Java-GC 垃圾收集器(HotSpot)
垃圾收集器为垃圾收集算法的具体实现,是执行垃圾收集算法的,是守护线程。
HotSpot 虚拟机采用分代收集(JVM 规范并未对堆区进行划分),将堆分为年轻代和老年代,垃圾收集器也按照这样区分。不过已有通用垃圾收集器出现。
一、新生代垃圾收集器
Serial 垃圾收集器(单线程)
在垃圾收集过程中停止一切用户线程(Stop The World),适合客户端使用。
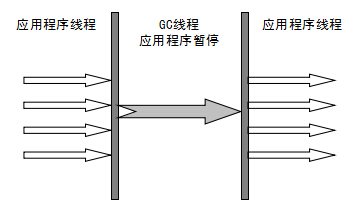
ParNew 垃圾收集器(多线程)
Serial 的多线程版本,但线程切换需要额外的开销,因此在单 CPU 环境中表现不如 Serial,清理过程依然需要 Stop The World。
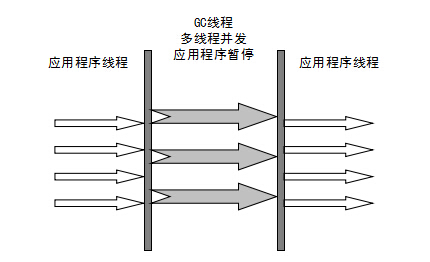
Parallel Scavenge 垃圾收集器(多线程)
Parallel Scavenge 和 ParNew 一样,都是多线程、新生代垃圾收集器。但是两者有巨大的不同点:
- Parallel Scavenge:追求 CPU 吞吐量,能够在较短时间内完成指定任务,因此适合没有交互的后台计算。
- ParNew:追求降低用户停顿时间,适合交互式应用。
吞吐量 = 运行用户代码时间 / (运行用户代码时间 + 垃圾收集时间)
二、老年代垃圾收集器
Serial Old 垃圾收集器(单线程)
Serial 的老年代版本,区别:Serial Old 工作在老年代,使用“标记-整理”算法;Serial 工作在新生代,使用“复制”算法。
Parallel Old 垃圾收集器(多线程)
Parallel Scavenge 的老年代版本,追求 CPU 吞吐量。
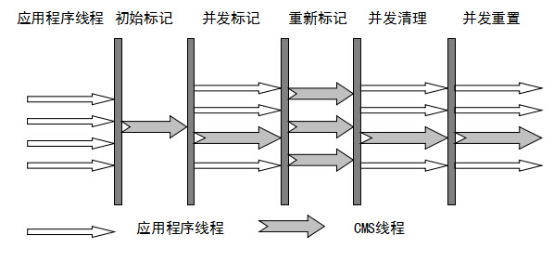
CMS 垃圾收集器
CMS(Concurrent Mark Sweep,并发标记清除)收集器是以获取最短回收停顿时间为目标的收集器(追求低停顿),它在垃圾收集时使得用户线程和 GC 线程并发执行,因此在垃圾收集过程中用户也不会感到明显的卡顿。
三、G1 通用垃圾收集器
面向服务端应用的垃圾收集器,它没有新生代和老年代的概念,而是将堆划分为一块块独立的 Region。当要进行垃圾收集时,首先估计每个 Region 中垃圾的数量,每次都从垃圾回收价值最大的 Region 开始回收,因此可以获得最大的回收效率。
从整体上看, G1 是基于“标记-整理”算法实现的收集器,从局部(两个 Region 之间)上看是基于“复制”算法实现的,这意味着运行期间不会产生内存空间碎片。
四、相关命令
# 服务端与客户端查看
java -version

# 默认 GC 查看,显示出JVM初始化完毕后所有跟最初的默认值不同的参数及它们的值
java -XX:+PrintCommandLineFlags -version
# java -XX:+PrintFlagsFinal -version | find ":"

| -XX:UseSerialGC | Client 模式的默认值,使用 Serial+Serial Old 收集器组合进行垃圾收集 |
| -XX:UseParNewGC | 使用 ParNew+Serial Old 收集器组合进行垃圾收集 |
| -XX:UseConcMarkSweepGC | 使用 ParNew+CMS+Serial Old 收集器组合进行垃圾收集。Serial Old 作为 CMS 收集器出现 Concurrent Mode Failure 的备用垃圾收集器 |
| -XX:UseParallelGC | Server 模式的默认值,使用 Parallel Scavenge+Serial Old 收集器组合进行垃圾收集 |
| -XX:UseParallelOldGC | 使用 Parallel Scavenge+Parallel Old 收集器组合进行垃圾收集 |
五、收集器组合情况

https://github.com/doocs/jvm/blob/master/docs/04-hotspot-gc.md
https://blog.csdn.net/earthhour/article/details/76468084
https://www.cnblogs.com/grey-wolf/p/9217497.html
Java-GC 垃圾收集器(HotSpot)的更多相关文章
- JAVA GC垃圾收集器的分析
本篇文章主要介绍了"JAVA GC垃圾收集器的分析",主要涉及到JAVA GC垃圾收集器的分析方面的内容,对于JAVA GC垃圾收集器的分析感兴趣的同学可以参考一下. ...
- java - GC垃圾收集器详解(一)
概要 该图标记了在jdk体系中所使用到的垃圾收集器及对应的关系图.图片上方为年轻代的垃圾收集器而图片下方是老年代的垃圾收集器.当选择某一个区域的垃圾收集器时会自动选择另外一个区域的另一个垃圾收集器.例 ...
- java - GC垃圾收集器详解(三)
以前收集器的特点 年轻代和老年代是各自独立且连续的内存块 年轻代收集必须使用单个eden+S0+S1进行复制算法 老年代收集扫描整个老年代区域 都是以尽可能少而快速地执行GC为设计原则 G1是什么 G ...
- java - GC垃圾收集器详解(二)
CMS收集器 CMS收集器(ConcurrentMarkSweep:并发标记清除)是一种以获取最短回收停顿时间为目标的收集器. 适合应用在互联网站或者B/S系统的服务器上,这类应用尤其重视服务器的响应 ...
- Java虚拟机垃圾收集器与内存分配策略
Java虚拟机垃圾收集器与内存分配策略 概述 那些内存须要回收,什么时候回收.怎样回收是GC须要完毕的3件事情. 程序计数器.虚拟机栈与本地方法栈这三个区域都是线程私有的,内存的分配与回收都具有确定性 ...
- [转] 深入理解Java G1垃圾收集器
[From] https://www.cnblogs.com/ASPNET2008/p/6496481.html 深入理解Java G1垃圾收集器 本文首先简单介绍了垃圾收集的常见方式,然后再分析了G ...
- JVM学习笔记——GC垃圾收集器
GC 垃圾收集器 Java 堆内存采用分代回收算法,因此 JVM 针对新生代和老年代提供了多种垃圾收集器. 1. Serial 收集器 Serial 收集器是单线程收集器,采用复制算法. 是最基本的垃 ...
- 深入理解java虚拟机【Java虚拟机垃圾收集器】
Java堆内存被划分为新生代和年老代两部分,新生代主要使用复制和标记-清除垃圾回收算法,年老代主要使用标记-整理垃圾回收算法,因此java虚拟中针对新生代和年老代分别提供了多种不同的垃圾收集器,JDK ...
- (转)《深入理解java虚拟机》学习笔记4——Java虚拟机垃圾收集器
Java堆内存被划分为新生代和年老代两部分,新生代主要使用复制和标记-清除垃圾回收算法,年老代主要使用标记-整理垃圾回收算法,因此java虚拟中针对新生代和年老代分别提供了多种不同的垃圾收集器,JDK ...
- 深入理解java虚拟机----->垃圾收集器与内存分配策略(下)
1. 前言 内存分配与回收策略 JVM堆的结构分析(新生代.老年代.永久代) 对象优先在Eden分配 大对象直接进入老年代 长期存活的对象将进入老年代 动态对象年龄判定 空间分配担保 2. 垃圾 ...
随机推荐
- C# 斐波那契数列 第n项数字/前n项的和
static void Main(string[] args) { int a = Convert.ToInt32(Console.ReadLine()); //求第n位数字是多少 Console.W ...
- SQLServer 主键插入
设置此命令后可以往主键插入值 set IDENTITY_INSERT 表名 on set IDENTITY_INSERT 表名 off 注意: 此语句是一个整体操作 反例: 先单步执行:set IDE ...
- BLE各版本新功能总结
文章转载自:http://www.sunyouqun.com/2017/04/ 协议发布时间 协议版本 2016/12 Bluetooth 5 2014/12 Bluetooth 4.2 2013/1 ...
- python函数:函数使用原则、定义与调用形式
一.函数初始 二.函数的使用原则 三.函数的定义与调用形式 四.函数的返回值 五.函数参数的使用 一.函数初始 # 须知一: # 硬盘空间无法修改,硬盘中的数据更新都是用新的内容覆盖旧的内容 # 内存 ...
- Django REST Framework(DRF)_第四篇
DRF分页(总共三种) PageNumberPagination(指定第n页,每页显示n条数据) 说明 既然要用人家的那么我们就先来看下源码,这个分页类源码中举例通过参数指定第几页和每页显示的数据:h ...
- 为什么JAVA对象需要实现序列化?
https://blog.csdn.net/yaomingyang/article/details/79321939 序列化是一种用来处理对象流的机制. 所谓对象流:就是将对象的内容进行流化.可以对流 ...
- loj2718 「NOI2018」归程[Kruskal重构树+最短路]
关于Kruskal重构树可以翻阅本人的最小生成树笔记. 这题明显裸的Kruskal重构树. 然后这题限制$\le p$的边不能走,实际上就是要满足走最小边权最大的瓶颈路,于是跑最大生成树,构建Krus ...
- iptables防火墙入门
一.iptables基本管理 iptables运行前提:关闭firewalld防火墙再开启iptables,不然造成冲突. 基本指令: 1.部署iptables服务 yum –y install ip ...
- 题解 【POJ1952】 BUY LOW, BUY LOWER
题目意思: 给你一个长度为\(n\)(\(1<=n<=5000\))的序列,并求出最长下降子序列的长度及个数, 并且,如果两个序列中元素的权值完全相同,那么即使它们的位置不一样,也只算一种 ...
- 题解 【USACO 4.2.1】草地排水
[USACO 4.2.1]草地排水 Description 在农夫约翰的农场上,每逢下雨,贝茜最喜欢的三叶草地就积聚了一潭水.这意味着草地被水淹没了,并且小草要继续生长还要花相当长一段时间.因此,农夫 ...