python-IE浏览器调用
IE浏览器驱动添加
selenium官网有提供下载http://code.google.com/p/selenium/downloads/list
这里我用的是IEDriverServer_Win32_2.43.0.zip,下载后解压,把IEDriverServer.exe放在python安装目录,与python.exe在同一目录下,即可调用.
IE浏览器的调用

#coding=utf-8
from selenium import webdriver driver=webdriver.Ie()
url='http://www.baidu.com'
driver.get(url)
driver.close()
说明:
1、【#coding=utf-8】为了防止乱码问题,以便在程序中添加中文注释,把编码统一为UTF-8,注意=两遍不要留空格,否则不起作用,另外【#_*_coding:utf-8_*_】的写法也可以达到相同的作用
2、【from selenium import webdriver】该步骤是导入selenium的webdriver包,只有导入selenium包,我们才能使用webdriver API进行自动化脚本的开发
3、【driver=webdriver.Ie()】这里将控制webdriver的Ie赋值给driver,通过driver获得浏览器操作对象,后就可以启动浏览器、打开网址、操作对应的页面元素了。
若IEDriverServer.exe没有放在python安装目录下,而自定义的目录,如:IE目录下,则直接使用上述代码是无法调用成功的,提示:"IEDriver executable needs to be available in the path. "因为在默认的路径下,无法找到IEDriver,所以需要为webdriver指定指定IEDriver的路径,如下:
#coding=utf-8
from selenium import webdriver
import os url='http://www.baidu.com'
iedriver ='C:\IEDriverServer.exe' #iedriver路径
os.environ["webdriver.ie.driver"] = iedriver #设置环境变量
driver = webdriver.Ie(iedriver)
driver.get(url)
driver.close()
说明:
1、 os.environ["webdriver.ie.driver"]是设置IEDriver的环境变量,设置为实际的IEDriver地址即可。
2、 若为chrom浏览器,则参数为:os.environ["webdriver.chrome.driver"]
关于https网站调用失败处理
上面介绍了,调用IE来打开对应的网页问题,但是在实际测试中,有些网站是采用https协议的,这时候IE浏览器会弹出如下窗口,一般手动选择后,才可进入登录界面,而在webdriver调用浏览器后,无法继续操作,那么该如何解决呢?

方法一:代码增加配置
首先,我们可以可以查看该网页的源码,分析下代码,可以看到下面部分信息:
<h4 id="continueToSite">
<img src="red_shield.png" ID="ImgOverride" border="0" alt="不推荐图标" class="actionIcon">
<A href='' ID="overridelink" NAME="overridelink" >继续浏览此网站(不推荐)。 </A>
</h4>
述标记部分的,则是上图标记的地方,一般我们点击该图标后即可进入登录窗口,下面代码中通过调用javascript来操作浏览器的提示框,来跳过该提示即可:
#coding=utf-8
from selenium import webdriver driver=webdriver.Ie()
firsturl='https://172.172.110.8/Terminal/logon.do'
driver.get(firsturl)
driver.get("javascript:document.getElementById('overridelink').click();")#解决IE提示问题
driver.close()
方法二:浏览器配置
方法二则是通过配置浏览器的方法,解决证书问题,方法如下:
1、点击【继续浏览此网页】后进入登录窗口,此时地址栏后面会出现【证书错误】提示
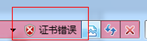
2、点击证书错误——查看证书,提示证书无效,则是因为证书不被信息,需要安装证书
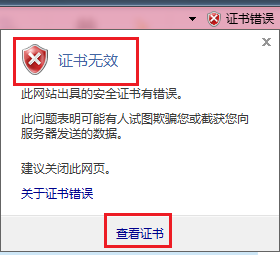
3、弹出证书界面,选择安装证书

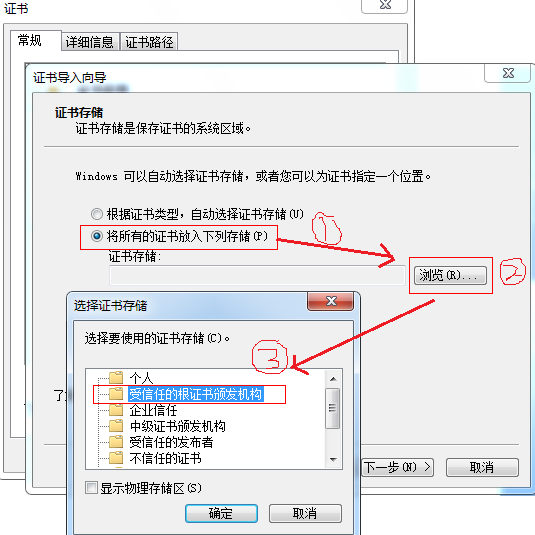
4、按向导操作,注意在下列步骤中需要选择证书位置
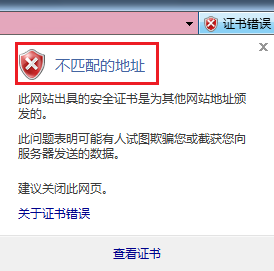
5、配置完成后,此时依然是无法登陆的,点击继续浏览后,弹出的错误提示为:不匹配的地址,如下,还需要继续配置
6、Internnet选项——高级下,去除下图中标记项的勾,然后保存

7、重新打开地址,此时仍然会弹出提示,选择继续浏览后,会发现上方的地址栏变为一个小锁,如右图,说明已经配置OK,后续在打开该地址就不会弹出错误选项了。

8、若还是无法登陆,可以在Internet选项—安全中:设置安全等级为低等级,并在高级选项下,将下属五项全部勾选后重启浏览器即可

关于调用IE浏览器的错误处理
运行过程中如果出现错误:WebDriverException: Message: u'Unexpected error launching Internet Explorer. Protected Mode settings are not the same for all zones. Enable Protected Mode must be set to the same value (enabled or disabled) for all zones.
解决方法
更改IE的internet选项->安全,将Internet/本地Internet/受信任的站定/受限制的站点中的启用保护模式全部去掉勾,或者全部勾上
参考资料
[1] 证书错误 导航已阻止 无法跳转 最终解决,
http://jingyan.baidu.com/article/cbf0e5008af1392eaa2893cf.html
[2] webdriver+python 对三大浏览器的支持,
http://blog.163.com/yang_jianli/blog/static/1619900062014102833427464/
python-IE浏览器调用的更多相关文章
- python+selenium浏览器调用(chrome、ie、firefox)
代码: #coding=utf-8 from selenium import webdriver driver=webdriver.Chrome() #调用chrome浏览器 driver.get(' ...
- Selenium+Python浏览器调用:Firefox
如何查看python selenium的API python -m pydoc -p 4567 说明: python -m pydoc表示打开pydoc模块,pydoc是查看python文档的首选工 ...
- python+selenium环境配置及浏览器调用
最近在学习python自动化,从项目角度和技术基础角度出发,我选择了python+selenium+appium的模式开始我的自动化测试之旅: 一.python安装 二.python IDE使用简介 ...
- Python对Selenium调用浏览器进行封装包括启用无头浏览器,及对应的浏览器配置文件
""" 获取浏览器 打开本地浏览器 打开远程浏览器 关闭浏览器 打开网址 最大化 最小化 标题 url 刷新 Python对Selenium封装浏览器调用 ------b ...
- python发布及调用基于SOAP的webservice
现如今面向服务(SOA)的架构设计已经成为主流,把公用的服务打包成一个个webservice供各方调用是一种非常常用的做法,而应用最广泛的则是基于SOAP协议和wsdl的webservice.本文讲解 ...
- python 打开浏览器的方法 Python打开默认浏览器
一.python 打开浏览器的方法: . startfile方法(打开指定浏览器) import os os.startfile("C:\Program Files\internet exp ...
- 【317】python 指定浏览器打开网页 / 文件
一.python 打开浏览器的方法: 1. startfile方法(打开指定浏览器) import os os.startfile("C:\Program Files\internet ex ...
- 如何用python“优雅的”调用有道翻译?
前言 其实在以前就盯上有道翻译了的,但是由于时间问题一直没有研究(我的骚操作还在后面,记得关注),本文主要讲解如何用python调用有道翻译,讲解这个爬虫与有道翻译的js“斗争”的过程! 当然,本文仅 ...
- 转:python提取浏览器Cookie
在用浏览器进行网页访问时,会向网页所在的服务器发送http协议的GET或者POST等请求,在请求中除了指定所请求的方法以及URI之外,后面还跟随着一段Request Header.Request He ...
- 第14.7节 Python模拟浏览器访问实现http报文体压缩传输
一. 引言 在<第14.6节 Python模拟浏览器访问网页的实现代码>介绍了使用urllib包的request模块访问网页的方法.但上节特别说明http报文头Accept-Encodin ...
随机推荐
- 剑指Offer的学习笔记(C#篇)-- 整数中1出现的次数(从1到n整数中1出现的次数)
题目描述 求出1~13的整数中1出现的次数,并算出100~1300的整数中1出现的次数?为此他特别数了一下1~13中包含1的数字有1.10.11.12.13因此共出现6次,但是对于后面问题他就没辙了. ...
- 8.Python初窥门径(文件操作)
Python (文件操作) 一.文件操作方式 打开文件 open 操作文件 read or write 关闭文件 close 二.打开文件的方式(第一种) 语法 : f=open("文件&q ...
- 洛谷P2971 牛的政治Cow Politics
题目描述 Farmer John's cows are living on \(N (2 \leq N \leq 200,000)\)different pastures conveniently n ...
- [Java]LinkedHashMap实现原理
1.概述 在理解了#7 介绍的HashMap后,我们来学习LinkedHashMap的工作原理及实现.首先还是类似的,我们写一个简单的LinkedHashMap的程序: LinkedHashMap&l ...
- [TCP/IP]OSI七层模型和TCP/IP四层模型
OSI參考模型 在過去的電腦網路上,由於資料通訊系統涉及複雜的軟硬體,可是又沒有統一的標準,導致通訊軟體不僅龐大複雜,而且不易測式.修改或分享.為此,ISO(國際標準組織)發展出一套OSI參考模型(O ...
- 题解 UVA11354 【Bond】
并查集+按秩合并 传送门 大意:给出一张n个点m条边的无向图, 每条边有一个权值,有q个询问, 每次给出两个点s.t,找一条路, 使得路径上的边的最大权值最小. 我们可以发现,跑最小生成树会跑挂, 那 ...
- byte取高4位,低4位,byte转int
byte abyte =-1; System.out.println(abyte); System.out.println(Integer.toBinaryString(abyte)); //取高四位 ...
- 038 Count and Say 数数并说
数数并说序列是一个整数序列,第二项起每一项的值为对前一项的计数,其前五项如下:1. 12. 113. 214. 12115. 1112211 被读作 " ...
- 067 Add Binary 二进制求和
给定两个二进制字符串,返回他们的和(用二进制表示).案例:a = "11"b = "1"返回 "100" .详见:https://leetc ...
- Python踩坑之旅其二裸用os.system的原罪
目录 1.1 踩坑案例 1.2 填坑解法 1.3 坑位分析 1.4.1 技术关键字 1.5 填坑总结 2. 前坑回顾 2.1 Linux中, 子进程拷贝父进程哪些信息 2.2 Agent常驻进程选择& ...