nutch 1.7 导入 eclipse
开发环境建议:ubuntu+eclipse (windows + cygwin + eclipse不推荐) 第一步:下载
http://archive.apache.org/dist/nutch/
从上述站点下载src和bin两个压缩文件
wget 'http://archive.apache.org/dist/nutch/1.7/apache-nutch-1.7-bin.tar.gz'
wget 'http://archive.apache.org/dist/nutch/1.7/apache-nutch-1.7-src.tar.gz' 第二步:解压
tar zxvf apache-nutch-1.7-bin.tar.gz
解压出一个 apache-nutch-1.7 文件夹
重命名: mv apache-nutch-1.7 apache-nutch-1.7-bin tar zxvf apache-nutch-1.7-src.tar.gz
解压出一个 apache-nutch-1.7 文件夹
重命名: mv apache-nutch-1.7 apache-nutch-1.7-src 第三步:组合
将apache-nutch-1.7-bin/lib中的所有jar包拷贝到apache-nutch-1.7-src/lib中
cp apache-nutch-1.7-bin/lib/* apache-nutch-1.7-src/lib/
将apache-nutch-1.7-bin/conf中的配置文件覆盖apache-nutch-1.7-src/conf中 第四步:导入eclipse
eclipse : File -- New -- Java Project
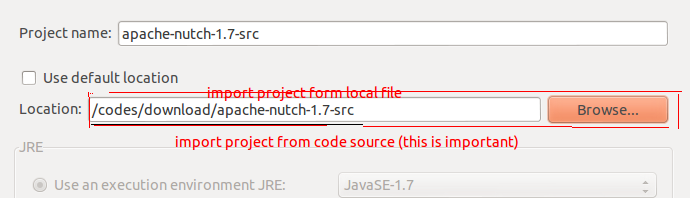
这一步完成了将源码(而非工程)导入eclipse
注解:笔者以前用的eclipse版本有import project from source ,但这个版本没有,只有import project from existing project.而我们只有src文件 点击NEXT
找到 conf 文件夹 ,然后点击 Add Folder 'conf' to build path
defautl output 设置为 apache-nutch-1.7/bin 点击Finish 第四步:一些小BUG
此时会发现工程有错误(红色的小叉叉),这是因为缺少引用导致的。
以parse-html为例:
import org.cyberneko.html.parsers.*;
这里报错是因为缺少 nekohtml-0.9.5.jar 如何获取nekohtml-0.9.5.jar:
到apache-nutch-1.7-bin/plugin 下搜索 nekohtml 就能找到这个jar包
然后复制到项目的lib文件夹里并add to build path 其他bug以此类推(所有的jar都可以在apache-nutch-1.7-bin/plugin 下找到 feed
cp apache-nutch-1.7-bin/plugins/feed/rome-0.9.jar apache-nutch-1.7-src/lib/
parse-html
cp apache-nutch-1.7-bin/plugins/parse-html/tagsoup-1.2.1.jar apache-nutch-1.7-src/lib/
cp apache-nutch-1.7-bin/plugins/lib-nekohtml/nekohtml-0.9.5.jar apache-nutch-1.7-src/lib/
至此整个工程将不会有任何错误了。 第五步:测试采集
1.vim conf/nutch-defalut.xml -----vim
/plugin.forlder ---vim查找命令
修该为:
<property>
<name>plugin.folders</name>
<value>./src/plugin</value>
<description>Directories where nutch plugins are located. Each
element may be a relative or absolute path. If absolute, it is used
as is. If relative, it is searched for on the classpath.</description>
</property>
原因:源代码文件中 plugin在src文件夹里,但在bin文件中plugin 在根目录下。
2 vim conf/nutch-site.xml 加入:
<property>
<name>http.agent.name</name>
<value>your sipder name</value>
</property>
3 在apache-nutch-1.7-src下建立一个urls文件夹,在urls下面建一个文本文档
mkdir urls
cd urls
vim seed.txt
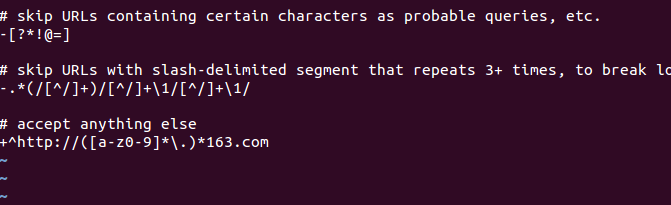
写入:http://www.163.com/ 4 vim conf/regex-urlfilter.txt
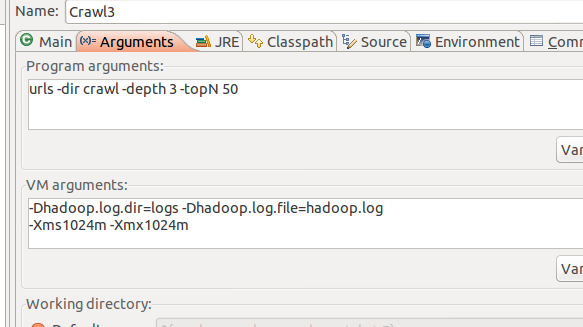
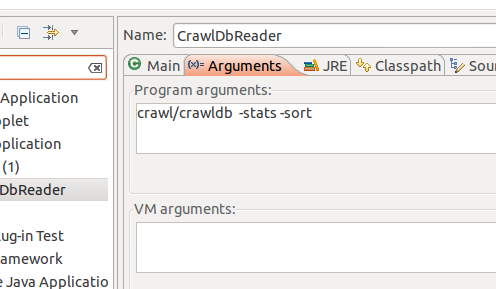
5 运行配置:

运行结果:
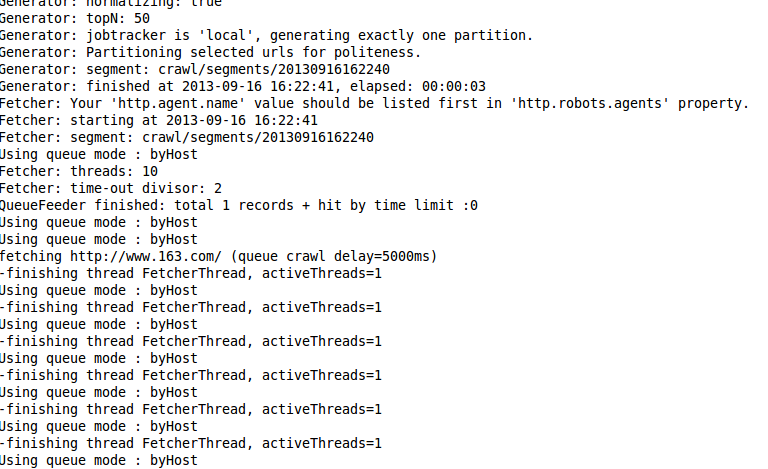
至此运行成功。
检测采集结果:
统计结果:(unfetched比较多是因为nutch给url打分,过滤掉了分数小于0的,这个可以在nutch-default.xml中修改)
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - Statistics for CrawlDb: crawl/crawldb
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - TOTAL urls:
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - retry :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - min score: 0.0
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - avg score: 0.003186398
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - max score: 1.007
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - status (db_unfetched):
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - 3g..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - auto..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - baby..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - baoxian..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - bbs..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - bbs.culture..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - bbs.ent..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - bbs.lady..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - biz..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - blog..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - book..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - caipiao..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - cbachina..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - club.auto..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - corp..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - data.ent..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - digi..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - discovery..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - dl..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - ecard..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - edu..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - email..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - emarketing.biz..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - ent..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - expo..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - fashion..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - focus.news..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - fushi..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - game..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - gb.corp..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - hea..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - help..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - history.news..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - home..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - house..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - hr..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - jiu..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - kf.yxp..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - lady..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - live.caipiao..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - love..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - lovegongyi..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - m..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - media..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - mibao.gm..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - mobile..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - money..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - news..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - news.tag..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - newsapp.blog..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - pay..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - pic.auto..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - post.news..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - product.auto..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - qiye..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - quotes.money..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - reg..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - sports..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - survey2..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - t..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - tech..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - travel..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - tveasy.blog..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - v..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - v.money..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - v.news..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - v.sports..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - vipmail..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - vs.caipiao..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - wangyiyuedu.blog..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - war.news..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - www..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - yuedu..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - zx.caipiao..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - zz.yc..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - status (db_fetched):
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - caipiao..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - corp..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - digi..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - emarketing.biz..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - gb.corp..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - help..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - love..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - m..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - music..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - newsapp.blog..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - open..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - open.yuedu..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - sitemap..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - t..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - tech..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - www..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - yuedu..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - zz.yc..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - status (db_redir_temp):
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - 3g..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - m..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - status (db_redir_perm):
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - caipiao..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - corp..com :
-- ::, INFO crawl.CrawlDbReader (CrawlDbReader.java:processStatJob()) - CrawlDb statistics: done
nutch 1.7 导入 eclipse的更多相关文章
- nutch 1.7导入Eclipse
1.下载Nutch1.7的包 apache-nutch-1.7-src.zip,解压之后应该包括 bin,conf,src等目录 2.将解压之后的 apache-nutch-1.7 文件夹放到ecli ...
- spring源码解析——spring源码导入eclipse
一.前言 众所周知,spring的强大之处.几乎所有的企业级开发中,都使用了spring了.在日常的开发中,我们是否只知道spring的配置,以及简单的使用场景.对其实现的代码没有进行深入的了 ...
- 如何将MyEclipse项目导入eclipse
我们经常会在网上下载一些开源项目,或者从别的地方迁移一些项目进来,但经常会发现导入后各种报错.这是初学java肯定会遇到的问题,本文对一些常见的处理方案做一个总结.(本文将MyEclipse项目导入e ...
- Android Studio 2.2.2导入Eclipse中创建的项目
最近随视频教程学习Android,原本都是用Adt写Android程序,中途教程换成了Android Studio,于是我自己下了android studio 2.2.2安装好,并下载好sdk,也跟着 ...
- 开源项目导入eclipse的一般步骤
开源项目导入eclipse的一般步骤 周银辉 下载到开源项目后,我们还是希望导入到eclipse中还看,这样要方便点,一般的步骤是这样的 打开源代码目录, 如果看到里面有.calsspath .pro ...
- svn工具安装下载Tomcat源码以及导入eclipse
安装 1.svn下载地址 https://tortoisesvn.net/downloads.html 2.语言包下载 3.先安装svn,在直接安装语言包 4.桌面右键可以看到相关svn信息 下载To ...
- Openfire3.9.3源代码导入eclipse中开发配置指南
这篇文章向大家介绍一下,如何把openfire3.9.3源码导入eclipse中,编译并启动的详细过程. 首先得感谢这篇文章的作者,http://www.micmiu.com/opensource/o ...
- Tomcat源码导入eclipse的步骤
Tomcat源码导入eclipse 一.下载源码 1. 进入Apache 官网:http://tomcat.apache.org/ 2. 在左边侧选择要下载的源码的版本. 3. 或者直接通过Ar ...
- Git项目存放位置在导入Eclipse前不能存放在Eclipse Workspace
这篇帖子的背景: 本人想将一个git项目导入至Eclipse的Workspace中,并且该项目的所有git信息.但是,该git项目在导入之前,就已经存放在Eclipse的Workspace中.在将该g ...
随机推荐
- MVC入门教程-视图中的Layout使用
本文目标 1.能够重用Razor模板进行页面的组件化搭建 本文目录 1.母板页_Layout.cshtml 2.用户自定义控件 3.默认Layout引用的使用(_ViewStart.cshtml) 1 ...
- c# 请问如何将四个RadioButton分成两组?
WinForm 只要放在同一个容器中的RadioButton 就自动互斥 创建两个panel容器,分别放两个RadioButton 就是两组了
- Spring Data Redis简介以及项目Demo,RedisTemplate和 Serializer详解
一.概念简介: Redis: Redis是一款开源的Key-Value数据库,运行在内存中,由ANSI C编写,详细的信息在Redis官网上面有,因为我自己通过google等各种渠道去学习Redis, ...
- 如何判断Android系统的版本
随着Android版本的增多,在不同的版本中使用不同的设计是必须的,根据程序运行的版本来提供不同的功能.这涉及到如何在程序中判断Android系统的版本. 在Android api中的android. ...
- JSP 内置对象的四种属性范围
在jsp页面中的对象,包括用户创建的对象(例如,javaBean对象)和JSP的隐含对象,都有一个范围属性.范围定义了在什么时间内,在哪一个JSP页面中可以访问这些对象.例如,session对象在会话 ...
- php通过文件头检测文件类型通用类(zip,rar…)(转)
在做web应用时候,通过web扩展名判断上存文件类型,这个是我们常使用的.有时候我们这样做还不完善.可能有些人上存一些文件,但是他通过修改 扩展名,让在我们的文件类型之内. 单实际访问时候又不能展示( ...
- Unity monodev环境搭建
断点调试功能可谓是程序员必备的功能了.Unity3D支持编写js和c#脚本,但很多人可能不知道,其实Unity3D也能对程序进行断点调试的.不过这个断点调试功能只限于使用Unity3D自带的MonoD ...
- jquery刷新iframe页面的方法
1,reload 方法,该方法强迫浏览器刷新当前页面. 语法:location.reload([bForceGet]) 参数: bForceGet, 可选参数, 默认为 false,从客户端缓存里取当 ...
- 触发器-Trigger
--触发器的实例: Create Table Student( --学生表 StudentID int primary key, --学号 ...
- 一个jquery的图片下拉列表 ddSlick
[ddSlick]http://designwithpc.com/Plugins/ddSlick How to use with JSON data Include the plugin javasc ...