用python做线性规划
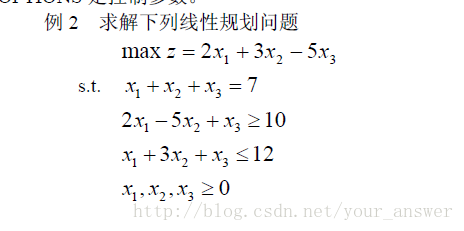
scipy.optimize.linprog(c, A_ub=None, b_ub=None, A_eq=None, b_eq=None, bounds=None, method='simplex', callback=None, options=None)
from scipy import optimize as op
import numpy as np
c=np.array([2,3,-5])
A_ub=np.array([[-2,5,-1],[1,3,1]])
B_ub=np.array([-10,12])
A_eq=np.array([[1,1,1]])
B_eq=np.array([7])
x1=(0,7)
x2=(0,7)
x3=(0,7)
res=op.linprog(-c,A_ub,B_ub,A_eq,B_eq,bounds=(x1,x2,x3))
print(res)
很容易发现,c指的应该是要求最大值的函数的系数数组,A_ub是应该是不等式未知量的系数矩阵,仔细观察的人应该发现,为什么第一行里面写的是[-2,5,-1]而不是[2,5,-1]呢,应该要与图里对应才对啊,原来这不等式指的是<=的不等式,那如果是>=呢,乘个负号就行了。A_eq就是其中等式的未知量系数矩阵了。B_ub就是不等式的右边了,B_eq就是等式右边了。bounds的话,指的就是每个未知量的范围了。我们看一下结果
con: array([0.])
fun: -14.571428571428571
message: 'Optimization terminated successfully.'
nit: 8
slack: array([0. , 3.85714286])
status: 0
success: True
x: array([6.42857143, 0.57142857, 0. ])
重点关注的就是第一行和最后一行了,第一行是整个结果,最后一行是每个x的结果。为什么第一行是负的呢?原来这个函数其实是求最小值的,那么求最大值,怎么办呢?很简单,仔细观察的人应该发现,之前的函数里面,我写的是-c,而不是c。那么这个函数的出来的结果其实就是-c的最小值,但很明显这恰恰是c最大值的相反数。那么答案就是14.57了,以上。
---------------------
作者:your_answer
来源:CSDN
原文:https://blog.csdn.net/your_answer/article/details/79131000
版权声明:本文为博主原创文章,转载请附上博文链接!
用python做线性规划的更多相关文章
- 万字教你如何用 Python 实现线性规划
摘要:线性规划是一组数学和计算工具,可让您找到该系统的特定解,该解对应于某些其他线性函数的最大值或最小值. 本文分享自华为云社区<实践线性规划:使用 Python 进行优化>,作者: Yu ...
- 使用python做科学计算
这里总结一个guide,主要针对刚开始做数据挖掘和数据分析的同学 说道统计分析工具你一定想到像excel,spss,sas,matlab以及R语言.R语言是这里面比较火的,它的强项是强大的绘图功能以及 ...
- 12岁的少年教你用Python做小游戏
首页 资讯 文章 频道 资源 小组 相亲 登录 注册 首页 最新文章 经典回顾 开发 设计 IT技术 职场 业界 极客 创业 访谈 在国外 - 导航条 - 首页 最新文章 经典回顾 开发 ...
- [原创博文] 用Python做统计分析 (Scipy.stats的文档)
[转自] 用Python做统计分析 (Scipy.stats的文档) 对scipy.stats的详细介绍: 这个文档说了以下内容,对python如何做统计分析感兴趣的人可以看看,毕竟Python的库也 ...
- 这几天有django和python做了一个多用户博客系统(可选择模板)
这几天有django和python做了一个多用户博客系统(可选择模板) 没完成,先分享下 断断续续2周时间吧,用django做了一个多用户博客系统,现在还没有做完,做分享下,以后等完善了再慢慢说 做的 ...
- 用python做中文自然语言预处理
这篇博客根据中文自然语言预处理的步骤分成几个板块.以做LDA实验为例,在处理数据之前,会写一个类似于实验报告的东西,用来指导做实验,OK,举例: 一,实验数据预处理(python,结巴分词)1.对于爬 ...
- 《用Python做HTTP接口测试》学习感悟
机缘巧合之下,报名参加了阿奎老师发布在"好班长"的课程<用Python做HTTP接口测试>,报名费:15rmb,不到一杯咖啡钱,目前为止的状态:坚定不移的跟下去,自学+ ...
- 使用Python做简单的字符串匹配
由于需要在半结构化的文本数据中提取一些特定格式的字段.数据辅助挖掘分析工作,以往都是使用Matlab工具进行结构化数据处理的建模,matlab擅长矩阵处理.结构化数据的计算,Python具有与matl ...
- python做量化交易干货分享
http://www.newsmth.NET/nForum/#!article/Python/128763 最近程序化交易很热,量化也是我很感兴趣的一块. 国内量化交易的平台有几家,我个人比较喜欢用的 ...
随机推荐
- HashMap 和 Hashtable 有什么区别?(未完成)
HashMap 和 Hashtable 有什么区别?(未完成)
- tensorflow模型的保存与恢复,以及ckpt到pb的转化
转自 https://www.cnblogs.com/zerotoinfinity/p/10242849.html 一.模型的保存 使用tensorflow训练模型的过程中,需要适时对模型进行保存,以 ...
- BZOJ 1093 强连通缩点+DAG拓扑DP
缩点后在一个DAG上求最长点权链 和方案数 注意转移条件和转移状态 if (nowmaxn[x] > nowmaxn[v]) { ans[v] = ans[x]; nowmaxn[v] = no ...
- MyBatis-06-日志
6.日志 6.1.日志工厂 如果一个数据库操作,出现了异常,我们需要排错.日志就是最好的助手! 曾经:sout.debug 现在:日志工厂 SLF4J LOG4J[掌握] LOG4J2 JDK_LOG ...
- 【概率dp】vijos 3747 随机图
没有养成按状态逐步分析问题的思维 题目描述 在一张图内,两点$i,j$之间有$p$的概率的概率生成一条边.求该图不出现大小$\ge 4$连通块的概率. $n \le 100,答案在实数意义下$ 题目分 ...
- 【换根dp】9.22小偷
换根都不会了 题目大意 给定一棵$n$个点的树和树上一撮关键点,求到所有$m$个关键点距离的最大值$dis_{max}\le LIM$的点的个数. $n,m\le 30000,LIM\le 30000 ...
- C# ado.net 操作存储过程(二)
调用存储过程 sql IF OBJECT_ID('RegionInsert') IS NULL EXEC (' -- -- Procedure which inserts a region recor ...
- Win2008 R2 IIS FTP防火墙的配置
注意以下两个选项要在防火墙下开启,否则将会访问失败.
- O(1)快速乘与O(log)快速乘
//O(1)快速乘 inline LL quick_mul(LL x,LL y,LL MOD){ x=x%MOD,y=y%MOD; return ((x*y-(LL)(((long d ...
- Jenkins忘记admin密码补救措施
遇到将Jenkins登录名密码忘记的情况,下面的方式可以重置密码. 进入C:\Program Files (x86)\Jenkins\users 目录可以看到admin开头的文件夹,里面有个confi ...