【平台中间件】为什么用etcd而不用ZooKeeper?从应用场景到实现原理的全方位解读
前言
博主在工作过程中经常接触到ETCD,搜索相关资料的时候发现排名最高的是一篇图片全是404的转载文章,后来看到了原文,感觉有义务让更多的人看到这样的精品文章,所以进行了转载。
原文发布在infoQ,原文链接:http://www.infoq.com/cn/articles/etcd-interpretation-application-scenario-implement-principle
摘要
随着CoreOS和Kubernetes等项目在开源社区日益火热,它们项目中都用到的etcd组件作为一个高可用强一致性的服务发现存储仓库,渐渐为开发人员所关注。在云计算时代,如何让服务快速透明地接入到计算集群中,如何让共享配置信息快速被集群中的所有机器发现,更为重要的是,如何构建这样一套高可用、安全、易于部署以及响应快速的服务集群,已经成为了迫切需要解决的问题。etcd为解决这类问题带来了福音,本文将从etcd的应用场景开始,深入解读etcd的实现方式,以供开发者们更为充分地享用etcd所带来的便利。
ETCD的经典应用场景
要问etcd是什么?很多人第一反应可能是一个键值存储仓库,却没有重视官方定义的后半句,用于配置共享和服务发现。
A highly-available key value store for shared configuration and service discovery.
实际上,etcd作为一个受到ZooKeeper与doozer启发而催生的项目,除了拥有与之类似的功能外,更专注于以下四点。
- 简单:基于HTTP+JSON的API让你用curl就可以轻松使用。
- 安全:可选SSL客户认证机制。
- 快速:每个实例每秒支持一千次写操作。
- 可信:使用Raft算法充分实现了分布式。
随着云计算的不断发展,分布式系统中涉及到的问题越来越受到人们重视。受阿里中间件团队对ZooKeeper典型应用场景一览一文的启发,笔者根据自己的理解也总结了一些etcd的经典使用场景。让我们来看看etcd这个基于Raft强一致性算法的分布式存储仓库能给我们带来哪些帮助。
值得注意的是,分布式系统中的数据分为控制数据和应用数据。使用etcd的场景默认处理的数据都是控制数据,对于应用数据,只推荐数据量很小,但是更新访问频繁的情况。
场景一:服务发现(Service Discovery)
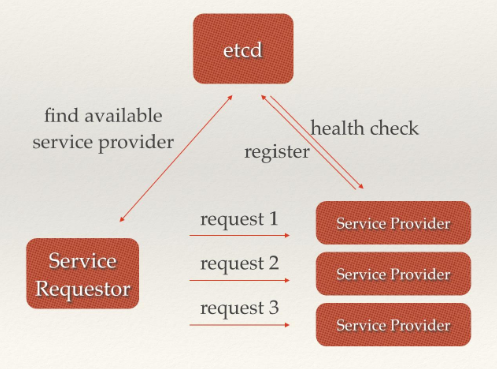
服务发现要解决的也是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务,要如何才能找到对方并建立连接。本质上来说,服务发现就是想要了解集群中是否有进程在监听udp或tcp端口,并且通过名字就可以查找和连接。要解决服务发现的问题,需要有下面三大支柱,缺一不可。
- 一个强一致性、高可用的服务存储目录。基于Raft算法的etcd天生就是这样一个强一致性高可用的服务存储目录。
- 一种注册服务和监控服务健康状态的机制。用户可以在etcd中注册服务,并且对注册的服务设置key TTL,定时保持服务的心跳以达到监控健康状态的效果。
- 一种查找和连接服务的机制。通过在etcd指定的主题下注册的服务也能在对应的主题下查找到。为了确保连接,我们可以在每个服务机器上都部署一个Proxy模式的etcd,这样就可以确保能访问etcd集群的服务都能互相连接。

服务发现示意图
下面我们来看服务发现对应的具体场景。
微服务协同工作架构中,服务动态添加
随着Docker容器的流行,多种微服务共同协作,构成一个相对功能强大的架构的案例越来越多。透明化的动态添加这些服务的需求也日益强烈。通过服务发现机制,在etcd中注册某个服务名字的目录,在该目录下存储可用的服务节点的IP。在使用服务的过程中,只要从服务目录下查找可用的服务节点去使用即可。
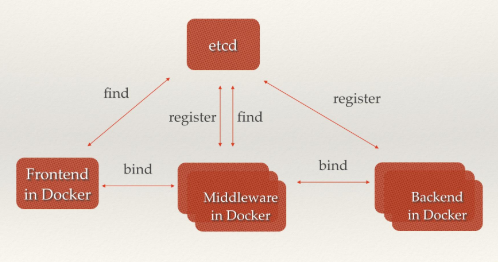
微服务协同工作
#### PaaS平台中应用多实例与实例故障重启透明化
PaaS平台中的应用一般都有多个实例,通过域名,不仅可以透明的对这多个实例进行访问,而且还可以做到负载均衡。但是应用的某个实例随时都有可能故障重启,这时就需要动态的配置域名解析(路由)中的信息。通过etcd的服务发现功能就可以轻松解决这个动态配置的问题。
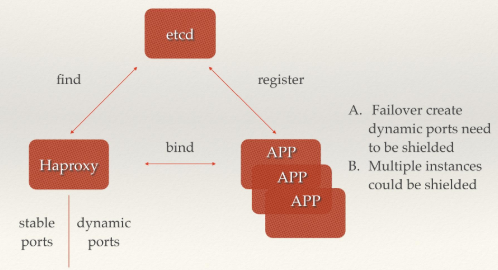
云平台多实例透明化
场景二:消息发布与订阅
在分布式系统中,最适用的一种组件间通信方式就是消息发布与订阅。即构建一个配置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦主题有消息发布,就会实时通知订阅者。通过这种方式可以做到分布式系统配置的集中式管理与动态更新。
- 应用中用到的一些配置信息放到etcd上进行集中管理。这类场景的使用方式通常是这样:应用在启动的时候主动从etcd获取一次配置信息,同时,在etcd节点上注册一个Watcher并等待,以后每次配置有更新的时候,etcd都会实时通知订阅者,以此达到获取最新配置信息的目的。
- 分布式搜索服务中,索引的元信息和服务器集群机器的节点状态存放在etcd中,供各个客户端订阅使用。使用etcd的key TTL功能可以确保机器状态是实时更新的。
- 分布式日志收集系统。这个系统的核心工作是收集分布在不同机器的日志。收集器通常是按照应用(或主题)来分配收集任务单元,因此可以在etcd上创建一个以应用(主题)命名的目录P,并将这个应用(主题相关)的所有机器ip,以子目录的形式存储到目录P上,然后设置一个etcd递归的Watcher,递归式的监控应用(主题)目录下所有信息的变动。这样就实现了机器IP(消息)变动的时候,能够实时通知到收集器调整任务分配。
- 系统中信息需要动态自动获取与人工干预修改信息请求内容的情况。通常是暴露出接口,例如JMX接口,来获取一些运行时的信息。引入etcd之后,就不用自己实现一套方案了,只要将这些信息存放到指定的etcd目录中即可,etcd的这些目录就可以通过HTTP的接口在外部访问。

消息发布与订阅
场景三:负载均衡
在场景一中也提到了负载均衡,本文所指的负载均衡均为软负载均衡。分布式系统中,为了保证服务的高可用以及数据的一致性,通常都会把数据和服务部署多份,以此达到对等服务,即使其中的某一个服务失效了,也不影响使用。由此带来的坏处是数据写入性能下降,而好处则是数据访问时的负载均衡。因为每个对等服务节点上都存有完整的数据,所以用户的访问流量就可以分流到不同的机器上。
- etcd本身分布式架构存储的信息访问支持负载均衡。etcd集群化以后,每个etcd的核心节点都可以处理用户的请求。所以,把数据量小但是访问频繁的消息数据直接存储到etcd中也是个不错的选择,如业务系统中常用的二级代码表(在表中存储代码,在etcd中存储代码所代表的具体含义,业务系统调用查表的过程,就需要查找表中代码的含义)。
- 利用etcd维护一个负载均衡节点表。etcd可以监控一个集群中多个节点的状态,当有一个请求发过来后,可以轮询式的把请求转发给存活着的多个状态。类似KafkaMQ,通过ZooKeeper来维护生产者和消费者的负载均衡。同样也可以用etcd来做ZooKeeper的工作。
负载均衡
场景四:分布式通知与协调
这里说到的分布式通知与协调,与消息发布和订阅有些相似。都用到了etcd中的Watcher机制,通过注册与异步通知机制,实现分布式环境下不同系统之间的通知与协调,从而对数据变更做到实时处理。实现方式通常是这样:不同系统都在etcd上对同一个目录进行注册,同时设置Watcher观测该目录的变化(如果对子目录的变化也有需要,可以设置递归模式),当某个系统更新了etcd的目录,那么设置了Watcher的系统就会收到通知,并作出相应处理。
- 通过etcd进行低耦合的心跳检测。检测系统和被检测系统通过etcd上某个目录关联而非直接关联起来,这样可以大大减少系统的耦合性。
- 通过etcd完成系统调度。某系统有控制台和推送系统两部分组成,控制台的职责是控制推送系统进行相应的推送工作。管理人员在控制台作的一些操作,实际上是修改了etcd上某些目录节点的状态,而etcd就把这些变化通知给注册了Watcher的推送系统客户端,推送系统再作出相应的推送任务。
- 通过etcd完成工作汇报。大部分类似的任务分发系统,子任务启动后,到etcd来注册一个临时工作目录,并且定时将自己的进度进行汇报(将进度写入到这个临时目录),这样任务管理者就能够实时知道任务进度。
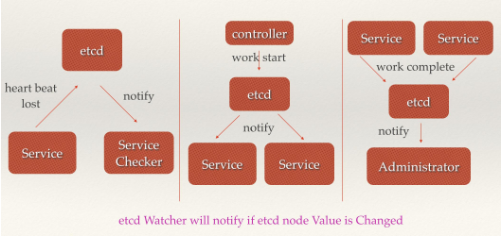
分布式协同工作
场景五:分布式锁
因为etcd使用Raft算法保持了数据的强一致性,某次操作存储到集群中的值必然是全局一致的,所以很容易实现分布式锁。锁服务有两种使用方式,一是保持独占,二是控制时序。
- 保持独占即所有获取锁的用户最终只有一个可以得到。etcd为此提供了一套实现分布式锁原子操作CAS(CompareAndSwap)的API。通过设置prevExist值,可以保证在多个节点同时去创建某个目录时,只有一个成功。而创建成功的用户就可以认为是获得了锁。
- 控制时序,即所有想要获得锁的用户都会被安排执行,但是获得锁的顺序也是全局唯一的,同时决定了执行顺序。etcd为此也提供了一套API(自动创建有序键),对一个目录建值时指定为POST动作,这样etcd会自动在目录下生成一个当前最大的值为键,存储这个新的值(客户端编号)。同时还可以使用API按顺序列出所有当前目录下的键值。此时这些键的值就是客户端的时序,而这些键中存储的值可以是代表客户端的编号。
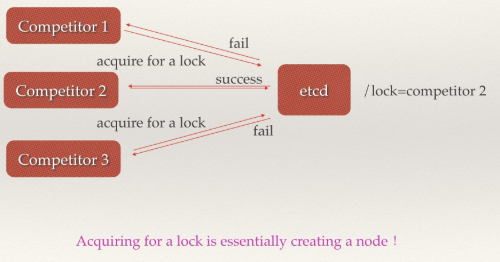
分布式锁
场景六:分布式队列
分布式队列的常规用法与场景五中所描述的分布式锁的控制时序用法类似,即创建一个先进先出的队列,保证顺序。
另一种比较有意思的实现是在保证队列达到某个条件时再统一按顺序执行。这种方法的实现可以在/queue这个目录中另外建立一个/queue/condition节点。
- condition可以表示队列大小。比如一个大的任务需要很多小任务就绪的情况下才能执行,每次有一个小任务就绪,就给这个condition数字加1,直到达到大任务规定的数字,再开始执行队列里的一系列小任务,最终执行大任务。
- condition可以表示某个任务在不在队列。这个任务可以是所有排序任务的首个执行程序,也可以是拓扑结构中没有依赖的点。通常,必须执行这些任务后才能执行队列中的其他任务。
- condition还可以表示其它的一类开始执行任务的通知。可以由控制程序指定,当condition出现变化时,开始执行队列任务。
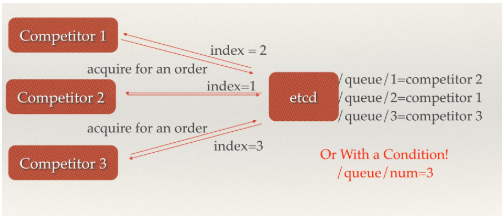
分布式队列
场景七:集群监控与Leader竞选
通过etcd来进行监控实现起来非常简单并且实时性强。
- 前面几个场景已经提到Watcher机制,当某个节点消失或有变动时,Watcher会第一时间发现并告知用户。
- 节点可以设置TTL key,比如每隔30s发送一次心跳使代表该机器存活的节点继续存在,否则节点消失。
这样就可以第一时间检测到各节点的健康状态,以完成集群的监控要求。
另外,使用分布式锁,可以完成Leader竞选。这种场景通常是一些长时间CPU计算或者使用IO操作的机器,只需要竞选出的Leader计算或处理一次,就可以把结果复制给其他的Follower。从而避免重复劳动,节省计算资源。
这个的经典场景是搜索系统中建立全量索引。如果每个机器都进行一遍索引的建立,不但耗时而且建立索引的一致性不能保证。通过在etcd的CAS机制同时创建一个节点,创建成功的机器作为Leader,进行索引计算,然后把计算结果分发到其它节点。
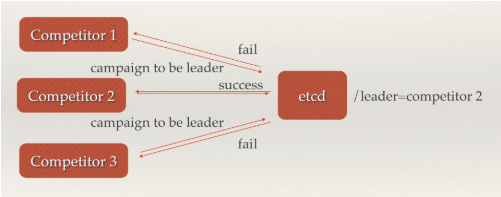
Leader竞选
场景八:为什么用etcd而不用ZooKeeper?
阅读了“ZooKeeper典型应用场景一览”一文的读者可能会发现,etcd实现的这些功能,ZooKeeper都能实现。那么为什么要用etcd而非直接使用ZooKeeper呢?
相较之下,ZooKeeper有如下缺点:
- 复杂。ZooKeeper的部署维护复杂,管理员需要掌握一系列的知识和技能;而Paxos强一致性算法也是素来以复杂难懂而闻名于世;另外,ZooKeeper的使用也比较复杂,需要安装客户端,官方只提供了Java和C两种语言的接口。
- Java编写。这里不是对Java有偏见,而是Java本身就偏向于重型应用,它会引入大量的依赖。而运维人员则普遍希望保持强一致、高可用的机器集群尽可能简单,维护起来也不易出错。
- 发展缓慢。Apache基金会项目特有的“Apache Way”在开源界饱受争议,其中一大原因就是由于基金会庞大的结构以及松散的管理导致项目发展缓慢。
而etcd作为一个后起之秀,其优点也很明显。
- 简单。使用Go语言编写部署简单;使用HTTP作为接口使用简单;使用Raft算法保证强一致性让用户易于理解。
- 数据持久化。etcd默认数据一更新就进行持久化。
- 安全。etcd支持SSL客户端安全认证。
最后,etcd作为一个年轻的项目,真正告诉迭代和开发中,这既是一个优点,也是一个缺点。优点是它的未来具有无限的可能性,缺点是无法得到大项目长时间使用的检验。然而,目前CoreOS、Kubernetes和CloudFoundry等知名项目均在生产环境中使用了etcd,所以总的来说,etcd值得你去尝试。
etcd实现原理解读
上一节中,我们概括了许多etcd的经典场景,这一节,我们将从etcd的架构开始,深入到源码中解析etcd。
原文较长,本文仅转载了前半部分,对etcd实现原理感兴趣的可以查看原文:http://www.infoq.com/cn/articles/etcd-interpretation-application-scenario-implement-principle
【平台中间件】为什么用etcd而不用ZooKeeper?从应用场景到实现原理的全方位解读的更多相关文章
- etcd:从应用场景到实现原理的全方位解读 转自infoq
转自 infoq etcd:从应用场景到实现原理的全方位解读 http://www.infoq.com/cn/articles/etcd-interpretation-application-scen ...
- 转:etcd:从应用场景到实现原理的全方位解读
原文来自于:http://www.infoq.com/cn/articles/etcd-interpretation-application-scenario-implement-principle ...
- etcd:从应用场景到实现原理的全方位解读
随着CoreOS和Kubernetes等项目在开源社区日益火热,它们项目中都用到的etcd组件作为一个高可用强一致性的服务发现存储仓库,渐 渐为开发人员所关注.在云计算时代,如何让服务快速透明地接入到 ...
- 【原创】开发Kafka通用数据平台中间件
开发Kafka通用数据平台中间件 (含本次项目全部代码及资源) 目录: 一. Kafka概述 二. Kafka启动命令 三.我们为什么使用Kafka 四. Kafka数据平台中间件设计及代码解析 五. ...
- 阿里巴巴为什么不用 ZooKeeper 做服务发现?
阿里巴巴为什么不用 ZooKeeper 做服务发现? http://jm.taobao.org/2018/06/13/%E5%81%9A%E6%9C%8D%E5%8A%A1%E5%8F%91%E7%8 ...
- 【分布式技术专题】「Zookeeper中间件」给大家学习一下Zookeeper的”开发伴侣”—Curator-Framework(基础篇)
CuratorFramework基本介绍 CuratorFramework是Netflix公司开源的一套Zookeeper客户端框架,它作为一款优秀的ZooKeeper客户端开源工具,主要提供了对客户 ...
- ZooKeeper典型应用场景
ZooKeeper典型应用场景一览 数据发布与订阅(配置中心) 发布与订阅模型,即所谓的配置中心,顾名思义就是发布者将数据发布到ZK节点上,供订阅者动态获取数据,实现配置信息的集中式管理和动态更新.例 ...
- ZooKeeper典型应用场景一览
原文地址:http://jm-blog.aliapp.com/?p=1232 ZooKeeper典型应用场景一览 数据发布与订阅(配置中心) 发布与订阅模型,即所谓的配置中心,顾名思义就是发布者将数据 ...
- ZooKeeper典型应用场景(转)
ZooKeeper是一个高可用的分布式数据管理与系统协调框架.基于对Paxos算法的实现,使该框架保证了分布式环境中数据的强一致性,也正是基于这样的特性,使得ZooKeeper解决很多分布式问题.网上 ...
随机推荐
- C# WebForm 屏蔽输入框的验证
按钮做界面跳转时,屏蔽输入框的验证可添加属性: CausesValidation="FALSE" <form runat="server"> &l ...
- 安装 node.js npm,cnpm
参考:https://blog.csdn.net/suiyuehuimou/article/details/74143436 https://www.liaoxuefeng.com/wiki/0014 ...
- Install CUDA 6.0 on Ubuntu 14.04 LTS
Ubuntu 14.04 LTS is out, loads of new features have been added. Here are some procedures I followed ...
- Javascript中的事件二
<!------------------示例代码一---------------------><!DOCTYPE html PUBLIC "-//W3C//DTD XHTM ...
- linux Linux入门
Linux入门 Linux学习什么? 常用命令(背会) 软件安装(熟练) 服务端的架构(开开眼界) Linux如何学习? 不要问那么多为什么,后面你就懒得问了 先尝试理解一下,不行就背下来 一个知识点 ...
- Java安全停止线程方法
1. 早期Java提供java.lang.Thread类型包含了一些列的方法 start(), stop(), stop(Throwable) and suspend(), destroy() and ...
- 5.1 Request 获取请求数据的几种方法
//获取请求头和请求数据 //请求数据(1.通过超链接 2.通过表单) //获取请求数据的时候一般来说 都要先检查 再使用 public class RequestDemo2 extends Http ...
- 【Distributed】大型网站高并发和高可用
一.DNS域名解析 二.大型网站系统应有的特点 三.网站架构演变过程 3.1 传统架构 3.2 分布式架构 3.3 SOA架构 3.4 微服务架构 四.高并发设计原则 4.1 拆分系统 4.2 服务化 ...
- 01_日志采集框架Flume简介及其运行机制
离线辅助系统概览: 1.概述: 在一个完整的大数据处理系统中,除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集.结果数据导出. 任务调度等不可或缺的辅助系统,而这些辅助 ...
- 自己手写实现Dubbo
目录 dubbo 简单介绍 为什么手写实现一下bubbo? 什么是RPC? 接口抽象 服务端实现 注册中心 消费者端: dubbo 简单介绍 dubbo 是阿里巴巴开源的一款分布式rpc框架. 为什么 ...