kafka复习(2)
一、简介
---------------------------------------
1.kafka是一个分布式的、可分区的、可复制的消息系统。它提供了消息系统的功能,但是有自己独特的设计。
2.名词解释:
(1)topic:kafka将罅隙以topic为单位
(2)producer:向kafka发送消息的程序
(3)consumer:将预定topics并消费的程序
(4)broker:kafka以集群的形式来运行,可以由一个或者多个服务组成,每个服务叫做一个broker
3.producer通过网络将消息发送到kafka集群,集群向消费者提供消息,如下图所示:
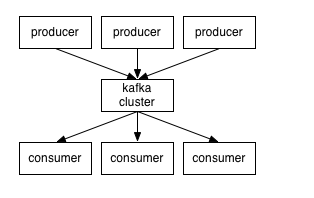
客户端和服务端通过TCP通信。Kafka提供了java客户端,并提供了多种语言的支持
4.Topics和Logs:kafka提供了一个抽象的概念:topic
一个topic是对一组消息的归纳。对每个topic,kafka对他的日志尽行了分区,如下图所示:
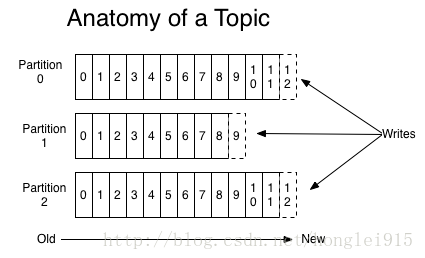
(1)每个分区都由一系列有序的、不可变的消息组成,这些消息被连续追加到分区中。分区中的每个消息都有一个连续的序列号叫做offset,用来在分区中唯一标识这个消息。
(2)在一个可以配置的时间内,kafka集群保留所有发布的消息,不管这些消息有没有被消费。比如消息的保存策略设置为2天,那么在一个消息发布的两天的时间内,他都是可以被消费的,如果没有被消费,就会保留在分区中。之后将会被丢弃来释放空间。Kafka的性能是和性能无关的常量级的,所以保留太多的数据不是问题。
(3)实际上每个consumer需要唯一维护的数据是消息在日志中的位置,也就是offset,这个offset由consumer来进行相应的维护:一般情况下随着consumer不断的读取消息,这个offset的值会不断增加,但是consumer可以任意顺序读取消息,比如可以将offset设置为一个旧的值来重读之前的消息。
(4)以上特点的结合,使得kafka consumer是一个非常的轻量级:他们可以在不对集群和其他consumer造成影响的情况下读取消息。可以使用命令行来tail消息而不会对其他正在消费的消息的consumer造成影响。
(5)日志分区可以达到以下目的:首先使得每个日志数量不会太大,可以在单个服务商保存。每个分区可以单独发布和消费,并未发布操作topic提供了一种坑能。
6.分布式
每一个分区在kafka集群的若干服务中都有副本,这样持有副本的服务可以共同处理数据和请求,副本数量是可以配置的。副本使得kafka具备了容错的能力。每个分区都由一个容器作为leader,0或者若干服务器作为flower,leader负责处理消息的读和写,flowers则则去复制leader,如果follower down了,flower中的一台会自动成为leader。集群中的每个服务器都会扮演两个角色:作为他所持有一部分分区的leader,其他分区的flowers,这样的集群就有比较哈ode均衡负载了。
7.Producers:
将消息发送到他所指定的topic中,并负责决定发布到哪个分区。通常由简单的负载均衡机制来选择分区,但是也可以通过特定的分区函数来选择哪个分区 。而我们通常使用更多的是第二种。
8.Consumers
----------------------------------------
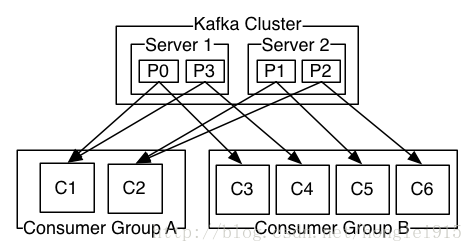
(1)发布消息的两种模式:
队列模式(queuing)和发布-订阅模式(publish-subscribe)。在队列模式中,consumer可以同时从服务器端读取消息,每个消息只被其中的一个consumer读取到;
发布-订阅模式消息:消息被广播到所有的所有的consumer中,consumers可以加入其中一个consumer组,共同竞争一个topic,topic中的消息将被分发到组中的一个成员。同一个组中的consumer可以在不同的程序中,也可以在不同的机器上面。如果所有的consumer在同一个组中,那就成为了传统的队列模式,在各个consumer中实现负载均衡。如果所有的consumer都在不同的组中,这就成为了发布-订阅模式,所有的消息都被发送到所有的consumer中,更加常见的是,每个topic都有若干数量的consumer组,每个组都是一个逻辑上的"订阅者",为了容错和更好的稳定性,每个组有若干consumer组成,这其实就是一种发布-订阅模式,只不过订阅者是个组而不是单个的consumer。
由两个机器组成的集群有4个分区(p0-p3)以及两个consumer组。A组有2个consumer,B组有4个consumer。
相比于传统的消息系统,kafka可以很好的保证有序性:传统的队列在服务器上保存有序的消息,如果有多个consumers同时从这个服务器上消费消息,那么服务器就会以消息存储的顺序向consumer分发消息。虽然服务器按顺序发布消息,但是消息被异步的分发到各个consumers上,所以当消息到达的时候可能已经失去了原来的顺序,这意味着并发消息将会导致顺序发生错乱。为了避免故障,这样的消息系统通常会使用"专用consumer"的概念,其实就是只允许一个消费者消费消息,当然这也意味着失去了消息的并发性。
在这方面kafka做的更好,通过分区的概念,Kafka可以在多个consumer组并发的情况下提供较好的有序性和负载均衡。因为有多个分区,依然可以在多个consumer组之间进行负载均衡。这个地方要注意:consumer组的数量不能多于分区的数量,也就是有多少分区就会有躲闪的并发消费者。
kafka只能保证在一个分区之内的消息有序性,在不同的分区之间是不可以的,这已经可以满足大部分的应用需求,如果需要topic中所有消息的有序性,那就只能让这个topic只有一个分区,当然只有一个consumer来消费它。
二、环境的搭建
-----------------------------------------------
1.下载kafka
tar -xzf kafka_2.9.2-0.8.1.1.tgz
cd kafka_2.9.2-0.8.1.1
2.启动服务:kafka用到了zookeeper,所有首先要启动zookeeper,下面简单的启动一个zookeeper服务。可以在命令的结尾加上一个&符号,这样就可以在启动后离开控制台。
>bin/zookeeper-server-start.sh config/zookeeper.properties &
3.启动kafka
bin/kafka-server-start.sh config/server.properties
[-- ::,] INFO Verifying properties (kafka.utils.VerifiableProperties)
[-- ::,] INFO Property socket.send.buffer.bytes is overridden to (kafka.utils.VerifiableProperties)
...
3.创建topic:创建一个叫做"test"的topic,只有一个分区,一个副本
bin/kafka-topics.sh --create --zookeeper localhost: --replication-factor --partitions --topic test
删除主题:
bin/kafka-topics.sh --zookeeper s202: --delete --topic test
kafka容错演示:
4.通过list命令查看创建的topic:
bin/kafka-topics.sh --list --zookeeper localhost:2181 //除了手动创建topic,还可以配置broker让它自动创建topic.
bin/kafka-topics.sh --zookeeper s202: --replication-factor --partitions --create --topic test2 //创建主题,指定主题个数和分区数
5.发送消息.:Kafka 使用一个简单的命令行producer,从文件中或者从标准输入中读取消息并发送到服务端。默认的每条命令将发送一条消息。kafka生产者不会连接到zk集群上去
运行producer并在控制台中输一些消息,这些消息将被发送到服务端:
bin/kafka-console-producer.sh --broker-list localhost: --topic test
6.启动consumer:Kafka也有一个命令行consumer可以读取消息并输出到标准输出
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topictest--from-beginning你在一个终端中运行consumer命令行,另一个终端中运行producer命令行,就可以在一个终端输入消息,另一个终端读取消息。这两个命令都有自己的可选参数,可以在运行的时候不加任何参数可以看到帮助信息。
7.搭建一个多个broker的集群。刚才只是启动了单个broker,现在启动有3个broker组成的集群,这些broker节点也都是在本机上的:首先为每个节点编写配置文件:
cp config/server.properties config/server-.properties
> cp config/server.properties config/server-.properties
在拷贝出的新文件中添加以下参数:
config/server-.properties:
broker.id=
port=
log.dir=/tmp/kafka-logs-
config/server-.properties:
broker.id=
port=
log.dir=/tmp/kafka-logs-
broker.id在集群中唯一的标注一个节点,因为在同一个机器上,所以必须制定不同的端口和日志文件,避免数据被覆盖。
We already have Zookeeper and our single node started, so we just need to start the two new nodes:
刚才已经启动可Zookeeper和一个节点,现在启动另外两个节点:
bin/kafka-server-start.sh config/server-.properties &
...
> bin/kafka-server-start.sh config/server-.properties &
8.现在我们搭建了一个集群,怎么知道每个节点的信息呢?运行“"describe topics”命令就可以了:
bin/kafka-topics.sh --describe --zookeeper localhost: --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount: ReplicationFactor: Configs:
Topic: my-replicated-topic Partition: Leader: Replicas: ,, Isr: ,,
下面解释一下这些输出。第一行是对所有分区的一个描述,然后每个分区都会对应一行,因为我们只有一个分区所以下面就只加了一行。
leader:负责处理消息的读和写,leader是从所有节点中随机选择的.
replicas:列出了所有的副本节点,不管节点是否在服务中.
isr:是正在服务中的节点.
在我们的例子中,节点1是作为leader运行。
向topic发送消息:
> bin/kafka-console-producer.sh --broker-list localhost: --topic my-replicated-topic
my test message 1my test message ^C
kafka复习(2)的更多相关文章
- kafka复习(1)
一:flume复习 0.JMS(java message service )java消息服务 ----------------------------------------------------- ...
- [CDH] Acquire data: Flume and Kafka
Flume 基本概念 一.是什么 Ref: http://flume.apache.org/ 数据源获取:Flume.Google Refine.Needlebase.ScraperWiki.Bloo ...
- JAVA复习笔记分布式篇:kafka
前言:第一次使用消息队列是在实在前年的时候,那时候还不了解kafka,用的是阿里的rocket_mq,当时觉得挺好用的,后来听原阿里的同事说rocket_mq是他们看来kafka的源码后自己开发了一套 ...
- 【原创】kafka producer源代码分析
Kafka 0.8.2引入了一个用Java写的producer.下一个版本还会引入一个对等的Java版本的consumer.新的API旨在取代老的使用Scala编写的客户端API,但为了兼容性 ...
- Kafka学习之路
一直在思考写一些什么东西作为2017年开篇博客.突然看到一篇<Kafka学习之路>的博文,觉得十分应景,于是决定搬来这“他山之石”.虽然对于Kafka博客我一向坚持原创,不过这篇来自Con ...
- 051 Kafka的安装
后来重新复习的时候,发现这篇文章不错:https://www.cnblogs.com/z-sm/p/5691760.html 一:前提 1.安装条件 Java Scala zookeeper Ka ...
- Kafka基础系列第1讲:Kafka的诞生背景及应用
Kafka 是由 LinkedIn 开发的一个分布式的消息系统,使用 Scala 编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如 Cloudera.Apache Sto ...
- Kafka消息存储原理
kafka消息存储机制 (一)关键术语 复习一下几个基本概念,详见上面的基础知识文章. Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker能够组成一个Kafka ...
- 大数据入门第二十四天——SparkStreaming(二)与flume、kafka整合
前一篇中数据源采用的是从一个socket中拿数据,有点属于“旁门左道”,正经的是从kafka等消息队列中拿数据! 主要支持的source,由官网得知如下: 获取数据的形式包括推送push和拉取pull ...
随机推荐
- windows 全局安装 express 但无法命令行执行
从 express 的官网直接按照命令行全局安装 express 后, express 命令无法执行, 在 cmd 中显示 该命令行无法识别.基本可判断是 环境变量配置 这边没有搞定. 1. 卸载 n ...
- 通过PPA存储库在UBUNTU或LINUX MINT中安装ORACLE JAVA 8 [JDK8]
http://www.webupd8.org/2012/09/install-oracle-java-8-in-ubuntu-via-ppa.html sudo add-apt-repository ...
- Springboot 构建http服务,返回的http行是'HTTP/1.1 200' 无状态码描述 客户端解析错误
————————————————————————————————————————— *** 响应的数据格式 HTTP/1.1 200 OK Server: Apache-Coyote/1.1 A ...
- BZOJ 3203 Luogu P3299 [SDOI2013]保护出题人 (凸包、斜率优化、二分)
惊了,我怎么这么菜啊.. 题目链接: (bzoj)https://www.lydsy.com/JudgeOnline/problem.php?id=3203 (luogu)https://www.lu ...
- es之路由:进一步提高Elasticsearch的检索效率(适用大规模数据集)
1:一条数据是如何落地到对应的shard上的 当索引一个文档的时候,文档会被存储到一个主分片中. Elasticsearch 如何知道一个文档应该存放到哪个分片中呢? 首先这肯定不会是随机的,否则将来 ...
- HTTP访问控制(CORS)踩坑小记
前几天在帮后端排查一个cors的问题的时候发现的一些小坑特此记录 ** cors的本质是出于安全原因,浏览器限制从脚本内发起的跨源HTTP请求. 例如,XMLHttpRequest和FetchAPI遵 ...
- JavaScript DOM位置尺寸API
我们需要了解几个基础概念,每个HTML元素都有下列属性 offsetWidth clientWidth scrollWidth offsetHeight clientHeight scrollHeig ...
- json根据一个值返回对象,filter方法使用
d = { "student":[ { "count":1000, "stuList":[ ...
- Html/CSS 初步介绍html和css部分重要标签
&初步介绍html和css部分重要标签& 注:开头书写:<!DOCTYPE html>表明对应标准html代码 先行总结重点 下方给出具体 CSS: 1. position ...
- 九:flask-response响应
1.如果返回的是个合法的响应对象,则直接返回 同时,也可以在response里面做一些操作,比如增加cookie 2.如果返回的是一个字符串,那么flask会重新创建一个werkzeug,wrappe ...