python模块之序列化
序列化
什么是序列化
序列化是将字典、列表等数据类型转化成一个字符串的过程
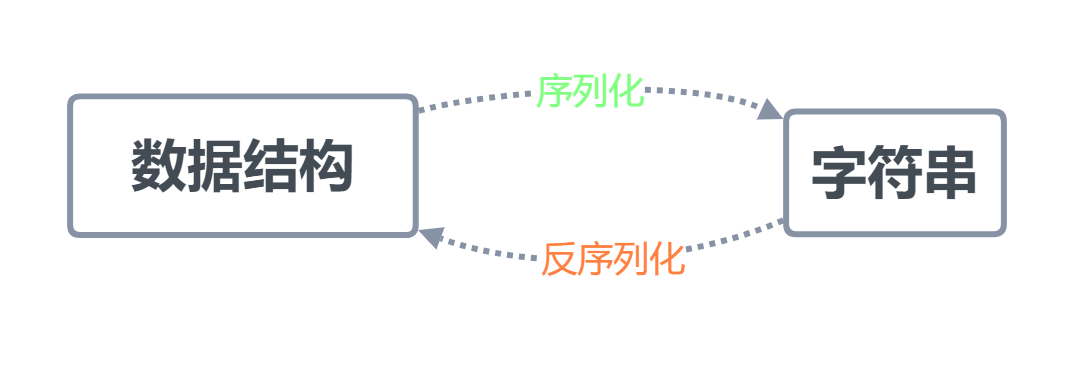
序列化的目的
1. 以某种存储形式使自定义对象持久化(存储)
2. 将对象从一个地方传递到另一个我地方(传输)
3. 使程序更具维护性
json模块
json是很多语言通用的一种数据标准,json可以转化的数据类型包括:str int bool dict list(tuple) None
json模块有四种方法:dumps, loads, dump, load
dumps和loads
处理列表
import json
lst = [1, 2, "a", "哈哈"]
s = json.dumps(lst, ensure_ascii=False) # 包含非ascii字符时要加上ensure_ascii=False
print(s[0]) # [ 可以像字符串一样取值
print(s[1]) #
print(s[1:8]) # 也可以切片 1, 2, " 注意列表元素之间有空格
print(s, type(s)) # [1, 2, "a", "哈哈"] <class 'str'>
l1 = json.loads(s)
print(l1, type(l1)) # [1, 2, 'a', '哈哈'] <class 'list'>
dumps也可以处理嵌套的数据类型,注意json会自动把字典的key变成字符串格式,元组转化之后会变成列表
import json
dic = {"": {1: "青", 2: "梅", 3: "竹", 4: "马"}, "": {1: "两", 2: "小", 3: "无", 4: "猜"}}
s = json.dumps(dic, ensure_ascii=False)
# print(s)
dic1 = json.loads(s)
print(dic1) # {'1': {'1': '青', '2': '梅', '3': '竹', '4': '马'}, '2': {'1': '两', '2': '小', '3': '无', '4': '猜'}}
dump和load
dump和load用于将数据写入文件和读出
import json
dic = {1: "你", 2: "我"}
with open("序列化.json", encoding="utf-8", mode="w") as f1:
json.dump(dic, f1, ensure_ascii=False) with open("序列化.json", encoding="utf-8", mode="r") as f2:
ret = json.load(f2) print(ret) # {'1': '你', '2': '我'}
一次只能写入一个数据,超过一个读取就会出错
import json
dic1 = {1: "你", 2: "我"}
dic2 = {1: "我", 2: "你"}
a = None
with open("序列化.json", encoding="utf-8", mode="w") as f1:
json.dump(dic1, f1, ensure_ascii=False)
json.dump(dic2, f1, ensure_ascii=False) with open("序列化.json", encoding="utf-8", mode="r") as f2:
ret1 = json.load(f2) # 报错json.decoder.JSONDecodeError: Extra data: line 1 column 21 (char 20)
ret2 = json.load(f2)
怎么同时写入多个数据呢,循环使用dumps,先用dumps把数据转化成json字符串,再用文件句柄写入
import json
dic1 = {1: "你", 2: "我"}
dic2 = {1: "我", 2: "你"}
a = None # 写进文件会变成null
b = 100
c = (1, 2, 3)
d = True
with open("序列化.json", encoding="utf-8", mode="w") as f1:
f1.write(json.dumps(dic1, ensure_ascii=False)) # {"1": "你", "2": "我"}
f1.write("\n")
f1.write(json.dumps(dic2, ensure_ascii=False)) # {"1": "我", "2": "你"}
f1.write("\n")
f1.write(json.dumps(a)) # null
f1.write("\n")
f1.write(json.dumps(b)) #
f1.write("\n")
f1.write(json.dumps(c)) # [1, 2, 3] # 元组反序列化之后是列表
f1.write("\n")
f1.write(json.dumps(d)) # true
pickle模块
json模块只能将常用的数据类型进行序列化,pickle模块是python独有的,可以将所有的python的数据类型(包括对象)序列化
import pickle
dic1 = {1: "你", 2: "我"}
p1 = pickle.dumps(dic1)
print(p1) # b'\x80\x03}q\x00(K\x01X\x03\x00\x00\x00\xe4\xbd\xa0q\x01K\x02X\x03\x00\x00\x00\xe6\x88\x91q\x02u.'
pickle是将数据类型转化成bytes类型存入文件中,用load也可以读出来
with open("p1.pickle", mode="rb") as f2: # 注意这里是rb模式
re = pickle.load(f2)
print(re) # {1: '你', 2: '我'}
与json不同,pickle可以一次写入和读取多个数据
import pickle
dic1 = {1: "你", 2: "我"}
dic2 = {1: "我", 2: "你"}
a = None # 写进文件会变成null
b = 100
c = (1, 2, 3)
d = True
with open("p1.pickle", mode="wb") as f1:
pickle.dump(dic1, f1)
pickle.dump(dic2, f1)
pickle.dump(a, f1)
pickle.dump(b, f1)
pickle.dump(c, f1) with open("p1.pickle", mode="rb") as f2:
ret1 = pickle.load(f2)
ret2 = pickle.load(f2)
ret3 = pickle.load(f2)
ret4 = pickle.load(f2)
ret5 = pickle.load(f2) # pickle反序列化出来还是元组
print(ret1) # {1: '你', 2: '我'}
print(ret2) # {1: '我', 2: '你'}
print(ret3) # None
print(ret4) #
print(ret5) # (1, 2, 3)
pickle也可以转化python对象
import pickle
def func():
print(111) with open("p2.pickle", mode="wb") as f1: # 模式必须是wb
pickle.dump(func, f1) with open("p2.pickle", mode="rb") as f2:
re = pickle.load(f2)
print(re) # <function func at 0x000001D1FF081E18>
json与pickele比较
1. json是通用的,别的语言也可以识别,pickle只能python识别
2. json只能转化str int bool dict list(tuple) None,pickle可以转化所有Python数据类型
shelve模块
shelve也是python提供给我们的序列化工具,比pickle用起来更简单一些。shelve只提供给我们一个open方法,是用key来访问的,使用起来和字典类似
import shelve
f = shelve.open("shelve_file") # 写入了三个文件bak dat dir
f["key"] = {"int": 10, "float": 3.4}
f.close() f = shelve.open("shelve_file")
print(f["key"]) # {'int': 10, 'float': 3.4}
f.close()
存储到shelve的文件一般不让修改,如果要修改可以加一个参数writeback=True
不加参数
f1 = shelve.open("shelve_file")
f1["key"]["int"] = 20
f1.close()
f2 = shelve.open("shelve_file")
print(f2["key"]) # {'int': 10, 'float': 3.4} 并没有修改
加上writeback=True
f3 = shelve.open("shelve_file", writeback=True)
f3["key"]["int"] = 20
f3.close()
f4 = shelve.open("shelve_file")
print(f4["key"]) # {'int': 20, 'float': 3.4}
f4.close()
总结
1. 序列化就是把其他数据类型转化成字符串的过程
2. 常用的序列化模块是json,可以不同语言间通用,使用方法有dumps, loads 和dump, load
3. pickle是python独有的,可以转化所有Python数据类型
4. shelve像字典一样可以用key来访问,一般不让修改
python模块之序列化的更多相关文章
- Python模块02/序列化/os模块/sys模块/haslib加密/collections
Python模块02/序列化/os模块/sys模块/haslib加密/collections 内容大纲 1.序列化 2.os模块 3.sys模块 4.haslib加密 5.collections 1. ...
- Python模块(二)(序列化)
1. namedtuple 命名元组->类似创建了一个类 from collections import namedtuple p = namedtuple("Point", ...
- python模块之序列化模块
序列化 """ 序列--字符串 序列化--其他数据类型转化为字符串数据类型 反序列化--字符串转化为其他数据类型 """ json模块 &q ...
- python-学习笔记之-Day5 双层装饰器 字符串格式化 python模块 递归 生成器 迭代器 序列化
1.双层装饰器 #!/usr/bin/env python # -*- coding: utf-8 -*- # author:zml LOGIN_INFO = False IS_ADMIN = Fal ...
- Python库:序列化和反序列化模块pickle介绍
1 前言 在“通过简单示例来理解什么是机器学习”这篇文章里提到了pickle库的使用,本文来做进一步的阐述. 通过简单示例来理解什么是机器学习 pickle是python语言的一个标准模块,安装pyt ...
- Python模块之time、random、os、sys、序列化、re
Time模块 和时间有关系的我们就要用到时间模块.在使用模块之前,应该首先导入这个模块. #常用方法 1.time.sleep(secs) (线程)推迟指定的时间运行.单位为秒. 2.time.tim ...
- [python](windows)分布式进程问题:pickle模块不能序列化lambda函数
运行错误:_pickle.PicklingError: Can't pickle <function <lambda> at 0x000002BAAEF12F28>: attr ...
- Python开发之序列化与反序列化:pickle、json模块使用详解
1 引言 在日常开发中,所有的对象都是存储在内存当中,尤其是像python这样的坚持一切接对象的高级程序设计语言,一旦关机,在写在内存中的数据都将不复存在.另一方面,存储在内存够中的对象由于编程语言. ...
- python之路----模块与序列化模块
认识模块 什么是模块 什么是模块? 常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. 但其实import加载的模块分为四个通用类别: 1 使用pyt ...
随机推荐
- ATR102E Stop. Otherwise... [容斥]
第一道容斥 \(ans[i] = \sum_{j = 0}^{min(cnt, n / 2)} (-1)^j \tbinom{cnt}{j} \tbinom{n - 2*j + k - 1}{k - ...
- 利用SSH上传、下载(使用sz与rz命令)
安装yum -y install lrzsz 用法sz用法:从服务器发送出去相当于下载一个文件sz filename 下载多个文件sz filename1 filename2rz用法:从外面接收回来, ...
- 【比赛】NOIP2018 赛道修建
最小值最大,二分长度 然后判断赛道大于等于这个长度最多可以有多少条 可以贪心,对于一个点和它的一些儿子,儿子与儿子之间尽量多配(排序后一大一小),剩下的选个最长的留给自己的父亲就好了 具体实现可以用一 ...
- bit、Byte、bps、Bps、pps、Gbps的单位详细说明及换算
1. bit 电脑记忆体中最小的单位,在二进位电脑系统中,每1bit 可以代表0 或 1 的数位讯号. 2. Byte 字节单位,一般表示存储介质大小的单位,一个B(常用大写的B来表示Byte)可代表 ...
- 【JVM】查看JVM加载的类及类加载器的方法
查看JVM加载了哪些类 java -verbose[:class|gc|jni] 在输出设备上显示虚拟机运行信息. java -verbose:class 在程序运行的时候有多少类被加载!你可以用ve ...
- Vue组件之间数据交互与通信
Vue 的组件作用域都是孤立的,不允许在子组件的模板内直接引用父组件的数据.必须使用特定的方法才能实现组件之间的数据传递. 一.父组件向子组件传递数据 在 Vue 中,可以使用 props 向子组件传 ...
- [ZJOI2005]九数码游戏(BFS+hash)
Solution 这题的话直接上BFS就可以了,因为要输出方案,所以我们要开一个pre数组记录前驱,最后输出就可以了. 对于状态的记录,一般都用哈希来存,但因为这道题比较特殊,它是一个排列,所以我们可 ...
- POJ1061 青蛙的约会(扩展欧几里得)
题目链接:http://poj.org/problem?id=1061 青蛙的约会 Time Limit: 1000MS Memory Limit: 10000K Total Submission ...
- Win10 安装 Linux子系统 Ubuntu18.04 / Kali Linux 的体验
汇总系列:https://www.cnblogs.com/dunitian/p/4822808.html#linux 几年前就看到新闻,今天周末,突发奇想,家里电脑安装下子系统不就不用安装开发的那些环 ...
- 动态代理之: com.sun.proxy.$Proxy0 cannot be cast to 问题
转: 动态代理之: com.sun.proxy.$Proxy0 cannot be cast to 问题 2018年05月13日 00:40:32 codingCoge 阅读数:1211 版权声明 ...