Yarn 工作机制
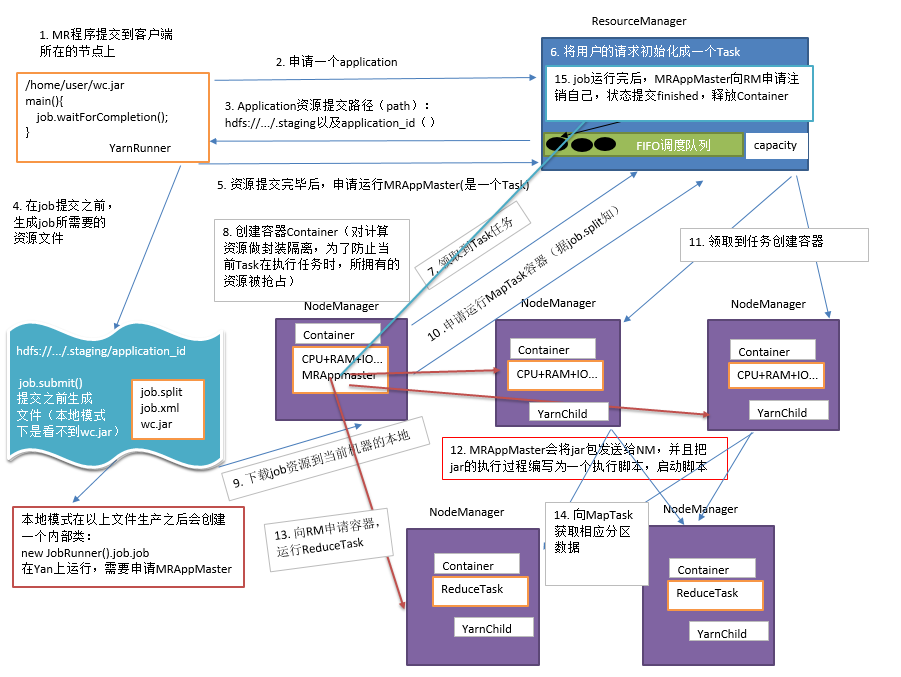
1、工作机制详述
(1)MR程序提交到客户端所在的节点。
(2)YarnRunner向ResourceManager申请一个Application。
(3)RM将该应用程序的资源路径返回给YarnRunner。
(4)该程序将运行所需资源提交到HDFS上。
(5)程序资源提交完毕后,申请运行mrAppMaster。
(6)RM将用户的请求初始化成一个Task。
(7)其中一个NodeManager领取到Task任务。
(8)该NodeManager创建容器Container,并产生MRAppmaster。
(9)Container从HDFS上拷贝资源到本地。
(10)MRAppmaster向RM 申请运行MapTask资源。
(11)RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
(12)MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
(13)MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
(14)ReduceTask向MapTask获取相应分区的数据。
(15)程序运行完毕后,MR会向RM申请注销自己。
2、作业提交详述
(1)作业提交
第1步:Client调用job.waitForCompletion方法,向整个集群提交MapReduce作业。
第2步:Client向RM申请一个作业id。
第3步:RM给Client返回该job资源的提交路径和作业id。
第4步:Client提交jar包、切片信息和配置文件到指定的资源提交路径。
第5步:Client提交完资源后,向RM申请运行MrAppMaster。
(2)作业初始化
第6步:当RM收到Client的请求后,将该job添加到容量调度器中。
第7步:某一个空闲的NM领取到该Job。
第8步:该NM创建Container,并产生MRAppmaster。
第9步:下载Client提交的资源到本地。
(3)任务分配
第10步:MrAppMaster向RM申请运行多个MapTask任务资源。
第11步:RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
(4)任务运行
第12步:MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
第13步:MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
第14步:ReduceTask向MapTask获取相应分区的数据。
第15步:程序运行完毕后,MR会向RM申请注销自己。
(5)进度和状态更新
YARN中的任务将其进度和状态(包括counter)返回给应用管理器, 客户端每秒(通过mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新, 展示给用户。
(6)作业完成
除了向应用管理器请求作业进度外, 客户端每5分钟都会通过调用waitForCompletion()来检查作业是否完成。
时间间隔可以通过mapreduce.client.completion.pollinterval来设置。
作业完成之后, 应用管理器和Container会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查。
Yarn 工作机制的更多相关文章
- Yarn工作机制
概述 (0)Mr 程序提交到客户端所在的节点. (1)Yarnrunner 向 Resourcemanager 申请一个 Application. (2)rm将该应用程序的资源路径和Applicati ...
- MapRdeuce&Yarn的工作机制(YarnChild是什么)
MapRdeuce&Yarn的工作机制 一幅图解决你所有的困惑 那天在集群中跑一个MapReduce的程序时,在机器上jps了一下发现了每台机器中有好多个YarnChild.困惑什么时Yarn ...
- Spark工作机制简述
Spark工作机制 主要模块 调度与任务分配 I/O模块 通信控制模块 容错模块 Shuffle模块 调度层次 应用 作业 Stage Task 调度算法 FIFO FAIR(公平调度) Spark应 ...
- MapReduce工作机制——Word Count实例(一)
MapReduce工作机制--Word Count实例(一) MapReduce的思想是分布式计算,也就是分而治之,并行计算提高速度. 编程思想 首先,要将数据抽象为键值对的形式,map函数输入键值对 ...
- Hadoop的namenode的管理机制,工作机制和datanode的工作原理
HDFS前言: 1) 设计思想 分而治之:将大文件.大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析: 2)在大数据系统中作用: 为各类分布式运算框架(如:mapr ...
- Hadoop yarn工作流程详解
yarn是什么?1.它是一个资源调度及提供作业运行的系统环境平台 资源:cpu.mem等 作业:map task.reduce Task yarn产生背景?它是从hadoop2.x版本才引入1.had ...
- MapReduce的工作机制
<Hadoop权威指南>中的MapReduce工作机制和Shuffle: 框架 Hadoop2.x引入了一种新的执行机制MapRedcue 2.这种新的机制建议在Yarn的系统上,目前用于 ...
- [hadoop读书笔记] 第五章 MapReduce工作机制
P205 MapReduce的两种运行机制 第一种:经典的MR运行机制 - MR 1 可以通过一个简单的方法调用来运行MR作业:Job对象上的submit().也可以调用waitForCompleti ...
- MapReduce1 工作机制
本文转自:Hadoop MapReduce 工作机制 工作流程 作业配置 作业提交 作业初始化 作业分配 作业执行 进度和状态更新 作业完成 错误处理 作业调度 shule(mapreduce核心)和 ...
随机推荐
- index 索引
1.创建表 drop table if exists kg_fk_user;create table kg_fk_user(id int,name string)row format delimite ...
- C\C++下获取系统进程或线程ID(转)
在程序开发时有时需要获取线程和进程ID以分析程序运行 ()windows下获取进程或线程ID 通过调用系统提供的GetCurProcessId或GetNowThreadID来获取当前程序代码运行时的进 ...
- HDU-6278-Jsut$h$-index(主席树)
链接: https://vjudge.net/problem/HDU-6278 题意: The h-index of an author is the largest h where he has a ...
- Chrome设置--disable-web-security解决跨域问题
这里介绍的是--disable-web-security参数.这个参数可以降低chrome浏览器的安全性,禁用同源策略,利于开发人员本地调试. (1)新建一个chrome快捷方式,右键“属性”,“快捷 ...
- Top 8 Diagrams for Understanding Java
Reference: http://www.programcreek.com/2013/09/top-8-diagrams-for-understanding-java/ A diagram is s ...
- 打包组件assembly之package.xml
形如: <assembly> <id>deploy</id> <formats> <format>zip</format> &l ...
- Floyd求解最短路
Floyd算法适用于求解全源最短路.也就是能够求解任意两点间的最短路径并且是适用于含有负权边的图,但是含有负环则不行了!空间复杂度为O(n2).时间复杂度为O(n3).其具体的原理在百度能够找到很多, ...
- 使用visual studio配置和运行《opengl圣经》的第一个案例
对vc++新手来说,想把opengl圣经里的教学案例运行起来还真不是一件容易的事情,而且并没有完整的操作流程教学,这里就总结一下吧: 先安装cmake,用于生成vs的工程文件,安装过程中选中“将目录添 ...
- document.referer
参考文章: 深入理解document.referrer的用法
- Qualcomm 8X camera过程解析【转】
本文转载自:http://blog.csdn.net/gabbzang/article/details/19906687 http://www.01yun.com/mobile_development ...