spark2.4+elasticsearch6.1.1搭建一个推荐系统
本博文详细记录了IBM在网上公布使用spark,elasticsearch搭建一个推荐系统的DEMO。demo中使用的elasticsearch版本号为5.4,数据集是在推荐中经常使用movies data。Demo中提供计算向量相似度es5.4插件在es6.1.1中无法使用,因此我们基于es6.1.1开发一个新的计算特征向量相似度的插件,插件具体详情见github,下面我们一步一步的实现这个推荐系统:
整体框架
整个框架图如下:
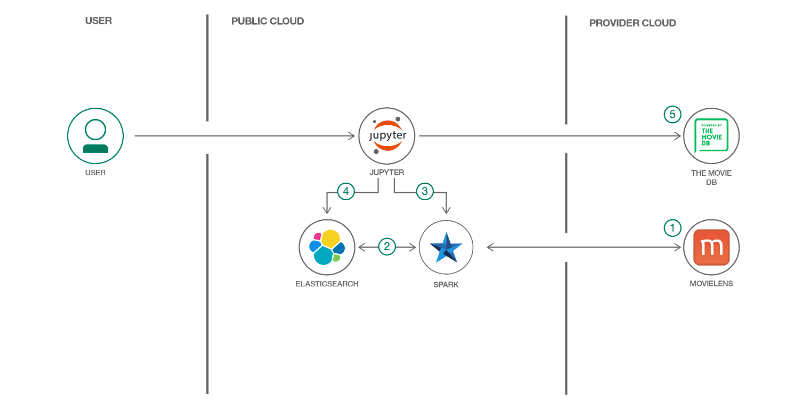
从图中我们可以看出具体的操作流程是:
- 利用spark.read.csv()读取ratings,users,movies数据集。
- 对数据集进行相关的处理
- 通过es-hadoop插件,将整理后的数据集保存到es
- 训练一个推荐模型-协同过滤模型
- 把训练好的模型保存到es中
- 搜索推荐-es查询和一个自定义矢量评分插件,计算用户与movies的最后评分
安装相关的组件
elasticsearch安装
spark安装
下载es-hadoop中间件
安装计算向量相似度的elasticsearch插件
运行
安装完es,spark,下载es-hadoop插件,以及es安装计算矢量评分的插件,然后通过如下命令启动:
PYSPARK_DRIVER_PYTHON="jupyter" PYSPARK_DRIVER_PYTHON_OPTS="notebook" /home/whb/Documents/pc/spark/spark-2.4.0/bin/pyspark --driver-memory 4g --driver-class-path /home/whb/Documents/pc/ELK/elasticsearch-hadoop-6.1.1/dist/elasticsearch-spark-20_2.11-6.1.1.jar
结果展示
from IPython.display import Image, HTML, display
def get_poster_url(id):
"""Fetch movie poster image URL from TMDb API given a tmdbId"""
IMAGE_URL = 'https://image.tmdb.org/t/p/w500'
try:
import tmdbsimple as tmdb
from tmdbsimple import APIKeyError
try:
movie = tmdb.Movies(id).info()
poster_url = IMAGE_URL + movie['poster_path'] if 'poster_path' in movie and movie['poster_path'] is not None else ""
return poster_url
except APIKeyError as ae:
return "KEY_ERR"
except Exception as me:
return "NA"
def fn_query(query_vec, q="*", cosine=False):
"""
Construct an Elasticsearch function score query.
The query takes as parameters:
- the field in the candidate document that contains the factor vector
- the query vector
- a flag indicating whether to use dot product or cosine similarity (normalized dot product) for scores
The query vector passed in will be the user factor vector (if generating recommended movies for a user)
or movie factor vector (if generating similar movies for a given movie)
"""
return {
"query": {
"function_score": {
"query" : {
"query_string": {
"query": q
}
},
"script_score": {
"script": {
"source": "whb_fvd",
"lang": "feature_vector_scoring_script",
"params": {
"field": "@model.factor",
"encoded_vector": query_vec,
"cosine" : True
}
}
},
"boost_mode": "replace"
}
}
}
def get_similar(the_id, q="*", num=10, index="movies", dt="movies"):
"""
Given a movie id, execute the recommendation function score query to find similar movies, ranked by cosine similarity
"""
response = es.get(index=index, doc_type=dt, id=the_id)
src = response['_source']
if '@model' in src and 'factor' in src['@model']:
raw_vec = src['@model']['factor']
# our script actually uses the list form for the query vector and handles conversion internally
q = fn_query(raw_vec, q=q, cosine=True)
results = es.search(index, dt, body=q)
hits = results['hits']['hits']
return src, hits[1:num+1]
def get_user_recs(the_id, q="*", num=10, index="users"):
"""
Given a user id, execute the recommendation function score query to find top movies, ranked by predicted rating
"""
response = es.get(index=index, doc_type="users", id=the_id)
src = response['_source']
if '@model' in src and 'factor' in src['@model']:
raw_vec = src['@model']['factor']
# our script actually uses the list form for the query vector and handles conversion internally
q = fn_query(raw_vec, q=q, cosine=False)
results = es.search(index, "movies", body=q)
hits = results['hits']['hits']
return src, hits[:num]
def get_movies_for_user(the_id, num=10, index="ratings"):
"""
Given a user id, get the movies rated by that user, from highest- to lowest-rated.
"""
response = es.search(index="ratings", doc_type="ratings", q="userId:%s" % the_id, size=num, sort=["rating:desc"])
hits = response['hits']['hits']
ids = [h['_source']['movieId'] for h in hits]
movies = es.mget(body={"ids": ids}, index="movies", doc_type="movies", _source_include=['tmdbId', 'title'])
movies_hits = movies['docs']
tmdbids = [h['_source'] for h in movies_hits]
return tmdbids
def display_user_recs(the_id, q="*", num=10, num_last=10, index="users"):
user, recs = get_user_recs(the_id, q, num, index)
user_movies = get_movies_for_user(the_id, num_last, index)
# check that posters can be displayed
first_movie = user_movies[0]
first_im_url = get_poster_url(first_movie['tmdbId'])
if first_im_url == "NA":
display(HTML("<i>Cannot import tmdbsimple. No movie posters will be displayed!</i>"))
if first_im_url == "KEY_ERR":
display(HTML("<i>Key error accessing TMDb API. Check your API key. No movie posters will be displayed!</i>"))
# display the movies that this user has rated highly
display(HTML("<h2>Get recommended movies for user id %s</h2>" % the_id))
display(HTML("<h4>The user has rated the following movies highly:</h4>"))
user_html = "<table border=0>"
i = 0
for movie in user_movies:
movie_im_url = get_poster_url(movie['tmdbId'])
movie_title = movie['title']
user_html += "<td><h5>%s</h5><img src=%s width=150></img></td>" % (movie_title, movie_im_url)
i += 1
if i % 5 == 0:
user_html += "</tr><tr>"
user_html += "</tr></table>"
display(HTML(user_html))
# now display the recommended movies for the user
display(HTML("<br>"))
display(HTML("<h2>Recommended movies:</h2>"))
rec_html = "<table border=0>"
i = 0
for rec in recs:
r_im_url = get_poster_url(rec['_source']['tmdbId'])
r_score = rec['_score']
r_title = rec['_source']['title']
rec_html += "<td><h5>%s</h5><img src=%s width=150></img></td><td><h5>%2.3f</h5></td>" % (r_title, r_im_url, r_score)
i += 1
if i % 5 == 0:
rec_html += "</tr><tr>"
rec_html += "</tr></table>"
display(HTML(rec_html))
def display_similar(the_id, q="*", num=10, index="movies", dt="movies"):
"""
Display query movie, together with similar movies and similarity scores, in a table
"""
movie, recs = get_similar(the_id, q, num, index, dt)
q_im_url = get_poster_url(movie['tmdbId'])
if q_im_url == "NA":
display(HTML("<i>Cannot import tmdbsimple. No movie posters will be displayed!</i>"))
if q_im_url == "KEY_ERR":
display(HTML("<i>Key error accessing TMDb API. Check your API key. No movie posters will be displayed!</i>"))
display(HTML("<h2>Get similar movies for:</h2>"))
display(HTML("<h4>%s</h4>" % movie['title']))
if q_im_url != "NA":
display(Image(q_im_url, width=200))
display(HTML("<br>"))
display(HTML("<h2>People who liked this movie also liked these:</h2>"))
sim_html = "<table border=0>"
i = 0
for rec in recs:
r_im_url = get_poster_url(rec['_source']['tmdbId'])
r_score = rec['_score']
r_title = rec['_source']['title']
sim_html += "<td><h5>%s</h5><img src=%s width=150></img></td><td><h5>%2.3f</h5></td>" % (r_title, r_im_url, r_score)
i += 1
if i % 5 == 0:
sim_html += "</tr><tr>"
sim_html += "</tr></table>"
display(HTML(sim_html))

参考博客
https://github.com/IBM/elasticsearch-spark-recommender
spark2.4+elasticsearch6.1.1搭建一个推荐系统的更多相关文章
- 通过ProGet搭建一个内部的Nuget服务器
.NET Core项目完全使用Nuget 管理组件之间的依赖关系,Nuget已经成为.NET 生态系统中不可或缺的一个组件,从项目角度,将项目中各种组件的引用统统交给NuGet,添加组件/删除组件/以 ...
- 基于hexo+github搭建一个独立博客
一直听说用hexo搭建一个拥有自己域名的博客是很酷炫的事情~,在这十一花上半个小时整个hexo博客岂不美哉. 使用Hexo吸引我的是,其简单优雅, 而且风格多变, 适合程序员搭建个人博客,而且支持多平 ...
- NodeJS 最快速搭建一个HttpServer
最快速搭建一个HttpServer 在目录里放一个index.html cd D:\Web\InternalWeb start http-server -i -p 8081
- 【日记】搭建一个node本地服务器
用node搭建一个本地http服务器.首先了解htpp服务器原理 HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端.HTTP协议采用了请求/响应模型 ...
- 从头开始搭建一个dubbo+zookeeper平台
本篇主要是来分享从头开始搭建一个dubbo+zookeeper平台的过程,其中会简要介绍下dubbo服务的作用. 首先,看下一般网站架构随着业务的发展,逻辑越来越复杂,数据量越来越大,交互越来越多之后 ...
- vuejsLearn---通过手脚架快速搭建一个vuejs项目
开始快速搭建一个项目 通过Webpack + vue-loader 手脚架 https://github.com/vuejs-templates/webpack 按照它的步骤一步一步来 $ npm i ...
- 利用git+hugo+markdown 搭建一个静态网站
利用git+hugo+markdown 搭建一个静态网站 一直想要有一个自己的文档管理系统: 可以很方便书写,而且相应的文档很容易被分享 很方便的存储.管理.历史记录 比较方面的浏览和查询 第一点用M ...
- 使用新浪云 Java 环境搭建一个简单的微信处理后台
前一段时间,写了一篇在新浪云上搭建自己的网站的教程,通过简单构建了一个 maven 的项目,展示部署的整个流程,具体的操作可以参看这里. 新浪云服务器除了可以搭建自己的网站以外,也非常的适合作为微信公 ...
- 超强教程:如何搭建一个 iOS 系统的视频直播 App?
现今,直播市场热火朝天,不少人喜欢在手机端安装各类直播 App,便于随时随地观看直播或者自己当主播.作为开发者来说,搭建一个稳定性强.延迟率低.可用性强的直播平台,需要考虑到部署视频源.搭建聊天室.优 ...
随机推荐
- 自己从0开始学习Unity的笔记 VII (C#中类继承练习)
好久都没有写了.今天做了类继承的练习,做了一个小队,进行简单的判定. namespace 兵团建立练习 { class ServantBasics { public string name; //pr ...
- Modular Arithmetic ( Arithmetic and Algebra) CGAL 4.13 -User Manual
1 Introduction Modular arithmetic is a fundamental tool in modern algebra systems. In conjunction wi ...
- Luogu1438 无聊的数列(单点查询)&&加强版(区间查询)
题目链接:戳我 线段树中差分和前缀和的应用 其实对于加上等差数列的操作我们可以分成这样三步-- update(1,1,n,l,l,k); if(r>l) update(1,1,n,l+1,r,d ...
- iOS出现 _OBJC_CLASS_$_ZSHomeServiceDataElementGroupLargeImage", referenced from:以及linker command failed with exit code 1 (use -v to see invocation)的错误分析
先说第一个问题 出现这样的错误我总结的原因有两个,我碰到过的: 1.文件重命名,在你创建文件的时候重名了 2.如果你是在一个类中又创建了一个或者多个类,那么你可能没有实现你写的类,也就是你只是@int ...
- Qt5学习笔记(控件)
上面的程序仅仅可以显示一个 大概 的界面,对其进行单击等操作,界面仅有一些简单的反应,对应的程序不能得知界面有什么改变(是否进行单击选择,文本框中是否有文字输入) 下面对程序进行完善. T05Cont ...
- 把 Reative Native 47 版本集成到已有的 Native iOS 工程中
一.搭建开发环境 http://reactnative.cn/docs/0.46/getting-started.html#content 二.创建一个模板 运行以下命令,创建一个最新版本的 reac ...
- [性能分析]linux文件描述符
1.什么是文件和文件描述符 Linux中文件可以分为4种:普通文件.目录文件.链接文件和设备文件.1.普通文件是用户日常使用最多的文件,包括文本文件.shell脚本.二进制的可执行和各种类型的数据.l ...
- power designer和uml应用
1.power designer和uml应用,它们可以帮助我们画图power designer还能在画图时帮助你完成代码.对于新手是很合适的一个画图工具, 2.这就是power designer 的示 ...
- sourceTree"重置提交"和"提交回滚"的区别
相信用过sourceTree的伙伴们都认识这两,但是不一定用过这两个功能,甚至是不能很好的把握它两的区别,根据自己最近亲身测试,总算是能小小的总结一下了 首先这儿假如,历史版本已经出现了1.2.3.4 ...
- Maven自动FTP远程部署
参照官网文档: https://maven.apache.org/plugins/maven-deploy-plugin/examples/deploy-ftp.html 1.在pom.xml中加入: ...