memcached 学习笔记 3
适合什么场合
memcached不是万能的,它也不是适用在所有场合。
Memcached是“分布式”的内存对象缓存系统,那么就是说,那些不需要“分布”的,不需要共享的,或者干脆规模小到只有一台服务器的应用,memcached不会带来任何好处,相反还会拖慢系统效率,因为网络连接同样需要资源,即使是UNIX本地连接也一样。 在我之前的测试数据中显示,memcached本地读写速度要比直接PHP内存数组慢几十倍,而APC、共享内存方式都和直接数组差不多。可见,如果只是本地级缓存,使用memcached是非常不划算的。
Memcached在很多时候都是作为数据库前端cache使用的。因为它比数据库少了很多SQL解析、磁盘操作等开销,而且它是使用内存来管理数据的,所以它可以提供比直接读取数据库更好的性能,在大型系统中,访问同样的数据是很频繁的,memcached可以大大降低数据库压力,使系统执行效率提升。另外,memcached也经常作为服务器之间数据共享的存储媒介,例如在SSO系统中保存系统单点登陆状态的数据就可以保存在memcached中,被多个应用共享。
需要注意的是,memcached使用内存管理数据,所以它是易失的,当服务器重启,或者memcached进程中止,数据便会丢失,所以memcached不能用来持久保存数据。很多人的错误理解,memcached的性能非常好,好到了内存和硬盘的对比程度,其实memcached使用内存并不会得到成百上千的读写速度提高,它的实际瓶颈在于网络连接,它和使用磁盘的数据库系统相比,好处在于它本身非常“轻”,因为没有过多的开销和直接的读写方式,它可以轻松应付非常大的数据交换量,所以经常会出现两条千兆网络带宽都满负荷了,memcached进程本身并不占用多少CPU资源的情况。
典型的应用场景可以简单示意为:
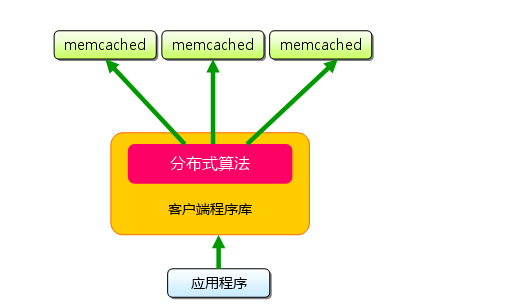
memcached的分布式
1)memcached但服务器端并没有“分布式”功能。分布式是完全由客户端程序库实现的。这种分布式是memcached的最大特点。
2)set(存数据到memcached)时,set(‘key’,data),将’key’传给客户端程序库后,
客户端实现的算法就会根据“键”来决定保存数据的memcached服务器。服务器选定后,即命令它保存(’key’,data);
3)get(从memcached取数据)时,get(‘key’),此时客户端把’key’传递给函数库,函数库通过与数据保存时相同的算法,根据“键”选择服务器。
使用的算法相同,就能选中与保存时相同的服务器,然后发送get命令。只要数据没有因为某些原因被删除,就能获得保存的值。
4)以上将不同的键保存到不同的服务器上,就实现了memcached的分布式。 memcached服务器增多后,键就会分散,
即使一台memcached服务器发生故障无法连接,也不会影响其他的缓存,系统依然能继续运行。
5)Cache::Memcached的分布式算法简单来说,就是“根据服务器台数的余数进行分散”。 求得键的整数哈希值[使用crc32函数,如crc32($key)],再除以服务器台数,根据其余数来选择服务器。余数计算的方法简单,数据的分散性也相当优秀,但也有其缺点。那就是当添加或移除服务器时,缓存重组的代价相当巨大。
memcached 的分布式算法
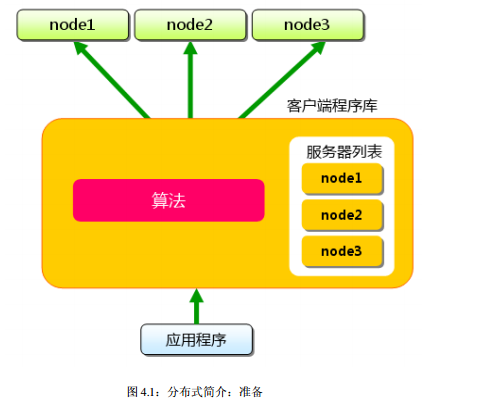
这里多次使用了“ 分布式” 这个词, 但并未做详细解释。现在开始简单地介绍一下其原理, 各个客户端的实现基本相同。
下面假设 memcached 服务器有 node1~node3 三台,应用程序要保存键名为“ tokyo”、 “ kanagawa”、 “ chiba”、 “ saitama”、 “ gunma”的数据。
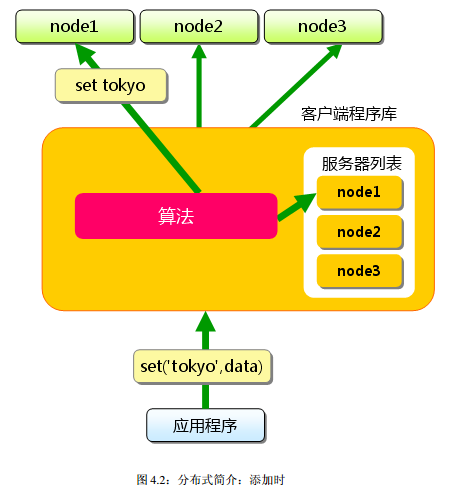
首先向 memcached 中添加“ tokyo”。
将“ tokyo”传给客户端程序库后,客户端实现的算法就会根据“ 键” 来决定保存数据的 memcached 服务器。
服务器选定后, 即命令它保存“ tokyo”及其值。
同样, “ kanagawa”、 “ chiba”、 “ saitama”、 “ gunma”都是先选择服务器再保存。
接下来获取保存的数据。获取时也要将要获取的键“ tokyo”传递给函数库。
函数库通过与数据保存时相同的算法,根据“ 键”选择服务器。使用的算法相同, 就能选中与保存时相同的服务器,然后发送 get 命令。
只要数据没有因为某些原因被删除, 就能获得保存的值。
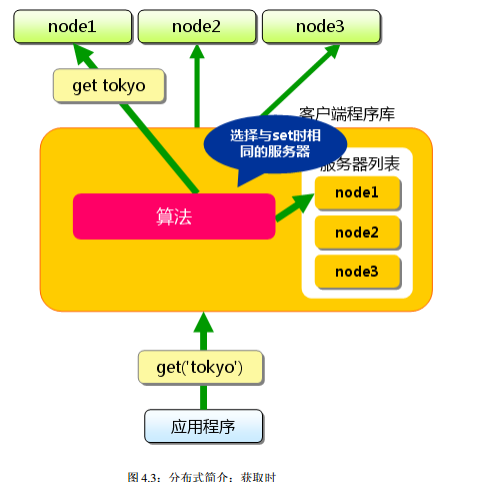
这样, 将不同的键保存到不同的服务器上, 就实现了 memcached 的分布式。
memcached 服务器增多后,键就会分散, 即使一台 memcached 服务器发生故障无法连接,也不会影响其他的缓存,系统依然能继续运行。
根据余数计算分散
Cache::Memcached 的分布式方法简单来说, 就是“ 根据服务器台数的余数进行分散” 。
求得键的整数哈希值, 再除以服务器台数,根据其余数来选择服务器。
下面将 Cache::Memcached 简化成以下的 Perl 脚本来进行说明。
use strict;
use warnings;
use String::CRC32;
my @nodes = ('node1','node2','node3');
my @keys = ('tokyo', 'kanagawa', 'chiba', 'saitama', 'gunma');
foreach my $key (@keys) {
my $crc = crc32($key); # CRC 値
my $mod = $crc % ( $#nodes + 1 );
my $server = $nodes[ $mod ]; # 根据余数选择服务器
printf "%s => %s\n", $key, $server;
}
Cache::Memcached 在求哈希值时使用了 CRC。
首先求得字符串 的 CRC 值,根据该值除以服务器节点数目 得到的余数决定服务器。上面的代码执行后输入以下结果:
tokyo => node2
kanagawa => node3
chiba => node2
saitama => node1
gunma => node1
根据该结果, “ tokyo”分散到 node2, “ kanagawa”分散到 node3 等。
多说一句, 当选择的服务器无法连接时, Cache::Memcached 会将连接次数添加到键之后, 再次计算哈希值并尝试连接。
这个动作称为 rehash。不希望 rehash 时可以在生成 Cache::Memcached 对象时指定“ rehash => 0”选项。
缺点:
余数计算的方法简单,数据的分散性也相当优秀, 但也有其缺点。那就是当添加或移除服务器时,
缓存重组的代价相当巨大。 添加服务器后,余数就会产生巨变,这样就无法获取与保存时相同的服务器,从而影响缓存的命中率。
Consistent Hashing
Consistent Hashing 如下所示: 首先求出 memcached 服务器(节点)的哈希值, 并将其配置到 0~232的圆( continuum)上。
然后用同样的方法求出存储数据的键的哈希值, 并映射到圆上。然后从数据映射到的位置开始顺时针查找, 将数据保存到找到的第一个服务器上。
如果超过 232 仍然找不到服务器, 就会保存到第一台 memcached 服务器上。
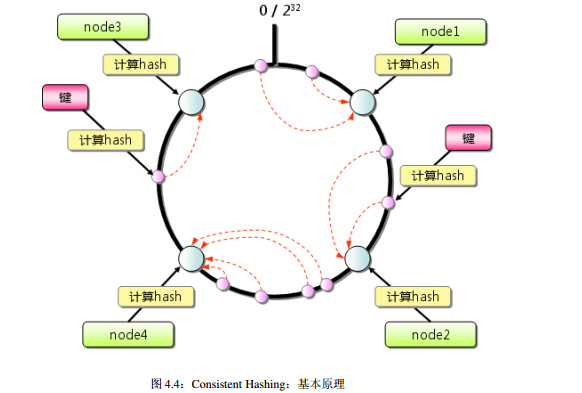
从上图的状态中添加一台 memcached 服务器。余数分布式算法由于保存键的服务器会发生巨大变化而影响缓存的命中率,
但 Consistent Hashing 中, 只有在 continuum 上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响。

因此, Consistent Hashing 最大限度地抑制了键的重新分布。
而且,有的 Consistent Hashing 的实现方法还采用了虚拟节点的思想。使用一般的 hash 函数的话,服务器的映射地点的分布非常不均匀。
因此,使用虚拟节点的思想,为每个物理节点(服务器)在 continuum 上分配 100~200 个点。
这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。
通过下文中介绍的使用 Consistent Hashing 算法的 memcached 客户端函数库进行测试的结果是,
由服务器台数( n)和增加的服务器台数( m)计算增加服务器后的命中率计算公式如下:(1 n/(n+m)) * 100
memcached 学习笔记 3的更多相关文章
- memcached学习笔记——存储命令源码分析下篇
上一篇回顾:<memcached学习笔记——存储命令源码分析上篇>通过分析memcached的存储命令源码的过程,了解了memcached如何解析文本命令和mencached的内存管理机制 ...
- memcached学习笔记——存储命令源码分析上篇
原创文章,转载请标明,谢谢. 上一篇分析过memcached的连接模型,了解memcached是如何高效处理客户端连接,这一篇分析memcached源码中的process_update_command ...
- Memcached 学习笔记(二)——ruby调用
Memcached 学习笔记(二)——ruby调用 上一节我们讲述了怎样安装memcached及memcached常用命令.这一节我们将通过ruby来调用memcached相关操作. 第一步,安装ru ...
- Memcached学习笔记
[TOC] 前言 此为学习笔记汇总,如有纰漏之处,还望不吝指出,谢谢. 启动流程 调用settings_init()设定初始化参数 从启动命令中读取参数来设置setting值 设定LIMIT参数 开始 ...
- memcached学习笔记2--安装及命令
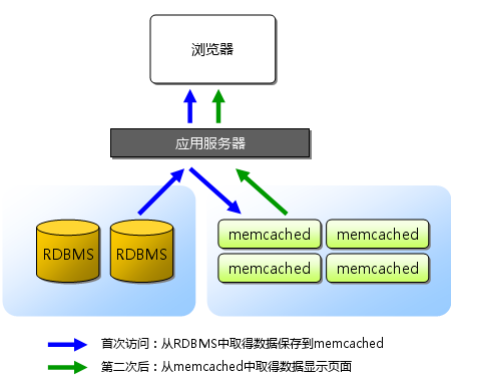
学习memcached的原理: 用户一 -> 访问浏览器 -> 服务器Apache -> PHP文件(该文件应用了memcached技术) -> [第一次]到数据库DB中查找数 ...
- memcached学习笔记6--浅谈memcached的机制 以及 memcached细节讨论
附:请浅谈memcached的机制 答: ①基于C/S架构,协议比较简单 c/s架构,此时memcached为服务器端,我们可以使用如PHP,c++/c等程序连接memcached服务器. memca ...
- memcached学习笔记5--socke操作memcached 缓存系统
使用条件:当我们没有权限或者不能使用服务器的时候,我们需要用socket操作memcached memcached-client操作 特点: 无需开启memcache扩展 使用fsocketopen( ...
- memcached学习笔记4--memcache扩展操作memcached
1. 安装并配置memcache扩展库 找到php.ini文件 添加: extendsion= php_memcache.dll 并把对应的dll文件拷贝到ext目录 2. 使用PHP对Memcahc ...
- memcached学习笔记3--telnet操作memcached
方式: 一.telnet访问memcached缓存系统(主要用于教学,不讨论) telnet 127.0.0.1 11211 => telnet IP地址 端口号 //往Memcache ...
- memcached学习笔记1--概念
1.memcached是danga的一个项目,最早是LiveJournal服务的,最初为了加速LiveJournal访问速度而开发,后来被很多大型网站采用 官网: http://www.danga.c ...
随机推荐
- ArcGIS(批量)删除属性字段
ArcGIS下删除属性字段有两种方式:① 单个删除:② 批量删除. 单个删除 批量删除 尽管如此,ArcGIS桌面软件在属性字段的编辑上并不太方便,所以我们自己做了一些工具辅助平时的内业处理工作.(* ...
- archlinux 64bit 开发android
arch 64位下直接运行android emulator会出现错误:“Failed to start emulator: Cannot run program "xxxx/sdk/tool ...
- Buffer Pool--内存总结1
物理地址空间是处理器用来访问位于总线上的所有部件的集合.在32位处理器上,地址总线为32位,寻址空间为4GB.在使用PAE的32位服务器上,地址总线为36位,寻址空间为64GB.在64位的处理器上生产 ...
- .net使用QQ邮箱发送邮件
/// <summary> /// 发送邮件 /// </summary> /// <param name="mailTo">要发送的邮箱< ...
- 对Integer类中的私有IntegerCache缓存类的一点记录
对Integer类中的私有IntegerCache缓存类的一点记录 // Integer类有内部缓存,存贮着-128 到 127. // 所以,每个使用这些数字的变量都指向同一个缓存数据 // 因此可 ...
- linq与数据库之添加
这个是linq的添加显示 代码如下: //添加 private void button2_Click(object sender, EventArgs e) { string strstu = &qu ...
- 毕业回馈—89C51之GPIO使用
STC89C51系列单片机共有如下几类GPIO口: (1)P0.0-P0.7: 对应DIP40封装的39-32号引脚:P0口既可以作为输入/输出GPIO口,也可以作为地址/数据复用总线使用. a)P0 ...
- WPF自定义ComboBox
<ControlTemplate x:Key="ComboBoxTextBox" TargetType="{x:Type TextBox}"> &l ...
- ASP.net 居中
<%@ Page Language="C#" AutoEventWireup="true" CodeFile="Default.aspx.cs& ...
- WP8中使用async/await扩展HttpWebRequest
前文讲到WP8中使用Async执行HTTP请求,用了微软提供的扩展.下面提供了一种方法,自己实现HttpWebRequest的扩展. 随后就可以使用 await HttpWebRequest.GetR ...