小白进阶之Scrapy第六篇Scrapy-Redis详解(转)
Scrapy-Redis 详解
通常我们在一个站站点进行采集的时候,如果是小站的话 我们使用scrapy本身就可以满足。
但是如果在面对一些比较大型的站点的时候,单个scrapy就显得力不从心了。

要是我们能够多个Scrapy一起采集该多好啊 人多力量大。
很遗憾Scrapy官方并不支持多个同时采集一个站点,虽然官方给出一个方法:
**将一个站点的分割成几部分 交给不同的scrapy去采集**
似乎是个解决办法,但是很麻烦诶!毕竟分割很麻烦的哇
下面就改轮到我们的额主角Scrapy-Redis登场了!

什么??你这么就登场了?还没说为什么呢?
好吧 为了简单起见 就用官方图来简单说明一下:

这张图大家相信大家都很熟悉了。重点看一下SCHEDULER
1. 先来看看官方对于SCHEDULER的定义:
**SCHEDULER接受来自Engine的Requests,并将它们放入队列(可以按顺序优先级),以便在之后将其提供给Engine**
2. 现在我们来看看SCHEDULER都提供了些什么功能:
根据官方文档说明 在我们没有没有指定 SCHEDULER 参数时,默认使用:’scrapy.core.scheduler.Scheduler’ 作为SCHEDULER(调度器)
scrapy.core.scheduler.py:
class Scheduler(object):
def __init__(self, dupefilter, jobdir=None, dqclass=None, mqclass=None,
logunser=False, stats=None, pqclass=None):
self.df = dupefilter
self.dqdir = self._dqdir(jobdir)
self.pqclass = pqclass
self.dqclass = dqclass
self.mqclass = mqclass
self.logunser = logunser
self.stats = stats
# 注意在scrpy中优先注意这个方法,此方法是一个钩子 用于访问当前爬虫的配置
@classmethod
def from_crawler(cls, crawler):
settings = crawler.settings
# 获取去重用的类 默认:scrapy.dupefilters.RFPDupeFilter
dupefilter_cls = load_object(settings['DUPEFILTER_CLASS'])
# 对去重类进行配置from_settings 在 scrapy.dupefilters.RFPDupeFilter 43行
# 这种调用方式对于IDE跳转不是很好 所以需要自己去找
# @classmethod
# def from_settings(cls, settings):
# debug = settings.getbool('DUPEFILTER_DEBUG')
# return cls(job_dir(settings), debug)
# 上面就是from_settings方法 其实就是设置工作目录 和是否开启debug
dupefilter = dupefilter_cls.from_settings(settings)
# 获取优先级队列 类对象 默认:queuelib.pqueue.PriorityQueue
pqclass = load_object(settings['SCHEDULER_PRIORITY_QUEUE'])
# 获取磁盘队列 类对象(SCHEDULER使用磁盘存储 重启不会丢失)
dqclass = load_object(settings['SCHEDULER_DISK_QUEUE'])
# 获取内存队列 类对象(SCHEDULER使用内存存储 重启会丢失)
mqclass = load_object(settings['SCHEDULER_MEMORY_QUEUE'])
# 是否开启debug
logunser = settings.getbool('LOG_UNSERIALIZABLE_REQUESTS', settings.getbool('SCHEDULER_DEBUG'))
# 将这些参数传递给 __init__方法
return cls(dupefilter, jobdir=job_dir(settings), logunser=logunser,
stats=crawler.stats, pqclass=pqclass, dqclass=dqclass, mqclass=mqclass)
def has_pending_requests(self):
"""检查是否有没处理的请求"""
return len(self) > 0
def open(self, spider):
"""Engine创建完毕之后会调用这个方法"""
self.spider = spider
# 创建一个有优先级的内存队列 实例化对象
# self.pqclass 默认是:queuelib.pqueue.PriorityQueue
# self._newmq 会返回一个内存队列的 实例化对象 在110 111 行
self.mqs = self.pqclass(self._newmq)
# 如果self.dqdir 有设置 就创建一个磁盘队列 否则self.dqs 为空
self.dqs = self._dq() if self.dqdir else None
# 获得一个去重实例对象 open 方法是从BaseDupeFilter继承的
# 现在我们可以用self.df来去重啦
return self.df.open()
def close(self, reason):
"""当然Engine关闭时"""
# 如果有磁盘队列 则对其进行dump后保存到active.json文件中
if self.dqs:
prios = self.dqs.close()
with open(join(self.dqdir, 'active.json'), 'w') as f:
json.dump(prios, f)
# 然后关闭去重
return self.df.close(reason)
def enqueue_request(self, request):
"""添加一个Requests进调度队列"""
# self.df.request_seen是检查这个Request是否已经请求过了 如果有会返回True
if not request.dont_filter and self.df.request_seen(request):
# 如果Request的dont_filter属性没有设置(默认为False)和 已经存在则去重
# 不push进队列
self.df.log(request, self.spider)
return False
# 先尝试将Request push进磁盘队列
dqok = self._dqpush(request)
if dqok:
# 如果成功 则在记录一次状态
self.stats.inc_value('scheduler/enqueued/disk', spider=self.spider)
else:
# 不能添加进磁盘队列则会添加进内存队列
self._mqpush(request)
self.stats.inc_value('scheduler/enqueued/memory', spider=self.spider)
self.stats.inc_value('scheduler/enqueued', spider=self.spider)
return True
def next_request(self):
"""从队列中获取一个Request"""
# 优先从内存队列中获取
request = self.mqs.pop()
if request:
self.stats.inc_value('scheduler/dequeued/memory', spider=self.spider)
else:
# 不能获取的时候从磁盘队列队里获取
request = self._dqpop()
if request:
self.stats.inc_value('scheduler/dequeued/disk', spider=self.spider)
if request:
self.stats.inc_value('scheduler/dequeued', spider=self.spider)
# 将获取的到Request返回给Engine
return request
def __len__(self):
return len(self.dqs) + len(self.mqs) if self.dqs else len(self.mqs)
def _dqpush(self, request):
if self.dqs is None:
return
try:
reqd = request_to_dict(request, self.spider)
self.dqs.push(reqd, -request.priority)
except ValueError as e: # non serializable request
if self.logunser:
msg = ("Unable to serialize request: %(request)s - reason:"
" %(reason)s - no more unserializable requests will be"
" logged (stats being collected)")
logger.warning(msg, {'request': request, 'reason': e},
exc_info=True, extra={'spider': self.spider})
self.logunser = False
self.stats.inc_value('scheduler/unserializable',
spider=self.spider)
return
else:
return True
def _mqpush(self, request):
self.mqs.push(request, -request.priority)
def _dqpop(self):
if self.dqs:
d = self.dqs.pop()
if d:
return request_from_dict(d, self.spider)
def _newmq(self, priority):
return self.mqclass()
def _newdq(self, priority):
return self.dqclass(join(self.dqdir, 'p%s' % priority))
def _dq(self):
activef = join(self.dqdir, 'active.json')
if exists(activef):
with open(activef) as f:
prios = json.load(f)
else:
prios = ()
q = self.pqclass(self._newdq, startprios=prios)
if q:
logger.info("Resuming crawl (%(queuesize)d requests scheduled)",
{'queuesize': len(q)}, extra={'spider': self.spider})
return q
def _dqdir(self, jobdir):
if jobdir:
dqdir = join(jobdir, 'requests.queue')
if not exists(dqdir):
os.makedirs(dqdir)
return dqdir
只挑了一些重点的写了一些注释剩下大家自己领会(才不是我懒哦 )
从上面的代码 我们可以很清楚的知道 SCHEDULER的主要是完成了 push Request pop Request 和 去重的操作。
而且queue 操作是在内存队列中完成的。
大家看queuelib.queue就会发现基于内存的(deque)
那么去重呢?
class RFPDupeFilter(BaseDupeFilter):
"""Request Fingerprint duplicates filter""" def __init__(self, path=None, debug=False):
self.file = None
self.fingerprints = set()
self.logdupes = True
self.debug = debug
self.logger = logging.getLogger(__name__)
if path:
# 此处可以看到去重其实打开了一个名叫 requests.seen的文件
# 如果是使用的磁盘的话
self.file = open(os.path.join(path, 'requests.seen'), 'a+')
self.file.seek(0)
self.fingerprints.update(x.rstrip() for x in self.file) @classmethod
def from_settings(cls, settings):
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(job_dir(settings), debug) def request_seen(self, request):
fp = self.request_fingerprint(request)
if fp in self.fingerprints:
# 判断我们的请求是否在这个在集合中
return True
# 没有在集合就添加进去
self.fingerprints.add(fp)
# 如果用的磁盘队列就写进去记录一下
if self.file:
self.file.write(fp + os.linesep)
按照正常流程就是大家都会进行重复的采集;我们都知道进程之间内存中的数据不可共享的,那么你在开启多个Scrapy的时候,它们相互之间并不知道对方采集了些什么那些没有没采集。那就大家伙儿自己玩自己的了。完全没没有效率的提升啊!

怎么解决呢?
这就是我们Scrapy-Redis解决的问题了,不能协作不就是因为Request 和 去重这两个 不能共享吗?
那我把这两个独立出来好了。
将Scrapy中的SCHEDULER组件独立放到大家都能访问的地方不就OK啦!加上scrapy-redis后流程图就应该变成这样了?
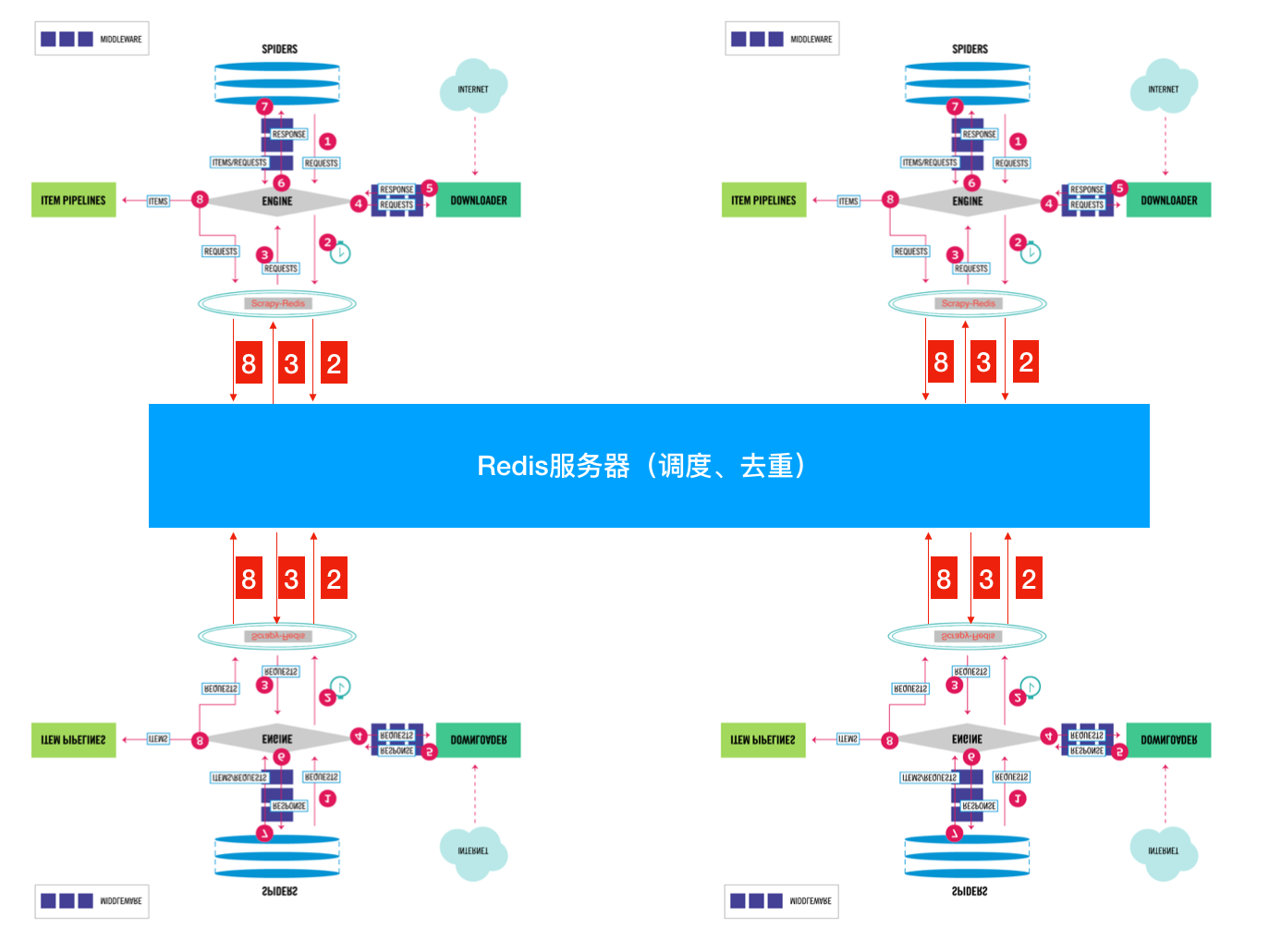
So············· 这样是不是看起来就清楚多了???
下面我们来看看Scrapy-Redis是怎么处理的?
scrapy_redis.scheduler.py:
class Scheduler(object):
"""Redis-based scheduler Settings
--------
SCHEDULER_PERSIST : bool (default: False)
Whether to persist or clear redis queue.
SCHEDULER_FLUSH_ON_START : bool (default: False)
Whether to flush redis queue on start.
SCHEDULER_IDLE_BEFORE_CLOSE : int (default: 0)
How many seconds to wait before closing if no message is received.
SCHEDULER_QUEUE_KEY : str
Scheduler redis key.
SCHEDULER_QUEUE_CLASS : str
Scheduler queue class.
SCHEDULER_DUPEFILTER_KEY : str
Scheduler dupefilter redis key.
SCHEDULER_DUPEFILTER_CLASS : str
Scheduler dupefilter class.
SCHEDULER_SERIALIZER : str
Scheduler serializer. """ def __init__(self, server,
persist=False,
flush_on_start=False,
queue_key=defaults.SCHEDULER_QUEUE_KEY,
queue_cls=defaults.SCHEDULER_QUEUE_CLASS,
dupefilter_key=defaults.SCHEDULER_DUPEFILTER_KEY,
dupefilter_cls=defaults.SCHEDULER_DUPEFILTER_CLASS,
idle_before_close=0,
serializer=None):
"""Initialize scheduler. Parameters
----------
server : Redis
这是Redis实例
persist : bool
是否在关闭时清空Requests.默认值是False。
flush_on_start : bool
是否在启动时清空Requests。 默认值是False。
queue_key : str
Request队列的Key名字
queue_cls : str
队列的可导入路径(就是使用什么队列)
dupefilter_key : str
去重队列的Key
dupefilter_cls : str
去重类的可导入路径。
idle_before_close : int
等待多久关闭 """
if idle_before_close < 0:
raise TypeError("idle_before_close cannot be negative") self.server = server
self.persist = persist
self.flush_on_start = flush_on_start
self.queue_key = queue_key
self.queue_cls = queue_cls
self.dupefilter_cls = dupefilter_cls
self.dupefilter_key = dupefilter_key
self.idle_before_close = idle_before_close
self.serializer = serializer
self.stats = None def __len__(self):
return len(self.queue) @classmethod
def from_settings(cls, settings):
kwargs = {
'persist': settings.getbool('SCHEDULER_PERSIST'),
'flush_on_start': settings.getbool('SCHEDULER_FLUSH_ON_START'),
'idle_before_close': settings.getint('SCHEDULER_IDLE_BEFORE_CLOSE'),
} # If these values are missing, it means we want to use the defaults.
optional = {
# TODO: Use custom prefixes for this settings to note that are
# specific to scrapy-redis.
'queue_key': 'SCHEDULER_QUEUE_KEY',
'queue_cls': 'SCHEDULER_QUEUE_CLASS',
'dupefilter_key': 'SCHEDULER_DUPEFILTER_KEY',
# We use the default setting name to keep compatibility.
'dupefilter_cls': 'DUPEFILTER_CLASS',
'serializer': 'SCHEDULER_SERIALIZER',
}
# 从setting中获取配置组装成dict(具体获取那些配置是optional字典中key)
for name, setting_name in optional.items():
val = settings.get(setting_name)
if val:
kwargs[name] = val # Support serializer as a path to a module.
if isinstance(kwargs.get('serializer'), six.string_types):
kwargs['serializer'] = importlib.import_module(kwargs['serializer'])
# 或得一个Redis连接
server = connection.from_settings(settings)
# Ensure the connection is working.
server.ping() return cls(server=server, **kwargs) @classmethod
def from_crawler(cls, crawler):
instance = cls.from_settings(crawler.settings)
# FIXME: for now, stats are only supported from this constructor
instance.stats = crawler.stats
return instance def open(self, spider):
self.spider = spider try:
# 根据self.queue_cls这个可以导入的类 实例化一个队列
self.queue = load_object(self.queue_cls)(
server=self.server,
spider=spider,
key=self.queue_key % {'spider': spider.name},
serializer=self.serializer,
)
except TypeError as e:
raise ValueError("Failed to instantiate queue class '%s': %s",
self.queue_cls, e) try:
# 根据self.dupefilter_cls这个可以导入的类 实例一个去重集合
# 默认是集合 可以实现自己的去重方式 比如 bool 去重
self.df = load_object(self.dupefilter_cls)(
server=self.server,
key=self.dupefilter_key % {'spider': spider.name},
debug=spider.settings.getbool('DUPEFILTER_DEBUG'),
)
except TypeError as e:
raise ValueError("Failed to instantiate dupefilter class '%s': %s",
self.dupefilter_cls, e) if self.flush_on_start:
self.flush()
# notice if there are requests already in the queue to resume the crawl
if len(self.queue):
spider.log("Resuming crawl (%d requests scheduled)" % len(self.queue)) def close(self, reason):
if not self.persist:
self.flush() def flush(self):
self.df.clear()
self.queue.clear() def enqueue_request(self, request):
"""这个和Scrapy本身的一样"""
if not request.dont_filter and self.df.request_seen(request):
self.df.log(request, self.spider)
return False
if self.stats:
self.stats.inc_value('scheduler/enqueued/redis', spider=self.spider)
# 向队列里面添加一个Request
self.queue.push(request)
return True def next_request(self):
"""获取一个Request"""
block_pop_timeout = self.idle_before_close
# block_pop_timeout 是一个等待参数 队列没有东西会等待这个时间 超时就会关闭
request = self.queue.pop(block_pop_timeout)
if request and self.stats:
self.stats.inc_value('scheduler/dequeued/redis', spider=self.spider)
return request def has_pending_requests(self):
return len(self) > 0
来先来看看
以上就是Scrapy-Redis中的SCHEDULER模块。下面我们来看看queue和本身的什么不同:
scrapy_redis.queue.py
以最常用的优先级队列 PriorityQueue 举例:
class PriorityQueue(Base):
"""Per-spider priority queue abstraction using redis' sorted set"""
"""其实就是使用Redis的有序集合 来对Request进行排序,这样就可以优先级高的在有序集合的顶层 我们只需要"""
"""从上往下依次获取Request即可"""
def __len__(self):
"""Return the length of the queue"""
return self.server.zcard(self.key) def push(self, request):
"""Push a request"""
"""添加一个Request进队列"""
# self._encode_request 将Request请求进行序列化
data = self._encode_request(request)
"""
d = {
'url': to_unicode(request.url), # urls should be safe (safe_string_url)
'callback': cb,
'errback': eb,
'method': request.method,
'headers': dict(request.headers),
'body': request.body,
'cookies': request.cookies,
'meta': request.meta,
'_encoding': request._encoding,
'priority': request.priority,
'dont_filter': request.dont_filter,
'flags': request.flags,
'_class': request.__module__ + '.' + request.__class__.__name__
} data就是上面这个字典的序列化
在Scrapy.utils.reqser.py 中的request_to_dict方法中处理
""" # 在Redis有序集合中数值越小优先级越高(就是会被放在顶层)所以这个位置是取得 相反数
score = -request.priority
# We don't use zadd method as the order of arguments change depending on
# whether the class is Redis or StrictRedis, and the option of using
# kwargs only accepts strings, not bytes.
# ZADD 是添加进有序集合
self.server.execute_command('ZADD', self.key, score, data) def pop(self, timeout=0):
"""
Pop a request
timeout not support in this queue class
有序集合不支持超时所以就木有使用timeout了 这个timeout就是挂羊头卖狗肉
"""
"""从有序集合中取出一个Request"""
# use atomic range/remove using multi/exec
"""使用multi的原因是为了将获取Request和删除Request合并成一个操作(原子性的)在获取到一个元素之后 删除它,因为有序集合 不像list 有pop 这种方式啊"""
pipe = self.server.pipeline()
pipe.multi()
# 取出 顶层第一个
# zrange :返回有序集 key 中,指定区间内的成员。0,0 就是第一个了
# zremrangebyrank:移除有序集 key 中,指定排名(rank)区间内的所有成员 0,0也就是第一个了
# 更多请参考Redis官方文档
pipe.zrange(self.key, 0, 0).zremrangebyrank(self.key, 0, 0)
results, count = pipe.execute()
if results:
return self._decode_request(results[0])
以上就是SCHEDULER在处理Request的时候做的操作了。
是时候来看看SCHEDULER是怎么处理去重的了!
只需要注意这个?方法即可:
def request_seen(self, request):
"""Returns True if request was already seen. Parameters
----------
request : scrapy.http.Request Returns
-------
bool """
# 通过self.request_fingerprint 会生一个sha1的指纹
fp = self.request_fingerprint(request)
# This returns the number of values added, zero if already exists.
# 添加进一个Redis集合如果self.key这个集合中存在fp这个指纹会返回1 不存在返回0
added = self.server.sadd(self.key, fp)
return added == 0
这样大家就都可以访问同一个Redis 获取同一个spider的Request 在同一个位置去重,就不用担心重复啦
大概就像这样:
- spider1:检查一下这个Request是否在Redis去重,如果在就证明其它的spider采集过啦!如果不在就添加进调度队列,等待别 人获取。自己继续干活抓取网页 产生新的Request了 重复之前步骤。
- spider2:以相同的逻辑执行
可能有些小伙儿会产生疑问了~~!spider2拿到了别人的Request了 怎么能正确的执行呢?逻辑不会错吗?
这个不用担心啦 因为整Request当中包含了,所有的逻辑,回去看看上面那个序列化的字典。
总结一下:
- 1. Scrapy-Reids 就是将Scrapy原本在内存中处理的 调度(就是一个队列Queue)、去重、这两个操作通过Redis来实现
- 多个Scrapy在采集同一个站点时会使用相同的redis key(可以理解为队列)添加Request 获取Request 去重Request,这样所有的spider不会进行重复采集。效率自然就嗖嗖的上去了。
- 3. Redis是原子性的,好处不言而喻(一个Request要么被处理 要么没被处理,不存在第三可能)
另外Scrapy-Redis本身不支持Redis-Cluster,大量网站去重的话会给单机很大的压力(就算使用boolfilter 内存也不够整啊!)
改造方式很简单:
- 使用 **rediscluster** 这个包替换掉本身的Redis连接
- Redis-Cluster 不支持事务,可以使用lua脚本进行代替(lua脚本是原子性的哦)
- **注意使用lua脚本 不能写占用时间很长的操作**(毕竟一大群人等着操作Redis 你总不能让人家等着吧)
以上!完毕
对于懒人小伙伴儿 看看这个我改好的: 集群版Scrapy-Redis **PS: 支持Python3.6+ 哦 ! 其余的版本没测试过**

转载请注明:静觅 » 小白进阶之Scrapy第六篇Scrapy-Redis详解
小白进阶之Scrapy第六篇Scrapy-Redis详解(转)的更多相关文章
- 转 Scrapy笔记(5)- Item详解
Item是保存结构数据的地方,Scrapy可以将解析结果以字典形式返回,但是Python中字典缺少结构,在大型爬虫系统中很不方便. Item提供了类字典的API,并且可以很方便的声明字段,很多Scra ...
- Scala进阶之路-面向对象编程之类的成员详解
Scala进阶之路-面向对象编程之类的成员详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Scala中的object对象及apply方法 1>.scala 单例对象 ...
- [转]PostgreSQL教程(十六):系统视图详解
这篇文章主要介绍了PostgreSQL教程(十六):系统视图详解,本文讲解了pg_tables.pg_indexes.pg_views.pg_user.pg_roles.pg_rules.pg_set ...
- 第十六章 IIC协议详解+UART串口读写EEPROM
十六.IIC协议详解+Uart串口读写EEPROM 本文由杭电网友曾凯峰根据小梅哥FPGA IIC协议基本概念公开课内容整理并最终编写Verilog代码实现使用串口读写EEPROM的功能. 以下为原文 ...
- mysql基础篇 - SELECT 语句详解
基础篇 - SELECT 语句详解 SELECT语句详解 一.实验简介 SQL 中最常用的 SELECT 语句,用来在表中选取数据,本节实验中将通过一系列的动手操作详细学习 SELEC ...
- Redis详解入门篇
Redis详解入门篇 [本教程目录] 1.redis是什么2.redis的作者3.谁在使用redis4.学会安装redis5.学会启动redis6.使用redis客户端7.redis数据结构 – 简介 ...
- Scala进阶之路-反射(reflect)技术详解
Scala进阶之路-反射(reflect)技术详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Scala中的反射技术和Java反射用法类似,我这里就不一一介绍反射是啥了,如果对 ...
- “全栈2019”Java异常第十六章:Throwable详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java异 ...
- 入木三分学网络第一篇--VRRP协议详解第一篇(转)
因为keepalived使用了VRRP协议,所有有必要熟悉一下. 虚拟路由冗余协议(Virtual Router Redundancy Protocol,简称VRRP)是解决局域网中配置静态网关时,静 ...
随机推荐
- RabbitMQ 使用参考
http://www.zouyesheng.com/rabbitmq.html 安装 基本概念 基本形式 持久化 调度策略 5.1. fanout 5.2. direct 5.3. topic 5.4 ...
- lftp下载文件无法覆盖,提示" file already existst and xfer:clobber is unset" 问题解决
在 /etc/lftp.conf 文件中添加以下配置即可 set xfer:clobber on
- 异步IO和协程
1-1.并行:真的多任务执行(CPU核数>=任务数):即在某个时刻点上,有多个程序同时运行在多个CPU上 1-2.并发:假的多任务执行(CPU核数<任务数):即一段时间内,有多个程序在同一 ...
- 用mongodump以及mongorestore来完成mongo的迁移任务
首先粘贴官网说明: 详细请见:https://docs.mongodb.com/manual/ 在实际操作中,一般只需用到 mongodump -h ip:port -d dbName -o path ...
- 虚拟机、云主机、VPS 三者之间的区别
当我们想部署网站的时候,经常会听到vps.云主机.虚拟机等关键字,那么你知道这几者之间的区别吗?本文就讲解一下VPS.云主机.虚拟机之间的区别. 什么是VPS VPS 是Virtual Private ...
- Scrapy框架——使用CrawlSpider爬取数据
引言 本篇介绍Crawlspider,相比于Spider,Crawlspider更适用于批量爬取网页 Crawlspider Crawlspider适用于对网站爬取批量网页,相对比Spider类,Cr ...
- Java之属性和普通方法
一.定义类 上一节讲了很多深奥的理论,那么这节我们就得实践一下,先简单描述一下我们的实体世界:有一个学生小明,那么这个学生就是一个对象,这个对象有哪些属性和方法呢,我们可以先简单抽象一下,属性有(姓名 ...
- 安装zabbix4.0 LTS
一.环境准备 1.https://www.zabbix.com/download?zabbix=4.4&os_distribution=centos&os_version=7& ...
- 菜鸟系列docker——搭建私有仓库harbor(6)
docker 搭建私有仓库harbor 1. 准备条件 安装docker sudo yum update sudo yum install -y yum-utils device-mapper-per ...
- (模板)hdoj1007(分治求平面最小点对)
题目链接:https://vjudge.net/problem/HDU-1007 题意:给定n个点,求平面距离最小点对的距离除2. 思路:分治求最小点对,对区间[l,r]递归求[l,mid]和[mid ...