SQLite入门与分析(七)---浅谈SQLite的虚拟机
写在前面:虚拟机技术在现在是一个非常热的技术,它的历史也很悠久。最早的虚拟机可追溯到IBM的VM/370,到上个世纪90年代,在计算机程序设计语言领域又出现一件革命性的事情——Java语言的出现,它与c++最大的不同在于它必须在Java虚拟机上运行。Java虚拟机掀起了虚拟机技术的热潮,随后,Microsoft也不甘落后,雄心勃勃的推出了.Net平台。由于在这里主要讨论SQLite的虚拟机,不打算对这些做过多评论,但是作为对比,我会先对Java虚拟机作一个概述。好了,下面进入正题。
1、概述
所谓虚拟机是指对真实计算机资源环境的一个抽象,它为解释性语言程序提供了一套完整的计算机接口。虚拟机的思想对现在的编译有很大影响,其思路是先编译成虚拟机指令,然后针对不同计算机实现该虚拟机。
虚拟机定义了一组抽象的逻辑组件,这些组件包括寄存器组、数据栈和指令集等等。虚拟机指令的解释执行包括3步:
1.获取指令参数;
2. 执行该指令对应的功能;
3. 分派下一条指令。
其中第一步和第三步构成了虚拟机的执行开销。
很多语言都采用了虚拟机作为运行环境。作为下一代计算平台的竞争者,Sun的Java和微软的.NET平台都采用了虚拟机技术。Java的支撑环境是Java虚拟机(Java Virtual Machine,JVM),.NET的支撑环境是通用语言运行库(Common Language Runtime,CLR)。JVM是典型的虚拟机架构。
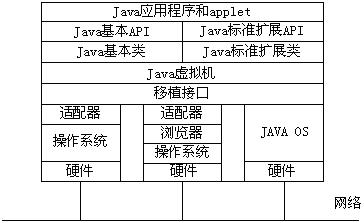
Java平台结构如图所示。从图中可以看出,JVM处于核心位置,它的下方是移植接口。移植接口由依赖平台的和不依赖平台的两部分组成,其中依赖于平台的部分称为适配器。JVM通过移植接口在具体的操作系统上实现。如果在Java操作系统(Java Operation System, JOS)上实现,则不需要依赖于平台的适配器,因为这部分工作已由JOS完成。因此对于JVM来说,操作系统和更低的硬件层是透明的。在JVM的上方,是Java类和Java应用程序接口(Java API)。在Java API上可以编写Java应用程序和Java小程序(applet)。所以对于Java应用程序和applet这一层次来说,操作系统和硬件就更是透明的了。我们编写的Java程序,可以在任何Java平台上运行而无需修改。
JVM定义了独立于平台的类文件格式和字节码形式的指令集。在任何Java程序的字节码表示形式中,变量和方法的引用都是使用符号,而不是使用具体的数字。由于内存的布局要在运行时才确定,所以类的变量和方法的改变不会影响现存的字节码。例如,一个Java程序引用了其他系统中的某个类,该系统中那个类的更新不会使这个Java程序崩溃。这也提高了Java的平台独立性。
虚拟机一般都采用了基于栈的架构,这种架构易于实现。虚拟机方法显著提高了程序语言的可移植性和安全性,但同时也导致了执行效率的下降。
2、Java虚拟机
2.1、概述
Java虚拟机的主要任务是装载Class文件并执行其中的字节码。Java虚拟机包含一个类装载器(class loader),它从程序和API中装载class文件,Java API中只有程序执行时需要的那些类才会被装载,字节码由执行引擎来执行。
不同的Java虚拟机,执行引擎的实现可能不同。在软件实现的虚拟机中,一般有几下几中实现方式:
(1) 解释执行:实现简单,但速度较慢,这是Java最初阶段的实现方式。
(2) 即时编译(just-in-time):执行较快,但消耗内存。在这种情况下,第一次执行的字节码会编译成本地机器代码,然后被缓存,以后可以重用。
(3) 自适应优化器:虚拟机开始的时候解释字节码,但是会监视程序的运行,并记录下使用最频繁的代码,然后把这些代码编译成本地代码,而其它的代码仍保持为字节码。该方法既提高的运行速度,又减少了内存开销。
同样,虚拟机也可由硬件来实现,它用本地方法执行Java字节码。
2.2、Java虚拟机
Java虚拟机的结构分为:类装载子系统,运行时数据区,执行引擎,本地方法接口。其中运行时数据区又分为:方法区,堆,Java栈,PC寄存器,本地方法栈。

关于Java虚拟机就介绍到此,由于Java虚拟机内容庞大,在这里不可能一一介绍,如果想更多了解Java虚拟机,参见《深入Java虚拟机》。
3、SQLite虚拟机
在SQLite的后端(backend)的上一层,通常叫做虚拟数据库引擎(virtual database engine),或者叫做虚拟机(virtual machine)。从作用上来说,它是SQLite的核心。用户程序发出的SQL语句请求,由前端(frontend)编译器(以后会继续介绍)处理,生成字节代码程序(bytecode programs),然后由VM解释执行。VM执行时,又会调用B-tree模块的相关的接口,并输出执行的结果(本节将以一个具体的查询过程来描述这一过程)。
3.1、虚拟机的内部结构
先来看一个简单的例子:
int main(int argc, char **argv)
{
int rc, i, id, cid;
char *name;
char *sql;
char *zErr;
sqlite3 *db; sqlite3_stmt *stmt;
sql="select id,name,cid from episodes";
//打开数据库
sqlite3_open("test.db", &db);
//编译sql语句
sqlite3_prepare(db, sql, strlen(sql), &stmt, NULL);
//调用VM,执行VDBE程序
rc = sqlite3_step(stmt);
while(rc == SQLITE_ROW) {
id = sqlite3_column_int(stmt, 0);
name = (char *)sqlite3_column_text(stmt, 1);
cid = sqlite3_column_int(stmt, 2);
if(name != NULL){
fprintf(stderr, "Row: id=%i, cid=%i, name='%s'\n", id,cid,name);
} else {
/* Field is NULL */
fprintf(stderr, "Row: id=%i, cid=%i, name=NULL\n", id,cid);
}
rc = sqlite3_step(stmt);
}
//释放资源
sqlite3_finalize(stmt);
//关闭数据库
sqlite3_close(db);
return 0;
}
这段程序很简单,它的功能就是遍历整个表,并把查询结果输出。
在SQLite 中,用户发出的SQL语句,都会由编译器生成一个虚拟机实例。在上面的例子中,变量sql代表的SQL语句经过sqlite3_prepare()处理后,便生成一个虚拟机实例——stmt。虚拟机实例从外部看到的结构是sqlite3_stmt所代表的数据结构,而在内部,是一个vdbe数据结构代表的实例。
关于这点可以看看它们的定义:
//sqlite3.h
typedef struct sqlite3_stmt sqlite3_stmt;
vdbe的定义:
Code
由vdbe的定义,可以总结出SQLite虚拟机的内部结构:

3.2、指令
int nOp; /* Number of instructions in the program(指令的条数) */ Op *aOp; /* Space to hold the virtual machine's program(指令)*/
aOp数组保存有SQL经过编译后生成的所有指令,对于上面的例子为:
0、Goto(0x5b-91) |0|0c 1、Integer(0x2d-45) |0|0 2、OpenRead(0x0c-12)|0|2 3、SetNumColumns(0x64-100)|0|03 4、Rewind(0x77-119) |0|0a 5、Rowid(0x23-35) |0|0 6、Column(0x02-2) |0|1 7、Column(0x02-2) |0|2 8、Callback(0x36-54)|3|0 9、Next(0x68) |0|5 10、Close 11、Halt 12、Transaction(0x66-102)|0|0 13、VerifyCookie(0x61-97)|0|1 14、Goto(0x5b-91) |0|1|
sqlite3_step()引起VDBE解释引擎执行这段代码,下面来分析该段指令的执行过程:
Goto:这是一条跳转指令,它的作用仅仅是跳到第12条指令;
Transaction:开始一个事务(读事务);
Goto:跳到第1条指令;
Integer:把操作数P1入栈,这里的0表示OpenRead指令打开的数据库的编号;
OpenRead:打开表的游标,数据库的编号从栈顶中取得,P1为游标的编号,P2为root page。
如果P2<=0,则从栈中取得root page no;
SetNumColumns:对P1确定的游标的列数设置为P2(在这里为3),在OP_Column指令执行前,该指令应该被调用来
设置表的列数;
Rewind:移动当前游标(P1)移到表或索引的第一条记录;
Rowid:把当前游标(P1)指向的记录的关键字压入栈;
Column:解析当前游标指定的记录的数据,p1为当前游标索引号,p2为列号,并将结果压入栈中;
Callback:该指令执行后,PC将指向下一条指令。该指令的执行会结束sqlite3_step()的运行,并向其返回
SQLITE_ROW ——如果存在记录的话;并将VDBE的PC指针指向下一条指令——即Next指令,所以当
重新 调用sqlite3_step()执行VDBE程序时,会执行Next指令(具体的分析见后面的指令实例分析);
Next:将游标移到下一条记录,并将PC指向第5条指令;
Close:关闭数据库。
3.3、栈
Mem *aStack; /* The operand stack, except string values(栈空间) */ Mem *pTos; /* Top entry in the operand stack(栈顶指针) */
aStack是VDBE执行时使用的栈,它主要用来保指令执行进需要的参数,以及指令执行时产生的中间结果(参见后面的指令实例分析)。
在计算机硬件领域,基于寄存器的架构已经压倒基于栈的架构成为当今的主流,但是在解释性的虚拟机领域,基于栈架构的实现占了上风。
1. 从编译的角度来看,许多编程语言可以很容易地被编译成栈架构机器语言。如果采用寄存器架构,编译器为了获得好的性能必须进行优化,如全局寄存器分配(这需要对数据流进行分析)。这种复杂的优化工作使虚拟机的便捷性大打折扣。
2. 如果采用寄存器架构,虚拟机必须经常保存和恢复寄存器中的内容。与硬件计算机相比,这些操作在虚拟机中的开销要大得多。因为每一条虚拟机指令都需要进行很费时的指令分派操作。虽然其它的指令也要分派,但是它们的语义内容更丰富。
3. 采用寄存器架构时,指令对应的操作数位于不同寄存器中,对操作数的寻址也是一个问题。而在基于栈的虚拟机中,操作数位于栈顶或紧跟在虚拟机指令之后。由于基于栈的架构的简便性,一些查询语言的实现也采用了此种架构。
SQLite的虚拟机就是基于栈架构的实现。每一个vdbe都有一个栈顶指针,它保存着vdbe的初始栈顶值。而在解释引擎中也有一个pTos,它们是有区别的:
(1)vdbe的pTos:在一趟vdbe执行的过程中不会变化,直到相应的指令修改它为止,在上面的例子中,Callback指令会修改其值(见指令分析)。
(2)而解释引擎中的pTos是随着指令的执行而动态变化的,在上面的例子中,Integer,Column指令的执行都会引起解释引擎pTos的改变。
3.4、指令计数器(PC)
每一个vdbe都有一个程序计数器,用来保存初始的计数器值。和pTos一样,解释引擎也有一个pc,它用来指向VM下一条要执行的指令。
3.5、解释引擎
经过编译器生成的vdbe最终都是由解释引擎解释执行的,SQLite的解释引擎实现的原理非常简单,本质上就是一个包含大量case语句的for循环,但是由于SQLite的指令较多(在version 3.3.6中是139条),所以代码比较庞大。
SQLite的解释引擎是在一个方法中实现的:
int sqlite3VdbeExec(
Vdbe *p /* The VDBE */
)
具体代码如下(为了阅读,去掉了一些不影响阅读的代码,具体见SQLite的源码):
/*执行VDBE程序.当从数据库中取出一行数据时,该函数会调用回调函数(如果有的话),
**或者返回SQLITE_ROW.
*/
int sqlite3VdbeExec(
Vdbe *p /* The VDBE */
){
//指令计数器
int pc; /* The program counter */
//当前指令
Op *pOp; /* Current operation */
int rc = SQLITE_OK; /* Value to return */
//数据库
sqlite3 *db = p->db; /* The database */
u8 encoding = ENC(db); /* The database encoding */
//栈顶
Mem *pTos; /* Top entry in the operand stack */
if( p->magic!=VDBE_MAGIC_RUN ) return SQLITE_MISUSE;
//当前栈顶指针
pTos = p->pTos;
if( p->rc==SQLITE_NOMEM ){
/* This happens if a malloc() inside a call to sqlite3_column_text() or
** sqlite3_column_text16() failed. */
goto no_mem;
}
p->rc = SQLITE_OK;
//如果需要进行出栈操作,则进行出栈操作
if( p->popStack ){
popStack(&pTos, p->popStack);
p->popStack = 0;
}
//表明栈中没有结果
p->resOnStack = 0;
db->busyHandler.nBusy = 0;
//执行指令
for(pc=p->pc; rc==SQLITE_OK; pc++){
//取出操作码
pOp = &p->aOp[pc];
switch( pOp->opcode ){
//跳到操作数P2指向的指令
case OP_Goto: { /* no-push */
CHECK_FOR_INTERRUPT;
//设置pc
pc = pOp->p2 - 1;
break;
}
//P1入栈
case OP_Integer: {
//当前栈顶指针上移
pTos++;
//设为整型
pTos->flags = MEM_Int;
//取操作数P1,并赋值
pTos->i = pOp->p1;
break;
}
//其它指令的实现
}//end switch
}//end for
}
3.6、指令实例分析
由于篇幅限制,仅给出几条的指令的实现,其它具体实现见源码。
1、Callback指令
Code
2、Rewind指令
Code
3、Column指令
Code
4、Next指令
Code
SQLite入门与分析(七)---浅谈SQLite的虚拟机的更多相关文章
- SQLite入门与分析(六)---再谈SQLite的锁
写在前面:SQLite封锁机制的实现需要底层文件系统的支持,不管是Linux,还是Windows,都提供了文件锁的机制,而这为SQLite提供了强大的支持.本节就来谈谈SQLite使用到的文件锁——主 ...
- SQLite入门与分析(二)---设计与概念(续)
SQLite入门与分析(二)---设计与概念(续) 写在前面:本节讨论事务,事务是DBMS最核心的技术之一.在计算机科学史上,有三位科学家因在数据库领域的成就而获ACM图灵奖,而其中之一Jim G ...
- 【分析】浅谈C#中Control的Invoke与BeginInvoke在主副线程中的执行顺序和区别(SamWang)
[分析]浅谈C#中Control的Invoke与BeginInvoke在主副线程中的执行顺序和区别(SamWang) 今天无意中看到有关Invoke和BeginInvoke的一些资料,不太清楚它们之间 ...
- SQLite入门与分析(四)---Page Cache之事务处理(2)
写在前面:个人认为pager层是SQLite实现最为核心的模块,它具有四大功能:I/O,页面缓存,并发控制和日志恢复.而这些功能不仅是上层Btree的基础,而且对系统的性能和健壮性有关至关重要的影响. ...
- SQLite入门与分析(三)---内核概述(1)
写在前面:从本章开始,我们开始进入SQLite的内核.为了能更好的理解SQLite,我先从总的结构上讨论一下内核,从全局把握SQLite很重要.SQLite的内核实现不是很难,但是也不是很简单.总的来 ...
- Web Service进阶(七)浅谈SOAP Webservice和RESTful Webservice
浅谈SOAP Webservice和RESTful Webservice REST是一种架构风格,其核心是面向资源,REST专门针对网络应用设计和开发方式,以降低开发的复杂性,提高系统的可伸缩性.RE ...
- SQLite入门与分析(四)---Page Cache之事务处理(1)
写在前面:从本章开始,将对SQLite的每个模块进行讨论.讨论的顺序按照我阅读SQLite的顺序来进行,由于项目的需要,以及时间关系,不能给出一个完整的计划,但是我会先讨论我认为比较重要的内容.本节讨 ...
- SQLite入门与分析(三)---内核概述(2)
写在前面:本节是前一节内容的后续部分,这两节都是从全局的角度SQLite内核各个模块的设计和功能.只有从全局上把握SQLite,才会更容易的理解SQLite的实现.SQLite采用了层次化,模块化的设 ...
- SQLite入门与分析(二)---设计与概念
写在前面:谢谢各位的关注,没想到会有这么多人关注.高兴的同时,也感到压力,因为我接触SQLite也就几天,也没在实际开发中用过,只是最近项目的需求才来研究它,所以我很担心自己的文章是否会有错误,误导别 ...
随机推荐
- ASP 生成带日期的随机数
<% Function getRnd() '**************************************** '返回值:如getRnd(),即输出2008082415534646 ...
- Java .Net C++ RSA 加密
原文:http://www.codeproject.com/Articles/25487/Cryptographic-Interoperability-Keys DEMO: JAVA .Net C++
- C#学习笔记3:提示“截断字符串或二进制数据”错误解决方法
1.调试程序如出现“截断字符串或二进制数据”的关于数据库的错误,可以先试一试修改数据库中字符定义的长度. 2.使用ManualResetEvent前需导入 命名空间System.Threading; ...
- PHP 实现对象的持久层,数据库使用MySQL
http://www.xuebuyuan.com/1236808.html 心血来潮,做了一下PHP的对象到数据库的简单持久层. 不常用PHP,对PHP也不熟,关于PHP反射的大部分内容都是现学的. ...
- aspx文件移动到新建的文件夹中设置路径的问题
项目中仅仅把aspx移动到想要的文件夹内是会出错的,不用想也知道是路径问题.这里我就说这个路径该如何去修改. 两个地方需要修改:1.母版路径修改方法: <link href="Styl ...
- 如何在浏览器网页中实现java小应用程序的功能
我们知道,java语言的运用就是面向对象实现功能,和c不同,java语言对于程序员来说,运用起来更为简便. 小应用程序与应用程序不同,小应用程序只能在与Java兼容的容器中运行,可以嵌入在HTML网页 ...
- JavaScript实现点击按钮弹出输入框,点确定后添加li组件到ul组件里
JavaScript实现点击按钮弹出输入框,点确定后添加li组件到ul组件里 <!doctype html> <html manifest="lab4.manifest&q ...
- NUnit单元测试
单元测试对程序员来说是非常重要的一门技术,但是在实际编程中却往往被程序员所忽视.微软的VS开发工具为我们提供了强大的单元测试环境,在VS当中可以直接对类库项目进行测试,极大的方便了程序员的自我纠错能力 ...
- UniqueID,页面子控件唯一标示
aspx: <form id="form1" runat="server"> <asp :Repeater ID="MyDa ...
- 细说PHP中strlen和mb_strlen的区别
在PHP中,strlen与mb_strlen是求字符串长度的函数,但是对于一些初学者来说,如果不看手册,也许不太清楚其中的区别.下面通过例子,讲解这两者之间的区别. $str='中文a字1符'; ec ...