小白如何入门 Python 爬虫?
本文针对初学者,我会用最简单的案例告诉你如何入门python爬虫!
想要入门Python 爬虫首先需要解决四个问题
- 熟悉python编程
- 了解HTML
- 了解网络爬虫的基本原理
- 学习使用python爬虫库
一、你应该知道什么是爬虫?
网络爬虫,其实叫作网络数据采集更容易理解。
就是通过编程向网络服务器请求数据(HTML表单),然后解析HTML,提取出自己想要的数据。
归纳为四大步:
- 根据url获取HTML数据
- 解析HTML,获取目标信息
- 存储数据
- 重复第一步
这会涉及到数据库、网络服务器、HTTP协议、HTML、数据科学、网络安全、图像处理等非常多的内容。但对于初学者而言,并不需要掌握这么多。
二、python要学习到什么程度
如果你不懂python,那么需要先学习python这门非常easy的语言(相对其它语言而言)。
编程语言基础语法无非是数据类型、数据结构、运算符、逻辑结构、函数、文件IO、错误处理这些,学起来会显枯燥但并不难。
刚开始入门爬虫,你甚至不需要去学习python的类、多线程、模块之类的略难内容。找一个面向初学者的教材或者网络教程,花个十几天功夫,就能对python基础有个三四分的认识了,这时候你可以玩玩爬虫喽!
当然,前提是你必须在这十几天里认真敲代码,反复咀嚼语法逻辑,比如列表、字典、字符串、if语句、for循环等最核心的东西都得捻熟于心、于手。
教材方面比较多选择,我个人是比较推荐python官方文档以及python简明教程,前者比较系统丰富、后者会更简练。
三、为什么要懂HTML
前面说到过爬虫要爬取的数据藏在网页里面的HTML里面的数据,有点绕哈!
维基百科是这样解释HTML的:
超文本标记语言(英语:HyperTextMarkupLanguage,简称:HTML)是一种用于创建网页的标准标记语言。
HTML是一种基础技术,常与CSS、JavaScript一起被众多网站用于设计网页、网页应用程序以及移动应用程序的用户界面[3]。网页浏览器可以读取HTML文件,并将其渲染成可视化网页。
HTML描述了一个网站的结构语义随着线索的呈现,使之成为一种标记语言而非编程语言。
总结一下,HTML是一种用于创建网页的标记语言,里面嵌入了文本、图像等数据,可以被浏览器读取,并渲染成我们看到的网页样子。
所以我们才会从先爬取HTML,再 解析数据,因为数据藏在HTML里。
学习HTML并不难,它并不是编程语言,你只需要熟悉它的标记规则,这里大致讲一下。
HTML标记包含标签(及其属性)、基于字符的数据类型、字符引用和实体引用等几个关键部分。
HTML标签是最常见的,通常成对出现,比如<h1>与</h1>。
这些成对出现的标签中,第一个标签是开始标签,第二个标签是结束标签。两个标签之间为元素的内容(文本、图像等),有些标签没有内容,为空元素,如<img>。
以下是一个经典的Hello World程序的例子:
<!DOCTYPE html>
<html>
<head>
<title>This is a title</title>
</head>
<body>
<p>Hello world!</p>
</body>
</html>
HTML文档由嵌套的HTML元素构成。它们用HTML标签表示,包含于尖括号中,如<p>
在一般情况下,一个元素由一对标签表示:“开始标签”<p>与“结束标签”</p>。元素如果含有文本内容,就被放置在这些标签之间。
四、了解python网络爬虫的基本原理
在编写python爬虫程序时,只需要做以下两件事:
- 发送GET请求,获取HTML
- 解析HTML,获取数据
这两件事,python都有相应的库帮你去做,你只需要知道如何去用它们就可以了。
首先,发送HTML数据请求可以使用python内置库urllib,该库有一个urlopen函数,可以根据url获取HTML文件,这里尝试获取百度首页“https://www.baidu.com/”的HTML内容
# 导入urllib库的urlopen函数
from urllib.request import urlopen
# 发出请求,获取html
html = urlopen("https://www.baidu.com/")
# 获取的html内容是字节,将其转化为字符串
html_text = bytes.decode(html.read())
# 打印html内容
print(html_text)
看看效果:

我们看一下真正百度首页html是什么样的
如果你用的是谷歌浏览器,在百度主页打开设置>更多工具>开发者工具,点击element,就可以看到了:

对比一下你就会知道,刚才通过python程序获取到的HTML和网页中的一样!
获取了HTML之后,接下就要解析HTML了,因为你想要的文本、图片、视频都藏在HTML里,你需要通过某种手段提取需要的数据。
python同样提供了非常多且强大的库来帮助你解析HTML,这里以著名的python库BeautifulSoup为工具来解析上面已经获取的HTML。
BeautifulSoup是第三方库,需要安装使用。在命令行用pip安装就可以了:
pip install bs4
BeautifulSoup会将HTML内容转换成结构化内容,你只要从结构化标签里面提取数据就OK了:

比如,我想获取百度首页的标题“百度一下,我就知道”,怎么办呢?
这个标题是被两个标签套住的,一个是一级标签<head><head>,另一个是二级标签<title><title>,所以只要从标签中取出信息就可以了

# 导入urlopen函数
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 打印标题
print(title)
看看结果:
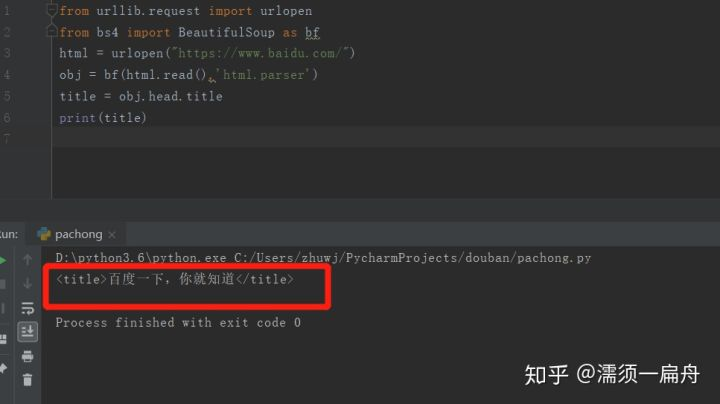
这样就搞定了,成功提取出百度首页的标题。
如果我想要下载百度首页logo图片呢?
第一步先获取该网页所有图片标签和url,这个可以使用BeautifulSoup的findAll方法,它可以提取包含在标签里的信息。
一般来说,HTML里所有图片信息会在“img”标签里,所以我们通过findAll("img")就可以获取到所有图片的信息了。
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 使用find_all函数获取所有图片的信息
pic_info = obj.find_all('img')
# 分别打印每个图片的信息
for i in pic_info:
print(i)
看看结果:
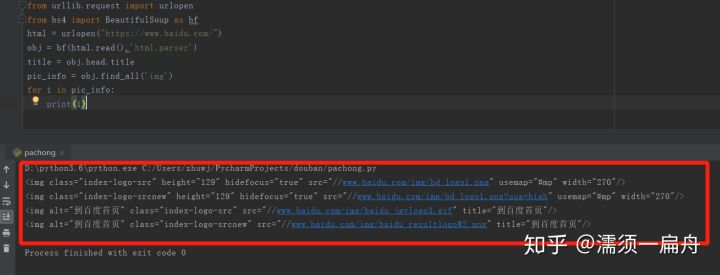
打印出了所有图片的属性,包括class(元素类名)、src(链接地址)、长宽高等。
其中有百度首页logo的图片,该图片的class(元素类名)是index-logo-src。

[<img class="index-logo-src" height="129" hidefocus="true" src="//www.baidu.com/img/bd_logo1.png" usemap="#mp" width="270"/>, <img alt="到百度首页" class="index-logo-src" src="//www.baidu.com/img/baidu_jgylogo3.gif" title="到百度首页"/>]
可以看到图片的链接地址在src这个属性里,我们要获取图片链接地址:
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 打印链接
print(logo_url)
结果:

获取地址后,就可以用urllib.urlretrieve函数下载logo图片了
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 导入urlretrieve函数,用于下载图片
from urllib.request import urlretrieve
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 使用urlretrieve下载图片
urlretrieve(logo_url, 'logo.png')
最终图片保存在'logo.png'

六、结语
本文用爬取百度首页标题和logo图片的案例,讲解了python爬虫的基本原理以及相关python库的使用,这是比较初级的爬虫知识,还有很多优秀的python爬虫库和框架等待后续去学习。
当然,掌握本文讲的知识点,你就已经入门python爬虫了。加油吧,少年!
小白如何入门 Python 爬虫?的更多相关文章
- 从零起步 系统入门Python爬虫工程师
从零起步 系统入门Python爬虫工程师 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大家看的 ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
- 从零起步 系统入门Python爬虫工程师 ✌✌
从零起步 系统入门Python爬虫工程师 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 大数据时代,python爬虫工程师人才猛增,本课程专为爬虫工程师打造, ...
- 从零起步 系统入门Python爬虫工程师✍✍✍
从零起步 系统入门Python爬虫工程师 爬虫(又被称为网页蜘蛛,网络机器人)就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序. 原则上,只要是浏览器(客户端) ...
- 一个月入门Python爬虫,轻松爬取大规模数据
Python爬虫为什么受欢迎 如果你仔细观察,就不难发现,懂爬虫.学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得 ...
- (转)如何入门 Python 爬虫
“入门”是良好的动机,但是可能作用缓慢.如果你手里或者脑子里有一个项目,那么实践起来你会被目标驱动,而不会像学习模块一样慢慢学习. 另外如果说知识体系里的每一个知识点是图里的点,依赖关系是边的话,那么 ...
- 如何入门 Python 爬虫?
作者:谢科 来源:知乎链接:https://www.zhihu.com/question/20899988/answer/24923424 著作权归作者所有.商业转载请联系作者获得授权,非商业转载 ...
- 零基础入门python爬虫(一)
✍写在前面: 欢迎加入纯干货技术交流群Disaster Army:317784952 接到5月25日之前要交稿的任务我就一门心思想写一篇爬虫入门的文章,可是我并不会.还好有将近一个月的时间去学习,于是 ...
- 职场老鸟,一文教你如何正确入门Python爬虫!
爬虫现在的火热程度我就不说了,先说一下这门技术能干什么事儿,主要为以下三方面: 1.爬取数据,进行市场调研和商业分析 爬取知乎.豆瓣等网站的优质话题内容:抓取房产网站买卖信息,分析房价变化趋势.做不同 ...
随机推荐
- linux常用的镜像(centos、kali、redhat等)官方下载地址
常用的linux版本: Redhat:https://developers.redhat.com/topics/linux/ Centos:https://www.centos.org/downloa ...
- 浅谈Vue中Slot以及slot-scope
vue中关于插槽的文档说明很短,语言又写的很凝练,再加上其和methods,data,computed等常用选项使用频率.使用先后上的差别,这就有可能造成初次接触插槽的开发者容易产生“算了吧,回头再学 ...
- Markers
immune pdf(file = paste0(outdir,"T_B_NK_feature.pdf")) VlnPlot(expr_1_4,features = c(" ...
- js控制手机保持亮屏的库,解决h5移动端,自动息屏问题
一些说明:我用Laya(ts)开发小游戏,有需要保持手机屏幕常亮的需求(非必须的),然后作为小白的我就在网上找到了这个库,大概了解下,应该是通过播放空视频的原理来保持手机屏幕常亮,然后就放到项目中试了 ...
- maven 配置私服 连接
两种方法: 1.在单个项目的pom.xml中使用 私服的连接地址,这样只对该项目起作用. 2.在maven的setting.xml配置中添加私服的连接地址.这样对所有项目起作用. 本文章只演示第二种方 ...
- JDK中String类的源码分析(二)
1.startsWith(String prefix, int toffset)方法 包括startsWith(*),endsWith(*)方法,都是调用上述一个方法 public boolean s ...
- 第四周实验总结&实验报告
实验二 Java简单类与对象 实验目的 掌握类的定义,熟悉属性.构造函数.方法的作用,掌握用类作为类型声明变量和方法返回值: 理解类和对象的区别,掌握构造函数的使用,熟悉通过对象名引用实例的方法和属性 ...
- 在配置em时运到报错ORACLE_UNQNAME not defined
Oracle 11G R2 RAC 配置em时报错 Environment variable ORACLE_UNQNAME not defined. oracle ORACLE_UNQNAME 借楼主 ...
- 为什么在vmware中不能使用ctrl+alt+F1~6切换到字符控制台
为什么在vmware中不能使用ctrl+alt+F1~6切换到字符控制台 是因为vmware虚拟机的快捷键: ctrl+alt也用到了 因为vmware本身的hot keys也用到了ctrl+alt: ...
- 【mysql】查询最新的10条记录
实现查询最新10条数据方法: select * from 表名 order by id(主键) desc limit 10 参考文档: MySQL查询后10条数据并顺序输出