C# - 类型
引用类型(Reference Type)
C#是一门使用OOP技术的编程语言(Object Oriented Programming 面向对象编程)面向对象最重要的特性就是接口、继承、多态 C#中所有的事物都可以看做是一个对象,对象由类型来创造,而类型就相当于一个蛋糕模型,将面粉填满这个模型且送进烤箱,最后烘焙出来的就是对象。烘焙的过程即对象诞生的过程,在面向对象编程的世界里这个过程被称为实例化对象,一旦创建完成,则该对象就有了该类型的属性、字段、方法等一切可以被对象访问的事物。类型本质上则是一个组合了方法及其相关数据的一个包容体。当我们存放的数据不能用一个简单的基元类型来存储的时候,就可以使用这种复杂的类型了。
类(Class)
类型修饰符
类有两种类型的修饰符,权限修饰符和形态修饰符,权限是必须的修饰符,而形态总是可选的项。
//定义类的格式:
权限修饰符 形态修饰符 class关键字 类名称
//因为类的默认权限是internal 所以权限修饰符就变成可选的
//形态修饰符本身就是可选的 所以最终格式可以是这样:class关键字 类名称
1.权限修饰
用于定义类型的访问权限。
Ⅰ.internal(内部) 默认
该类只能在定义它的命名空间中被访问。 如果没有特殊需求,一般都将类设为public,因为internal的类不能在它所属于的命名空间之外被访问,也就失去了类作为封装数据并提供复用操作的意义,所以为什么不将public设为默认项而将internal设为默认项,有点搞不明白。
Ⅱ.public(公有)
该类可以在任何命名空间中被访问。
2.形态修饰
用于定义类型的形态。
Ⅰ.abstract(抽象)
该类不能new,可继承。可以这样理解:抽象的东西是无形之物,因为其无形,所以无法new出具体的样貌,但具体的事物可以从其派生,因为具体的事物全部源自无形的虚空。
Ⅱ.sealed(密封)
该类不能继承,可new。可以这样理解:封闭之物是尊崇自我的有形之物,因为其有形,所以可new出具体的样貌,但不能从其派生。因为它完全彻底的封闭自我,它不结婚生子,所以不可能从其派生。
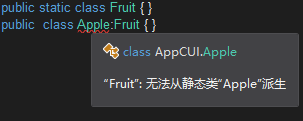
Ⅲ.static(静态)
在内存中是唯一的,综合了抽象和密封的特点,也即它不能new、不能从其派生。

定义类
定义类时, 先声明权限,再声明形态(可选), 如:
public class Myclass
{
//成员略……
}
定义抽象类
抽象类提供能体现某些基本行为的成员,但只做声明而无具体的实现逻辑。抽象类是不能被实例化的。派生自抽象类型的子类型必须override基类的所有抽象成员。如果不实现,则子类型也必须声明为是抽象类型。另外,抽象类既可以定义抽象成员同时也可以定义非抽象的成员。但字段不能声明为抽象字段,成员只有抽象属性和抽象方法。
public abstract class 虚无
{
public abstract string 幻象 { get; set; } //抽象属性
public abstract void 涅盘(); //没有方法体,这是一个抽象方法
} public class 存在 : 虚无
{
public override string 幻象 { get { return "无垠"; } set { 幻象 = value; } }
public override void 涅盘()
{ }
}
派生类重写抽象基类的成员,那么这些重写的成员实现就属于抽象基类,抽象类用于为多个类型所共有的某些成员提供一个共享但可重写的机会,用抽象类作为其他类型所依赖的类型,以便达到运行时动态确定抽象类的具体类型,使类型之间的耦合关系具有一定的灵活性。
{
public abstract void Test( );
}
public class B : A
{
public override void Test( )
{
Console.WriteLine( "xxx" );
}
}
public class Programe
{
static void Main( string[] args )
{
A a = new B( ); //B重写了A的Test方法,然后隐式转换为A
a.Test( ); //调用已经被B重写的A.Test方法 print xxx
}
}
定义密封类
密封类主要用于防止被派生、被外部扩展。正因为它不能被派生,所以它不可能是基类。但它可以被实例化,这种特性在某些情况下与面向对象编程技术的灵活性和可扩展性是相抵触的,通常不建议使用密封类型。要声明密封类只需加上sealed形态修饰符,密封类的这种特性使其从不用作基类,因此在性能上对密封类成员的调用速度会略快。
定义静态类
如果自定义的类是一个static的则应该将它的所有成员也定义为static。因为这样的类不能被实例化,逻辑上就不需要具备对象才可以访问的实例成员。
初始化对象
初始化就是为对象在内存上划分空间。使用new操作符调用构造函数可以在内存堆上分配一块空白区域,new在这块区域中创建出对象的this成员,并将对象的内存地址存入this中返回。这样就完成了一个对象的创建。 默认每个类都自动拥有一个无参版的构造函数,你可以不显示写出类的构造函数,这样,你的类将具备默认的无参构造函数,new对象时调用的正是这个默认无参的构造函数去初始化对象的。
public class Animal { public string name; } //没有定义自己的构造函数,这样它将获得默认无参的构造函数
Animal a = new Animal ( );
如果显示写出了无论是无参或有参版的构造函数,那么默认构造函数将会自动隐藏。
初始化成员
new调用构造函数,构造函数根据对象的所有成员所能占用的空间大小(位数)去计算出结果,然后在内存堆上划分对应大小的空间来存储这些成员。总结一下就是这样:new操作符调用构造函数 - 构造函数隐式地计算出类的成员和对象的成员所能占用的内存空间大小 - 再分配内存 - 在堆上存储this地址引用和初始化每一个成员,如果成员没有被你手动赋值,则对它们应用为其类型所对应的默认值(值类型总是=0,引用类型总是=null),如果成员已经被手动赋值,就将值放进内存中 - 进入构造函数方法体,如果有语句则执行,否则退出。也即在完成前面一系列工作后才会进入构造函数的方法体扫描代码。而初始化成员的值虽然由构造函数自动完成,但你也可以利用构造函数,在方法体内手动为成员赋一个你期望的值。引用类型的成员其默认值是null,null的变量被视为已赋值,所以你可以输出它而不会抛错,而未赋值的变量!=null,未赋值的变量不能访问,这两者有本质的区别。 为了确定构造函数(无论有参无参)初始化对象时确实计算并初始化了所有的成员并为它们赋了默认值,可参考下面简单的代码:
public class Animal
{
public string Name;
public int FoodCount;
} public class Programe
{
static void Main( string [ ] args )
{
Animal a = new Animal( ); //流程:初始化Animal对象,分配内存,初始化成员字段name,然后进入构造函数代码体,代码体无可执行语句,退出。
Console.WriteLine( a.Name == null ); //print true
Console.WriteLine (a.FoodCount == ); //print true
}
}
public class Animal
{
public string name;
public Animal(string xName)
{
name = xName;
}
}
Animal a = new Animal ( "蚂蚁" );
//流程:计算Animal对象的成员占用的空间大小,在堆上分配内存,初始化它的成员字段name,进入构造函数代码体,代码体存在一段为name字段赋新值的代码,执行后退出。
再来看一个例子,当类内部声明一个成员字段时显示为其赋了值,尔后又在构造函数中为其赋值,那么最终该成员字段的值是什么呢?按照以上的初始化流程应该很容易知道答案了:
public class Animal
{
public string Name = "cat";
public int FoodCount = ;
public Animal( )
{
Name = "dog";
FoodCount = ;
}
} public class Programe
{
static void Main(string [ ] args)
{
Animal a = new Animal( );
//流程:计算Animal对象的成员占用的空间大小,在堆上分配内存,初始化成员字段Name和FoodCount,然后进入构造函数代码体,代码体存在一段为两个字段赋新值的代码,执行后退出。
//于是输出结果为:
Console.WriteLine( a.Name ); //print dog
Console.WriteLine( a.FoodCount ); //print 200
}
}
新的初始化器
C#3.0中可以使用新语法来初始化对象,新的语法允许一个类在具备无参构造函数的前提下可以使用new操作符在初始化对象的同时为对象的成员赋值,如果类不存在无参构造函数则不能使用下面的语法。也即如果你的类定义了有参的构造函数,则必须显示指定一个无参版的构造函数,否则这种语法不能正常工作,因为它总是调用无参构造器来初始化对象和为对象的成员赋值。但是通常我们还是需要定义有参版构造函数,因为这样可以明确通知用户,我需要你提供哪些参数来初始化对象,而不是让用户利用初始化器来自己任意初始化成员。
public class Animal
{
public string name;
public Animal( )
{ }
}
Animal a = new Animal { name = "蚂蚁" };
//流程:计算Animal对象的成员占用的空间大小,在堆上分配内存,初始化成员字段name,然后进入{}代码体,代码体存在一段为name字段赋新值的代码,执行后退出。
new操作符的用途
调用构造函数初始化对象、对象初始化器(初始化对象时可初始化对象的成员)、初始化匿名对象、隐藏基类成员。
this和base关键字
this是new操作符隐式创建的对象的成员,这个成员存储的地址就是该对象,在类内部任何处都可以使用this访问到该对象。而base是派生类的基类,base是一个隐式创建的基对象,它存储基类对象在内存的地址。也即当你new一个Animal对象时,首先在内存中会创建Animal的基类object的实例,在派生类内部任何处都可以使用base访问到基对象,也即如果在派生类内部通过base访问基类成员,则说明调用base时已经隐式的在内存中创建了一个基类的实例。
匿名对象
使用关键字var可以创建一个匿名对象,这不需要类型做模板,如下所示:
var obj = new { Name = "sam" , Age = };
匿名对象的属性是只读,不可写的。可以将两个相等的匿名对象进行相互赋值。
var y= new { name = "leo", age = "20" };
x = y;
Console.WriteLine(x.name); //print leo
匿名对象也可以调用Equals方法,与具名对象(有类型的对象)的同名方法不一样。该方法会测试该匿名对象的每个属性的值与另一个匿名对象的属性的值是否相等(值相等或引用地址相等)且属性出现的先后顺序是否相同,如果为真则认为两个匿名对象是相等的。
定义实例构造函数
构造函数在类型中定义,是类型的成员,new操作符正是调用构造函数来为对象做初始化工作的。构造函数可以是public、private、protected的,且其名称与类名必须相同,构造函数没有返回值,也不能return。
快速定义构造函数
键入ctor 连续按tab键两次,自动生成构造器。
构造函数重载
C#支持名称重复的函数名,重名的函数称为函数重载。但名称重复的函数必须具有不同的函数签名。对于构造函数来说,一旦构造函数重载,默认隐藏的无参构造函数就会被替换掉因而无法调用。
不同的方法签名
1.参数类型不同 | 2.参数个数不同 | 3.泛型类型参数不同 | 4.有无ref、out、params关键字的不同
外部代码块在调用同名的方法时会自动根据传递的参数的类型或参数个数来确定要调用的是哪一个方法。
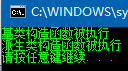
构造函数执行的顺序
如果实例化一个派生类,new操作符将逐层从上往下调用各个当前类型的基类的构造函数,默认情况下最开始调用的一定是System.Object类的Object构造函数。这是因为如果没有调用基类构造函数则派生类实例根本不可能得到基类的成员。
一个测试:
public class BaseClass
{
public BaseClass() { Console.WriteLine("基类构造函数被执行"); }
} public class Myclass : BaseClass//此处表示该类将从指定的基类派生
{
public Myclass()
{
Console.WriteLine("派生类构造函数被执行");
}
} class Program
{
static void Main(string[] args)
{
Myclass myclass = new Myclass();
}
}
输出结果为
指定基类构造函数
默认调用的是基类的无参版构造函数,也可以在函数括号后使用base关键字明确指定基类要执行的是哪个版本的构造函数。
public class BaseClass
{
public BaseClass( ) { Console.WriteLine ( "正在执行基类无参构造函数" ); }
public BaseClass( string name ) { Console.WriteLine ( "正在执行基类带参构造函数" ); }
} public class Myclass : BaseClass
{
public Myclass( string name ) : base ( name ) //转接到基类带参构造函数上
{
Console.WriteLine ( "正在执行派生类构造函数" );
}
}
抽象类也可以定义构造函数,但我们并不能用这个构造函数来初始化抽象实例,它只能由子类的构造函数去实现
{
public string Name { get; set; }
public AbstractClass(string name )
{
this.Name = name;
}
}
public class A : AbstractClass
{
//子类向抽象超类传递参数初始化抽象类的Name成员
public A( string name ) : base( name ) { }
}
构造函数转接
可以在函数括号后使用this关键字把当前执行的构造函数转接到另一个构造函数上去。
public class Test
{
public int ID;
public int Score;
public Test( int result ) : this ( result , result )//转接到带参构造函数
{
}
public Test( int id , int score ) { this.ID = id; this.Score = score; }
} Test t = new Test ( );
静态构造函数
静态构造函数的作用是初始化类的成员(被修饰为static)。与实例构造函数一样,每个类都具备一个默认的静态构造函数,也可以显示指定一个。但不能显示调用它,处于下面两种情况时会自动执行静态构造函数
初始化类成员的时期
1.当使用new操作符创建对象时
2.当访问静态成员时
静态构造函数只会执行一次
静态构造函数禁止指定权限修饰符,它作为类的成员只会被执行一次,也即new出对象时,或使用静态类访问成员时,静态构造函数会自动执行,但当再次new对象时,或再次访问成员时,静态构造函数就不会再执行了,这是因为类成员不同于对象成员,对象成员的所有权归对象所有,每创建一个对象都会在当前对象所在的内存区块中创建出对象的成员,多个对象之间各自维护着自己的成员,而类成员的所有权归属于类,是属于当前类的全局成员,只会在内存中创建一次,也即静态构造函数只可能被执行一次,在内存中为类创建好其成员后就不会再次执行。
public class Test
{
public static string none;
static Test ( ) //实例构造函数使用public修饰、静态构造函数使用static修饰
{
Console.WriteLine ( "正在执行静态构造函数" );
}
} public class Programe
{
static void Main ( string [ ] args )
{
Test.none="sam"; //执行一次静态构造函数,打印:正在执行静态构造函数
Test.none="leo"; //这次访问成员时,静态构造函数不会执行,所以此次不会输出任何打印
}
}
静态构造函数执行顺序
当new一个对象时,静态构造函数会先执行以便初始化类的成员,接着才会执行实例构造函数初始化对象的成员。这个顺序很好理解,毕竟类大于对象,初始化时也会按照这个原则执行。如果类是一个从属的派生类则new出其对象前会先执行它的静态构造函数,然后执行基类静态构造函数,完毕后再执行基类的实例构造函数、再执行派生类的实例构造函数。也即派生类的静态构造函数的执行顺序是从自身开始逐层往上,完毕后从基类开始逐层往下执行实例构造函数。
public class Animal
{
static Animal()
{
Console.WriteLine("正在执行Animal的静态构造函数");
}
public Animal()
{
Console.WriteLine("正在执行Animal的实例构造函数");
}
} public class Person : Animal
{
static Person()
{
Console.WriteLine("正在执行Person的静态构造函数");
} public Person()
{
Console.WriteLine("正在执行Person的实例构造函数");
}
} public class Programe
{
static void Main(string[] args)
{
Person p = new Person();
}
}
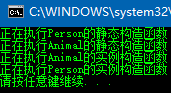
利用静态构造函数创建唯一的全局对象
因为静态构造函数只会执行一次,利用这个特点我们可以创建一个表示唯一性的、在任何地方都可以共享的对象
public class Animal
{
public string CurrentName { get; set; }
static Animal ( )
{
Current = new Animal ( ); //在静态构造函数中实例化一个Animal对象,通过Current属性存取这个对象
}
public static Animal Current { get; private set; }
} //测试
Animal animal = Animal.Current;
animal.CurrentName = "碳基";
Animal animal2 = Animal.Current;
string s = animal2.CurrentName; //print 碳基
继承(派生)
继承即派生,它是面向对象编程的支柱。我们将一些基本的功能存放在基类中。子类通过自动继承获得基类定义的功能而无需重复编写已被基类实现的某些功能从而达到代码重用的目的。
继承规则
1.如果一个自定义的类没有显示设置它的基类,则默认其直接从system.Object派生。
2.一个类只能有一个基类
3.派生类继承除基类的构造函数和析构函数之外的所有成员(包括静态成员),但继承了基类的成员后,派生类并不一定能访问继承得来的成员,能不能访问取决于为那些成员定义的权限修饰符
2.类的访问权限遵从子类访问权限不能大于基类,要么其权限等于基,要么小于基。(类只有两种访问权限,要么internal要么public,所以很好记。基类如果是internal则子类不允许是public)
派生类可以获得基类的成员,比如基类是Animal,它有EatFood方法,它有两个派生类Cow和Chicken,它们通过继承自动获得EatFood方法:
{
public void EatFood()
{
}
}
public class Cow : Animal
{
}
public class Chicken : Animal
{
}
static void Main(string[] args)
{
Cow cow = new Cow();
cow.EatFood();//自动获得基类的方法
Chicken chicken = new Chicken();
chicken.EatFood();//自动获得基类的方法
}
通过派生类的构造函数访问base代表的基对象的Name字段并初始化它。
{
public string Name { get; set; }
}
public class Cow : Animal
{
public Cow( string name )
{
base.Name = name;
}
}
组合对象
基类与派生类之间的转换
基类对象不能转换为派生类型的对象,但派生类型的对象可以转换为基类型的对象。实际上我们不应该考虑转换问题而是将转换看成是赋值,记住这句话:赋值会测试赋值操作符左右两边的操作数其类型的等同性。现在假设有一个Person从Animal派生,看下面的解释:
//基类型的对象为什么不能转换为派生类型的对象?
//要解决这个问题先看派生类对象转基类对象是怎么得来的 Person person = new Person { JobName = "programer" }; //流程:new操作符调用无参构造函数初始化person对象,这会先调用person的静态构造函数为person的静态成员划分内存空间
//再调用Animal的实例构造函数,计算Animal的成员所占用的空间大小,然后在堆上划分Animal的内存
//这样,Animal对象就出现在了内存中
//再再接下来才会开始计算person对象的成员所占用的空间,为person划分内存空间,最后进入{ }构造函数方法体,执行后退出
//最重要的一步来了,此时内存中的Animal对象将自身的地址拷贝给了person,也即person对象持有对Animal对象的引用,所以Person才能获得Animal的成员。
//完成这一系列的操作后,看下面的代码 Animal animal = Person; //当编译器发现=操作符时,它将判断左右两边的两个操作数其类型的等同性,看起来person和animal类型根本不一样,所以它们并不匹配
//但编译器发现person持有对animal的引用,要不它怎么获得基类的成员?所以立马将person指向的地址交给了animal。
//也即animal存储的是person指向的地址(包含内存中Animal对象的地址和自身的地址),但不能通过animal去访问地址指向的person的内容,但可以访问内存中的Animal对象的内容。
//要记住一点:animal确确实实存储了整个对person的引用,这样的引用完全合乎逻辑,行之有理,毫不违和。
//综上所述,以上的操作就可以完成 //现在来回答基类型的对象为什么不能转换为派生类型的对象?正是因为创建基类型对象后(Animal),内存中根本没有Person类型的对象被创建,并且基类型对象在内存中不持有对派生类型对象的引用,一个不存在的地址是无法交给另一个不同类型的,如下所示: Animal animal = new Animal { Name = "sam" };
Person pp = ( Person ) animal; //编译通过但运行时会抛出异常,能通过是因为显示转换类似于强转,告诉编译器我对我的行为负责,你不要管
//所以,今后看到引用类型之间的转换时,首先问自己,右边的对象在内存中是否持有对左边类型的某个对象的引用,有则可以转换,无则不能转换
只有在如下情况中才可能将基类型对象转换为派生类型的对象,总结起来一句话:基类型对象能转换为派生类型对象的办法是先将派生类型对象赋值给基类型的变量,再将基类型的变量转换为派生类型的对象。
Person p = new Person { JobName = "programer" };
Animal a = p; //编译器认为左右两边的操作数可以对等,因为p持有对内存中的Animal对象的引用,于是立即将p指向的地址交给a(包括自身的地址和内存中的Animal的地址),但a因为是Animal类型,所以它只能访问p地址指向的Animal的内容部分
Person newPerson = ( Person ) a; //显示转换后,a变成了Person类型,a本身存储着对p的引用,转换后自然可以访问p的内容
newPerson.JobName = "philosopher";
Console.WriteLine( p.JobName); //print philosopher
隐式转换的问题
子类可以隐式转换为父类,但子类不一定能安全的转换为父类,隐式转换会导致两个很突出的问题,它将破坏隐式转换,使继承本来可以展示出的多态性变得不如看上去那么好。
1.子类维护了父类上下文,它内部可以操纵父类成员并修改它们,一旦子类修改了父类的成员,那么外部调用子类隐式转换为父类的实例时,结果可能就不符合预期。
2.基类将某个成员修饰为私有,那么外部调用子类隐式转换为父类的实例时,结果可能就不符合预期。
{
public class Animal
{
public string Name { get; set; }
public Animal( )
{
Name = "sam";
}
}
public class Person : Animal
{
public Person( )
{
Name = "leo"; //获取了基类成员并擅自修改了它
}
}
public class Programe
{
static void Main( string[] args )
{
Animal animal = new Person( );
Console.WriteLine( animal.Name ); //animal.Name可能不符合预期
}
}
}
隐藏基类成员
1.new 操作符
如果派生类从基类继承的方法或属性的代码块的内部实现并不能满足派生类的需求,此时可能会想到要重新定义一个与基类同名的方法或属性,这个需求可以使用new操作符把派生类从基类继承的成员彻底隐藏从而定义自己的同名版本。这样,重新定义的与基类同名的属性或方法就是自己原生的属性或方法。当派生类的实例访问这些属性或方法时,得到的就是原生的版本了。
public class Animal
{
public int GetCount( )
{
return ;
}
} public class Person : Animal
{
public new int GetCount( )
{
return ;
}
}
重写基类成员
1.virtual操作符
使用此修饰符可以将对象的成员定义为虚成员,这和abstract是同一种性质,相等之处在于abstract和virtual都是抽象的,都只能修饰具有代码块的成员,区别在于要定义abstract的成员,则类型也必须是abstract的,所以虚成员只是为了解决不能在非abstract的类中定义抽象的成员,同样的,虚成员允许派生类重写,派生类重写虚成员时,其权限修饰符必须和基类中定义的虚成员的权限修饰符是一致的。
2.override操作符
使用此修饰符可以重写被基类定义为virtual或abstract的对象成员,子类的子类也可以继续重写这些成员,但不能更改成员的权限修饰符。
如果要查看哪些基类成员是可以重写的,只需要直接写override(不写权限修饰符和形态修饰符),然后敲空格,这样Visual Studio会自动列出可重写的成员列表,如下图列出了Person类的基类Animal类的可重写的成员和Animal类的基类object类的可重写的成员:

如果在设计类的时候考虑到了某些对象的属性或方法不能满足派生类的需求,此时可为基类的那些可能需要派生类去改写的对象的属性或方法定义一个virtual的标识,声明为virtual的属性或方法可以被派生类重新定义,派生类使用override修饰重新定义基类的对象成员。
这与派生类使用new操作符隐藏基类同名成员的区别在于:new操作符是将与基类同名的属性或方法隐藏掉并定义了一个全新的自己原生的属性或方法,而override是直接在基类实例指向的内存堆上修改数据,派生类实例访问这些被override的成员时,这些成员依然是靠继承得来的,它们不是派生类自己的原生成员。
静态成员不能override。
new隐藏和override重写的区别如下面代码所示:
public class Animal
{
public int GetCount( )
{
return ;
}
} public class Person : Animal
{
public new int GetCount( )
{
return ;
}
} public class Programe
{
static void Main(string [ ] args)
{
Person p = new Person( );
Animal a = p; // a持有对p和内存中的Animal的地址,但只能访问内存中的Animal
Console.WriteLine( a.GetCount()); //print 100000
}
}
public class Animal
{
public virtual int GetCount( )
{
return ;
}
} public class Person : Animal
{
public override int GetCount( )
{
return ;
}
} public class Programe
{
static void Main(string [ ] args)
{
Person p = new Person( );
Animal a = p; // a持有对p和内存中的Animal的地址,但只能访问内存中的Animal
Console.WriteLine( a.GetCount( ) );//print 100
//内存中的Animal实例维护的GetCount已经被p实例重写
}
}
类的扩展方法
在Linq查询中,所有的查询方法都由Enumerable提供,Enumerable扩展了IEnumerable<T>接口的方法,每一个实现IEnumerable<T>的集合类型都继承了这些用于Linq查询的扩展方法。假如没有扩展方法,微软会怎么做?它会直接在IEnumerable<T>接口中增加几十个用于Linq查询的方法成员,这样一来,大量实现了IEnumerable<T>的类就必须手动实现这些方法,工作量可以想象有多巨大。而如果使用扩展方法,那么只需要为IEnumerable<T>扩展一套支持Linq查询的方法就行了,所有实现了IEnumerable<T>的类就会自动得到这些扩展方法。也即,Linq查询的方法只在一处完成,其它类都靠与接口的关系自动拥有Linq查询的方法。从而达到了简化的目的。如果我们希望为一个内置的类型增加成员,比如增加一个方法,我们可能会转到该类型的源代码中为它定义一个新方法,但是内置类型都是C#预定义的东东,我们只能查看到一堆有限的元数据。没办法进入源码对类进行扩展。C#3.0允许通过方法扩展为类型增加方法。扩展方法也从遵循继承原则,一个基类具有扩展方法,那么派生类也会自动继承扩展方法。类、接口、泛型类、泛型接口都可以增加扩展方法。最后,为泛型、泛型接口增加扩展方法,那么实现该扩展方法的类依然是一个单类型(非泛型),但,其方法必须是泛型方法。
以下演示了如何定义扩展方法:
//首先,定义一个静态类,命名最好遵循后缀为Extention,比如要为Double类型定义扩展方法,则类名为DoubleExtention
public static class DoubleExtention
{
//其次,既然是静态类,那么方法也肯定是静态的。
//再者,扩展方法的的第一个参数必须以his 作为修饰,参数类型必须是要扩展的类型 ,其它参数随意
public static double MPow(this double xDoubleObj , double xDouble)
{
return Math.Pow( xDoubleObj , xDouble );
}
} public class Programe
{
static void Main(string [ ] args)
{
//编译器如何发现Double类型具有MPow方法的呢?
//因为在当前编辑器中,所有被引入的命名空间中的所有数据都会被编译器监视,一个静态方法被视为某个类型的扩展,则内存中就会存储该方法
//当使用x调用MPow时,首先查看double是否具有MPow,如果没有则查看其基类是否具有MPow,如果没有则查看double是否有一个静态的MPow
double x = ;
double result = x.MPow( );
Console.WriteLine( result );
}
}
扩展方法的意义
1.可以为.NET内置的类型扩展出自定义的方法,因为你不可能修改内置类型的源代码,而你又想为内置类型增加自己的方法实现。而自定义的类型根本不需要扩展方法,因为你自己定义的类型是有源代码的,直接在源代码上添加一个方法就可以了。
2.为接口定义扩展方法,使实现接口的类型可以自动获得这些扩展方法而不需要每一个实现了某接口的类型都去实现一遍逻辑完全一样的方法。
public interface ILanguage { }
public class Animal : ILanguage { }
public class Person : ILanguage { }
public static class ILanguageExtetion
{
public static void Say(this ILanguage language, string sayString)
{
Console.WriteLine(sayString);
}
}
public class Programe
{
static void Main(string[] args)
{
Animal a = new Animal();
a.Say("%^$&");
Person p = new Person();
p.Say("hello");
//如果不是为ILanguage定义了扩展方法,那么你需要在Animal和Person中都重复实现一个Say方法,这样就增加了代码的冗余,显得不够简洁
}
}
为 IQueryable<T>接口扩展迭代方法
public static class IQueryableExtend
{
public static void For<T>(this IQueryable<T> queryableList,Action<T> lambda )
{
foreach(var item in queryableList)
{
lambda( item );
}
}
}
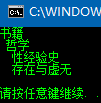
{
//以下假设数据库有一个节点表,现在要打印如下的层级结构
//书籍
// 哲学
// 性经验史
// 存在与虚无
DBContext EFContext = new DBContext( );
//先获取根节点
var roots=EFContext.Nodes.Where( node => node.ParentId == null );
StringBuilder builder = new StringBuilder( );
roots.For( node => ShowNode( node, 0, builder ) ); //调用自定义的扩展方法
Console.WriteLine( builder.ToString( ) );
}
public static StringBuilder ShowNode( Node fatherNode, int deep, StringBuilder builder )
{
builder.Append( new string(' ',deep)+ fatherNode.NodeName+"\n" );
fatherNode.Childs.AsQueryable( ).For( node => { ShowNode( node, deep+1, builder ); deep = fatherNode.Childs.Last( ) == node ? 0 : deep; } );
return builder;
}
嵌套类
可以在一个类里嵌套其它的类,但尽量不要这样做,除非嵌套的类有其实际意义,比如它确实不需要被外部访问而是在包容它的容器类中提供一些数据支持。而且通常应将嵌套类设为private,千万不要设为public,因为公开它则使它失去作为嵌套类的意义,public的嵌套类如何访问呢?必须以包容它的容器类作为前缀,而这样访问看起来类似于访问静态成员,可实际上它又并非是静态的,为了不引起语义上的混淆,不要将嵌套类定义为public。而且定义为public的嵌套类根本没有意义,还不如直接定义成另一个非嵌套的类。理解嵌套类时,可将它看做包容它的容器类的成员,在类内部成员之间的相互访问规则也适用于嵌套类。嵌套类的this指向自身实例,如果要在嵌套类里访问包容它的容器类,可以考虑将包容类的this赋值给一个成员变量,在嵌套类里访问该成员变量即可。总之,什么时候使用嵌套类?只在不需要从包容它的容器类外部访问它时,同时它有存在的必要时才定义这样的类型。
分布类
使用关键字partial声明分部类,分布类就是将类的成员分布在同一命名空间、同一个类的多个文件中。如下所示 我们创建了三个类文件 每个文件里都有MyClass的定义,它使用了partial关键字。
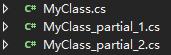
第一个文件中的MyClass类只定义了它的方法
namespace LearningCsharp
{
public partial class MyClass
{
public string showName() { return this.Name; }
}
}
第二个文件的MyClass类定义了它的字段
namespace LearningCsharp
{
public partial class MyClass
{
private string name;
}
}
最后一个文件的MyClass类定义了它的属性
namespace LearningCsharp
{
public partial class MyClass
{
public string Name { get { return name; } set { name = value; } }
}
}
对象成员和类成员(Class Member&object Member)
我喜欢这样理解,类内部定的非static的成员其所有权归属于对象所有,static的成员其所有权归属类所有。所以在定义的类内部有类的成员和对象的成员之分。
1.字段
2.属性
3.方法
成员修饰符

1.权限修饰
用于定义成员的访问权限。
1.Internal(内部)
该成员只能在定义它的命名空间中且在类的作用域中被访问。此为成员的默认项。
2.Public(公有)
该成员可以在任何命名空间中被访问。
3.Private(私有)默认
类内部可访问。
4.Protected(保护)
类内部可访问,派生类内部可访问。可组合Internal。Internal Protected表示只有在当前命名空间下的派生类才可以访问该基类的成员。
2.形态修饰
用于定义成员的形态。
1.abstract(抽象)|
抽象(只有在抽象类中才可以使用抽象修饰符修饰成员)
2.virtual(虚)
可以在任何类型中使用虚修饰符
3.sealed(密封)
密封(如果基类允许子类重写某个成员,那么子类除了可以重写基类成员外,还可以使用override sealed将基类成员重写后密封。成员被密封后则其后的子类只能继承不能再被其后的子类重写)
4.static(静态)
在内存中是唯一的,表示类的成员,对象无法访问。静态成员是为了表示类型所独有的一个特性,比如人类这个类型有一个属性是总人口,创建人类的对象后,一个独立的个体得以出现,但该对象不应该具备总人口这个属性,应把类似这样的属性设置为类型所独有的特性,这就要用到static。无论new出多少个人类实例,人类的静态成员在一个应用程序域中就永远只有一个。以下定义了一个Animal类,每创建一个Animal对象,Animal类的AnimalCount都自增,用于统计Animal对象的个数。
public class Animal
{
private static int animalCount = 0;
public static int AnimalCount
{
get
{
return animalCount;
}
} public Animal()
{
animalCount++;
}
} public class Programe
{
static void Main(string[] args)
{
Animal a1 = new Animal();
Animal a2 = new Animal();
Animal a3 = new Animal();
Console.WriteLine(Animal.AnimalCount); //print 3
}
}
3.字段修饰符
只能用于对字段的修饰
1.ReadOnly
只读字段,表示该字段只能读取,不能更改,但可以在构造函数中对其进行更改。静态只读字段只能由静态构造函数更改,实例只读字段只能由实例构造函数更改。
2.Const
常量字段,表示该字段只能读取,不能更改,构造函数也不能更改它,它隐式地被定义为static,所以它属于类的成员。常量字段声明的同时必须显示赋值。
常量字段与只读字段的区别
1.常量字段属于类成员,所以可以将它看成是隐式静态(Static),而只读字段属于类还是对象取决于是否有static做形态修饰。
1.常量字段不可改,只读字段在构造函数中可改。
2.方法中可声明常量字段,方法中不可声明只读字段。
3.声明常量时必须同时赋值,声明只读字段时可以不用立即赋值。
4.常量字段只能是简单类型(值、string类型),只读字段可以是任意类型。
5.只读字段可以是静态或实例的,常量字段都是静态的。
如果把一个列表字段设为只读,那么就不能更改这个字段的值,也即不能new一个新的实例,但是可以更改列表里的元素,因为其元素并未设置为只读,而是把列表这个对象设为了只读,考虑如下代码:
{
public readonly List<string> LanguageList = new List<string>
{
"#$%^",
"@*&#",
"中文",
"英文"
};
public readonly string name = "sam";
}
a.LanguageList[0] = "^^^^^"; //可以修改只读字段LanguageList包含的元素
a.LanguageList = new List<string>( ); //error ,只读字段LanguageList不能new
a.name = "leo"; //error,只读字段name不能设置值
成员重名
除了方法可以重名(重载),其它成员的名称都禁止重复,哪怕类型不同也不行,比如不能定义一个int x,再定义一个string x。如果某个类实现的两个接口具有同名的成员,那么实现的另一个接口的成员只能显示地实现。
在类外部时,成员之间的相互访问
在类外部,类的成员只能由类访问,对象的成员只能由对象访问,类不能访问对象的成员,对象也不能访问类的成员。
在类内部时,成员之间的相互访问
我把类视为>对象的存在,这在理解在类内部成员之间的相互可访问性时显得尤为重要。静态成员属于类,类>对象,根据子承父的原则,子(对象)的成员就可以访问父(类)的成员,而父(类)的成员则无法访问子(对象)的成员。 所以类的成员无法访问this,正是因为这个原因,this是属于对象的一个属性,它指向对象在堆上的地址,按我的理解:在类内部,类成员无法访问对象的成员成立。
public class Animal
{
//类的成员
private static int AnimalCount; //对象的成员
public int ShowTotalCount()
{
Console.WriteLine(AnimalCount); //对象的ShowTotalCount成员可访问类的AnimalCount成员
return AnimalCount;
} //类的成员
public static void GetTotalCount()
{
ShowTotalCount(); //error:类的成员GetTotalCount无法引用对象的ShowTotalCount成员
}
}
字段成员(Feild Member)
类中声明的变量称为字段,字段可以是任何值类型和引用类型。
public class Person
{
public string Name; //对象字段
public static string PersonCount; //类字段
public readonly int ID; //对象只读字段
public static readonly string GDP; //类只读字段
}
属性成员(Property Member)
属性与字段的区别
public的字段是可读写的,如果不希望字段被访问,可设其权限为类外部不可访问(private)。或者你希望字段是在类外部可读但不可写的,可设为public readonly。但字段的访问与修改不够灵活,如果需要在外部修改字段,但需要经过一个验证的逻辑,则字段不能胜任这样的工作。如果需要当访问字段时,返回其它的值,则字段也无法胜任这样的工作。属性的出现正是基于这样两个需求。属性是可以理解为一种方法的变体,它具有代码块,可以通过在代码块写语句和表达式从而更为灵活的控制字段的读写。访问属性时,属性可以自己斟酌应返回一个什么结果给外部,这可以在代码块中做出处理。为属性赋值时,赋的值可以看成是属性代码块的局部变量,也即可以看成是一个参数。属性接收这个参数然后在代码块里对其做出处理。利用属性具有方法块的特点,可以实现当属性值发生改变时在属性的set代码块触发一个类似于ValueChange的事件。该不该使用属性应视具体情况而定而不要盲目使用它。属性具有方法的行为,它有一个叫做value的参数被有效的传递进来,这个value是C#内置的参数,它只能在set访问器中使用,它表示的是用户传递进来的值。
public class Person
{
private string userName; //通常做法是不向外界暴露字段,通过在类内部用属性访问字段。
public string Name
{
get
{
return userName == "" ? "匿名用户" : userName;
}
set
{
userName = value == "" ? "匿名用户" : value;
}
}
}
自动属性
编译器隐式地为属性创建隐藏的字段,你只需要定义属性就可以了,但如果get、set有自己的实现,那么你还是得定义一个字段作为属性的存取器。
public string Name { get; set; }
get和set也可以使用权限修饰符,因为它们类似于方法,方法可以使用选项修饰符,所以属性的get、set自然也可以使用修饰符。
public string Name { get; private set; }
索引器成员(Index Member)
索引器只能是对象的成员,它可以使对象变得像数组般被检索。简单来说,定义好索引器就可以通过类实例[索引]的方式获取一些数据。至于是什么样的数据,这由你自己决定。
定义索引器
public class StringContainner
{
private string[] stringAry;
public string[] StringAry
{
get { return stringAry; }
set { stringAry = value; }
} //索引器,返回类型和get、set的实现可以随意,index可以是任意类型
public string this[int index]
{
get { return stringAry[index]; }
set { stringAry[index] = value; }
}
} static void Main(string[] args)
{
StringContainner strcontainner = new StringContainner();
strcontainner.StringAry = { "sam" , "leo" , "korn" };
Console.WriteLine(strcontainner[0]); //return sam
}
快速定义索引器
键入indexer,按Tab键两次,自动生成索引器。
namespace Test
{
//以下实现了一个只能通过索引器访问或设置Animal的字段。将枚举数作为Animal对象的索引键,当用户通过索引器设置Animal的name和type字段时,强制要求索引键必须是枚举数
public enum AnimalPro
{
Name = 1 << 0,
Type = 1 << 2
} public class Animal
{
private string name;
private string type;
public string this[AnimalPro pro]
{
get
{
return pro == AnimalPro.Name ? name : pro == AnimalPro.Type ? type : throw new Exception("无此枚举数,无法确定要获取的对象");
}
set
{
if (pro == AnimalPro.Name)
{
name = value;
}
else if (pro == AnimalPro.Type)
{
type = value;
}
else
{
throw new Exception("无此枚举数,无法确定要设置的对象");
}
}
}
} public class Programe
{
static void Main(string[] args)
{
Animal animal = new Animal();
animal[0] = "青蛙"; //0可以被当做枚举数进行传递,编译器无法检查,抛出自定义异常
animal[AnimalPro.Name] = "蚂蚁";
animal[AnimalPro.Type] = "昆虫";
}
}
}
索引器重载
索引器的索引键的类型不同或个数不同就被视为重载。
方法成员(Method Member)
函数在类型中定义后称为方法,方法是一个命名的代码块,代码块中的逻辑组合在一起形成一个具体的操作以达到复用代码的目的。方法只能封装在类型或结构中,下边定义了一个最基本的方法,用于返回一个字符串。
定义方法
public class Animal
{
public string Get()
{
return "cow";
}
}
方法返回值
1.void(无返回值)
2.数据类型(返回的类型)
对于声明为void的方法,return是可有可无的,但不能return一个变量,因为void已经明确表示了该方法无返回值。而声明了返回类型的方法必须在方法执行结束处使用return返回某种类型的值。
方法优势
方法的优势就在于可重复使用,为了达到重复使用同时又能降低今后修改方法内部逻辑的工作量,我们就要做到对方法的逻辑实现必须遵循复用这一基本原则,比如现在假设需要写三个方法分别计算圆面积、圆柱体积和圆锥体积:
public class GetCircleMsg
{
//圆面积
public double GetCircleArea(double r)
{
return 3.14 * r * r;
}
//圆柱体积
public double GetCylinVolume(double r, double h)
{
return 3.14 * r * r * h;
}
//圆锥体积
public double GetConeVolume(double r, double h)
{
return 3.14 * r * r * h / 3;
}
}
看起来没什么问题,可是今后如果需求转变为要把π值精确到3.1415926时,我们会发现需要手动修改多处使用了π值的各个方法。这就会造成大量无意义的重复工作,所以为了降低无意义的重复工作,我们一定要把经常重复使用的数据单独封装成一个方法,用一个函数来返回经常使用的数据,该方法只实现一个单一的功能。今后需求改动就只需要改这个函数即可,当然经常重复使用的数据还可以定义成枚举。
public class GetCircleMsg
{
//封装一个获取π值的方法
public double Getπ()
{
return 3.14;
}
//圆面积
public double GetCircleArea(double r)
{
return Getπ() * r * r;
}
//圆柱体积
public double GetCylinVolume(double r, double h)
{
return Getπ() * r * r * h;
}
//圆锥体积
public double GetConeVolume(double r, double h)
{
return Getπ() * r * r * h / 3;
}
}
方法重载
C#支持名称重复的方法名,重名的方法称为方法重载。但名称重复的方法必须具有不同的方法签名。
不同的方法签名
1.参数类型不同 | 2.参数个数不同 | 3.泛型类型参数不同 | 4.有无ref、out、params关键字的不同 | 5.与返回类型无关。
签名与方法返回值的类型无关,外部代码块在调用同名的方法时会自动根据传递的参数的类型或参数个数来确定要调用的是哪一个方法。
public string Get(string name)
{
return name;
} public string Get(string name, string age)
{
return name + age;
}
运算符重载
你可以在自定义类型中使用运算符重载。如果这样做,那么该类型的对象就可以使用标准的运算符来进行运算,运算逻辑由自己定义,运算符重载跟定义一个函数差不多。不过必须使用operator关键字且形态必须是static。
运算符重载规则
1.&&、||、=、+=、-=、*=、/=都不能重载。
2.如果重载比较运算符 则比较运算符必须成对重载。重载>就必须重载<,类似的还有>=、<=。
{
public int Val;
//以下定义了MyClass的运算符 我们重载了+法运算 实现了自定义的+运算逻辑
public static MyClass operator +( MyClass obj1, MyClass obj2 )
{
MyClass obj = new MyClass( );
obj.Val = obj1.Val + obj2.Val;
return obj;
}
}
static void Main( string[] args )
{
MyClass obj1 = new MyClass( );
MyClass obj2 = new MyClass( );
obj1.Val = 1;
obj2.Val = 2;
MyClass obj3 = obj1 + obj2;
Console.WriteLine( obj3.Val );
}
方法参数详解
方法参数的隐式转换
如果传递给方法的实参类型与方法形参类型不匹配,此时方法会尝试隐式转换实参类型为形参类型,如果无法隐式转换,则编译器会提示无法将x类型转换为z类型,这段错误提示表示x是实参类型,y则是方法所要求的形参类型,比如将一个int传递给需要byte类型的形参时,编译器无法隐式的大转小,所以编译器会立即提示错误,而如果将byte实参传递给需要int形参的方法时则不会发生编译错误,在调用方法时,传递的引用类型的参数如果与方法接收的参数类型不一样,那么也同样会尝试执行隐式转换,隐式转换在方法调用时是存在的,需要特别注意。
namespace Test
{
public class Animal { public string name; }
public class Person : Animal { } class Program
{
public static void Get(string ID) { }
public static void Get(Animal animal) { show(animal.name); } //假设show是一个输出的方法 static void Main(string[] args)
{
Get(new Person { name = "sam" }); //Person被隐式转换为Animal,小转大,没问题
}
}
}
方法参数种类
方法参数称为形参,形参是方法的局部变量,只在方法体内部有效,所以在方法中不能再次定义与形参同名的局部变量。调用方法时传递给方法的参数称为实参。值类型和string类型的变量作为实参传递给方法时,值类型变量会发生拷贝,string类型会重新创建新的字符,只有引用类型的变量传递给方法后不发生拷贝,而是将该类实例在堆上的地址传递给方法,也即值类型和string类型传递给方法时立即发生了拷贝或新建,所以该参数在方法内部是一个独立的变量,改变该变量并不会影响外部的变量,而引用类型的变量作为参数传递后一旦在方法体内部被改变,那么外部也会被影响、被改变。
传递方法参数时的拷贝行为
值类型和string类型传递给方法后,在方法内部会建立一个副本,而引用类型传递给方法时,传递的是引用地址。
方法参数的隐式转换
ref参数(引用参数)
方法参数可声明为ref,声明为ref的参数将作为引用使用,也即值类型和string类型声明为ref参数并传递给方法后,不再发生拷贝的行为。ref参数传递给方法前必须先初始化,因为方法要接收这个地址就必须在传递前明确变量指向的数据在栈堆上的地址。没有地址则方法根本无法去引用变量。而非ref的值类型和strig类型的参数不需要明确赋值,方法也可以接收,毕竟它们与方法没有共生的关系,传递给方法后就与己无关了。
static void Main(string[] args)
{
int ID = 100;
string name = "sam";
Test(ref ID, ref name);
show(ID + " " + name); //prin 10 leo
} static void Test(ref int ID, ref string name)
{
ID = 10;
name = "leo";
} //疑问,书上说ref必须初始化然后才能传递给方法,因为方法需要ref参数的地址
static void TestRef(ref string val)
{
val = "resetVal";
}
static void Main(string[] args)
{
string val = null;
TestRef(ref val);
Console.WriteLine(val); //print true 不明白,null是没有地址的,怎么引用上val的?
}
out参数(输出参数)
与ref一样,声明为out的参数将作为引用使用,也即值类型和string类型声明为out参数并传递给方法后,不再发生拷贝的行为。与ref唯一的区别在于,out参数传递给方法前不需要初始化,书上没有对这个区别做详细解释,我自己的推断则是out变量实际上发生了拷贝。因为out变量没有初始化也可以传递给方法,没有初始化则该变量在栈堆上根本没有地址,没有地址则方法根本不可能引用它。所以方法体内部可能执行了拷贝,在方法内部可以为拷贝的参数变量赋值,然后方法会自动将变量的值赋值给外部的作为out参数传递过的变量。也即这并非是传引用,而是动态为外部那个曾经作为参数传递过的变量赋了新值。(个人想当然,不保证正确性)
static void Main(string[] args)
{
int ID;
string name;
Test(out ID, out name);
show(ID + " " + name); //print 10 leo
} static void Test(out int ID, out string name) //发生拷贝
{
ID = 10; //赋值的同时自动隐式的将这个值输出到外部那个作为out参数传递过的变量
name = "leo";//赋值的同时自动隐式的将这个值输出到外部那个作为out参数传递过的变量
}
params参数(不定长参数)
可以将params参数描述为可接收个数不固定的相同类型的参数,这种参数看起来好像跟直接传递数组差不多,实际上params参数和数组参数的唯一区别只有一个,那就是传参数时可以不传数组,每个参数用逗号隔开就可以了!每个参数都会被方法自动压入params参数数组中。也即传参时可以不传数组却可以被方法当成数组处理。params参数必须遵守以下规则
1.params形参必须是数组
2.只能在方法参数列表末尾定义
3.只能有一个params形参
static void Main(string[] args)
{
string[] f = { "番茄", "荔枝", "芒果" };
Test("水果", f);//传数组
Test("生物", "鲨鱼", "海豚", "乌贼"); //非数组一样可以传给方法
} static void Test(string name, params string[] elms)
{
foreach (var elm in elms)
{
//……
}
}
具名参数
这是一种可以颠倒传参顺序的方式。运用具名参数后参数的顺序就不再重要。但具有params参数的方法不能使用具名参数。
static void Main(string[] args)
{
string[] f = { "番茄", "荔枝", "芒果" };
Test(age: 32, name: "生物"); //传参顺序随意颠倒,只要提供了形参的名字和对应的值就行
} static void Test(string name, int age)
{ }
默认参数
可为方法的参数设置默认值,这样,调用方法时,就允许不传递具有默认值的参数。
static void Main(string[] args)
{
string[] f = { "番茄", "荔枝", "芒果" };
Test(name: "生物");
} static void Test(string name, int age = 32) //如果没有传递age,则使用默认值,否则覆盖默认值
{ }
方法返回类型的隐式转换
假设Person从Animal派生,方法返回类型是Animal类型,而方法内部return的是一个Person实例,那么最终该方法返回的就是一个经过隐式转换的实例,该方法会尝试将Person实例转换为Animal的实例,由于Person实例持有对内存中的Animal的访问,所以这个转换是成功的。这样,当外部调用拿到Animal实例后,就只能调用Animal的成员了。
方法的作用域
在方法中声明的变量称为局部变量,局部变量无法离开块,它可以定义在方法块、方法块的其它语句块中,同级别块中的变量是相互独立的,也即你可以在两个if块中声明同一个名称的x局部变量。由于作用域的的原因,同一个作用域中不能声明一个同名变量两次,而子块本身处于父块中,所以父块声明了x变量则子块中只可访问x但不能再次声明x。
结构类型(Struct)
C#中所有类型最开始都从Object派生,结构从System.ValueType派生,System.ValueType从Object派生。结构被隐式地定义为sealed(不可从其派生)。内置值类型都是预定义的结构类型(ValueType),所以值类型也都是隐式地被new出来的,你也可以尝试显示地new出一个int(调用int的结构构造函数初始化为0)。
int i = new int(); //显示调用构造函数后,i会被初始化为0,如果未显示调用构造函数,则该变量就没有被初始化,
Console.WriteLine(i==0); //print true
int z;
Console.WriteLine(z); //编译错误,使用了未赋值的局部变量z
自定义结构
结构是一种存储在栈上的值类型,虽然它不是引用类型。但它可以包含类能包含的所有成员。微软引入结构是因为引用类型容易消耗大量内存,而结构存储在栈上,这个单一的数据结构比单一的值类型数据占用更多的内存栈空间,也就可以存储更多的数据,而结构不是引用类型,所以在保证了存储更多数据的情况下又没有引用类型那么大的内存消耗,结构就显得更为轻量级,但是结构是密封的,无法从其派生,所以大多数时候我们都定义类而非结构。也即结构与类是很相似的,上面讲到的关于类的知识也可以应用在结构上,区别仅仅在于类可继承、数据在堆上,结构不可继承,数据在栈上。如何选择应该定义类还是定义结构呢?需要继承派生的功时就定义类,否则定义结构。最后,结构类型是一种类型,所以不要试图把结构类型定义在自定义的类型中,否则看起来就像是嵌套类,没有太大意义。但你可以在类中定义结构类型的成员。
//自定义结构
public struct MyInteger
{
public int Value { get; set; }
} MyInteger myInteger = new MyInteger(); //调用了默认的无参构造函数
Console.WriteLine(myInteger.Value); //print 0
//自定义结构
public struct MyInteger
{
public int Value { get; set; }
public MyInteger(int value) //带参构造函数,不能定义无参构造函数,因为结构默认的无参构造函数不会因为你定义了有参构造函数就被覆盖掉,这区别与类的构造函数
{
Value = value;
}
} class Program
{
static void Main(string[] args)
{
MyInteger myInteger = new MyInteger(100);//调用了带参的构造函数
Console.WriteLine(myInteger.Value); //print 100
MyInteger myInteger2;
Console.WriteLine(myInteger2); //编译错误,使用了未赋值的局部变量
}
}
作为参数的结构
因为结构存储在栈上,它是值类型,将结构作为参数传递给方法,传递的是一份结构的拷贝,即原来的结构不会因为参数的改变而改变,如果尝试把数据量大的结构作为参数进行传递,因为拷贝的原因,所以也会造成性能损失,不过,你可以使用ref、out传递结构。
结构实现接口
结构可以实现接口,比如C#预定义的值类型都实现了ICompareble、IFormattable等等接口。
枚举(Enum)
结构是一个包含了N个变量的值类型,而枚举是一个包含N个常量的值类型 。枚举维护的一组值称为枚举数或枚举选项,访问枚举数的方式与访问类的成员是一样的。枚举是密封的,它从System.Enum派生,后者又从System.ValueType派生。枚举数把数值映射为一个名称使代码更易于理解。如果经常需要使用一些在某个范围内的值,就可以考虑使用枚举,因为枚举不但容易理解,也更容易修改。
//枚举类型包含的每一个项称为该类型的枚举数,每个枚举数都表示为枚举类型
public enum MyEnum
{
red, //默认起始位置的枚举数表示的值是0,可以手动显示指定为另外的值
blue = 2, //如果此处改为2 则yellow=3 red不受影响
yellow
} //枚举数的底层类型默认是int类型,也可通过以下方式修改枚举数的底层类型,但只能修改为值类型
public enum MyEnum : byte
{
} public class Programe
{
static void Main(string[] args)
{
Console.WriteLine(MyEnum.blue); //print blue
Console.WriteLine((int)MyEnum.blue); //print blue
}
}
//Enum静态方法
Enum.GetValues(Type enumType)
//获取一个数组,该数组包含了参数指定的枚举所包含的枚举数的值,注意:返回的是Array类型,不是int[] Enum.GetNames(Type enumType)
//获取一个数组,该数组包含了参数指定的枚举所包含的枚举数的名称,注意:返回的是Array类型,不是string[] Enum.GetName(Type enumType, object value)
//根据参数指定的枚举类型和值返回一个该值所对应的枚举数的名称,一个字符串 Enum.IsDefined(Type enumType, object value)
//测试参数指定的枚举是否具有指定的值 Enum.TryParse<TEnum>(Type t, string str, bool noCase, out TEnum tem )
//尝试将参数指定的字符转换为指定的枚举数,转换成功返回true,并把转换后的值输出到tem
//noCase:指定是否不区分大小写
public enum Fruit { litchi = 1, tomato = 2 };
string str = "litchi";
Fruit fruit;
Enum.TryParse<Fruit>(str,true,out fruit);
Console.WriteLine((int) fruit); //print 1
//数字可以直接强转为枚举数
Fruit fruit = (Fruit)1;
Console.WriteLine(fruit); //print litchi
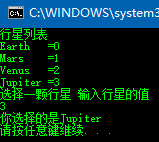
public enum Planet
{
Earth,
Mars,
Venus,
Jupiter
} public class Programe
{
static void Main(string[] args)
{
Array values = Enum.GetValues(typeof(Planet));
Console.WriteLine("行星列表");
for (var i = 0; i < values.Length; i++)
{
object value = values.GetValue(i);
Console.WriteLine("{0}\t={1}", Enum.GetName(typeof(Planet), value), (int)value);
}
Console.WriteLine("选择一颗行星 输入行星的值");
string input = Console.ReadLine();
int planetValue = int.Parse(input);
if (!Enum.IsDefined(typeof(Planet), planetValue))
{
Console.WriteLine("请输入正确的数字");
}
else
{
string planetName = Enum.GetName(typeof(Planet), planetValue);
Console.WriteLine("你选择的是{0}", planetName);
}
}
}
位标志枚举
可以在枚举上运用内置的Flags特性。运用此特性后,就可以利用位运算符将多个枚举数连在一起使用。
public class Employee { public AdminRoles Roles { get; set; } }
//AdminRoles只维护一个数字,通过在该数字的二进制数上进行位移从而使每个枚举成员得到不同的值
[Flags]
public enum AdminRoles
{
// 默认权限
None = 0,
// 添加员工
AddEmployee = 1 << 0, //1<<1=1
// 删除员工
DelEmployee = 1 << 1, //1<<1=2
// 更新员工
UpdateEmployee = 1 << 2, //1<<2=4
}
Employee e = new Employee(); //假设此处是获取到某一个具体的员工
e.Roles = AdminRoles.AddEmployee | AdminRoles.DelEmployee; //位或,两个枚举数位或结果:AddEmployee,DelEmployee,取连接两个数
Console.WriteLine((int) e.Roles); //print 3
e.Roles = e.Roles & AdminRoles.DelEmployee; //位与,两个枚举数位与结果:DelEmployee,取两边都相等的数
e.Roles = AdminRoles.DelEmployee ^ AdminRoles.DelEmployee; //位与,两个枚举数位抑或结果:None,取两边都不相等的数,如果都相等则等于0
Console.WriteLine((int) e.Roles);//print 0
接口(Interface)
接口是一种完全向外界暴露的公共契约规范,可以将接口看成是抽象的类型,因为抽象,所以不能new,也即它没有构造函数。它定义的成员隐式地被默认是abstract的抽象类型。当然,一个规范也可以是空的(没有任何关于成员的定义,空接口)。一个类型只要实现了某个接口,那个类型就可以被当做是接口类型,比如Programmer类和Employee类都实现了表示薪水的ISalary接口,那么Programmer和Employee都可以当做ISalary类型。使用接口的优势在于:一个类型只能从一个类派生,它只能继承有限的成员,但它可以从多个接口处通过实现接口的成员变成多种接口类型(权当是派生关系好了!),一个类通过实现N个接口就能使其拥有更多的可能(类型的多态性)。
接口规范
1.接口中只能定义非静态的、公共抽象的、具有代码块的成员,而每个成员默认都隐式地被修饰为public abstract,所以定义成员时,禁止使用public abstract和static。
2.接口一旦公布,就不要再试图为其增加成员,因为这考虑到向老版本兼容的问题,为了适应新的需求,就应该在接口被公布后为接口定义派生接口。接口的主要用途就是为了使多个类型享用多态性。
定义接口
//一个表示智力的接口
public interface Iintelligence
{
string Level { get; set; }
string Language();
} //隐式实现接口成员
public class Person : Iintelligence //实现接口快捷键:在:后,光标移入接口名,Alt+Shift+F10
{
private string level;
public string Level { get => ""; set => level = value; } } public string Language()
{
return "Earth language";
}
} //显示实现接口成员
public class Xperson : Iintelligence
{
private string level;
string Iintelligence.Level { get => level; set => level = value; } string Iintelligence.Language()
{
return "X language";
}
} public class Programe
{
static void Main(string[] args)
{
Person p = new Person();
string language = p.Language(); Xperson xperson = new Xperson();
string xLanguage = (xperson as Iintelligence).Language(); //隐式实现接口则用类实例直接调用接口成员
//显示实现接口则用接口实例显示调用接口成员
}
}
显示与隐式实现接口的区别
隐式实现了接口的类是帮助接口实现了它的成员,同时类自身的实例也拥有了接口的成员。显示实现接口的类虽然也帮助接口实现了它的成员,但类自身的实例并不具备接口的成员。而无论如何,接口因为被某个类所实现,所以使在内存中创建接口实例才成为了可能。关于显示实现接口和隐式实现接口之间的区别,同样可以用创建对象时对象在内存中的存储流程来加以解释,还是用上面的代码加以解说:
Person p = new Person( );
//隐式实现接口,当使用new操作符实例化Person时,首先会实例化Person的基类对象(System.Object)
//当Object在内存中被创建后,接着new操作符调用Person的构造函数,构造函数发现Person隐式实现了Iintelligence接口的成员
//所以立马计算基于Person实现的Iintelligence版本的接口的成员所占用的空间大小,然后在堆上初始化这些成员。
//接着在内存中初始化Person的成员,然后将接口实例的地址交给Person持有,由于Person是隐式实现Iintelligence接口,所以被实现的接口成员又在Person对象中被存储
//也即,隐式实现接口,那么实现的成员同时存储在两个地方,一个是存储在内存中的接口实例之中,一个是存储在Person实例中,并且Person实例还持有对内存中的接口实例的引用
//那么访问接口成员就有三种方式,要么直接用Person实例访问(因为它自身已经存储了被实现的接口成员),要么将Person实例显示或隐式转换为接口实例 //直接访问在内存中的Person实例自身所包含的Iintelligence接口成员Language:
string language = p.Language( );
//将Person显示转换为Iintelligence接口类型,然后访问存储在内存中的Iintelligence接口实例中的Language成员:
string language2 = ( p as Iintelligence ).Language( );
//将p隐式转换为Iintelligence接口类型,为什么可以隐式转换为Iintelligence?正是因为Person实例持有对内存中的接口实例的引用,这跟派生类实例存储了内存中的基类实例的引用是完全一样的:
Iintelligence IintelligenceObj = p;
string language3=IintelligenceObj.Language( );//然后访问存储在内存中的Iintelligence接口实例中的Language成员 Xperson xperson = new Xperson( );
//显示实现接口,当使用new操作符实例化Xperson时,首先会实例化Xperson的基类对象(System.Object)
//当Object在内存中被创建后,接着new操作符调用XPerson的构造函数,构造函数发现XPerson显示实现了Iintelligence接口的成员
//所以立马计算基于XPerson实现的Iintelligence版本的接口的成员所占用的空间大小,然后在堆上初始化这些成员。
//接着在内存中初始化XPerson的成员,然后将接口实例的地址交给XPerson持有,由于XPerson是x显示实现Iintelligence接口,所以被实现的接口成员不会在Xperson对象中被存储,它们只存储在内存中的Iintelligence接口实例中
//也即,显示实现接口,那么实现的成员只存储在一个地方,即存储在内存中的接口实例之中
//那么访问接口成员只有两种方式,将Xperson实例显示或隐式转换为接口实例 string xLanguage = ( xperson as Iintelligence ).Language( );
Iintelligence IintelligenceXobj = xperson;
string xLanguage2 = IintelligenceXobj.Language( );
什么时候该显示实现接口,什么时候又该隐式实现接口呢?
在面向对象编程的设计思路中,应明确模型的从属关系和接口的非模型从属关系。比如Person类自身本应具备说出一种语言的功能,所以就应该考虑将Language方法定义为Person的原生成员方法,也即说出语言这种成员从属于Person,是模拟了模型从属关系。而接口不考虑这种模型从属关系,比如Person表示一个人,它不可能具备比较、排序这样的功能,比较、排序不从属于Person,所以这不是模型从属关系。但这不妨碍通过接口使Person具备比较和排序的功能,所以应该将语义并非是明确的、非核心的或可能本身就是非从属关系的成员定义到接口中去,以便让类保持它的成员具有隶属于它的高度凝聚性。那么在实现接口的时候,就要问自己,假如将接口中的成员作为Person自身的成员是否合适是否恰当,如果没什么违和之处,则使用隐式方式去实现接口。这样在使用Person实例访问接口成员时就相当于在访问自己的成员,如果有违和之处则以显示的方式实现接口,这样在访问接口成员时就需要将实现接口的类实例转换为接口类型实例以便访问接口的成员,这样做就可以很清楚的看出访问的成员是接口成员而非自己的成员。最后,一个接口中的某些成员可能更适合被显示实现,另一些则适合被隐式实现,C#完全允许当一个类实现接口成员时,一部分成员被显示实现,另一部分被隐式实现。
派生接口
public interface IFather { void Xxx( ); }
public interface IChild : IFather { void Yyy( ); }
public class Test : IChild
{
void IFather.Xxx( ) { }
void IChild.Yyy( ) { }
}
public class Test2 : IChild,IFather
{
void IFather.Xxx( ) { }
void IChild.Yyy( ) { }
}
接口的扩展方法
可以为类型扩展方法,同样的,也可以为接口类型扩展方法。 在Linq中,正是由Enumerable类扩展了IEnumerable<T>接口的方法,才使所有实现了IEnumerable<T>接口的类型可以使用Linq提供的扩展方法。而在System.Collections命名空间下的集合类虽然不能使用那些从IEnumerable<T>上扩展的方法,但可以通过调用非泛型集合的Cast<T>方法将其转换为泛型集合,使其可以使用Enumerable类提供的Linq扩展方法。扩展方法最佳搭档就是接口,不要试图为某个单一的类型定义扩展方法(因为几乎毫无必要),应像Linq那样为接口定义扩展方法,这样,每个实现接口的类型就都会继承为接口定义的扩展。
public class Book : IListable { }
public interface IListable { }
public static class IListableCollectionExtention
{
public static int GetMyCount ( this IListable [] xIListableArray )
{
return xIListableArray.Count ( );
}
}
public class Programe
{
static void Main ( string [ ] args )
{
Book [ ] b = { };
int count=b.GetMyCount ( );
}
}
委托(Delegate)
委托是C语言中的函数指针的升级版,变量存储的是内存中某个数据的地址,而函数不但存储了数据的地址,它还存储了一系列的指令。有两种方式可以调用函数:
1.直接调用
写上函数名加括号,这样,在运行时CPU扫描到调用函数的代码时,会根据函数名直接在内存里查询这个函数的地址,然后执行它。
2.间接调用
利用委托(函数指针)来调用函数,先将函数的内存地址存储在函数指针中,这样,在运行时CPU扫描到函数指针的执行代码时,会先读取函数地址从而在内存中找到函数,然后执行它
简而言之,委托(函数指针)是一种C#类型,委托对象则是一个函数实例。
public delegate void Calculator( double x, double y );
class Program
{
//Show方法可以看成是Calculator委托类型,因为它匹配了Calculator的返回类型和参数签名
static void Show( double x, double y )
{
Console.WriteLine( x + y );
}
static void Main( string[] args )
{
//委托是一种类型,所以可以实例化它,实例化时,将Show注册在Calculator上
Calculator calculator = new Calculator( Show );
//现在可以这样调用Show方法
calculator( , );
//这样调用Show方法好像并没有什么意义,但注意Show方法已经可以被当做一种类型来使用,
//也即,Show方法可以被当做一个有类型的变量了
//所以,你完全可以将其作为参数传递给另外的函数
Test( calculator );
}
static void Test(Calculator calculator )
{
calculator( , );
}
}
内置委托
.NET内置了两个非常实用的委托类型,如果不喜欢手动定义委托,可以考虑使用它们。
无返回值的委托
Action()
Action<in T1>(T1 args1 ),
Action<in T1, in T2>(T1 args1, T2 args2),
Action<in T1, in T2, in T3>(T1 args1, T2 args2, T3 args3),
……
Action委托有16个版本,委托类型参数同时也是委托参数,每个T类型都支持逆变。
public static void Show(Action<string> action)
{
action("sam");
} static void Main(string[] args)
{
//lambda表达式符合Action<string>委托的签名和返回类型void,所以可以当做Action<string>委托来使用
Show((str) => { Console.WriteLine(str); });
}
有返回值的委托类型
Func<out TResult>( ),
Func <in T1 , out TResult > ( T1 args1 ),
Func<in T1 , in T2 , out TResult > ( T1 args1 , T2 args2 ),
Func <in T1 , in T2 , in T3 , out TResult > (T1 args1 , T2 args2 , T3 args3),
……
Func委托有17个版本,每个版本除开最后一个类型参数是返回类型,前面16个类型参数同时也是委托参数且支持逆变,最后一个类型参数支持协变。
static void Test ( Func<Father , Child > func )
{
Func< Child, Father> c = func; //支持协变的Child类型转换为了Father类型,支持逆变的Father类型转换为了Child
c ( new Child { Car = "奔驰" } );
}
static void Main ( string [ ] args )
{
Test ( ( c ) => { Console.WriteLine ( c.Car ); return new Child { Computer = "奔驰" }; } );
}
委托弊端
委托很容易使用,但难以精通它,它属于方法级别的紧耦合,debug时难度会剧增,如果委托使用不当,会造成内存泄漏,因为被委托的函数始终是属于对象,对象与委托有了关联就不容易被释放。所以慎用复杂委托,平常应多考虑使用接口替代委托。
事件(Event )
简单来说,事件的概念就是:我需要将某个类内部发生的事情通知给其它的类,让其它的类对这个事情进行响应。打个比方,两个邻居就是两个类,比如A类和C类,两个邻居平时之间互无关系,A邻居哪天要是生病了,需要B邻居的帮助,但A邻居生病这个事儿如何传达给B邻居呢?所以,需要一个在A类中定义一个代理,然后在B类中定义一个响应(处理)事件的方法,再将这个方法注册到A类的代理中去,在A类中针对生病这个事儿再定义一个生病的事件(OnSick方法),当A生病的事件发生时(调用OnSick方法),A可以就在OnSick方法中调用代理去执行B的响应逻辑。总结起来也就三步:
1.A类中定义一个事件代理,可使用内置的EventHandler委托作为代理,事件委托必须使用event关键字来修饰,而EventHandler只不过是一个规范,你也可以不使用它,比如直接用其他的自定义的委托类型。EventHandler的签名参数是一个obejct和一个EventArgs,前者表示发布事件的源对象,后者表示附加的一些信息,比如你可以定义一些自定义的事件信息,如果需要附加信息,则必须定义一个类,使其从EventArgs派生,信息以属性的方式定义即可。
2.A类中定义一个事件,事件就是一个方法,按照约定,该方法必须以On做前缀
3.B类中定义一个处理事件的方法
public class A
{
public string name;
public event EventHandler Sick; //定义一个事件委托 //定义生病的事件
public void OnSick()
{
Sick.Invoke(this, null);
}
} public class B
{
//事件处理器,匹配了EventHandler委托的签名,可当做委托使用
public void ReceiveForSick(object source, EventArgs e)
{
Console.WriteLine($"{(source as A).name},我送你去医院吧!");
}
} public class Programe
{
static void Main(string[] args)
{
A a = new A();
a.name = "sam";
B b = new B();
a.Sick += b.ReceiveForSick; //B订阅A的生病事件
a.OnSick();//手动触发事件
}
}

另一种写法则是让事件接收一个事件处理器,比如一个Action委托,这样就不需要在A类中定义事件委托了
public class A
{
public string name;
//定义生病的事件,接收一个事件处理器
public void OnSick(Action<A> action)
{
action.Invoke(this); //执行事件处理器
}
} public class B
{
//事件处理器
public void ReceiveForSick(A a)
{
Console.WriteLine($"{a.name},我送你去医院吧!");
}
} public class Programe
{
static void Main(string[] args)
{
A a = new A();
a.name = "sam";
B b = new B();
a.OnSick(b.ReceiveForSick); //但假如有10个人对此事件感兴趣,则发布事件时得写10行代码来调用OnSick
}
}
如果需要详细参透事件这个概念,可以参考下面的解说,如果喜欢快速写出一个事件,马上用起来,那么以上代码就已经足够了。
订阅事件
其他类/对象可能对某个事件有兴趣,而事件定义在与它们毫无瓜葛的类里边,所以要想知道事件的发生,那些类/对象就必须订阅它,也即通过某种形式去关注它。
事件通知
如果某个类/对象订阅了某个事件,那么事件发生后,事件就会通过某种形式去通知它,并且事件可能会附带一些事件的信息(数据)公开给对它感兴趣的类/对象,以便类/对象能拿到某些数据信息针对事件的发生进行处理,而这些数据就是参数。通知总是由拥有该事件的类的对象在完成某个逻辑之后明确告诉事件成员:你快去通知其他类/对象。这样,事件才会发出通知。通知一旦发出,订阅了这个事件的类/对象就会开始处理,它在订阅的当时就会制定一个处理器专门针对某一事件作出响应。事件处理器与事件必须遵守同一个约定。也即你的事件处理器必须与事件的要求匹配,否则你不能处理该事件。
事件的5个必要
事件拥有者(Event Source)
事件成员(Event)
事件的响应者(Event subscriber)
事件处理器(Event Handler)
订阅事件(Subscribe to events)
事件的4种情形
事件拥有者与事件订阅者是它自身。
事件拥有者与事件订阅者是独立的。
事件拥有者是事件订阅者的一个成员。
事件订阅者是事件拥有者的一个成员。
//事件拥有者与事件订阅者是独立的。
namespace ConsoleApplication2
{
class Program
{
static void Main(string[] args)
{
Timer time = new Timer();
time.Interval = ;
Boy boy = new Boy();
time.Elapsed += boy.Action;//Elapsed事件被boy对象以Action方法所订阅,也即boy对象以Action方法注册了该事件,一旦注册,它就有了处理它的资格。
Girl girl = new Girl();
time.Elapsed += girl.Action;
time.Start();
Console.ReadLine();
}
}
class Boy
{
public void Action(object o,ElapsedEventArgs e)
{
Console.WriteLine("Boy Jump!");
}
}
class Girl
{
public void Action(object o,ElapsedEventArgs e)
{
Console.WriteLine("Girl Jump!");
}
}
}
//事件拥有者是事件响应者的一个字段成员
namespace ConsoleApplication2
{
class Program
{
static void Main(string[] args)
{
Form form = new Form();
Controller controller = new Controller(form);
form.ShowDialog();
}
}
class Controller
{
private Form form;
public Controller(Form form)
{
if (form!=null)
{
this.form = form;
this.form.Click += this.FormClick;
}
} private void FormClick(object sender, EventArgs e)
{
this.form.Text = DateTime.UtcNow.ToString();
}
}
}
//事件拥有者与事件订阅者是它自身。
namespace ConsoleApplication2
{
class Program
{
static void Main(string[] args)
{
Form form = new Form();
form.Click += new EventHandler(form.ResponseClick);
form.ShowDialog();
}
} public static class FormExtension
{
public static void ResponseClick(this Form form,object o,EventArgs e)
{
Form f = (Form)o;
f.Text = DateTime.UtcNow.ToString();
}
}
}
事件订阅的不同写法
//以下写法全部等同。
form.Click +=form.ResponseClick
//使用Click内置的EventHandler委托代理事件订阅者订阅事件
form.Click += new EventHandler(form.ResponseClick);
//使用匿名委托代理事件订阅者订阅事件
form.Click += delegate (object o, EventArgs e)
{
form.Text = DateTime.UtcNow.ToString();
};
//使用Lambda表达式定义匿名委托,用匿名委托代理事件订阅者订阅事件,编译器会自动根据委托的参数类型推断出o和e的数据类型
form.Click += ( o, e) =>
{
form.Text = DateTime.UtcNow.ToString();
};
自定义事件
framework有自己的内置事件,你也可以自定义事件。事件与事件订阅者需要依靠一个约束(规范)进行匹配,这个任务是由中间角色委托来实现的,委托名应官方要求最好写成:委托名EventHandler,这样就表示这个委托是一种事件委托。委托要发布自己的规范,按照官方的"国际惯例",这个委托规范就是两个固定的参数,官方要求参数1是发布事件的对象,参数2是代表能存储事件信息的对象。
下面通过一个实际的例子:出版社发布新书,通知顾客,顾客购买这样一个流程一步一步对自定义事件加以说明:
首先我们需要一个委托中介。
/出版社发布新书,通知顾客,顾客购买。
//首先定义事件约束,即定义一个中介者(委托),它就是事件对象和事件处理对象的中间角色,它规范了双方如何遵守约定来匹配这个发布事件。
public delegate void OderEventHandler(Publishing publishing, Book book);
还需要两个类,即出版社和新书的类。
//出版社
public class Publishing
{ }
//新书信息
public class Book:EventArgs
{ }
出版社应该有一个名字:
public class Publishing
{
//出版社名字
public string publishingName="译林出版社";
}
新书要有自己的书籍信息,因为它是事件信息,按照官方的要求,这种事件信息类必须派生自EventArgs。
//新书信息
public class Book:EventArgs
{
string bookName;
double bookPrice;
}
出版社(事件拥有者)必须拥有规范事件的委托,因为委托是中间角色,外部订阅事件时需要订阅到委托上去。比如这个新书发布事件我们称为PublishingBook,想象一下外部某个人要订阅这个事件可能的代码如下:
Person p = new Person();
Publishing publishing = new Publishing();
//此人用他的Buy方法(事件处理器)订阅了新书发布事件
publishing.PublishingBook += p.Buy;
而这个事件必然是由委托代理执行,所以定义事件实际上就是把事件处理器注册到委托上面去。
//出版社
public class Publishing
{
//事件拥有者必须拥有规范事件的委托,因为委托是中间角色,外部订阅事件时需要订阅到委托上去。
private OderEventHandler o;
}
事件的定义需要实现add(事件添加器)和remove(事件移除器)。其中value就代表了上面代码中的 p.Buy。
public class Publishing
{
//事件拥有者必须拥有规范事件的委托,因为委托是中间角色,外部订阅事件时需要订阅到委托上去。
private OderEventHandler o;
//定义事件
public event OderEventHandler PublishingBook
{
add
{
o += value;
}
remove
{
o -= value;
}
}
}
以上就是一个事件的定义,接着我们需要事件响应者,即一个堆新书感兴趣的人。
public class Person
{
//事件处理器:买书 要想订阅新书事件,必须匹配事件委托所给出的参数规范,两个参数就是委托规范的参数类型
public void Buy(Publishing p,Book b)
{ }
}
拥有事件处理器的对象就会因为它的处理器遵守了委托的规范从而拿到了事件拥有者与事件信息的对象,它就可以在自己的代码内内访问到它们。
public class Person
{
//事件处理器:买书 要想订阅新书事件 必须匹配事件委托的所给出的参数规范
public void Buy(Publishing p,Book b)
{
Console.WriteLine("谢谢{0},我知道你们发布了新书,我需要为新书《{1}》付{2}元", p.publishingName,b.bookName, b.bookPrice);
}
}
如此,事件已经定义完毕。接着如何触发这个事件呢?我们知道.net framework有它内置的触发事件机制,那是适用于窗体、按钮的内置触发机制,而我们自定义的事件则没有被规定如何触发,这需要我们自己用代码手动实现触发,发布新书自然是由出版社去执行,以下代码写在出版社这个类中:
//触发新书发布事件
public void TrrigerBook()
{
Book book = new Book();
book.bookName = "万有引力之虹";
book.bookPrice = 20.8;
o.Invoke(this, book);
}
最后就是让Person去订阅事件,让出版社去发布(触发)事件:
Person p = new Person();
Publishing publishing = new Publishing();
//订阅新书发布事件
publishing.PublishingBook += p.Buy;
publishing.TrrigerBook();
完整代码如下:
namespace ConsoleApplication2
{ class Program
{
static void Main(string[] args)
{
Person p = new Person();
Publishing publishing = new Publishing();
//订阅新书发布事件
publishing.PublishingBook += p.Buy;
publishing.TrrigerBook();
}
} //出版社发布新书,通知顾客,顾客购买。
//首先定义事件约束,即定义一个中介者(委托),它就是事件对象和事件处理对象的中间角色,它规范了双方如何遵守约定来匹配这个发布事件。
public delegate void OderEventHandler(Publishing publishing, Book book);
//出版社
public class Publishing
{
//事件拥有者必须拥有规范事件的委托,因为委托是中间角色,外部订阅事件时需要订阅到委托上去。
private OderEventHandler o;
//出版社名字
public string publishingName="译林出版社";
//定义事件
public event OderEventHandler PublishingBook
{
add
{
o += value;
}
remove
{
o -= value;
}
}
//触发新书发布事件
public void TrrigerBook()
{
Book book = new Book();
book.bookName = "万有引力之虹";
book.bookPrice = 20.8;
o.Invoke(this, book);
}
} //新书信息
public class Book:EventArgs
{
public string bookName;
public double bookPrice;
} //对新书有兴趣的人
public class Person
{
//事件处理器:买书 要想订阅新书事件 必须匹配事件委托的所给出的参数规范
public void Buy(Publishing p,Book b)
{
Console.WriteLine("谢谢{0},我知道你们发布了新书,我需要为新书《{1}》付{2}元", p.publishingName,b.bookName, b.bookPrice);
}
}
}

定义事件的简约写法
把事件发布者的私有的委托字段删掉,声明一个事件:
public class Publishing
{
public event OderEventHandler PublishingBook;
//出版社名字
public string publishingName = "译林出版社"; //触发新书发布事件
public void TrrigerBook()
{
Book book = new Book();
book.bookName = "万有引力之虹";
book.bookPrice = 20.8;
PublishingBook.Invoke(this,book);
}
}
为什么不直接使用委托而偏偏要事件?因为委托可以被任意调用,如果外面的用户直接操纵委托执行代码,那外面的用户就可以擅自创建两个被他修改过的对象然后把他们扔进委托里,这就造成了混乱。比如:
public class Publishing
{
public OderEventHandler PublishingBook;
//出版社名字
public string publishingName = "译林出版社"; //触发新书发布事件
public void TrrigerBook()
{
Book book = new Book();
book.bookName = "万有引力之虹";
book.bookPrice = 20.8;
PublishingBook.Invoke(this, book);
}
} static void Main(string[] args)
{
Publishing publishing = new Publishing();
Person p = new Person();
Book book = new Book();
book.bookName = "寂静的春天";
book.bookPrice = ;
publishing.PublishingBook = new OderEventHandler(p.Buy);//先订阅
publishing.PublishingBook.Invoke(publishing, book);//接着直接操纵被公布的PublishingBook委托实例
}

所以委托并不安全,微软发明了事件正是基于这样一种防止外面用户的恶意行为的考虑,因为被定义为event的对象它不会接受外面用户的传值,外面的用户想要访问事件,唯一能做的就是使用+=,然后把他自己的处理器注册给它,他是不可能提供任何数据给事件的,事件不接受别人的数据,从而也就防止了委托实例被调用后造成的弊端。我们要记住的就是事件拥有者才有定义数据如何展现的逻辑,它是主控者,而关注事件的对象,它们没有任何权利去篡改数据、投机取巧。即事件时封装了委托的一个包装器,事件让委托更为安全。
继续简化事件的定义
EventHandler是一个内置的事件委托,基于它我们就可以写出事件而不需要手动定义事件委托。EventHandler它有两个参数,object和EventArgs ,其实这两个类型参数不过就是任意类型的对象而已,它接收这两个参数无非就是为了发布事件时顺带把事件拥有者和事件信息一并发布出去以便让关注事件并作出响应的人可以获得这些数据,所以我们今后不需要自定义事件委托,利用EventHandler就可以了。
public class Publishing
{
//直接利用微软的事件委托声明一个事件字段
public event EventHandler PublishingBookHandler;
//出版社名字
public string publishingName = "译林出版社"; //触发新书发布事件
public void TrrigerBook()
{
Book book = new Book();
book.bookName = "万有引力之虹";
book.bookPrice = 20.8;
//执行订阅者对新书发布事件的响应
PublishingBookHandler.Invoke(this, book);
}
} //对新书有兴趣的人
public class Person
{
//事件处理器:买书 要想订阅新书事件 必须匹配事件委托的所给出的参数规范
public void Buy(object p, EventArgs b)
{
//EventHandler 事件委托规定需要object和EventArgs类型的参数,所以接到参数后需要强制转换为出版社和新书这两个目标对象
Publishing publish = p as Publishing;
Book book = b as Book;
Console.WriteLine("谢谢{0},我知道你们发布了新书,\n我需要为新书《{1}》付{2}元", publish.publishingName, book.bookName, book.bookPrice);
}
}
最终,我们发现事件的定义非常简单,总结起来就三点:
1.事件发布者只需要声明事件委托并使用event关键字,不需要添加add和remove代码块。
2.不需要自定义事件约束(自定义事件委托)
3.事件处理器强转一下两个参数对象就可以用了。
4.触发事件的函数方法名通常要加前缀On以表明这是一个可触发事件的方法。
5.事件字段通常要加后缀EventHandler
6.事件是委托的包装器,定义事件字段不是在定义委托字段!
最终代码很简单:
namespace ConsoleApplication2
{ class Program
{
static void Main(string[] args)
{
Publishing publishing = new Publishing();
Person p = new Person();
publishing.PublishingBookHandler += p.Buy;
publishing.OnTrrigerBook();
}
} //出版社
public class Publishing
{
//直接利用微软的事件委托声明一个事件字段
public event EventHandler PublishingBookHandler;
//出版社名字
public string publishingName = "译林出版社"; //触发新书发布事件
public void OnTrrigerBook()
{
Book book = new Book();
book.bookName = "万有引力之虹";
book.bookPrice = 20.8;
PublishingBookHandler.Invoke(this, book);
}
} //新书信息
public class Book : EventArgs
{
public string bookName;
public double bookPrice;
} //对新书有兴趣的人
public class Person
{
//事件处理器:买书 要想订阅新书事件 必须匹配事件委托的所给出的参数规范
public void Buy(object p, EventArgs b)
{
//EventHandler 事件委托规定需要object和EventArgs类型的参数,所以接到参数后需要强制转换为出版社和新书这两个目标对象
Publishing publish = p as Publishing;
Book book = b as Book;
Console.WriteLine("谢谢{0},我知道你们发布了新书,\n我需要为新书《{1}》付{2}元", publish.publishingName, book.bookName, book.bookPrice);
}
}
}
泛型(Generic)
假如没有泛型……
//没有泛型前,C#语言存在两个问题:类型安全问题和装箱拆箱问题
public struct Cell
{
public readonly int X;
public readonly int Y;
public Cell(int x , int y)
{
X = x;
Y = y;
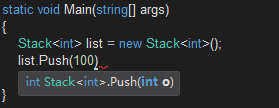
} } public class Stack
{
public object Push(object o)
{
//其它实现逻辑略……
return o;
}
} //这个表示栈集合的类有一个Push方法,它接收任意类型作为参数并将参数对象作为元素压入集合中,最后返回这个参数对象
//Stack是类型非常不安全的类型,因为它接收的是object类型,任何类型都从object派生,这意味着别人可以传递任意类型给Push
//如果传递了一个不是预期的类型给Push,那么我们在取出元素,将其转换为期望的类型时就有一个转换失败的异常被抛出
//所以,Stack类型就成为一个不安全的类型 //如果传递的是引用类型,那么问题不大,因为不会发生装箱拆箱的操作。
//但假如传递的是值类型,首先Push方法就会将其装箱为object
//当取出元素时,需要将object转换为目标值类型,这又发生了拆箱
//要将值类型转换为object,就得在堆上划分内存,将值复制到堆上存储
//将object拆箱时,又会将堆上的数据转移到栈上
//循环重复地对元素进行装箱、拆箱的过程就会造成大的性能损耗
//所以,Stack类型又成为一个不高效的类型
//在System.Collections命名空间中定义的集合类都是不安全、不高效的集合类型
//比如Stack、Queue 、ArrayList 、Hashtable 、SortedList ……
//所以我们需要一种解决方案,以便让类型变得更加安全、更加高效
//为了解决这两个问题,可以尝试强迫Stack只处理我们期望的类型,比如将Stack改为: public class Cell { } public class Stack
{
public Cell Push(Cell o)
{
//其它实现逻辑略……
return o;
}
} //这样,Push就只接收Cell类型的实例,取出元素时不需要再进行转换。ok,似乎完美解决问题。
//但接下来,还想让Stack存储int类型的元素,怎么办?答案是只能重载Push,ok,似乎完美解决问题。
//再接下来,还想让Stack存储Animal类型的元素,怎么办?答案是只能重载Push,ok,似乎完美解决问题。
//继而接下来,还想让Stack存储Person类型的元素、String类型的元素、Employee类型的元素、无数类型的元素,怎么办?答案是只能重载Push,这……
//是不是没完没了了?所以,重载函数不可能从根本上解决类型安全与转换的问题。
泛型的定义与使用
类、接口、结构都可以定义成泛型,泛型的构造函数不需要尖括号,因为定义泛型时已经定义好了泛型的形参。既然泛型也是一种类型,类具有的一切特征,泛型也都具备,是共通的。
//泛型自身被视为一种类型,而尖括号里的T被称为形参变量,T相当于是一个占位符,它表示某种任意的类型
public class Template<T> { } //读作:Template for T类型
//只有在定义泛型的时候,才可以定义泛型形参,每个形参以逗号隔开
public class Template2<T,V> { }
//在泛型类内部,任何位置处都能使用泛型形参作为成员、变量的类型
public class Template3<T, V, Key>
{
public T person;
public V favit;
public Key numberCode;
public void GetCount(T xPerson)
{
person = xPerson;
}
} //在泛型类外部,不能使用泛型形参,必须提供实参,实参就是真实的类型
//如何确定什么时候是在定义泛型,什么时候又是在使用泛型呢?
//类型的定义是你在创建该类型的时候为其下的定义,而除开为类型下定义的位置,在任何其它位置访问泛型时都将被视为使用泛型,使用泛型就必须提供实参
public class Person { }
Template3<Person , string , int> temp = new Template3<Person , string , int>( ); //外部访问泛型时,必须提供实参 //想象一下,函数可以接收形参,但函数的形参是一个指向对象的变量,而泛型的形参是一个指向类型的变量
//也即函数的形参变量表示对象,泛型的形参变量表示类型 //在定义泛型时,在泛型内部可以定义三种泛型成员
//未完全提供实参的泛型
//完全未提供实参的泛型
//完全提供了实参的泛型
public class Template3<T, V, Key>
{
public Template<T> tem;//完全未提供实参的泛型
public Template<string> reTem; //完全提供了实参的泛型
public Template2<T , int> tem2; //未完全提供实参的泛型
} //上面代码中没有为tem成员提供实参,这是因为在泛型Template3<T, V, Key>的内部,因为有T的定义
//当外部访问Template3<T, V, Key>时,必然提供T的实参,这样T的实参就作为了tem(Template<T>)中(T)的实参
//实现泛型接口也尊崇这样的原则:
public interface IPair<T>
{
T First { get; set; }
} //Pair自身不是泛型,没有泛型形参,实现IPair<T>时提供的实参是string
public class Pair : IPair<string>
{
private string first;
public string First { get => first; set => first = value; }
} //Pair2自身是泛型,泛型形参是X,实现IPair<T>时提供的实参是X
public class Pair2<X> : IPair<X>
{
private X first;
public X First { get => first; set => first = value; }
}
现在利用泛型来解决类型安全和装箱拆箱的问题就很简单了:

下次要压入int类型的元素时,只需要声明int版本的Stack集合
泛型重载
确定泛型重载是根据类型参数的个数不同。
类型参数默认值
因为泛型只有在使用时才提供实参,所以如果在泛型的构造函数中为泛型成员赋默认值,此时就不知道该成员究竟是值类型还是引用类型,可使用default ( Type ) 操作符为泛型成员赋默认值。
public Key numberCode = default(Key );
泛型类型形参变量的比较
泛型类型形参变量不能使用==和!=操作符用于测试等同性,可以考虑使用Equals()方法或Object.Equals()方法。参考:C# - 系统类和系统接口
泛型派生
泛型也是类类型,具有类类型的特点,所以可以派生,继承泛型的子类可以是泛型类或非泛型类。
元组(Tuple)
关系数据库中每条记录(行)被称为元组,而每一列的数据被称为元数。在C#中,一组有关联的数据组合在一起就称为元组,每个操作数则称为元数。C#预定义了8个叫做Tuple的元组类。
Tuple<T1>
Tuple<T1 , T2>
Tuple<T1 , T2 , T3>
Tuple<T1 , T2 , T3 , T4>
Tuple<T1 , T2 , T3 , T4 , T5>
Tuple<T1 , T2 , T3 , T4 , T5 , T6>
Tuple<T1 , T2 , T3 , T4 , T5 , T6 , T7>
Tuple<T1 , T2 , T3 , T4 , T5 , T6 , T7 , T8>
它最多允许接收8个形参用以创建一个元组对象,元数是只读的,不可写,可按顺序从item1-item8访问元数。因为每一个T类型同时也可以是一个元组,所以Tuple中的每个元数也称为元组。
//创建一行数据 ValueTuple<int, string> v1 = ValueTuple.Create(1, "sam");
Console.WriteLine(v1.Item1); //print 1
Console.WriteLine(v1.Item2); //print sam //方式二
(int ID, string Name) v3 = (1, "sam");
Console.WriteLine(v3.ID);//print 1
Console.WriteLine(v3.Name);//print sam //创建二维表 //方式一
(ValueTuple<int, string> row1, ValueTuple<int, string> row2) table = ((1, "sam"), (2, "leo"));
Console.WriteLine(table.row1.Item1);//print 1
Console.WriteLine(table.row1.Item2);//print sam
Console.WriteLine(table.row2.Item1);//print 2
Console.WriteLine(table.row2.Item2);//print leo //方式二
(int ID, string Name) row1= (1, "sam");
(int ID, string Name) row2 = (2, "leo");
var table2 = (row1, row2);
Console.WriteLine(table2.row1.ID);//print 1
Console.WriteLine(table2.row1.Name);//print sam
Console.WriteLine(table2.row2.ID);//print 2
Console.WriteLine(table2.row2.Name);//print leo
Tuple应用场景
1.函数只能返回一个某种类型的变量,当某函数需要返回多个变量时,可使用out、ref修饰传引用或传输出的参数,还可以让函数直接返回一个值元组
static Tuple<int , string , float , Tuple<string>> Test( )
{
return Tuple.Create( , "sam" , 1.75f , Tuple.Create( "favit:none" ) );
}
2.当函数需要接收一系列参数时,不需要params而以元组作为替代
static void Test(Tuple<int , string , float , Tuple<string>> tuple )
{
int ID = tuple.Item1;
string name = tuple.Item2; }
static void Main(string [ ] args)
{
Test( Tuple.Create( , "sam" , 1.75f , Tuple.Create( "favit:none" ) ) );
}
值元组(ValueTuple)
值元组是C#7.0的新类,framework4.7已经内置,如果是4.7以下版本则可以通过NuGet下载。
ValueTuple
ValueTuple<T1>
ValueTuple<T1 , T2>
ValueTuple<T1 , T2 , T3>
ValueTuple<T1 , T2 , T3 , T4>
ValueTuple<T1 , T2 , T3 , T4 , T5>
ValueTuple<T1 , T2 , T3 , T4 , T5 , T6>
ValueTuple<T1 , T2 , T3 , T4 , T5 , T6 , T7>
ValueTuple<T1 , T2 , T3 , T4 , T5 , T6 , T7 , TRest>
区别于Tuple是引用类型的泛型,ValueTuple是结构类型的泛型,而且值元组不但可读可写,它还有新的语法糖使代码得以简化。声明一个值元组类型,可以使用ValueTuple的Create工厂方法,但用语法糖将进一步简化代码量。
//创建一行数据 ValueTuple<int, string> v1 = ValueTuple.Create(1, "sam");
Console.WriteLine(v1.Item1); //print 1
Console.WriteLine(v1.Item2); //print sam //方式二
(int ID, string Name) v3 = (1, "sam");
Console.WriteLine(v3.ID);//print 1
Console.WriteLine(v3.Name);//print sam //创建二维表 //方式一
(ValueTuple<int, string> row1, ValueTuple<int, string> row2) table = ((1, "sam"), (2, "leo"));
Console.WriteLine(table.row1.Item1);//print 1
Console.WriteLine(table.row1.Item2);//print sam
Console.WriteLine(table.row2.Item1);//print 2
Console.WriteLine(table.row2.Item2);//print leo //方式二
(int ID, string Name) row1= (1, "sam");
(int ID, string Name) row2 = (2, "leo");
var table2 = (row1, row2);
Console.WriteLine(table2.row1.ID);//print 1
Console.WriteLine(table2.row1.Name);//print sam
Console.WriteLine(table2.row2.ID);//print 2
Console.WriteLine(table2.row2.Name);//print leo
应用值元组的场景
//返回一个值元组类型
static (int ID, string Name) GetData()
{
return (1, "sam");//值元组实例
} //接收一个值元组类型
static void GetData((int ID,string Name) valueTuple)
{
int id = valueTuple.ID;
string name = valueTuple.Name;
}
泛型方法
当泛型类所定义的类型形参不满足方法的需求时,可以考虑将方法定义成泛型方法,具有自己独有的类型形参的方法称为泛型方法。既然泛型方法也是一种方法,方法具有的一切特征,泛型方法也都具备,是共通的。
public class Unknown<T>
{
//非泛型方法
public static void Take1 ( T x ) { }
//泛型方法
public static void Take2<X> ( X x , T t ) { }
} public class Anonymous
{
//泛型方法
public static void Take2<X, T> ( X x , T t ) { }
}
泛型方法重载
确定泛型方法重载是根据类型参数的个数不同或方法参数的不同。
调用泛型方法
调用泛型方法时,如果该方法的类型形参出现在方法的参数列表中则可以不指定类型实参,因为编译器会自行对调用方法时圆括号中的参数类型进而类型推断从而确定类型形参的实参类型,但假如类型形参没有出现在方法的参数列表中,此时必须显示地指定方法的类型实参。
public class Anonymous
{
public static void Take<T>(T x, T y) { }
public static void PickUp<T>(string z) { }
} public class Programe
{
static void Main(string[] args)
{
Anonymous.Take("sam", "korn"); //Take<T>的T形参出现在了圆括号的参数列表中,调用方法时可以不指定类型实参,编译器自动推断
Anonymous.PickUp<int>("sam"); //PickUp<T>的T形参没有出现在圆括号的参数列表中,调用方法时必须指定类型实参
}
}
泛型的协变与逆变
C#仅允许泛型接口和泛型委托支持类型参数的可变性(协变、逆变),什么意思呢?先看一个泛型接口
public interface IFication<T>
{
void Test(T t);
} public class Animal : IFication<Animal>
{
void IFication<Animal>.Test(Animal t) { }
} public class Person :Animal, IFication<Person>
{
void IFication<Person>.Test(Person t) { }
} public class Programe
{
static void Main(string[] args)
{
Animal a = new Animal();
IFication<Animal> aFication = a;
IFication<Person> pFication = aFication; //提示无法进行转换
//声明Animal变量时,在栈上划分32位的空间以便存储Aniaml对象在堆上的地址
//使用new操作符调用Animal构造函数,构造函数发现Animal实现了IFication接口,
//于是将基于Animal实现的IFication版本的接口实例存储在内存中,并将接口的地址交给Animal变量持有
//构造函数计算Animal成员所能占用的空间大小,然后初始化成员
//将Animal对象隐式转换为IFication<Animal>接口
//试图将变量aFication转换为IFication<Person>类型
//右边操作数只持有基于Animal实现的IFication版本的接口实例的地址和自身的地址
//它并不持有左边操作数的类型在内存中的地址,所以这个转换是失败的
}
}
两个泛型接口或泛型委托中的类型参数如果存在派生关系,那么理论上是可以实现相互转换的,而这种转换需要你自己做出判断后,使用out、in关键字去声明泛型接口/委托的类型参数,out和in关键字用于声明泛型接口/委托的类型参数究竟是支持协变还是支持逆变,声明后编译器就会通过,不再提示错误。
协变:out(输出参数), 表示接口的类型参数可以转换为其父类型(子转父)
逆变:in,(输入参数),表示接口的类型参数可以转换为其子类型(父转子)
//-------------------支持逆变的三种判断方式-------------------
//1.接口方法将T用于方法的参数,不用于方法的返回类型
//2.接口的方法将另一个支持T协变的接口用于方法的参数,不用于方法的返回类型
//3.接口的方法将另一个支持T逆变的接口用于方法的返回类型,不用于方法的参数 //-------------------支持协变的三种判断方式-------------------
//1.接口方法将T用于方法的返回类型,不用于方法的参数
//2.接口的方法将另一个支持T协变的接口用于方法的返回类型,不用于方法的参数
//3.接口的方法将另一个支持T逆变的接口用于方法的参数,不用于方法的返回类型
public interface IFication<in T>
{
void Test(T t);
}
那接口中可能不止一个方法,假如其他方法将T作为了返回类型又怎么办呢?因为Test是接收T而非输出T,所以该接口支持逆变,现在多了一个输出T的方法,我们就不知道该如何为T定义in或out了!其实很简单,如果这种情况存在,那说明你的泛型接口不支持协变也不支持逆变,编译器会提醒你错误。也即泛型接口/委托能不能支持协变、逆变与方法有关,首先我们是定义方法而不是专注于去设计协变逆变,能支持就支持,不能支持就拉倒,就这么简单。
//以下三种写法都支持T类型的逆变: //第一种:
public interface IFication<in T>
{
void Test ( T t );
} //第二种:
public interface IFication<in T>
{
void Test ( IRecation<T> );
} public interface IRecation<out X>
{
X ReTest ( );
} //第三种:
public interface IFication<in T>
{
IRecation<T> Test ( );
} public interface IRecation<in X>
{
void ReTest ( X x );
} IFication<Animal> a = new Animal ( );
IFication<Person> p = a;
//以下三种写法都支持T类型的协变: //第一种:
public interface IFication<out T>
{
T Test ( );
} //第二种:
public interface IFication<out T>
{
IRecation<T> Test ( );
} public interface IRecation<out X>
{
X ReTest ( );
} //第三种:
public interface IFication<out T>
{
void Test ( IRecation<T> t );
} public interface IRecation<in X>
{
void ReTest ( X x );
} IFication<Person> p = new Person ( );
IFication<Animal> a = p;
画图秒懂:

参考了这篇大神的文章:.NET 4.0中的泛型协变和逆变(大神去世了,愿一路走好)。
泛型约束
泛型的类型参数可以指向任何类型,假如要处理T类型,但T类型是不确定的类型,这就没法调用其构造函数创建其实例了。所以C#提供了泛型约束,用以指明T类型可用的类型范围。可以为类型形参指定多个约束,约束总是放在泛型类型声明的结尾处,约束以where T : 开头,每个约束以逗号隔开。可以指定非密封类的约束如下::
2.引用类型约束:class,必须出现在约束的最开始且只能有一个,不能同时指定Animal或struct
3.值类型约束:struct,必须出现在约束的最开始且只能有一个,不能同时指定Animal或class
4.无参构造器约束:new( ) [如果不指定构造器约束则编译器不允许这样的类型形参调用构造函数]
public class Stack<T, W, S, X, Y, H, P>
where T : IComparable // T类型必须实现IComparable接口
where S : struct // S类型必须是结构
where X : IComparable, new() // X类型必须实现IComparable接口且拥有无参构造函数
where Y : Animal // Y类型必须是Animal类或派生自Animal
where H : class // H类型必须是一个引用类型
where P : T //P类型必须派生自T
{ } //一个容易出错的例子
public class Template<T> { } public class List<X, Y>
where X : Template<Y>
{
public X GetX ( )
{
return new Template<Y> ( ); //提示:无法将Template<Y>隐式转换为X
}
} // X 可能是一个Template<Y>的派生,假设用户传递的是子类,则X=子,而new Template<Y>是直接创建new Template<Y>的实例(父),所以这个转换是失败的
如果基类泛型的某个类型形参有一个约束,那么从其派生的泛型类在继承基类泛型时提供的类型参数也必须得到与基类相同的约束,在保证与基类一致的约束前提下,派生泛型可以继续为类型参数增加更多的约束。
如果泛型方法是一个虚方法,当该方法为某个类型形参指定约束后,派生类如果重写了此方法,则不能再次对类型形参提供约束,因为只能修改基类方法的实现,而不能修改为方法所下的定义,约束已经在基类方法中完成定义,没必要重复为方法定义两次约束。但new隐藏基类的泛型方法可以提供新的约束,因为该方法是派生类自己的成员而非基类,所以不受限制。
泛型的CIL表示
public class Stack<T>
{
T [ ] Items;
}

Stack ' 1表示该泛型的元数是1,泛型中的类型参数以!表示
泛型静态构造函数
与普通类型的静态构造函数的逻辑是一致的,但需要注意 Animal<string>和Animal<Person>不是相同的类型,所以Animal<string>的静态成员(类成员)与Animal<Person>的静态成员是相互独立的版本,当访问这两个不同类型的成员或实例化它们时,它们的静态构造函数自然会各自独立执行而不是只执行一次。
泛型的本地代码
定义泛型时定义的是个类型模板,它并不能用来执行并创建出对象。这就像把类进行了一次抽象,运行时先要将模板转化为真正可执行的泛型类型,接着才能实例化泛型。运行时会根据类型参数(值类型或引用类型)的不同而创建不同的本地代码。,本地代码才使真正可执行的、能创建出对象的代码。
//在运行时会根据类型实参的不同创建不同的本地代码
public class Stack<T>
{
public T x;
public T Test (T t )
{
return t;
}
}
//如果是值类型,那么不同的值类型会创建不同的本地代码
//所谓本地代码就是如下所示的、真正可用于实例化泛型的类型代码
//比如使用Stack<T>时提供的类型实参是Stack<int>,则运行时生成的本地代码如下
public class Stack<int>
{
public int x;
public int Test ( int t )
{
return t;
}
}
//比如使用Stack<T>时提供的类型实参是Stack<long>,则运行时生成的本地代码如下
public class Stack<long>
{
public long x;
public long Test ( long t )
{
return t;
}
}
//比如使用Stack<T>时提供的类型实参是Stack<Animal>等所有的引用类型,则运行时生成的本地代码都是objec引用,t如下
//这样做的好处不言而喻,不需要为Stack<Animal>、Stack<Person>等类似的引用类型单独生成不同的本地代码,避免本地代码爆炸
//实例化泛型类型时,object会指向具体的泛型实例在内存堆上的地址
public class Stack<object>
{
public object x;
public object Test ( object t )
{
return t;
}
}
使用泛型
现在假设我们需要写一个能提供排序算法的MySort类,它的GetSort方法可以对int类型的数组执行排序。我们假设后来又需要对double类型的数组进行排序,那么我们唯一的办法就是重载GetSort方法,但这样的话就有两个版本的GetSort,它们的算法逻辑却是相同的,重复编写相同的代码是很蠢的事情,此时就可以考虑使用泛型了。
{
//将数组元素按从小到大排序
public class MySort
{
public void SetSort ( int [ ] intAry )
{
int aryLength = intAry.Length;
for ( int i = aryLength - ; i > ; i-- )
{
for ( int z = aryLength - ; z > ; z-- )
{
bool result = intAry [ z ].CompareTo ( intAry [ z - ] ) < ;
if ( result )
{
int temp = intAry [ z - ];
intAry [ z - ] = intAry [ z ];
intAry [ z ] = temp;
}
}
}
}
}
class Program
{
static void Main ( string [ ] args )
{
MySort m = new MySort ( );
int [ ] a = { , , , , , , , , , , , };
m.SetSort ( a );
foreach ( var item in a )
{
Console.WriteLine ( item );
}
}
}
}
非泛型的排序算法
{
public class MySort<T> where T : IComparable
{
public void SetSort ( T [ ] TAry )
{
int aryLength = TAry.Length;
for ( int i = aryLength - ; i > ; i-- )
{
for ( int z = aryLength - ; z > ; z-- )
{
bool result = TAry [ z ].CompareTo ( TAry [ z - ] ) < ;
if ( result )
{
T temp = TAry [ z - ];
TAry [ z - ] = TAry [ z ];
TAry [ z ] = temp;
}
}
}
}
}
class Program
{
static void Main ( string [ ] args )
{
MySort<double> m = new MySort<double> ( );
double [ ] a = { , , , , , , , , , , , };
m.SetSort ( a );
foreach ( var item in a )
{
Console.WriteLine ( item );
}
}
}
}
泛型排序算法
特性(Attribute)
特性也是一种类型,但用法与普通的类型有区别,使用[AttributeName(……)]将特性置于程序集、类型、结构、枚举、接口、委托、事件、字段、属性、方法、方法参数、泛型类型参数、返回值、程序模块(为了便于描述,暂且统称这些东西为特性的目标)等等的声明之前,用于对特性目标进行描述,编译器可以读取特性并自动根据特性的内部实现对特性目标采取相应的动作。
内置特性
1.Obsolete ( string message , bool IsError )
[Obsolete("此类已被抛弃,请使用XAnimal类创建实例",true)]
public class Animal //Animal是Obsolete的特性目标
{
public string name="蚂蚁";
}
Animal a = new Animal ( );
Console.WriteLine(a.name );

2.AttributeUsage ( AttributeTargets , AllowMultiple = bool , Inherited = bool )
用于定义在自定义的特性类上,
ValidOn:AttributeTargets枚举:用于指定特性只能运用在什么对象上,比如程序集、类型、构造函数、委托等等……
AllowMultiple=bool:指定自定义的特性是否可以在一个特性目标上被运用多次。
Inherited=bool:假如某父类和子类同时运用了某个特性,Inherited指定运用到子类上的特性是否可以持有对运用到父类上的特性的访问,如果Inherited=true则必须保证AllowMultiple=true,否则抛错。
AttributeTargets.Assembly; // 特性可以应用于程序集
AttributeTargets.All; // 特性可以应用于任何特性的目标
AttributeTargets.Class;
AttributeTargets.Constructor;
AttributeTargets.Delegate;
//略……
下面是Inherited的例子:
[AttributeUsage(AttributeTargets.All, AllowMultiple = true,Inherited=true)]
public class A : Attribute
{
public string Name;
public A(string str) { this.Name = str; }
} [A("xxx")]
public class Animal { }
[A("yyy")]
public class Person:Animal { } class Program
{
static void Main(string[] args)
{
Type t = typeof(Person);
var attri = t.GetCustomAttributes(true); //获取Person的特性集合
Console.WriteLine((attri[0] as A).Name); //yyy
Console.WriteLine((attri[1] as A).Name); //xxx
//如果Inherited=false 则attri数组只有一个实例,只返回yyy,不会返回父类的A.Name
//另,GetCustomAttributes方法的参数是一个额外的开关,如果传递false,则不会迭代到父类的A特性
}
}
3.assebly、module、return
打开项目的properties可以看到一个AsseblyInfo.cs文件,此文件大量运用了内置的assembly特性用于描述程序集的信息,例如公司、产品名,版本号等。注意,assebly和module这两个特性必须出现在所有using引用之后。assebly应出现在所有命名空间之前,而module应出现在所有类的声明之前。最后,return特性应出现在方法之前。下面是return特性的例子:
public class A : Attribute { public A(string description) { } }
public class Animal
{
[return: A("如果没有提供参数,将返回默认值sam")]
public string Name()
{
return "sam";
}
public string Name(string name)
{
return name;
}
}
4.Flags
这是一个专门应用在枚举上的特性,表示这是一个位标志枚举,可以利用这个特性使一组枚举值可以存储在一个变量中。参看本页的枚举一节。
自定义特性
使自定义的特性类从Attribute派生就可以了。从Attribute派生的类都自动隐性的添加了Attribute后缀,但声明特性或运用特性时可以不显示添加Attribute后缀,只有在以内联的方式访问特性时才需要提供后缀,如:typeof(AnalysisAttribute)
public class Analysis : Attribute
{
public string Description { get; set; }
public Analysis ( string message )
{
Description = message;
}
} [Analysis ( "此类是密封的,不能继承" )]
public sealed class Philosopher
{ } public class Programe
{
static void Main ( string [ ] args )
{
Type type = typeof ( Philosopher ); //获取Philosopher的Type表示
Attribute attri= type.GetCustomAttribute ( typeof ( Analysis ) ); //在Philosopher的Type表示上获取Analysis特性
Analysis analysis = attri as Analysis;
Console.WriteLine ( analysis.Description );
}
}
特性可以以逗号分隔写在一行,但合并的写法不适用于返回值、程序集和模块。
public class A : Attribute { }
public class B : Attribute { public SwitchAlias(string country) { } }
public class Animal
{
[A]
[B("chinese")]
public string Name { get; set; }
}
public class Animal
{
[A, B("chinese")]
public string Name { get; set; }
}
aa
C# - 类型的更多相关文章
- 【.net 深呼吸】细说CodeDom(5):类型成员
前文中,老周已经厚着脸皮介绍了类型的声明,类型里面包含的自然就是类型成员了,故,顺着这个思路,今天咱们就了解一下如何向类型添加成员. 咱们都知道,常见的类型成员,比如字段.属性.方法.事件.表示代码成 ...
- 【.net 深呼吸】细说CodeDom(4):类型定义
上一篇文章中说了命名空间,你猜猜接下来该说啥.是了,命名空间下面就是类型,知道了如何生成命名空间的定义代码,之后就该学会如何声明类型了. CLR的类型通常有这么几种:类.接口.结构.枚举.委托.是这么 ...
- opencv中Mat与IplImage,CVMat类型之间转换
opencv中对图像的处理是最基本的操作,一般的图像类型为IplImage类型,但是当我们对图像进行处理的时候,多数都是对像素矩阵进行处理,所以这三个类型之间的转换会对我们的工作带来便利. Mat类型 ...
- [C#] async 的三大返回类型
async 的三大返回类型 序 博主简单数了下自己发布过的异步文章,已经断断续续 8 篇了,这次我想以 async 的返回类型为例,单独谈谈. 异步方法具有三个可让开发人员选择的返回类型:Task&l ...
- C# - 值类型、引用类型&走出误区,容易错误的说法
1. 值类型与引用类型小总结 1)对于引用类型的表达式(如一个变量),它的值是一个引用,而非对象. 2)引用就像URL,是允许你访问真实信息的一小片数据. 3)对于值类型的表达式,它的值是实际的数据. ...
- salesforce 零基础学习(六十二)获取sObject中类型为Picklist的field values(含record type)
本篇引用以下三个链接: http://www.tgerm.com/2012/01/recordtype-specific-picklist-values.html?m=1 https://github ...
- Dapper逆天入门~强类型,动态类型,多映射,多返回值,增删改查+存储过程+事物案例演示
Dapper的牛逼就不扯蛋了,答应群友做个入门Demo的,现有园友需要,那么公开分享一下: 完整Demo:http://pan.baidu.com/s/1i3TcEzj 注 意 事 项:http:// ...
- ElasticSearch 5学习(9)——映射和分析(string类型废弃)
在ElasticSearch中,存入文档的内容类似于传统数据每个字段一样,都会有一个指定的属性,为了能够把日期字段处理成日期,把数字字段处理成数字,把字符串字段处理成字符串值,Elasticsearc ...
- js:给定两个数组,如何判断他们的相对应下标的元素类型是一样的
题目: 给Array对象原型上添加一个sameStructureAs方法,该方法接收一个任意类型的参数,要求返回当前数组与传入参数数组(假定是)相对应下标的元素类型是否一致. 假设已经写好了Array ...
- C++11特性——变量部分(using类型别名、constexpr常量表达式、auto类型推断、nullptr空指针等)
#include <iostream> using namespace std; int main() { using cullptr = const unsigned long long ...
随机推荐
- bzoj 2693: jzptab 线性筛积性函数
2693: jzptab Time Limit: 10 Sec Memory Limit: 512 MBSubmit: 444 Solved: 174[Submit][Status][Discus ...
- kafka.common.FailedToSendMessageException: Failed to send messages after 3 tries.
今天在写kafka生产者生成数据的程序并运行时,报如下错误: log4j:WARN No appenders could be found for logger (kafka.utils.Verifi ...
- Android用户界面 UI组件--TextView及其子类(二) Button,selector选择器,sharp属性
1.XML文件中的OnClick 属性可以指定在Activity中处理点击事件的方法,Activity中必须定义该属性指定的值作为方法的名字且有一个View类型的参数,表示此物件被点击. 2.使用se ...
- Linux libtins 库安装教程
因为工作原因需要用到libtins网络库, 所以今天去装一下. 很尴尬,由于本人对linux理解比较浅, 所以在中途遇到了一些问题. 虽然只是简单的安装步骤,但是阻挡不了自己菜啊. 一. 下载lib ...
- 安装PyQt
下载PyQt(版本一定要对) http://www.riverbankcomputing.com/software/pyqt/download import sys,urllib2 from HTML ...
- oracle 绑定变量
“绑定变量”这个词也许对于某些人来说看以来陌生,其实我们在很早的时候就已经开始运用它了. 在java中使用的PrepareStatement对象,大家一定会说这不是将sql语句做预编译操作嘛,被封装的 ...
- linux内核驱动中_IO, _IOR, _IOW, _IOWR 宏的用法与解析
在驱动程序里, ioctl() 函数上传送的变量 cmd 是应用程序用于区别设备驱动程序请求处理内容的值.cmd除了可区别数字外,还包含有助于处理的几种相应信息. cmd的大小为 32位,共分 4 个 ...
- GCC常用参数
GCC--GNU C Compiler c语言编译器(远不止c语言) 介绍: 作为自由软件的旗舰项目,Richard Stallman 在十多年前刚开始写作 GCC 的时候,还只是把它当作仅仅一个C ...
- Team Foundation Server操作说明
目录 一. Visual Studio 2010团队协作管理 1.1团队模型及角色 1.1.1创建角色 1.1.2创建工作组 1.1.3工作组成员及权限 1.2团队成员利用VS2010实现协同办公 1 ...
- 动态规划---最长公共子序列 hdu1159
hdu1159 题目要求两个字符串最长公共子序列, 状态转换方程 f[i][j]=f[i-1][j-1]+1; a[i]=b[j]时 f[i][j]=MAX{f[i-1][j],f[i][j-1] ...