Python之机器学习K-means算法实现
一、前言:
今天在宿舍弄了一个下午的代码,总算还好,把这个东西算是熟悉了,还不算是力竭,只算是知道了怎么回事。今天就给大家分享一下我的代码。代码可以运行,运行的Python环境是Python3.6以上的版本,需要用到Python中的numpy、matplotlib包,这一部分代码将K-means算法进行了实现。当然这还不是最优的代码,只是在功能上已经实现了该算法的功能。
二、代码部分:
import numpy as np
import random
from matplotlib import pyplot as plt
class K_means(object):
def __init__(self,X,k,maxIter):
self.X = X#数据集 是一个矩阵
self.k = k#所需要分的类的数
self.maxIter = maxIter#所允许的程序执行的最大的循环次数
def K_means(self):
row,col = self.X.shape#得到矩阵的行和列
dataset = np.zeros((row,col + 1))#新生成一个矩阵,行数不变,列数加1 新的列用来存放分组号别 矩阵中的初始值为0
dataset[:,:-1] = self.X
print("begin:dataset:\n" + repr(dataset))
# centerpoints = dataset[0:2,:]#取数据集中的前两个点为中心点
centerpoints = dataset[np.random.randint(row,size=k)]#采用随机函数任意取两个点
centerpoints[:,-1] = range(1,self.k+1)
oldCenterpoints = None #用来在循环中存放上一次循环的中心点
iterations = 1 #当前循环次数
while not self.stop(oldCenterpoints,centerpoints,iterations):
print("corrent iteration:" + str(iterations))
print("centerpoint:\n" + repr(centerpoints))
print("dataset:\n" + repr(dataset))
oldCenterpoints = np.copy(centerpoints)#将本次循环的点拷贝一份 记录下来
iterations += 1
self.updateLabel(dataset,centerpoints)#将本次聚类好的结果存放到矩阵中
centerpoints = self.getCenterpoint(dataset)#得到新的中心点,再次进行循环计算
np.save("kmeans.npy", dataset)
return dataset
def stop(self,oldCenterpoints,centerpoints,iterations):
if iterations > self.maxIter:
return True
return np.array_equal(oldCenterpoints,centerpoints)#返回两个点多对比结果
def updateLabel(self,dataset,centerpoints):
row,col = self.X.shape
for i in range(0,row):
dataset[i,-1] = self.getLabel(dataset[i,:-1],centerpoints)
#[i,j] 表示i行j列
#返回当前行和中心点之间的距离最短的中心点的类别,即当前点和那个中心点最近就被划分到哪一部分
def getLabel(self,datasetRow,centerpoints):
label = centerpoints[0, -1]#先取第一行的标签值赋值给该变量
minDist = np.linalg.norm(datasetRow-centerpoints[0, :-1])#计算两点之间的直线距离
for i in range(1, centerpoints.shape[0]):
dist = np.linalg.norm(datasetRow-centerpoints[i, :-1])
if dist < minDist:#当该变距离中心点的距离小于预设的最小值,那么将最小值进行更新
minDist = dist
label = centerpoints[i,-1]
print("minDist:" + str(minDist) + ",belong to label:" + str(label))
return label
def getCenterpoint(self,dataset):
newCenterpoint = np.zeros((self.k,dataset.shape[1]))#生成一个新矩阵,行是k值,列是数据集的列的值
for i in range(1,self.k+1):
oneCluster = dataset[dataset[:,-1] == i,:-1]#取出上一次分好的类别的所有属于同一类的点,对其求平均值
newCenterpoint[i-1, :-1] = np.mean(oneCluster,axis=0)#axis=1表示对行求平均值,=0表示对列求平均值
newCenterpoint[i-1, -1] = i#重新对新的中心点进行分类,初始类
return newCenterpoint
#将散点图画出来
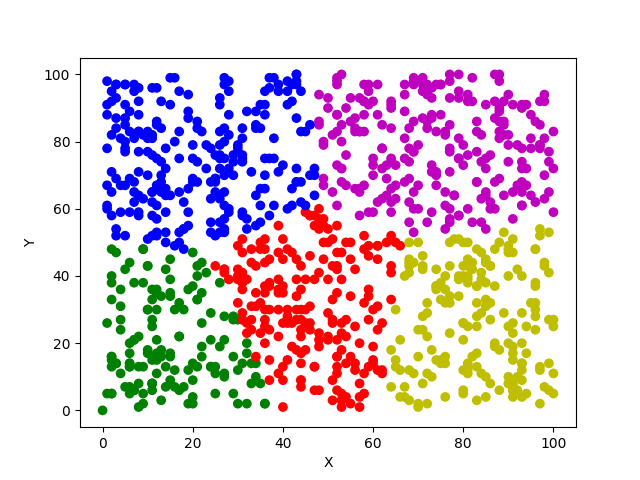
def drawScatter(self):
plt.xlabel("X")
plt.ylabel("Y")
dataset = self.K_means()
x = dataset[:, 0] # 第一列的数值为横坐标
y = dataset[:, 1] # 第二列的数值为纵坐标
c = dataset[:, -1] # 最后一列的数值用来区分颜色
color = ["none", "b", "r", "g", "y","m","c","k"]
c_color = []
for i in c:
c_color.append(color[int(i)])#给每一种类别的点都涂上不同颜色,便于观察
plt.scatter(x=x, y=y, c=c_color, marker="o")#其中x表示横坐标的值,y表示纵坐标的
# 值,c表示该点显示出来的颜色,marker表示该点多形状,‘o’表示圆形
plt.show()
if __name__ == '__main__':
'''
关于numpy中的存储矩阵的方法,这里不多介绍,可以自行百度。这里使用的是
np.save("filename.npy",X)其中X是需要存储的矩阵
读取的方法就是代码中的那一行代码,可以不用修改任何参数,导出来的矩阵和保存之前的格式一模一样,很方便。
'''
# X = np.load("testSet-kmeans.npy")#从文件中读取数据
#自动生成数据
X = np.zeros((1,2))
for i in range(1000):
X = np.row_stack((X,np.array([random.randint(1,100),random.randint(1,100)])))
k = 5 #表示待分组的组数
kmeans = K_means(X=X,k=k,maxIter=100)
kmeans.drawScatter()
三、显示效果:
Python之机器学习K-means算法实现的更多相关文章
- 秒懂机器学习---k临近算法(KNN)
秒懂机器学习---k临近算法(KNN) 一.总结 一句话总结: 弄懂原理,然后要运行实例,然后多解决问题,然后想出优化,分析优缺点,才算真的懂 1.KNN(K-Nearest Neighbor)算法的 ...
- [机器学习] k近邻算法
算是机器学习中最简单的算法了,顾名思义是看k个近邻的类别,测试点的类别判断为k近邻里某一类点最多的,少数服从多数,要点摘录: 1. 关键参数:k值 && 距离计算方式 &&am ...
- 用Python从零开始实现K近邻算法
KNN算法的定义: KNN通过测量不同样本的特征值之间的距离进行分类.它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别.K通 ...
- Python3入门机器学习 - k近邻算法
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代 ...
- 机器学习-K最近邻算法
一.介绍 二.编程 练习一(K最近邻算法在单分类任务的应用): import numpy as np #导入科学计算包import matplotlib.pyplot as plt #导入画图工具fr ...
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- 机器学习(1)——K近邻算法
KNN的函数写法 import numpy as np from math import sqrt from collections import Counter def KNN_classify(k ...
- 1.K近邻算法
(一)K近邻算法基础 K近邻(KNN)算法优点 思想极度简单 应用数学知识少(近乎为0) 效果好 可以解释机器学习算法使用过程中的很多细节问题 更完整的刻画机器学习应用的流程 图解K近邻算法 上图是以 ...
- 机器学习 Python实践-K近邻算法
机器学习K近邻算法的实现主要是参考<机器学习实战>这本书. 一.K近邻(KNN)算法 K最近邻(k-Nearest Neighbour,KNN)分类算法,理解的思路是:如果一个样本在特征空 ...
- python 机器学习(二)分类算法-k近邻算法
一.什么是K近邻算法? 定义: 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. 来源: KNN算法最早是由Cover和Hart提 ...
随机推荐
- 命名空间p方式的属性注入
---------------------siwuxie095 命名空间 p 方式的属性注入 命名空间 p 方式的属性注入是 Spring 2.x 版本后提供的方式 1.编写一个普通类 Book.ja ...
- [leetcode]134. Gas Station加油站
There are N gas stations along a circular route, where the amount of gas at station i is gas[i]. Y ...
- Qt Pro file
Qt keys qmake Manual Building Common Project Types #~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ ...
- Sprint boot notes
1. spring.io 官网 2. http://javainuse.com/spring/sprboot spring boot学习资源 3. spring boot websocketss视频 ...
- ubuntu 12.04安装jdk 8
转载:http://www.itnose.net/detail/6196130.html Ubuntu12.4安装jdk1.8 1.要安装的jdk,我把它拷在了共享文件夹里面. (用优盘拷也可以 ...
- pyspider示例代码一:利用phantomjs解决js问题
本系列文章主要记录和讲解pyspider的示例代码,希望能抛砖引玉.pyspider示例代码官方网站是http://demo.pyspider.org/.上面的示例代码太多,无从下手.因此本人找出一下 ...
- 共享keychain数据
[共享keychain数据] 当往keychain中插入数据时,默认的 kSecAttrAccessGroup 就是App自身的BundleID. [官方文档] You can add a keych ...
- UVa 10118 Free Candies (记忆化搜索+哈希)
题意:有4堆糖果,每堆有n(最多40)个,有一个篮子,最多装5个糖果,我们每次只能从某一堆糖果里拿出一个糖果,如果篮子里有两个相同的糖果, 那么就可以把这两个(一对)糖果放进自己的口袋里,问最多能拿走 ...
- 博客和Github简单练习
我的第一篇博客 1.首先是自我介绍 姓名:孙弘毅 班级:网工142 学号:1413042050 兴趣:游戏,看书 至于我写了多少代码我也不清楚,反正不多 2.Github 注册流程 (1)百度Git ...
- css选择器与DOM'匹配的关系
一道面试题 css 选择器匹配时,只考察是否包含有对应的class,而与class的顺序无关 而css的定义是后面的覆盖前面的定义 原理:http://www.w3.org/html/ig/zh/wi ...