的执行过程,最后根据情况采取相应的优化措施。
一、定位慢查询
1.使用show status查询数据库的运行状况
//显示数据库运行状态
SHOW STATUS
//显示数据库运行总时间
SHOW STATUS LIKE 'uptime'
//显示连接的次数
SHOW STATUS LIKE 'connections'
//显示执行CRUD的次数
SHOW STATUS LIKE 'com_select'
SHOW STATUS LIKE 'com_insert'
SHOW STATUS LIKE 'com_update'
SHOW STATUS LIKE 'com_delete'
2.定位慢查询sql
我们可以通过mysql来记录慢查询,一旦有sql执行时间超过了设置的慢查询时间,就会被记录到慢查询日志中。这样我们就可以从慢查询日志中定位慢查询sql,然后进行分析优化。
查看慢查询相关信息
//显示慢查询次数
SHOW STATUS LIKE 'slow_queries'
//显示慢查询时间,默认为10s
SHOW VARIABLES LIKE 'long_query_time'
mysql的慢查询默认是关闭的,可以通过修改配置文件或通过命令来开启。
①修改配置文件方式
Linux下修改my.cnf,Windows下修改my.ini。修改后需要重启mysql才会生效。
#开启慢查询
slow-query-log=1
#慢查询的文件路径
slow_query_log_file="D:/Program Files/MySQL/Log/mysql-slow.log"
#慢查询时间。默认为10秒
long_query_time=10
②命令方式
也可以使用命令来修改。
【session级别】
#开启慢查询
SET slow_query_log='ON'; #设置慢查询日志存放位置
SET slow_query_log_file='/usr/local/mysql/data/slow.log'; #设置慢查询时间
SET long_query_time=3 【global级别】
SET global slow_query_log='ON';
SET global slow_query_log_file='/usr/local/mysql/data/slow.log';
SET global long_query_time=3
3.分析慢查询
在实际生产环境中,可能因为开发写了不正确的SQL语句,索引优化的不好,或其他查询操作而导致数据库整体性能下降。我们只需要分析一下慢查询日志就会知道问题出在哪。
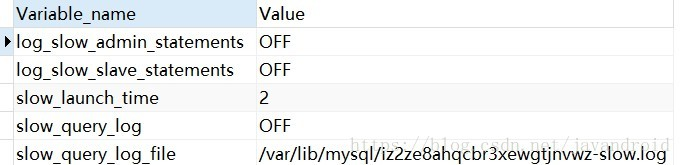
//查看是否启用慢日志记录和状态
show variables like "%slow%"
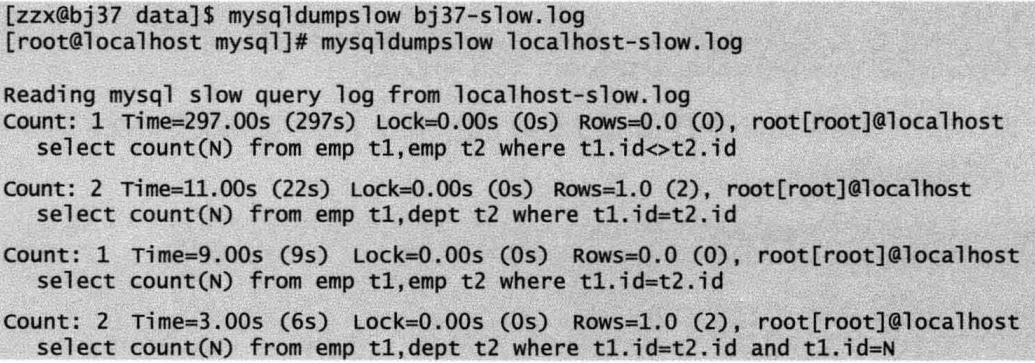
如果慢查询日志中记录内容较多,则可以使用Mysql自带的慢查询日志分析工具mysqldumpslow工具来对慢查询日志进行分类汇总。该工具位于/mysql/bin目录下。mysqldumpslow将会自动将文本完全一致但变量不同的SQL语句视为同一个语句进行统计,变量值用N来代替。
mysqldumpslow -s r -t 10 /data/dbdata/frem-slow.log
二、使用explain分析sql执行过程
官方文档:Optimizing Queries with EXPLAIN
mysql会将慢查询记录到慢查询日志中,这时我们就可以针对这些慢查询的sql进行分析和优化,需要用到explain命令。
explain [要分析的sql]
分析结果中有如下几列:
+----+-------------+---------+------+---------------+------+---------+------+------+-------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+------+---------------+------+---------+------+------+-------+-------+
下面介绍各列的含义。可以参考官方文档说明:Explain Output Colums
id
表示select查询序列号。id值越大,越优先执行。如果id相同,执行顺序由上至下;

select_type
表示查询操作的类型。主要用于区分普通查询、子查询、联合查询等几种查询情况。有这些取值:simple,primary,subquery,derived,union,union result
①simple:表示简单查询,只有一个select操作,即不使用连接和union。
#只有一个select操作,所以都是简单查询 select id from emp; select id from emp join dept on emp.dept_id=dept.id;
②primary:表示主查询。子查询语句中的最外层select,或union操作的第一个select。
#子查询形式:第一个select操作为primary
select * from app_school where id = (select id from app_school where id=100); #union形式:第一个select操作为primary
select * from app_school where id=100
union
select * from app_school where id=101;
③subquery:表示子查询。子查询语句中的内层select。
#第二个select操作为subquery
select * from app_school where id = (select id from app_school where id=100);
④derived:表示FROM后跟着的select查询,会被标记为derived(导出表/衍生表)。
#第二个select操作为derived
select * from (select id from app_school) t;
⑤union:表示UNION操作后面的select查询。
#第二个select操作为union
select * from app_school where id=100
union
select * from app_school where id=101;
⑥union result:表示获取UNION最后结果的查询。
#第一个select操作为primary
#第二个select操作为union
#获取最终结果的操作为union result
select * from app_school where id=100
union
select * from app_school where id=101;

table
表示查询用到的表。
type
表示找到匹配行用到的访问类型。最为常见的类型有system,const,eq_ref,ref,range,index,All,按照性能从高到低顺序如下:NULL-->system-->const-->eq-ref-->ref-->range-->index-->All 。一般来说,要让查询至少达到range级别,最好能达到ref级别。
①NULL:不用访问表或索引,就可直接得出结果。
②system:该表是最多仅有一行的系统表(这是const类型的一个特例)。系统表中的数据通常已经加载到了内存中,所以不需要磁盘IO。
例子1:查询系统表
例子2:内层嵌套(const)返回了一个临时表,外层嵌套从临时表中查询,其扫描类型也是system,也不需要磁盘IO。

③const:最多只有一个匹配行,所以该行中的其它列的值可以当作常量来处理。例如,根据主键primary key或唯一索引unique index进行查询。简单地说const就是直接按主键或唯一键取值。例如在②中介绍system时的举例中user表的访问类型就是const,其通过主键来取值。

④eq_ref:使用唯一索引,对于每个索引键值,表中只有一条记录匹配。简单说,就是多表连接中使用primary key或unique index作为关联条件。
注意const和eq_ref的区别:简单地说是const是直接按主键或唯一键读取,eq_ref用于联表查询的情况,按联表的主键或唯一键联合查询。
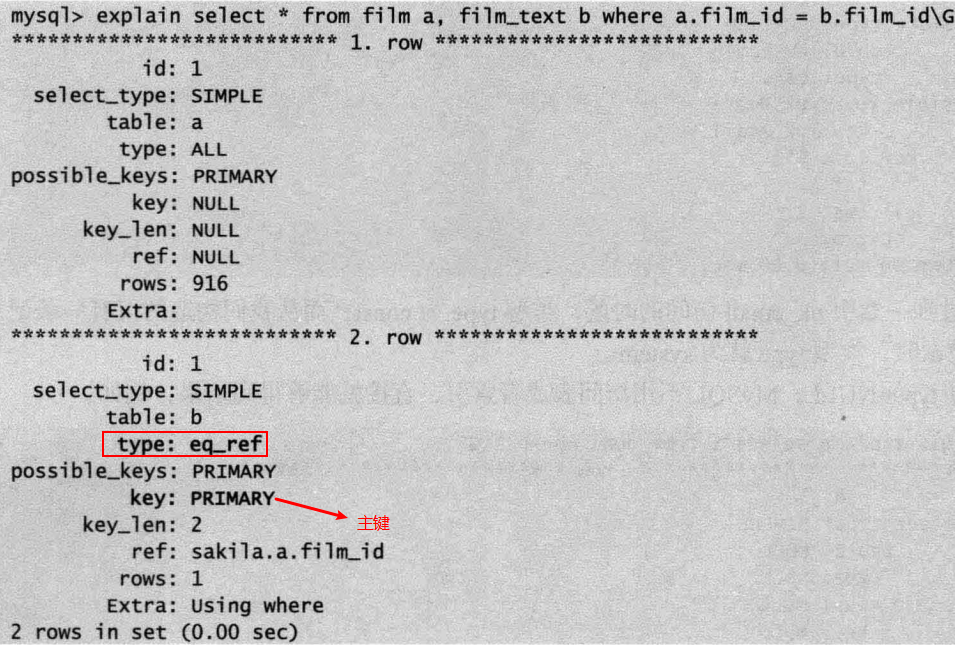

⑤ref:使用非唯一索引,或唯一索引的前缀扫描,返回匹配某个单独值的所有行(可能匹配多个行)。


ref还经常出现在join操作中
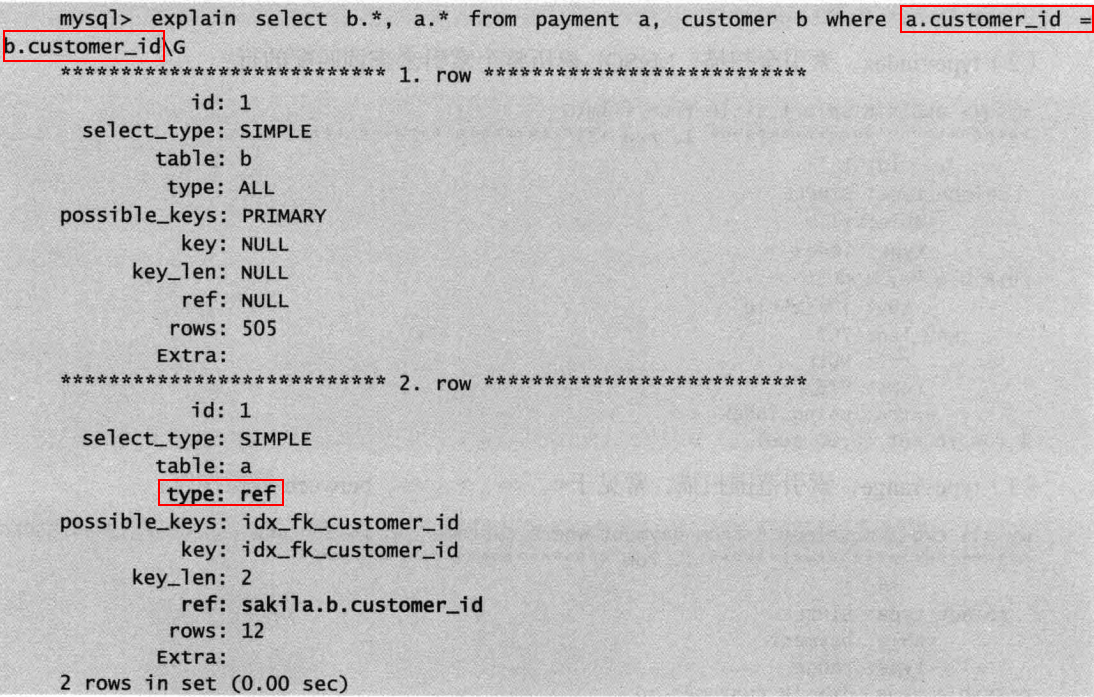
⑥ref_or_null:与ref类似,区别在于条件中包含对NULL的查询。
⑦index_merge:索引合并优化。
⑧unique_subquery:in的后面是一个查询主键字段的子查询。
⑨index_subquery:与unique subquery类似,区别在于in的后面是查询非唯一索引字段的子查询。
⑩range:只检索指定范围的行,使用一个索引来选择行。常见于<,<=,>,>=,between或者IN操作符。
key列显示使用了哪个索引。key_len包含所使用索引的最长关键元素。

.index:索引全扫描。遍历整个索引来查询匹配的行。

12.ALL:全表扫描,性能最差。

possible_keys和key
possible_keys表示查询时可能使用到的索引。key表示实际使用的索引
key_len
表示使用到的索引字段的长度
ref
表示该表的索引字段关联了哪张表的哪个字段
rows
表示扫描行的数量
Extra
表示执行情况的说明和描述。包含不适合在其它列中显示但对执行计划非常重要的额外信息。
三、使用show profile分析sql
有时仅通过explain分析执行计划并不能很快地定位SQL的问题,这时就可以选择profile联合分析。Mysql从5.0.37开始增加了对show profiles和show profile语句的支持。默认profile是关闭的,可以通过set开启session级别的profiling。
//查看是否支持profile
SELECT @@have_profiling
//开启profile(session级别)
set profiling=1;
①执行select语句
②show profiles,查询该sql语句的Query ID.
③通过show profile for query语句能看到执行中线程的每个状态和消耗的时间。
show profile for query [上面的query id]
三、通过trace分析优化器如何选择执行计划
Mysql5.6提供了对sql的跟踪trace,通过trace文件能够进一步了解为什么优化器选择A执行计划而不选择B执行计划,帮助我们更好地理解优化器的行为。
使用方式:
①首先打开trace,设置格式为json,设置trace最大能够使用的内存大小,避免解析过程中因为默认内存过小而不能够完整显示。
//打开trace,设置json格式
SET OPTIMIZER_TRACE="enabled=on",END_MARKERS_IN_JSON=on;
//设置内存
SET OPTIMIZER_TRACE_MAX_MEM_SIZE=1000000;
②接下来执行想做trace的sql语句
select xxx
③检查INFORMATION_SCHEMA.OPTIMIZER_TRACE就知道mysql是如何执行sql的了
SELECT * FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE
最后会输出一个跟踪文件。
SQL查询优化的步骤的更多相关文章
- MySQL 性能调优——SQL 查询优化
如何设计最优的数据库表结构,如何建立最好的索引,以及如何扩展数据库的查询,这些对于高性能来说都是必不可少的.但是只有这些还不够,要获得良好的数据库性能,我们还要设计合理的数据库查询,如果查询设计的很糟 ...
- SQL查询优化——数据结构设计
本文部分内容会涉及mysql,可能在其它数据库中并不适用. 本章节仅仅针对数据库结构设计做讨论.查询优化的其它内容待续. 数据库设计及使用是WEB开发程序猿必备的一项基础技能,在大数据量和高并发场景, ...
- 引用:初探Sql Server 执行计划及Sql查询优化
原文:引用:初探Sql Server 执行计划及Sql查询优化 初探Sql Server 执行计划及Sql查询优化 收藏 MSSQL优化之————探索MSSQL执行计划 作者:no_mIss 最近总想 ...
- 30条SQL查询优化原则
在我们平常的SQL查询中,其实我们有许多应该注意的原则,以来实现SQL查询的优化,本文将为大家介绍30条查询优化原则. 首先应注意的原则 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 wher ...
- SQL查询优化 LEFT JOIN和INNER JOIN
作者:VerySky 推荐:陈敬(Cathy) SQL查询优化 LEFT JOIN和INNER JOIN 1,连接了八个数据库表,而且全部使用LEFT JOIN,如下所示: Resource_Reso ...
- MySQL SQL查询优化技巧详解
MySQL SQL查询优化技巧详解 本文总结了30个mysql千万级大数据SQL查询优化技巧,特别适合大数据里的MYSQL使用. 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 ...
- MySQL系列(七)--SQL优化的步骤
前面讲了如何设计数据库表结构.存储引擎.索引优化等内存,这篇文章会讲述如何进行SQL优化,也是面试中关于数据库肯定会被问到的, 这些内容不仅仅是为了面试,更重要的是付诸实践,最终用到工作当中 之前的M ...
- 《打造扛得住的MySQL数据库架构》第7章 SQL查询优化
SQL查询优化 7-1 获取有性能问题SQL的三种方法 如何设计最优的数据库表结构 如何建立最好的索引 如何拓展数据库的查询 查询优化,索引优化,库表结构优化 如何获取有性能问题的SQL 1.通过测试 ...
- 优化 SQL 语句的步骤
优化 SQL 语句的步骤 1.分析MySQL服务器当前的状态信息 SHOW SESSION STATUS; SHOW SESSION STATUS LIKE 'Com_%' //当前会话下所有语句类型 ...
随机推荐
- SpringMvc配置自定义视图
1.在dispatcherServlet-servlet.xml配置自定义视图 <!-- 配置视图 BeanNameViewResolver 解析器: 使用视图的名字来解析视图 --> & ...
- JS中keyup, keypress, keydown以及oninput四个事件的区别
$email_input.onkeyup=function(event){ // console.log('event handle');//按方向键以及backspce esc有反应 长按字母键也没 ...
- 分布式任务队列 Celery —— 详解工作流
目录 目录 前文列表 前言 任务签名 signature 偏函数 回调函数 Celery 工作流 group 任务组 chain 任务链 chord 复合任务 chunks 任务块 mapstarma ...
- powered by Fernflower decompiler
About Fernflower Fernflower is the first actually working analytical decompiler for Java and probabl ...
- ARTS-1
ARTS的初衷 Algorithm:主要是为了编程训练和学习.每周至少做一个 leetcode 的算法题(先从Easy开始,然后再Medium,最后才Hard).进行编程训练,如果不训练你看再多的算法 ...
- CSS3——提示工具 图片廓 图像透明 图像拼接技术 媒体类型 属性选择器
提示工具 提示框在鼠标移动到特定的元素上显示 设置提示框的位置 给提示框添加箭头 提示框的淡入效果 提示框美化 图片廓 响应式图片廓 图像透明 创建透明图像——悬停效果 ———鼠标放置后———> ...
- 阿里云 centos 部署 Django 可能遇到的问题
问题一:版本限制 File "/Users/icourt/Desktop/hf/venv/lib/python3.7/site-packages/django/db/backends/m ...
- 什么是Shell?Shell脚本基础知识详细介绍
这篇文章主要介绍了什么是Shell?Shell脚本基础知识介绍,本文是一篇Shell脚本入门文章,在本文你可学到什么是Shell.有多少种Shell.一个Shell脚本代码实例,需要的朋友可以参考下 ...
- redis学习(二)
深入了解redis字符串,列表,散列和有序集合命令,了解发布,订阅命令和其他命令. 一,字符串 1.字符串可以存储3种类型的值 字符串,整数,浮点数 2.运算命令列表 incr : incr ...
- 华硕RT-AC86U路由器 AP模式实现多路由器组网,扩展主路由器的无线网范围
描述: 宽带拨号上网的路由器为 TP-LINK TL-WAR1200L,由于室内空间大,遂在此路由器下接入一个 华硕RT-AC86U路由器: 配置使该 华硕路由器与 TP-LINK 路由器的网段相同 ...