35.百度云语音识别接口使用及PyAudio语音识别模块安装
百度云语音识别接口使用:
百度云语音识别接口文档:https://cloud.baidu.com/doc/SPEECH/ASR-API.html#JSON.E6.96.B9.E5.BC.8F.E4.B8.8A.E4.BC.A0
一. 解析用户语音输入,转换为字符串
- 捕获用户的语音输入
- windows安装
- pip3 install PyAudio #如果报错可以尝试2,3步骤 丶 如果用pip3下载安装报错可以在python第三方安装包下载地址搜索下载安装https://pypi.org/
- python -m pip install --upgrade pip
- pip install PyAudio
CentOS 7.4 下安装PyAudio 需要先安装 portaudio (采用的方法,可行)
1、在安装pyaudio时,报错failed error: portaudio.h: 没有那个文件或目录
2、pyaudio的运行需要依赖于portaudio这个库,应该先安装一个portaudio库
3、portaudio安装步骤:
a)下载portaudio库http://portaudio.com/download.html
b)将下载的文件进行解压
c)进入解压后的portaudio文件,依次执行命令:
./configure
make
make install
d)进入~/.bashrc文件:vim ~/.bashrc
在文件最后一行加入 export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
然后执行命令source ~/.bashrc
4、到此portaudio库安装成功
5、安装pyaudio库,pip3 install pyaudio (wget https://files.pythonhosted.org/packages/ab/42/b4f04721c5c5bfc196ce156b3c768998ef8c0ae3654ed29ea5020c749a6b/PyAudio-0.2.11.tar.gz)
成功后显示版本为0.2.11
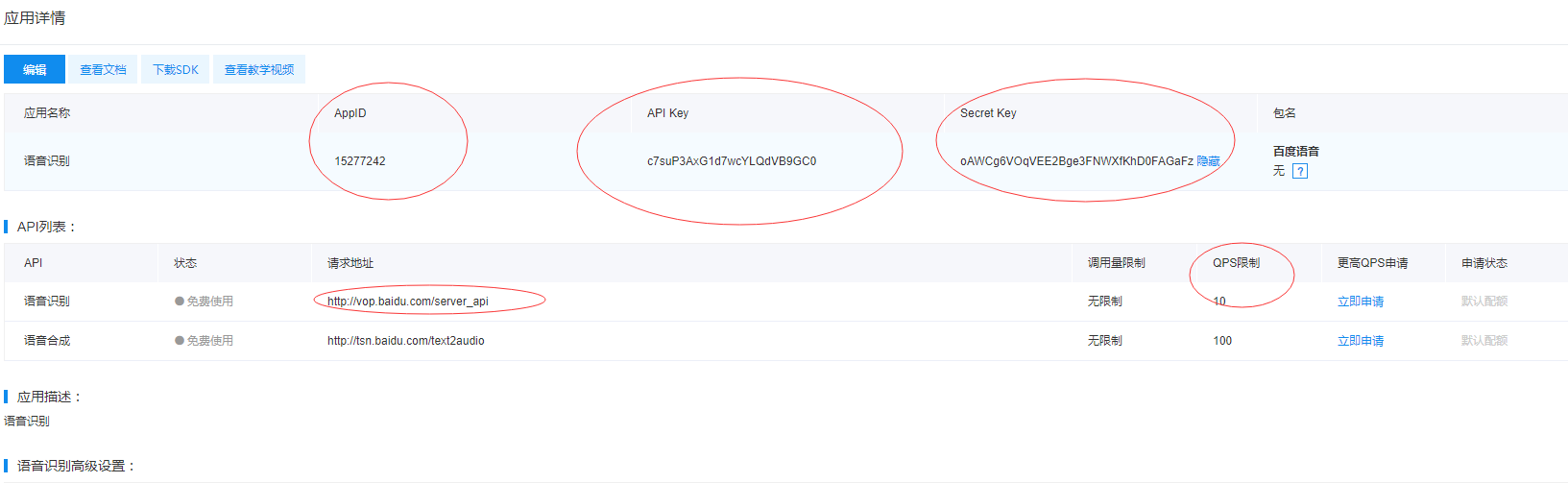
二,音频数据给到百度云
- 音频数据的格式规则
- format:格式 wav
- rate:采样率 16000
- channel:声道 1单声道
- cuid:用户ID MAC地址,只要保证唯一
- token:身份识别 在百度云接口平台注册后,才能拿到
- dev_pid: 1536英文,1537中文
- len:数据的长度 原始的 len(data) ->
- speech:数据对象
1,base64 编码2,经常用于网络中的音频图像二进制的数据传输3,base64.b64encode(data)
- **JSON**格式POST上传本地音频流数据
- header:Content-Type:application/json
- 标识,
- GET:直接获取服务器上的数据
- POST:客户端先向服务端提交数据,服务端在返回,POST一定会向服务器提交数据
- RESTFUL:资源定义成了连接(url 同一资源,这个要了解一下)
- 连接,www.baidu.com
- POST提交数据,
- WEB服务 HTTP协议
- RESTFUL:ip/?shutdown #关机命令
- http://vop.baidu.com/server_api #百度云api接口地址,我们的语音信息提交到这个接口就行了
三,捕获百度云返回的结果
- JSON的返回 #无论什么方式上传都会以JSON格式返回结果
- json.loads() 解析json数据变为Python中数据对象 字典
- j'son.dumps() dict -> dict
- result #音频返回的结果在result字段中
- PyAudio:对象,实例化一个设备
- pa.open(format=存储位深 int 16位, channels=声道,rate=采样率,input=True,frame_per_buffer=1024)
import time
from pyaudio import PyAudio,paInt16
from urllib.request import urlopen,Request #专门处理http协议的模块
import json
import base64
def play_audio(data): #播放音频
pa = PyAudio() #设备实例化
equip = pa.open(
format=paInt16,
channels=1, #单声道
rate=16000,
output=True,
) #打开设备,并且支持输出
equip.write(data) #设备的write函数,写入音频数据
equip.stop_stream() #关闭写入
equip.close()
pa.terminate() #关闭设备实例
def record_audio(): #输入音频
pa = PyAudio() #设备实例化
equip = pa.open(
format=paInt16,
channels=1,
rate=16000,
input=True,
frames_per_buffer=1024,
) #打开设备,并且支持输入
data = [] #存储未来的语音输入
#一截一截的语音数据 [b'1',b'2',]
times = 0 #用来控制用户输入语音长度的
start = time.time()
while times < 50: #3S
data.append(equip.read(1024)) #读取设备中此时的语音数据
times += 1
end = time.time()
print('[TALK] %.2f' % (end - start)) #%.2f 保留2位小数点有效位数字
data = b''.join(data) #完整的音频流数据
equip.close()
pa.terminate() #关闭设备实例
return data
def baidu_token():
API_Key = 'oAcBP47GDDpj6XIHWmcSkeRi'
Secret_Key = 'ba2EKROswCy6KXzLdTpnGqPnPhHSFHU7'
grant_type = 'client_credentials'
url = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=%s&client_id=%s&client_secret=%s'
response = json.loads(urlopen(url % (grant_type,API_Key,Secret_Key)).read().decode())
access_token = response['access_token']
return access_token
def baidu_fenxi(data):
url = 'http://vop.baidu.com/server_api'
data_len = len(data)
audio_data = base64.b64encode(data).decode()
access_token = baidu_token()
post_data = json.dumps({
"format":"wav",
"rate":16000,
"dev_pid":1536,
"channel":1,
"token":access_token,
"cuid":"00-50-56-C0-00-08",
"len":data_len,
"speech":audio_data,
}).encode() #变为json的二进制
headers = {'Content-Type':'application/json'}
req = Request(url=url,headers=headers,data=post_data)
result = json.loads(urlopen(req).read().decode()).get('result')
if result:
return result[0]
else:
return None
def main():
data = record_audio()
res = baidu_fenxi(data)
print(res)
if __name__ == '__main__':
#程序入口
main()运行结果:E:\python学习资料\上课代码编写\代码练习py>python e:/python学习资料/上课代码编写/代码练习py/百度云.py
[TALK] 3.21
你好
35.百度云语音识别接口使用及PyAudio语音识别模块安装的更多相关文章
- C#调用百度云存储接口上传文件
因前几日见园子里有人说可以把网站静态文件放在百度上,于是去百度开放平台看了看,发现之前那篇文章不是调的云存储接口啊... 于是自己写了个C#能调百度云存储的例子(百度云开放平台只提供php.java. ...
- 百度云服务接口错误:Parameter invalid, the key input with filter parameter is not searchfilter column key
百度LBS云服务接口: 地址:http://lbsyun.baidu.com/index.php?title=lbscloud/api/geosearch 访问接口:http://api.map.ba ...
- 借助百度云API进行人脸识别
前言:本篇博客是笔者第一次使用百度云api进行人脸检测,主要内容包括两部分,一是获取接口,二是借助接口进行人脸检测.笔者也是初步了解这方面的内容,也是参考了杂七杂八的博文,内容可能存在错误及其他毛病, ...
- 百度云语音识别,Audio2Txt(c#)
百度云识别没有提供c#版本的sdk,下面给个c#的 1.打开网址http://developer.baidu.com/ 2.登陆 3.管理控制台>开发者服务管理 4.创建工程 5.输入名称,点击 ...
- python录音并调用百度语音识别接口
#!/usr/bin/env python import requests import json import base64 import pyaudio import wave import os ...
- python调用百度语音识别接口实时识别
1.本文直接上干货 奉献代码:https://github.com/wuzaipei/audio_discern/tree/master/%E8%AF%AD%E9%9F%B3%E8%AF%86%E5% ...
- 利用百度云接口实现车牌识别·python
一个小需求---实现车牌识别. 目前有两个想法 1. 调云在线的接口或者使用SDK做开发(配置环境和变异第三方库麻烦,当然使用python可以避免这些问题) 2. 自己实现车牌识别算法(复杂) 一开始 ...
- python利用百度云接口实现车牌识别
一个小需求---实现车牌识别. 目前有两个想法 调云在线的接口或者使用SDK做开发(配置环境和编译第三方库很麻烦,当然使用python可以避免这些问题) 自己实现车牌识别算法(复杂) ! 一开始准备使 ...
- Android推送服务——百度云推送
一.推送服务简介 消息推送,顾名思义,是由一方主动发起,而另一方与发起方以某一种方式建立连接并接收消息.在Android开发中,这里的发起方我们把它叫做推送服务器(Push Server),接收方叫做 ...
随机推荐
- 微信小程序 空白页重定向---二维码扫描第二次进入 不经过onLoad过程解析scene参数,跳转问题
在刚开始的时候将小程序的入口文件直接指向tabbar 的首页,此时出现问题:二维码扫描,第一次不关闭首页,第二次进入时:不会经过onLoad过程解析scene参数: 官方中解释:tabbar跳转方式触 ...
- P4475 巧克力王国 k-d tree
思路:\(k-d\ tree\) 提交:2次 错因:\(query\)时有一个\(mx\)误写成\(mn\)窝太菜了. 题解: 先把\(k-d\ tree\)建出来,然后查询时判一下整个矩形是否整体\ ...
- border-style
border-style 语法: border-style:<line-style>{1,4} <line-style> = none | hidden | dotted | ...
- 001_STM32程序移植之_DS1302
1. 测试环境:STM32C8T6 2. 测试模块:DS1302时钟模块 3. 测试接口: 1. DS1302模块接口: DS1302引脚 单片机引脚 VCC--------------------3 ...
- linux下core dump--转载
原文链接:https://www.cnblogs.com/Anker/p/6079580.html 1.前言 一直在从事linux下后台开发,经常与core文件打交道.还记得刚开始从事linux下 ...
- C/C++应用--Window下获取硬件信息(CPU, 硬盘,网卡等)
一.头文件如下: #include <Windows.h> #include <string> #include <iostream> #include <w ...
- centos7下glances系统监控的安装
yum install epel* -y yum install python-pip python-devel -y yum install glances -y 启动>>glances
- Js 之获取对象key值
var date = Object.keys(data); Object.keys( ) 会返回一个数组,数组中是这个对象的key值列表 所以只要Object.keys(a)[0], 就可以得只包含一 ...
- 安装使用VUE
安装使用VUE 如果是简单实用vue的话,可以直接引用js文件. https://vuejs.org/js/vue.js 但是在构建大型项目的时候推荐使用NPM安装,NPM能够很好的和诸如webpac ...
- Postgresql - MATERIALIZED VIEW
MATERIALIZED VIEWPG 9.3 版本之后开始支持物化视图.View 视图:虚拟,不存在实际的数据,在查询视图的时候其实是对视图内的表进行查询操作. 物化视图:实际存在,将数据存成一张表 ...