CentOS6安装各种大数据软件 第五章:Kafka集群的配置
相关文章链接
CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令
CentOS6安装各种大数据软件 第三章:Linux基础软件的安装
CentOS6安装各种大数据软件 第四章:Hadoop分布式集群配置
CentOS6安装各种大数据软件 第五章:Kafka集群的配置
CentOS6安装各种大数据软件 第六章:HBase分布式集群的配置
CentOS6安装各种大数据软件 第七章:Flume安装与配置
CentOS6安装各种大数据软件 第八章:Hive安装和配置
CentOS6安装各种大数据软件 第九章:Hue大数据可视化工具安装和配置
CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
1. Kafka集群的安装准备
1.1. 选择安装Kafka的版本
由于kafka是scala语言编写的,基于scala的多个版本,kafka发布了多个版本。
其中2.11是推荐版本。
1.2. 下载并解压安装包
解压文件,删除之前的的安装记录,并重命名
tar -zxvf kafka_2.11-1.0.0.tgz -C /export/servers/
cd /export/servers/
rm -rf /export/servers/kafka
rm -rf /export/logs/kafka/
rm -rf /export/data/kafka
mv kafka_2.11-1.0.0 kafka
2. 查看目录及修改配置文件
2.1. 查看目录

2.2. 修改配置文件
进入配置目录,查看server.properties文件
可以通过cat server.properties |grep -v "#"目录过滤掉带有#的注释行数
修改三个地方
1)Borker.id
2)数据存放的目录,注意目录如果不存在,需要新建下。
3)zookeeper的地址信息
# broker.id 标识了kafka集群中一个唯一broker。
broker.id=0 # 存放生产者生产的数据 数据一般以topic的方式存放
# 创建一个数据存放目录 /export/data/kafka --- mkdir -p /export/data/kafka
log.dirs=/export/data/kafka # 配置zk的信息
zookeeper.connect=zk01:2181,zk02:2181,zk03:2181
3. 分发配置文件及修改brokerid
将修改好的配置文件,分发到其他服务器上。
注意:如果在其他服务器上原先安装过kafka,需先删除以往的安装记录。
rm -rf /export/servers/kafka
rm -rf /export/logs/kafka/
rm -rf /export/data/kafka
分发安装包:
scp -r /export/servers/kafka/ node02:/export/servers/
scp -r /export/servers/kafka/ node03:/export/servers/
修改其他服务器上的broker.id

4. 启动Kafka集群
cd /export/servers/kafka/bin
./kafka-server-start.sh /export/servers/kafka/config/server.properties
5. 测试kafka集群
5.1. 创建一个topic
kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 1 --partitions 1 --topic my-kafka-topic
#执行结果:
Created topic "my-kafka-topic".
参数说明:
- zookeeper:参数是必传参数,用于配置 Kafka 集群与 ZooKeeper 连接地址。至少写一个。
- partitions:参数用于设置主题分区数,该配置为必传参数。
- replication-factor:参数用来设置主题副本数 ,该配置也是必传参数。
- topic:指定topic的名称。
5.2. 查看该kafka集群中的topic
kafka-topics.sh --list --zookeeper node01.ouyang.com:2181
__consumer_offsets
my-kafka-topic
5.3. 创建一个生产者
bin/kafka-console-producer.sh --broker-list node01.ouyang.com:9092,node02.ouyang.com:9092,node02.ouyang.com:9092 --topic test
5.4. 创建一个消费者
bin/kafka-console-consumer.sh --zookeeper node01.ouyang.com:2181,node02.ouyang.com:2181,node03.ouyang.com:2181 --topic test --from-beginning(老版本)
bin/kafka-console-consumer.sh --bootstrap-server node01.ouyang.com:9092,node02.ouyang.com:9092,node03.ouyang.com:9092 --topic test --from-beginning(新版本)
6. 查看Kafka集群(需借助外部工具kafka-manager)
Kafka Manager 由 yahoo 公司开发,该工具可以方便查看集群 主题分布情况,同时支持对 多个集群的管理、分区平衡以及创建主题等操作。
源码托管于github:https://github.com/yahoo/kafka-manager
6.1. 上传Kafka-manager安装包并且解压
tar -xvf kafka-manager-1.3.3.17.tar.gz -C /export/servers/
cd /export/servers/kafka-manager-1.3.3.17/conf
6.2. 修改配置文件
/kafka-manager/conf下的application.conf文件
#在配置文件中新增如下配置,http访问服务的端口
http.port=19000
#修改成自己的zk机器地址和端口
kafka-manager.zkhost1s="node01:2181"
#保存退出
6.3. 启动服务
cd /export/servers/kafka-manager-1.3.3.17/bin
./kafka-manager -Dconfig.file=../conf/application.conf
6.4. 制作一键启动脚本
步骤一:配置该文件夹的环境变量和一键启动文件的环境变量
export KAFKA_MANAGE_HOME= /export/servers/kafka-manager
export PATH=${KAFKA_MANAGE_HOME}/bin:$PATH
export PATH=${ZK_ONEKEY}/kafka-manager:$PATH
步骤二:编写一键启动脚本
vim startkafkamanager.sh
nohup kafka-manager -Dconfig.file=${KAFKA_MANAGE_HOME}/conf/application.conf >/dev/null 2>&1 &
chmod +x start-kafka-manager.sh
步骤三:重新加载环境变量,并一键启动
source /etc/profile
startkafkamanager.sh
步骤四:检查是否启动成功
打开浏览器,输入地址:http://node01:19000/,即可看到kafka-manage管理界面。
6.5. kafka-manager的使用
6.5.1. 添加Cluster
进入管理界面,是没有显示Cluster信息的,需要添加后才能操作。
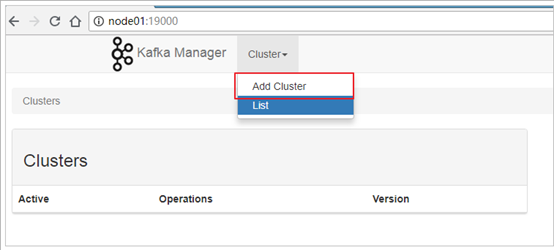
1. 添加 Cluster:
2. 输入Cluster Name、ZooKeeper信息、以及Kafka的版本信息(这里最高只能选择1.0.0)。
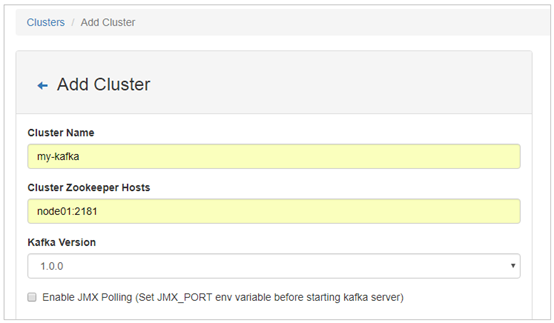
3. 点击Save按钮保存。

6.5.2. 在kafka-manager界面查看各主键的信息
1. 查看kafka的信息
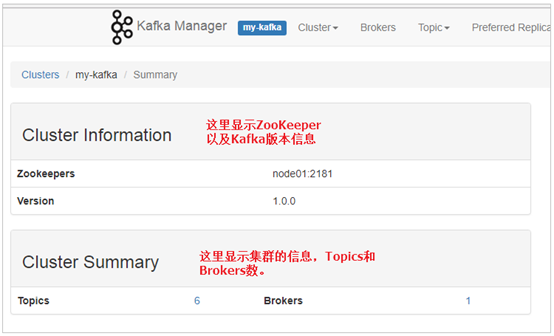
2. 查看Broker信息

3. 查看Topic列表

4. 查看单个topic信息以及操作
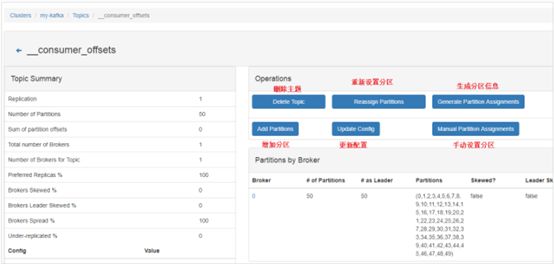
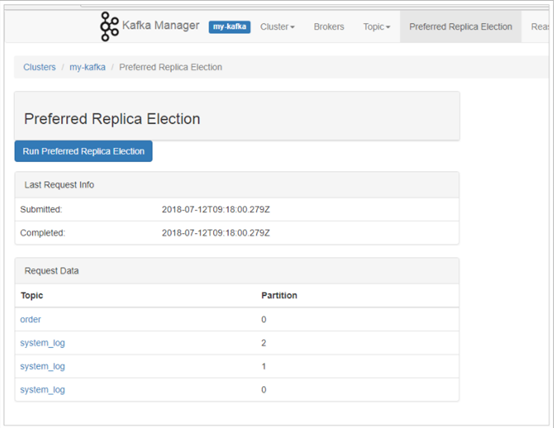
5. 优化副本选举
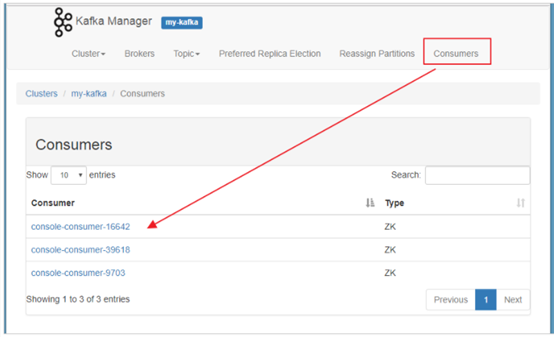
6. 查看消费者信息
CentOS6安装各种大数据软件 第五章:Kafka集群的配置的更多相关文章
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- CentOS6安装各种大数据软件 第四章:Hadoop分布式集群配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- CentOS6安装各种大数据软件 第七章:Flume安装与配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- CentOS6安装各种大数据软件 第六章:HBase分布式集群的配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- CentOS6安装各种大数据软件 第三章:Linux基础软件的安装
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- CentOS6安装各种大数据软件 第九章:Hue大数据可视化工具安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- CentOS6安装各种大数据软件 第八章:Hive安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- CentOS6安装各种大数据软件 第一章:各个软件版本介绍
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
随机推荐
- Difference between scipy.fftpack and numpy.fft
scipy.fftpack 和 numpy.fft 的区别 When applying scipy.fftpack.rfft and numpy.fft.rfft I get the followin ...
- zTree 学习笔记之(一)
zTree 学习笔记之(一) 简介 zTree 是一个依靠 jQuery 实现的多功能 “树插件”.优异的性能.灵活的配置.多种功能的组合是 zTree 最大优点. 到底有哪些具体的优点,可以参见官网 ...
- spring cloud config配置
参考: http://www.ityouknow.com/springcloud/2017/05/22/springcloud-config-git.html http://www.ityouknow ...
- 常用sql commands以及mysql问题解决日志
mysql workbench常用命令快捷键 ctrl+T ->创建新的sql query tab ctrl+shift+enter->执行当前的sql命令 https://dev.mys ...
- 剑指offer相关问题
1. 变态跳台阶 Fib(n) = Fib(n-1)+Fib(n-2)+Fib(n-3)+..........+Fib(n-n) =Fib(0)+Fib(1)+Fib(2)+..... ...
- 海量数据处理面试题(1) 找出两文件种包含的相同的url
问题:给定a.b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a.b文件共同的url? 分析:50亿个url,每个url64字节,就是320G,显然是无法一次读入内存 ...
- python面向对象编程(2)—— 实例属性,类属性,类方法,静态方法
1 实例属性和类属性 类和实例都是名字空间,类是类属性的名字空间,实例则是实例属性的名字空间. 类属性可通过类或实例来访问.只有通过类名访问时,才能修改类属性的值. 例外的一种情况是,当类属性是一个 ...
- Java自学之路(新手一定要看)
Java自学之路(新手一定要看) 转自尚学堂 JAVA自学之路 一:学会选择 为了就业,不少同学参加各种各样的培训. 决心做软件的,大多数人选的是java,或是.net,也有一些选择了手机.嵌入式.游 ...
- Kali Nethunter初体验
1.官网环境要求:n5 n7 n10 android 4.4 2.实验设备: N7 android 4.4.4 N7 android 4.4.3 N5 nadroid 4.4.2 3.开发者模式+us ...
- java万年历
import java.util.Scanner; public class perpetualCalendar { public static void main(String[] args) { ...