java输入输出 -- java NIO之缓存区Buffer
一、简介
java NIO相关类在jdk1.4被引入,用于提高I/O的效率。java NIO包含很多东西,但核心的东西不外乎Buffer、channel和selector。本文先来看Buffer的实现。
二、继承体系
Buffer 的继承类比较多,用于存储各种类型的数据。包括 ByteBuffer、CharBuffer、IntBuffer、FloatBuffer 等等。这其中,ByteBuffer 最为常用。所以接下来将会主要分析 ByteBuffer 的实现。Buffer 的继承体系图如下:

其实核心是第一个的ByteBuffer,后面的一串类只是包装了一下它而已,我们使用最多的通常也是 ByteBuffer。
我们应该将 Buffer 理解为一个数组,IntBuffer、CharBuffer、DoubleBuffer 等分别对应 int[]、char[]、double[] 等。
MappedByteBuffer 用于实现内存映射文件,也不是本文关注的重点
三、源码
1.属性及相关操作
Buffer 本质就是一个数组,只不过在数组的基础上进行适当的封装,方便使用。 Buffer 中有几个重要的属性,通过这几个属性来显示数据存储的信息。
这个属性分别是:
1. capacity 容量:Buffer 所能容纳数据元素的最大数量,也就是底层数组的容量值。在创建时被指定,不可更改。
2. position 位置:下一个被读或被写的位置
3. limit 上届:可供读写的最大位置,用于限制position,position < limit
4. mark 标记:位置标记,用于记录某一次的读写位置,可以通过reset重新回到这个位置。
2. ByteBuffer 初始化
ByteBuffer 可通过 allocate、allocateDirect 和 wrap 等方法初始化,这里以 allocate 为例:
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
HeapByteBuffer(int cap, int lim) {
super(-1, 0, lim, cap, new byte[cap], 0);
}
ByteBuffer(int mark, int pos, int lim, int cap, byte[] hb, int offset) {
super(mark, pos, lim, cap);
this.hb = hb;
this.offset = offset;
}
上面是 allocate 创建 ByteBuffer 的过程,ByteBuffer 是抽象类,所以实际上创建的是其子类 HeapByteBuffer。HeapByteBuffer 在构造方法里调用父类构造方法,将一些参数值传递给父类。
最后父类再做一次中转,相关参数最终被传送到 Buffer 的构造方法中了。我们再来看一下 Buffer 的源码:
public abstract class Buffer {
// Invariants: mark <= position <= limit <= capacity
private int mark = -1;
private int position = 0;
private int limit;
private int capacity;
Buffer(int mark, int pos, int lim, int cap) { // package-private
if (cap < 0)
throw new IllegalArgumentException("Negative capacity: " + cap);
this.capacity = cap;
limit(lim);
position(pos);
if (mark >= 0) {
if (mark > pos)
throw new IllegalArgumentException("mark > position: ("
+ mark + " > " + pos + ")");
this.mark = mark;
}
}
}
Buffer 创建完成后,底层数组的结构信息如下:

上面的几个属性作为公共属性,被放在了 Buffer 中,相关的操作方法也是封装在 Buffer 中。那么接下来,我们来看看这些方法吧。
3. ByteBuffer 读写操作
ByteBuffer 读写操作时通过 get 和 put 完成的,这两个方法都有重载,这些方法是在子类中HeapByteBuffer实现我们只看其中一个。
// 读操作
public byte get() {
return hb[ix(nextGetIndex())];
} final int nextGetIndex() {
if (position >= limit)
throw new BufferUnderflowException();
return position++;
} // 写操作
public ByteBuffer put(byte x) {
hb[ix(nextPutIndex())] = x;
return this;
} final int nextPutIndex() {
if (position >= limit)
throw new BufferOverflowException();
return position++;
}
读写操作都会修改 position 的值,每次读写的位置是当前 position 的下一个位置。通过修改 position,我们可以读取指定位置的数据。当然,前提是 position < limit。
Buffer 中提供了position(int) 方法用于修改 position 的值。
public final Buffer position(int newPosition) {
if ((newPosition > limit) || (newPosition < 0))
throw new IllegalArgumentException();
position = newPosition;
if (mark > position) mark = -1;
return this;
}
当我们向一个刚初始化好的 Buffer 中写入一些数据时,数据存储示意图如下:
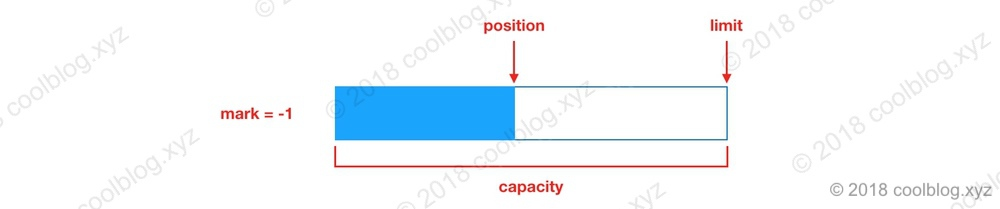
如果读取里面的数据,就需要修改 position 的值。将 position 设置为 0,这样就能从头读取刚刚写入的数据。
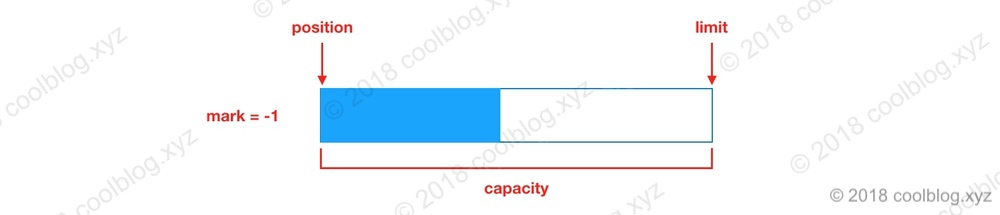
仅修改 position 的值是不够的,如果想正确读取刚刚写入的数据,还需修改 limit 的值,不然还是会读取到空白空间上的内容。
我们将 limit 指向数据区域的尾部,即可避免这个问题。修改 limit 的值通过 limit(int) 方法进行。
public final Buffer limit(int newLimit) {
if ((newLimit > capacity) || (newLimit < 0))
throw new IllegalArgumentException();
limit = newLimit;
if (position > limit) position = limit;
if (mark > limit) mark = -1;
return this;
}
修改后,数据存储示意图如下:
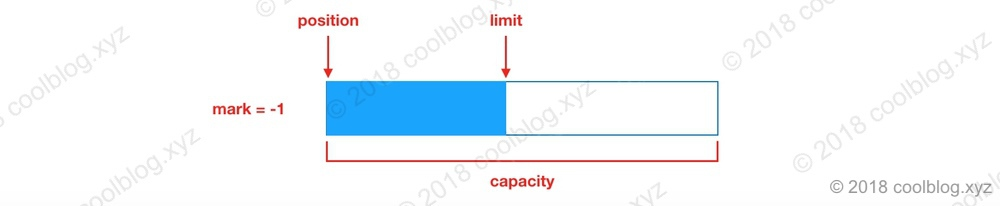
上面为了正确读取写入的数据,需要两步操作。Buffer 中提供了一个便利的方法,将这两步操作合二为一,即 flip 方法。
public final Buffer flip() {
// 1. 设置 limit 为当前位置
limit = position;
// 1. 设置 position 为0
position = 0;
mark = -1;
return this;
}
4.ByteBuffer 标记
我们在读取或写入的过程中,可以在感兴趣的位置打上一个标记,这样我们可以通过这个标记再次回到这个位置。
Buffer 中,打标记的方法是 mark,回到标记位置的方法时 reset。简单看下源码吧。
public final Buffer mark() {
mark = position;
return this;
}
public final Buffer reset() {
int m = mark;
if (m < 0)
throw new InvalidMarkException();
position = m;
return this;
}
打标记及回到标记位置的流程如下:
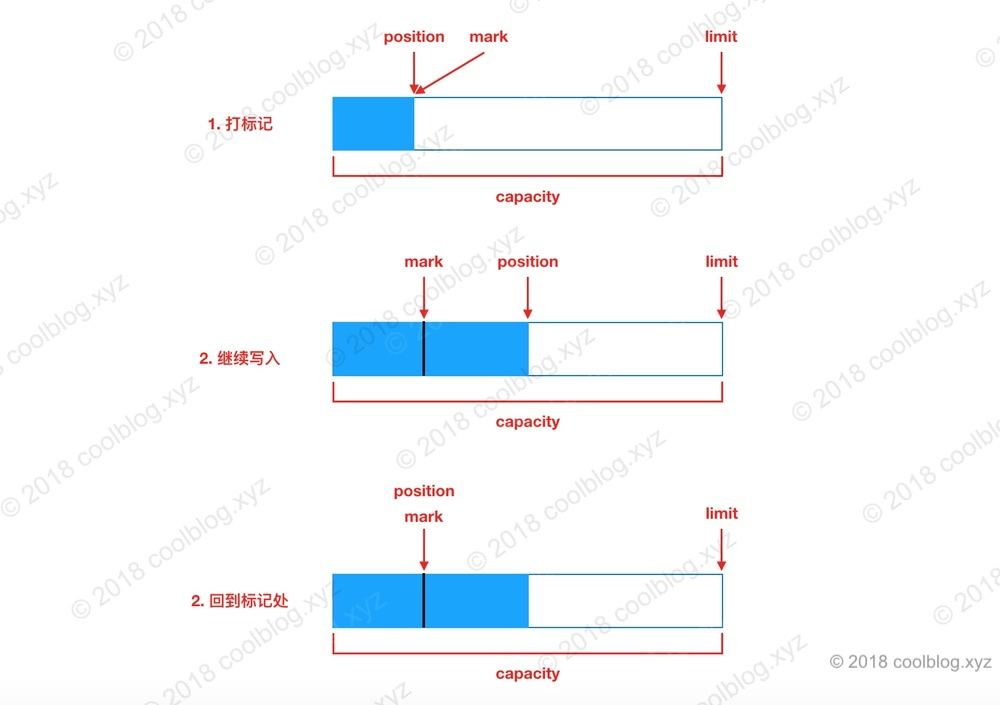
四、子类实现简单分析
它的子类实现,主要是HeapByteBuffer和DirectByteBuffer。
HeapByteBuffer
ByteBuffer 的 allocate 方法,该方法实际上创建的是 HeapByteBuffer 对象。
HeapByteBuffer顾名思义就是JVM堆上的字节缓冲区,他用于缓存数据的byte数组就是直接在堆内申请的。默认的构造方法直接就是new一个byte数组作为数据存储的缓冲区。
DirectByteBuffer
ByteBuffer 还有一个方法 allocateDirect。这个方法创建的是 DirectByteBuffer 对象。DirectByteBuffer翻译过来就是直接的字节缓冲区,它是使用直接内存的,即不从JVM的堆上分配内存。
那堆空间和直接内存在使用上有什么不同呢?用一个表格列举一下吧。
| 空间类型 | 优点 | 缺点 |
|---|---|---|
| 堆内空间 | 分配速度快 | JVM 整理内存空间时,堆内空间的位置会被搬动,比较笨重 |
| 堆外空间 | 1. 空间位置固定,不用担心空间被 JVM 随意搬动 2. 降低堆内空间的使用率 |
1. 分配速度慢 2. 回收策略比较复杂 |
五、总结
Buffer 是 Java NIO 中一个重要的辅助类,使用比较频繁。在不熟悉 Buffer 的情况下,有时候很容易因为忘记调用 flip 或其他方法导致程序出错。
不过好在 Buffer 的源码不难理解,大家可以自己看看,这样可以避免出现一些奇怪的错误。
感谢:http://www.tianxiaobo.com/2018/03/04/Java-NIO%E4%B9%8B%E7%BC%93%E5%86%B2%E5%8C%BA/
java输入输出 -- java NIO之缓存区Buffer的更多相关文章
- Java NIO------基础理论之缓存区
1.概述:NIO我的理解就是 New IO,是API1.4里提供的新的API,为所有的原始类型做缓存支持. NIO主要的核心组成部分: Buffer(缓存) Channels(通道) Selector ...
- java输入输出 -- java NIO之文件通道
一.简介 通道是 Java NIO 的核心内容之一,在使用上,通道需和缓存类(ByteBuffer)配合完成读写等操作.与传统的流式 IO 中数据单向流动不同,通道中的数据可以双向流动.通道既可以读, ...
- java输入输出 -- Java NIO之选择器
一.简介 前面的文章说了缓冲区,说了通道,本文就来说说 NIO 中另一个重要的实现,即选择器 Selector.在更早的文章中,我简述了几种 IO 模型.如果大家看过之前的文章,并动手写过代码的话.再 ...
- java输入输出 -- Java NIO之套接字通道
一.简介 前面一篇文章讲了文件通道,本文继续来说说另一种类型的通道 – 套接字通道.在展开说明之前,咱们先来聊聊套接字的由来.套接字即 socket,最早由伯克利大学的研究人员开发,所以经常被称为Be ...
- 深入理解JAVA中的NIO
前言: 传统的 IO 流还是有很多缺陷的,尤其它的阻塞性加上磁盘读写本来就慢,会导致 CPU 使用效率大大降低. 所以,jdk 1.4 发布了 NIO 包,NIO 的文件读写设计颠覆了传统 IO 的设 ...
- NIO入门之缓冲区Buffer
缓存区 Buffer 是数据容器 ByteBuffer 可以存储除了 boolean 以外的其他 7 种Java基本数据类型,如 getInt.putInt Buffer 是抽象类,它有除了 Bool ...
- Java IO(3)非阻塞式输入输出(NIO)
在上篇<Java IO(2)阻塞式输入输出(BIO)>的末尾谈到了什么是阻塞式输入输出,通过Socket编程对其有了大致了解.现在再重新回顾梳理一下,对于只有一个“客户端”和一个“服务器端 ...
- Java性能优化之使用NIO提升性能(Buffer和Channel)
在软件系统中,由于IO的速度要比内存慢,因此,I/O读写在很多场合都会成为系统的瓶颈.提升I/O速度,对提升系统整体性能有着很大的好处. 在Java的标准I/O中,提供了基于流的I/O实现,即Inpu ...
- Java NIO中的缓冲区Buffer(二)创建/复制缓冲区
创建缓冲区的方式 主要有以下两种方式创建缓冲区: 1.调用allocate方法 2.调用wrap方法 我们将以charBuffer为例,阐述各个方法的含义: allocate方法创建缓冲区 调用all ...
随机推荐
- Luogu4688 [Ynoi2016]掉进兔子洞 【莫队,bitset】
题目链接:洛谷 我们知道要求的是\([l_1,r_1],[l_2,r_2],[l_3,r_3]\)的可重集取交的大小,肯定是要用bitset的,那怎么做可重集呢? 那就是要稍微动点手脚,首先在离散化的 ...
- 设计一个树型目录结构的文件系统,其根目录为 root,各分支可以是目录,也可以是文件,最后的叶子都是文件。
设计一个树型目录结构的文件系统,其根目录为 root,各分支可以是目录,也可以是文件,最后的叶子都是文件. 我实现的功能是提供父目录(兄弟目录),输入文件名,创建树型目录结构,文本文件不可以再有子目录 ...
- GitLab获取人员参与项目-贡献项目列表
目录 前言 获取token 登录 获取用户参与项目 完整代码 前言 最近在做的统计报表项目包含人员代码提交量. 要获取人员代码提交量首先要知道人员参与的项目.GitLab个人页面中有Contribut ...
- linux环境下完成jenkins的环境搭建
环境搭建部署: 请完成jenkins的环境搭建,需安装tomcat,mysql. Jenkins 地址: https://jenkins.io/download/ 步骤分析: 1.全部操作使用普通用 ...
- springboot项目整合swagger2出现的问题
swagger需要开放以下uri:/swagger-ui.html/swagger-resources/webjars/csrf/v2 添加swagger后项目报错 Failed to start b ...
- c++中的new的应用
代码如下: #include <cstddef> #include <iostream> using namespace std; class CTest{ public: ; ...
- FM与FFM深入解析
因子机的定义 机器学习中的建模问题可以归纳为从数据中学习一个函数,它将实值的特征向量映射到一个特定的集合中.例如,对于回归问题,集合 T 就是实数集 R,对于二分类问题,这个集合可以是{+1,-1}. ...
- 阿里云OSS的 存储包、下行流量包、回流流量包 三者有啥关系
阿里云OSS的 存储包.下行流量包.回流流量包 三者有啥关系 一.总结 一句话总结: 你把文件放 oss,会占用存储空间,存储包覆盖这部分费用 你访问存储在 oss 里面的文件,会产生下行流量,就是从 ...
- <HTML/CSS>BFC原理剖析
本文讲了BFC的概念是什么: BFC的约束规则:咋样才能触发生成新的BFC:BFC在布局中的应用:防止margin重叠(塌陷,以最大的为准): 清除内部浮动:自适应两(多)栏布局. 1. BFC是什么 ...
- Eclipse中把项目导出为war包【我】
项目右键,Export 全部默认一路下一步,选择一个目标文件夹,确定即可.