bert系列一:《Attention is all you need》论文解读
论文创新点:
- 多头注意力
- transformer模型
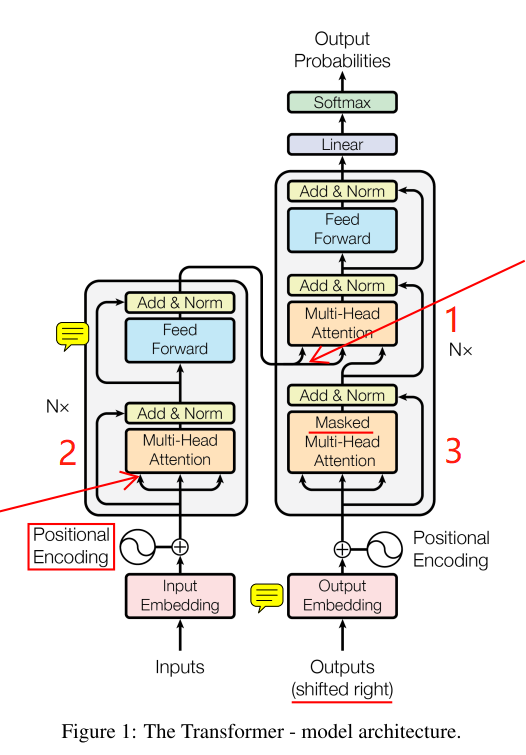
Transformer模型
上图为模型结构,左边为encoder,右边为decoder,各有N=6个相同的堆叠。
encoder
先对inputs进行Embedding,再将位置信息编码进去(cancat方式),位置编码如下:
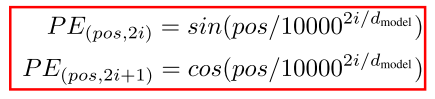
然后经过多头注意力模块后,与残余连接cancat后进行一个Norm操作,多头注意力模块如下:
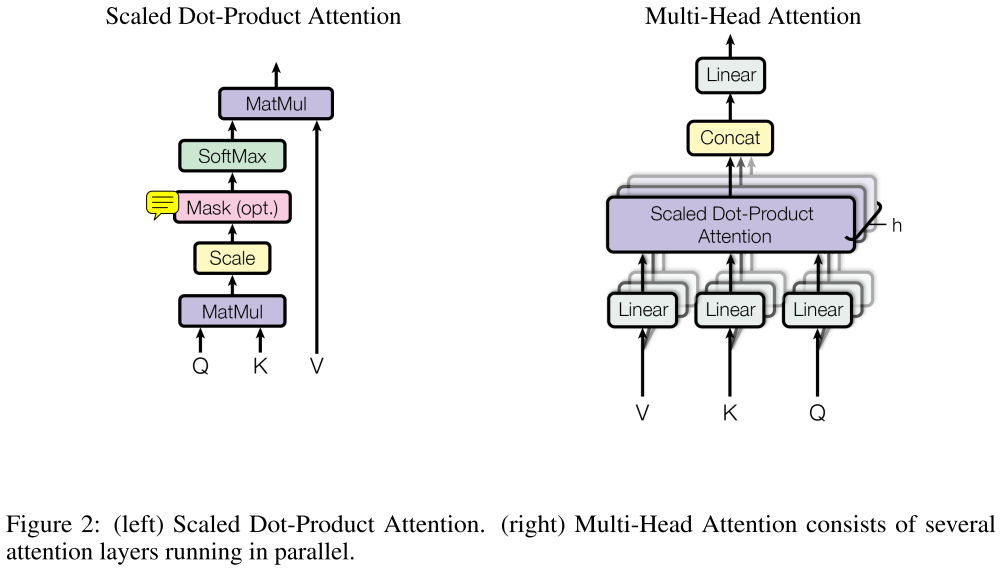
左图:缩放点乘注意力,这就是个平常的注意力机制,只不过多了scale和mask(仅对于decoder下面橙色框部分),使用的是dot-product attention,原文还提到另一种additive attention。
右图:多头注意力实现。每个Q,K,V都经过h个(不同)线性结构,以捕获不同子空间的信息,经过左图结构后,对h个dot-product attention进行concat后,再经过一个线性层。
之后,再通过一个有残余连接的前向网络。
decoder
同样先经过Embedding和位置编码,输入outputs右移了(因为每一个当前输出基于之前的输出)。
下面的橙色框:
之后也经过一个多头的self-attention,不同的是,它多了个mask操作。
这个mask操作是什么意思呢?注意我们的self-attention是一句话中每个词向量都与句子中所有词向量有关,对于encoder这没问题,而对于decoder,我们是根据之前的输出预测下一个输出。
举个例子,在BiLSTM中(当然这里是Transformer模型),假设我们decode时输入为A-B-C-D序列,在B处解码下一个输出时,我们根据之前的输出进行预测,但是这是双向模型,
即我们存在这样的一个之前的输出C-B-A-B,那么这个之前的输出里居然包含了我们下一个需要正确预测的C!这就是“自己看见自己”问题。
所以,mask操作是掩盖掉之后的位置(原文leftward,即向左流动的信息)的影响,原文是置为负无穷。这个橙色框我觉得可以称为half-self-attention。
最上面的橙色框:
它就不能叫self-attention结构了,因为它的K和V来自encoder的输出,Q是下面橙色框的输出。到这步为止,我们的输入inputs是完整的self-attention了,我们的输出outputs也是half-self-attention了。
好了,前戏准备完毕,开始短兵相接了。
这里的K和V一般相同,表示经过self-attention的隐藏语义向量,Q为经过half-self-attention的上一个输出,此处即为解码操作。经过一个有残余连接的前向网络,一个线性层,再softmax得到输出概率分布。
至此,Transformer模型描述完毕。
我们再看看self-attention模块,我之前一直不明白这些Q,K,V是啥东东。此处也是我个人推断。
在self-attention中,K,V表示当前位置的词向量,Q表示所有位置的词向量,用Q中每一个词向量与K进行操作(类似上面缩放点乘注意力截止到softmax),得到L个(L为句子单词数)权重向量。
此时应该有2种操作,一种是对L个权重向量相加,一种是取平均。得到的结果权重向量与V点乘,即为有self-attention后的词向量。
其余的实验及结果部分不再讲述,没什么难点。
这里再提下另一篇论文《End-To-End Memory Networks》中的一个模型结构。因为这篇论文被上面论文提到,对于理解上面论文有所帮助。
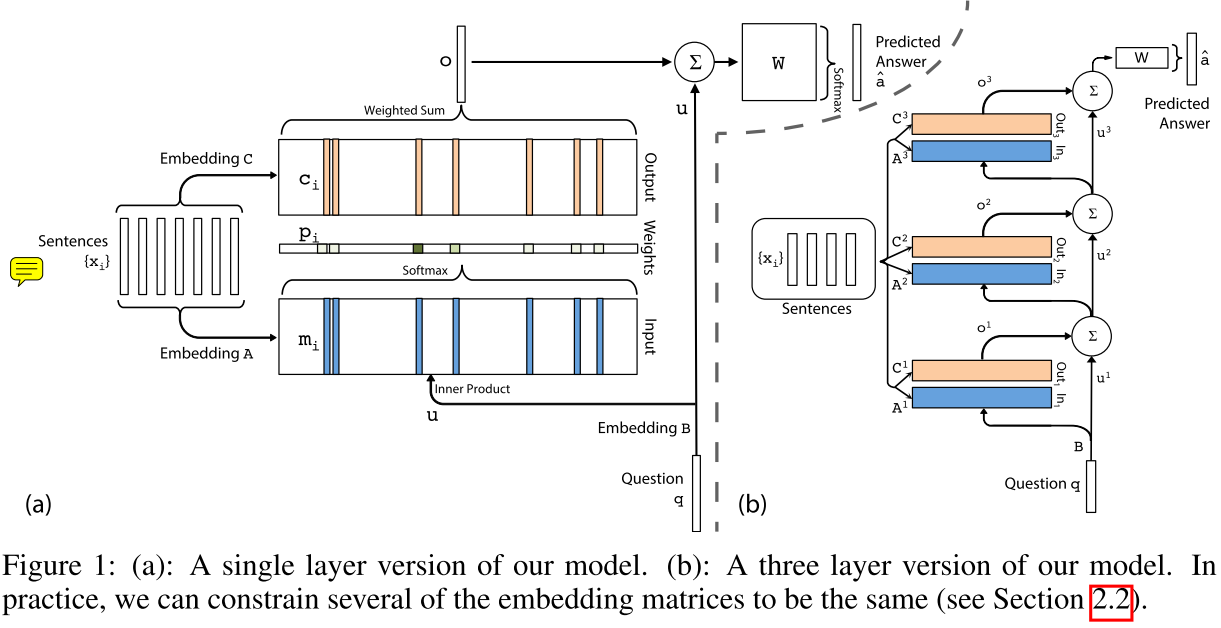
上图左边为单层,右边为多层版本。
单层的输出为:

Embedding B和C用于将输入x和问题q转化为嵌入向量,Embedding A用另一套参数将输出x转化为嵌入向量,与问题q共同决定注意力权重。
因为右图涉及到众多参数,为了简化模型,作者提出2种方案,这里直接上图:

这篇论文的创新点在于右图的多层版本类似RNNs,运算复杂度也比拟RNNs,避免了RNNs存在的一些问题。在QA问题上取得不错的成绩。
bert系列一:《Attention is all you need》论文解读的更多相关文章
- Bert系列 源码解读 四 篇章
Bert系列(一)——demo运行 Bert系列(二)——模型主体源码解读 Bert系列(三)——源码解读之Pre-trainBert系列(四)——源码解读之Fine-tune 转载自: https: ...
- Bert系列(三)——源码解读之Pre-train
https://www.jianshu.com/p/22e462f01d8c pre-train是迁移学习的基础,虽然Google已经发布了各种预训练好的模型,而且因为资源消耗巨大,自己再预训练也不现 ...
- bert系列二:《BERT》论文解读
论文<BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding> 以下陆续介绍ber ...
- Bert系列(二)——源码解读之模型主体
本篇文章主要是解读模型主体代码modeling.py.在阅读这篇文章之前希望读者们对bert的相关理论有一定的了解,尤其是transformer的结构原理,网上的资料很多,本文内容对原理部分就不做过多 ...
- nlp任务中的传统分词器和Bert系列伴生的新分词器tokenizers介绍
layout: blog title: Bert系列伴生的新分词器 date: 2020-04-29 09:31:52 tags: 5 categories: nlp mathjax: true ty ...
- Java容器--2021面试题系列教程(附答案解析)--大白话解读--JavaPub版本
Java容器--2021面试题系列教程(附答案解析)--大白话解读--JavaPub版本 前言 序言 再高大上的框架,也需要扎实的基础才能玩转,高频面试问题更是基础中的高频实战要点. 适合阅读人群 J ...
- 论文解读(FedGAT)《Federated Graph Attention Network for Rumor Detection》
论文信息 论文标题:Federated Graph Attention Network for Rumor Detection论文作者:Huidong Wang, Chuanzheng Bai, Ji ...
- BERT论文解读
本文尽量贴合BERT的原论文,但考虑到要易于理解,所以并非逐句翻译,而是根据笔者的个人理解进行翻译,其中有一些论文没有解释清楚或者笔者未能深入理解的地方,都有放出原文,如有不当之处,请各位多多包含,并 ...
- [Attention Is All You Need]论文笔记
主流的序列到序列模型都是基于含有encoder和decoder的复杂的循环或者卷积网络.而性能最好的模型在encoder和decoder之间加了attentnion机制.本文提出一种新的网络结构,摒弃 ...
随机推荐
- Java 对象序列化和反序列化 (实现 Serializable 接口)
序列化和反序列化的概念 把对象转换为字节序列的过程称为对象的序列化. 把字节序列恢复为对象的过程称为对象的反序列化. 对象的序列化主要有两种用途: 1) 把对象的字节序列永久地保存到硬盘上,通常存放 ...
- php类知识---命名空间
<?php #命名空间namespace用来解决类的命名冲突,和引用问题 namespace trainingplan1; class mycoach { public function tra ...
- 题解 【NOI2010】超级钢琴
[NOI2010]超级钢琴 Description 小Z是一个小有名气的钢琴家,最近C博士送给了小Z一架超级钢琴,小Z希望能够用这架钢琴创作出世界上最美妙的音乐. 这架超级钢琴可以弹奏出n个音符,编号 ...
- 什么是URL百分号编码?
㈠什么是URL 统一资源定位系统(uniform resource locator;URL)是因特网的万维网服务程序上用于指定信息位置的表示方法. ㈡URL编码 url编码是一种浏览器用来打包表单输入 ...
- VirtualBox 安装CentOS虚拟机网卡配置
VirtualBox虚拟机网络设置(NAT+HOST-ONLY) 目标: 虚拟机可以像宿主机一样访问互联网和其他主机 宿主机和虚拟机可以相互访问 使用NAT实现目标一 使用Host-Only实现目标二 ...
- java+上传大视频文件断点续传
上周遇到这样一个问题,客户上传高清视频(1G以上)的时候上传失败. 一开始以为是session过期或者文件大小受系统限制,导致的错误. 查看了系统的配置文件没有看到文件大小限制, web.xml中s ...
- LibreOffice/Calc:取消单元格中的超链接
造冰箱的大熊猫@cnblogs 2019/2/27 在LibreOffice Calc的表格中输入电子邮箱地址或者网址后,软件会自动将输入内容转换为超链接形式显示.在某些情况下这种自动转换并非用户所 ...
- 11.EL(表达式语言)
一.EL概述 EL(Expression Language,表达式语言)是JSP2.0 中引入的新内容.通过EL可以简化在JSP中对对象的引用,从而规范页面代码,增加程序的可读性和可维护性. 1.EL ...
- AtCoder Dwango Programming Contest V E
题目链接:https://dwacon5th-prelims.contest.atcoder.jp/tasks/dwacon5th_prelims_e 题目描述: 给定一个大小为\(N\)的数组\(A ...
- TensorFlow使用记录 (六): 优化器
0. tf.train.Optimizer tensorflow 里提供了丰富的优化器,这些优化器都继承与 Optimizer 这个类.class Optimizer 有一些方法,这里简单介绍下: 0 ...