Hadoop概念学习系列之Hadoop 生态系统
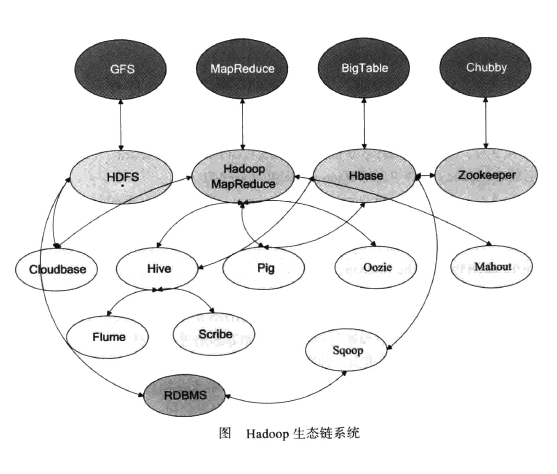
当下 Hadoop 已经成长为一个庞大的生态体系,只要和海量数据相关的领域,都有 Hadoop 的身影。下图是一个 Hadoop 生态系统的图谱,详细列举了在 Hadoop 这个生态系统中出现的各种数据工具。

这一切,都起源自 Web 数据爆炸时代的来临。Hadoop 生态系统的功能以及对应的开源工具说明如下。
MapReduce
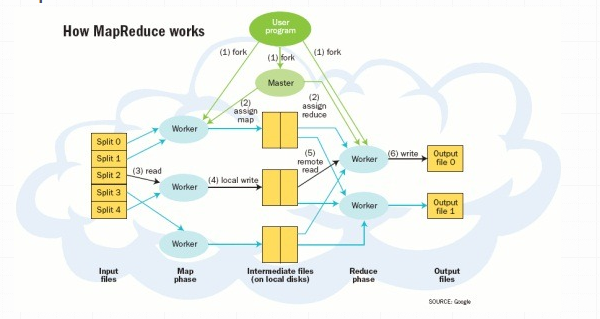
fork是计算机程序设计中的分叉函数。
Google的网络搜索引擎在得益于算法发挥作用的同时,MapReduce在后台发挥了极大的作用。MapReduce框架成为当今大数据处理背后的最具影响力的“发动机”。
MapReduce的重要创新是当处理一个大数据集查询时会将其任务分解并在运行的多个节点中处理。当数据量很大时就无法在一台服务器上解决问题,此时分布式计算优势就体现出来。将这种技术与Linux服务器结合可获得性价比极高的替代大规模计算阵列的方法。Yahoo在2006年看到了Hadoop未来的潜力,并邀请Hadoop创始人Doug Cutting着手发展Hadoop技术,在2008年Hadoop已经形成一定的规模。Hadoop项目再从初期发展的成熟的过程中同时吸纳了一些其他的组件,以便进一步提高自身的易用性和功能。
HDFS

对于分布式计算,每个服务器必须具备对数据的访问能力,这就是HDFS(Hadoop Distributed File System)所起到的作用。 HDFS与MapReduce的结合是强大的。在处理大数据的过程中,当Hadoop集群中的服务器出现错误时,整个计算过程并不会终止。同时HFDS可保障在整个集群中发生故障错误时的数据冗余。当计算完成时将结果写入HFDS的一个节点之中。HDFS对存储的数据格式并无苛刻的要求,数据可以是非结构化或其它类别。相反关系数据库在存储数据之前需要将数据结构化并定义架构。 开发人员编写代码责任是使数据有意义。Hadoop MapReduce级的编程利用Java APIs,并可手动加载数据文件到HDFS之中。
Pig和Hive

对于开发人员,直接使用Java APIs可能是乏味或容易出错的,同时也限制了Java程序员在Hadoop上编程的运用灵活性。于是Hadoop提供了两个解决方案:Pig和Hive,使得Hadoop编程变得更加容易。
Pig:是一种编程语言,它简化了Hadoop常见的工作任务。Pig可加载数据、表达转换数据以及存储最终结果。Pig内置的操作使得半结构化数据变得有意义(如日志文件)。同时Pig可扩展使用Java中添加的自定义数据类型并支持数据转换。
Hive:在Hadoop中扮演数据仓库的角色。Hive添加数据的结构在HDFS(hive superimposes structure on data in HDFS),并允许使用类似于SQL语法进行数据查询。与Pig一样,Hive的核心功能是可扩展的。
Pig和Hive总是令人困惑的。Hive更适合于数据仓库的任务,Hive主要用于静态的结构以及需要经常分析的工作。Hive与SQL相似促使其成为Hadoop与其他BI工具结合的理想交集。Pig赋予开发人员在大数据集领域更多的灵活性,并允许开发简洁的脚本用于转换数据流以便嵌入到较大的应用程序。Pig相比Hive相对轻量,它主要的优势是相比于直接使用Hadoop Java APIs可大幅削减代码量。正因为如此,Pig仍然吸引了大量的软件开发人员。
HBase、Sqoop以及Flume

Hadoop核心还是一套批处理系统,数据加载进HDFS、处理然后检索。对于计算这或多或少有些倒退,但通常互动和随机存取数据是有必要的。HBase作为面向列的数据库运行在HDFS之上。HBase以Google BigTable为蓝本。项目的目标就是快速在主机内数十亿行数据中定位所需的数据并访问它。HBase利用MapReduce来处理内部的海量数据。同时Hive和Pig都可以与HBase组合使用,Hive和Pig还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变得非常简单。
但为了授权随机存储数据,HBase也做出了一些限制:例如Hive与HBase的性能比原生在HDFS之上的Hive要慢4-5倍。同时HBase大约可存储PB级的数据,与之相比HDFS的容量限制达到30PB。HBase不适合用于ad-hoc分析,HBase更适合整合大数据作为大型应用的一部分,包括日志、计算以及时间序列数据。
Sqoop和Flume可改进数据的互操作性和其余部分。Sqoop功能主要是从关系数据库导入数据到Hadoop,并可直接导入到HFDS或Hive。而Flume设计旨在直接将流数据或日志数据导入HDFS。
ZooKeeper和Oozie
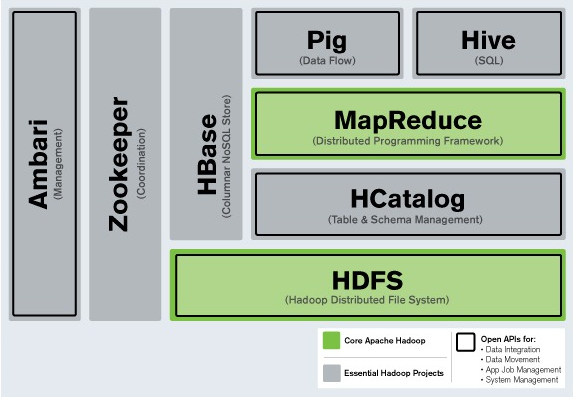
随着越来越多的项目加入Hadoop大家庭并成为集群系统运作的一部分,大数据处理系统需要负责协调工作的的成员。随着计算节点的增多,集群成员需要彼此同步并了解去哪里访问服务和如何配置,ZooKeeper正是为此而生的。
而在Hadoop执行的任务有时候需要将多个Map/Reduce作业连接到一起,它们之间或许彼此依赖。Oozie组件提供管理工作流程和依赖的功能,并无需开发人员编写定制的解决方案。
Ambari是最新加入Hadoop的项目,Ambari项目旨在将监控和管理等核心功能加入Hadoop项目。Ambari可帮助系统管理员部署和配置Hadoop,升级集群以及监控服务。还可通过API集成与其他的系统管理工具。
Mahout
各类组织需求的不同导致相关的数据形形色色,对这些数据的分析也需要多样化的方法。Mahout提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括集群、分类、推荐过滤、频繁子项挖掘。
通常情况下,Hadoop应用于分布式环境。就像之前Linux的状况一样,厂商集成和测试Apache Hadoop生态系统的组件,并添加自己的工具和管理功能。
HDFS一一 Hadoop分布式文件系统,GFS的Java开源实现,运行于大型商用机器集群,可实现分布式存储。
MapReduce一一 一种并行计算框架,Google MapReduce模型的Java开源实现,基于其写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理T级别及以上的数据集。
Zookeepe一一 一分布式协调系统,Google Chubby的Java开源实现,是高可用的和可靠的分布式协同(coordination)系统,提供分布式锁之类的基本服务,用于构建分布式应用。
Hbase一一 基于Hadoop的分布式数据库,Google BigTable的开源实现,是一个有序、稀疏、多维度的映射表,有良好的伸缩性和高可用性,用来将数据存储到各个计算节点上。
Hive一一 是为提供简单的数据操作而设计的分布式数据仓库,它提供了简单的类似SQL语法的HiveQL语言进行数据查询。
Cloudbase一一 基于Hadoop的数据仓库,支持标准的SQL语法进行数据查询。
Pig一一 大数据流处理系统。建立于Hadoop之上为并行计算环境提供了一套数据工作流语言和执行框架。
Mahout一一 基于HadoopMapReduce的大规模数据挖掘与机器学习算法库。
Oozie一一 MapReduce工作流管理系统。
Sqoop—一 数据转移系统,是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库中的数据导入Hadoop的HDFS中、也可以将HDFS的数据导入关系型数据库中。
Flume一一 一个可用的、可靠的、分布式的海量日志采集、聚合和传输系统。
Scribe一一 Facebook开源的日志收集聚合框架系统。
Hadoop概念学习系列之Hadoop 生态系统的更多相关文章
- Hadoop概念学习系列之Hadoop新手学习指导之入门需知(二十)
不多说,直接上干货! 零基础学习hadoop,没有想象的那么困难,也没有想象的那么容易.从一开始什么都不懂,到能够搭建集群,开发.整个过程,只要有Linux基础,虚拟机化和java基础,其实hadoo ...
- Hadoop概念学习系列之Hadoop 生态系统(十二)
当下 Hadoop 已经成长为一个庞大的生态体系,只要和海量数据相关的领域,都有 Hadoop 的身影.下图是一个 Hadoop 生态系统的图谱,详细列举了在 Hadoop 这个生态系统中出现的各种数 ...
- Hadoop概念学习系列之hadoop生态系统闲谈(二十五)
分层次讲解 最底层平台 ------->hdfs yarn mapreduce spark 应用层-------->hbase hive pig sparkSQL nu ...
- Hadoop概念学习系列之Hadoop HA进一步深入(二十八)
对于Hadoop里的HA,有hdfs HA和resourcemanger HA之分. 1.hdfs HA 为什么引入federation? 因为,这样能达到允许在一个集群里,有多对namenode.通 ...
- Hadoop概念学习系列之Hadoop集群动态增加新节点或删除已有某节点及复制策略导向 (四十三)
不多说,直接上干货! hadoop-2.6.0动态添加新节点 https://blog.csdn.net/baidu_25820069/article/details/52225216 Hadoop集 ...
- Hadoop概念学习系列之Hadoop、Spark学习路线(很值得推荐)(十八)
不多说,直接上干货! 说在前面的话 此笔,对于仅对于Hadoop和Spark初中学者.高手请忽略! 1 Java基础: 视频方面: 推荐<毕向东JAVA基础视频教程>.学 ...
- Hadoop概念学习系列之Hadoop、Spark学习路线(很值得推荐)
说在前面的话 此笔,对于仅对于Hadoop和Spark初中学者.高手请忽略! 1 Java基础: 视频方面: 推荐<毕向东JAVA基础视频教程>.学习hadoop不需要过 ...
- Hadoop概念学习系列之Hadoop、Spark学习路线
1 Java基础: 视频方面: 推荐<毕向东JAVA基础视频教程>.学习hadoop不需要过度的深入,java学习到javase,在Java虚拟机的内存管理.以及多线程. ...
- Hadoop概念学习系列之hadoop、spark常备查询网址(二十九)
http://archive.apache.org/dist
随机推荐
- javascript fetch 跨域请求时 session失效问题
javascript 使用fetch进行跨域请求时默认是不带cookie的,所以会造成 session失效. fetch(url, { method: 'POST', credentials: 'in ...
- appium(10)-iOS predictate
iOS predictate It is worth looking at ’-ios uiautomation’ search strategy with Predicates. UIAutomat ...
- Java+Jsoup实现网页内容抓取
不知不觉毕业快一年了,工作逐渐趋于平淡,从一个对编程了解得很少甚至完全一窍不通的小小菜,终于成为了一枚小菜,总而言之,算是入了IT这一行.这大半年马马虎虎做了三个项目,有安卓项目,有Java Web项 ...
- CORS 理解(不要那么多术语)
摘要 谈到跨域,不论前端还是后端,多少有点谈虎色变,面试中也常会问到这些问题,浏览器和服务器端到底怎么做才能跨域,他们都做了什么? 同源 vs 跨域 同源,字面意义是相同的源头,即同一个web服务器( ...
- 10.19-10.20 test
2016 10.19-10.20 两天 题目by mzx Day1: T1:loverfinding 题解:hash #include<iostream> #include<cst ...
- fiddler_test
fiddler学习第二天 啦啦啦 拉拉呀
- Add GNOME to a CentOS Minimal Install
by Jeff Hunter, Sr. Database Administrator Contents Introduction CentOS 6 About the Author Introduct ...
- MSTAR GUI
1.架构 WIN32 SDK ACT->CTL->API->GE/GOP ACT: Customized logic parts CTL: Behavior widgets API: ...
- ubuntu 使用命令行清空回收站
sudo rm -rf ~/.local/share/Trash/*
- bzoj2718
二分图匹配 首先有个定理:最长反链=最小链覆盖 最小链覆盖可以重复经过点 所以我们不能直接建图 那么我们用floyd判断是否相连 然后建图就行了 #include<bits/stdc++.h&g ...