OpenCV入门之获取验证码的单个字符(二)
在文章 OpenCV入门之获取验证码的单个字符(字符切割)中,介绍了一类验证码的处理方法,该验证码如下:
该验证码的特点是字母之间的间隔较大,很容易就能提取出其中的单个字符。接下来,笔者将会介绍如何在另一种验证码中提取单个字符的方法。
测试的验证码来源于某个账号注册的网站,如下:

笔者一共收集了346张验证码。我们可以看到,这些验证码的特点是:噪声较大,有些验证码之间的字母黏连在一起,这样的话,想要提取单个字符的难度会加大。
首先,我们按照文章 OpenCV入门之获取验证码的单个字符(字符切割)的处理方式来提取单个字符,看看效果,完整的Python
代码如下:

import os
import uuid
import cv2
def split_picture(imagepath):
# 以灰度模式读取图片
gray = cv2.imread(imagepath, 0)
# 将图片的边缘变为白色
height, width = gray.shape
for i in range(width):
gray[0, i] = 255
gray[height-1, i] = 255
for j in range(height):
gray[j, 0] = 255
gray[j, width-1] = 255
# 中值滤波
blur = cv2.medianBlur(gray, 3) #模板大小3*3
# 二值化
ret,thresh1 = cv2.threshold(blur, 200, 255, cv2.THRESH_BINARY)
# 提取单个字符
image, contours, hierarchy = cv2.findContours(thresh1, 2, 2)
for cnt in contours:
# 最小的外接矩形
x, y, w, h = cv2.boundingRect(cnt)
if x != 0 and y != 0 and w*h >= 100:
print((x,y,w,h))
# 显示图片
cv2.imwrite('E://chars/%s.jpg'%(uuid.uuid1()), thresh1[y:y+h, x:x+w])
def main():
dir = "E://verifycode"
for file in os.listdir(dir):
imagepath = dir+'/'+file
split_picture(imagepath)
main()
得到的单个字符的效果如下:
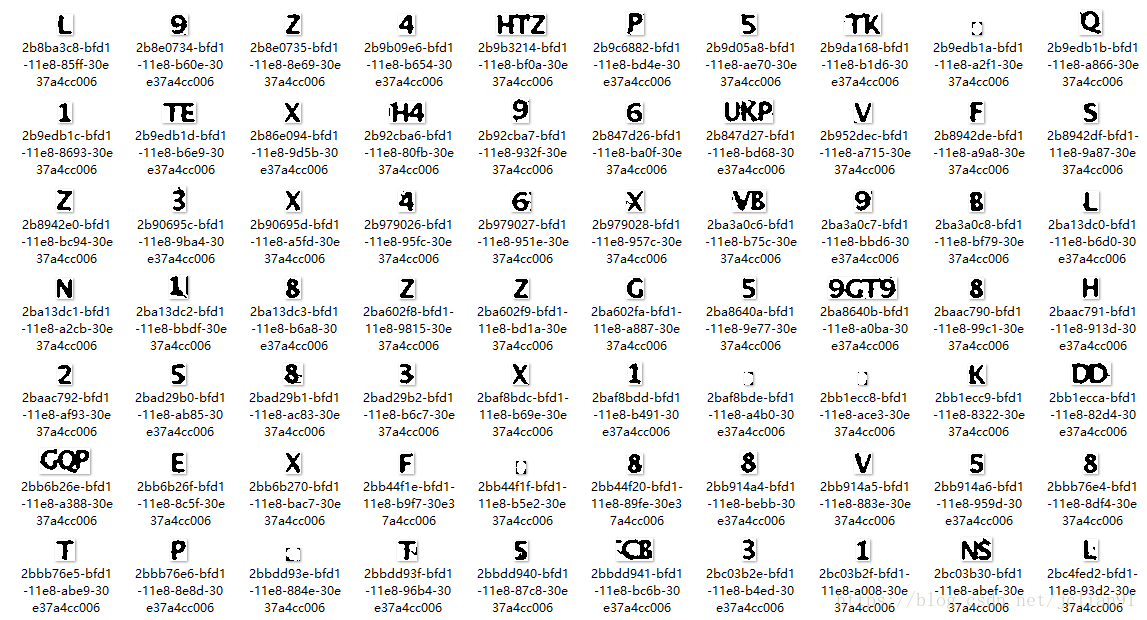
可以看到,虽然我们也能得到单个的字符,但是也产生了很多噪声图片以及黏连在一起的字符图片(以下简称黏连图片)。因此,下一步的工作是如何处理噪声图片和黏连图片。
首先我们介绍如何去掉噪声图片。观察以上的噪声图片,即中间有大片空白,角落里有部分黑色的图片,如下:

笔者选择的处理方式如下:在该图片的四个角落的像素点取值,一共是四个值,如果黑色像素的点大于等于3个,则被认为是噪声图片。处理的Python函数如下:
def remove_edge_picture(imagepath):
image = cv2.imread(imagepath, 0)
height, width = image.shape
corner_list = [image[0,0] < 127,
image[height-1, 0] < 127,
image[0, width-1]<127,
image[ height-1, width-1] < 127
]
if sum(corner_list) >= 3:
os.remove(imagepath)
接着是黏连图片的处理,所谓黏连图片,指的是提取字符的图片中含有2个及以上字符的图片,如下:
对于黏连图片,我们很容易想到的处理方式就是均分图片,图片中含有几个字符,就将图片均分成几等分。那么,怎样才能知道图片中所含字符的数量呢?笔者暂时没有完美的处理方法,能想到的就是根据图片的宽度来决定字符的个数。根据观察,4个字符的图片宽度往往大于等于64,3个字符的图片宽度往往大于等于48,两个字符的图片往往大于等于26,因此,就把这个作为图片中含有字符数量的标准。处理黏连图片的Python代码如下:

def resplit_with_parts(imagepath, parts):
image = cv2.imread(imagepath, 0)
height, width = image.shape
# 将图片重新分裂成parts部分
step = width//parts # 步长
start = 0 # 起始位置
for _ in range(parts):
cv2.imwrite('E://chars/%s.jpg'%uuid.uuid1(), image[:, start:start+step])
start += step
os.remove(imagepath)
def resplit(imagepath):
image = cv2.imread(imagepath, 0)
height, width = image.shape
if width >= 64:
resplit_with_parts(imagepath, 4)
elif width >= 48:
resplit_with_parts(imagepath, 3)
elif width >= 26:
resplit_with_parts(imagepath, 2)
好了,有了以上处理噪声图片和黏连图片的方法,我们来试试处理后的效果,显示的图片如下:
一共是346张验证码,每个验证码4个字符,一共是1384张图片。按照这样处理方法,得到1381张图片,当然,存在极少的噪声图片(1~2张)和有些为切分的图片,如上图中用红线圈出的部分。总的来说,得到的有效单个字符的图片为1371张图片,提取的效率为99%,这无疑是极好的,达到了笔者的预期效果。
下面给出以上处理的完整的Python代码:

import os
import cv2
import uuid
def remove_edge_picture(imagepath):
image = cv2.imread(imagepath, 0)
height, width = image.shape
corner_list = [image[0,0] < 127,
image[height-1, 0] < 127,
image[0, width-1]<127,
image[ height-1, width-1] < 127
]
if sum(corner_list) >= 3:
os.remove(imagepath)
def resplit_with_parts(imagepath, parts):
image = cv2.imread(imagepath, 0)
height, width = image.shape
# 将图片重新分裂成parts部分
step = width//parts # 步长
start = 0 # 起始位置
for _ in range(parts):
cv2.imwrite('E://chars/%s.jpg'%uuid.uuid1(), image[:, start:start+step])
start += step
os.remove(imagepath)
def resplit(imagepath):
image = cv2.imread(imagepath, 0)
height, width = image.shape
if width >= 64:
resplit_with_parts(imagepath, 4)
elif width >= 48:
resplit_with_parts(imagepath, 3)
elif width >= 26:
resplit_with_parts(imagepath, 2)
def main():
dir = 'E://chars'
for file in os.listdir(dir):
remove_edge_picture(imagepath=dir+'/'+file)
for file in os.listdir(dir):
resplit(imagepath=dir+'/'+file)
main()
今日中秋,祝大家中秋节快乐~
注意:本人现已开通两个微信公众号: 轻松学会Python爬虫(微信号为:easy_web_scrape), 欢迎大家关注哦~~
OpenCV入门之获取验证码的单个字符(二)的更多相关文章
- OpenCV入门之获取验证码的单个字符(字符切割)
介绍 在我们日常上网注册账号以及制作网络爬虫时,经常会遇到奇奇怪怪的验证码,有些容易,有些连人眼都无法辨识.于是,大牛们想到了用深度学习的方法来破解验证码,对于一般的验证码往往能出奇制胜,取得不俗 ...
- iOS 获取字符串中的单个字符
要取到单个字符,就要知道字符串的编码方式,这样才能够定位每个字符在内存中的位置.但是,iOS的字符串编码是不固定的,因此,需要设置一个统一的编码格式,将所有其他格式的字符串都转化为统一的格式,然后就可 ...
- C#获取单个字符的拼音声母
public class ConvertToPinYing { /// <summary> /// 汉字转拼音缩写 /// < ...
- OpenCV入门学习笔记
OpenCV入门学习笔记 参照OpenCV中文论坛相关文档(http://www.opencv.org.cn/) 一.简介 OpenCV(Open Source Computer Vision),开源 ...
- [验证码识别技术] 字符型验证码终结者-CNN+BLSTM+CTC
验证码识别(少样本,高精度)项目地址:https://github.com/kerlomz/captcha_trainer 1. 前言 本项目适用于Python3.6,GPU>=NVIDIA G ...
- C++学习45 流成员函数put输出单个字符 cin输入流详解 get()函数读入一个字符
在程序中一般用cout和插入运算符“<<”实现输出,cout流在内存中有相应的缓冲区.有时用户还有特殊的输出要求,例如只输出一个字符.ostream类除了提供上面介绍过的用于格式控制的成员 ...
- opencv ,亮度调整【【OpenCV入门教程之六】 创建Trackbar & 图像对比度、亮度值调整
http://blog.csdn.net/poem_qianmo/article/details/21479533 [OpenCV入门教程之六] 创建Trackbar & 图像对比度.亮度值调 ...
- php随机获取验证码
<?php $yzm = ""; for($i=0;$i<5;$i++) { $a = rand(0,9); //0-9随机数 $yzm.= $a; } echo jo ...
- android发送短信验证码并自动获取验证码填充文本框
android注册发送短信验证码并自动获取短信,截取数字验证码填充文本框. 一.接入短信平台 首先需要选择短信平台接入,这里使用的是榛子云短信平台(http://smsow.zhenzikj.com) ...
随机推荐
- eclipse新建的项目,也添加到tomcat上了,地址栏访问的时候就是访问不到。。。怎么办
其实是可以访问的,目前我遇到以下两种可能出现这种现象的原因: 1.这个项目在你写的过程中改了名字,这样你访问改后的名字是不行的,需要在下图,也就是server服务器的server.xml文件中修改访问 ...
- Django 执行单独脚本及SyntaxError缩进报错解决
有时候会碰到这样的场景,对于一些业务升级,我需要把数据库数据做些处理,同时又想以 Django 项目的环境变量执行脚本,这个时候使用 python 脚本是再适合不过的手段了. 注意:在pycharm里 ...
- react native (1) 新建页面并跳转
新建页面 1.新建文件 import React from 'react'; import { Text } from 'react-native'; export default class tod ...
- 《OpenCV3编程入门》学习笔记
把第一章的例程看完了,除了基本的操作函数,还了解了跟视频操作有关的函数,发现在自己的中心偏检测中,不仅可以处理图片,还可以对视频进行处理. 问题解决方案 1.0x7547d36f 处有未经处理的异常: ...
- FPGA中分数分频器的实现代码
module clkFracDiv( output reg clkout, input rstn, input refclk, :] fenzi, :] fenmu ); :] rstn_syn; : ...
- 【腾讯Bugly干货分享】Android内存优化总结&实践
本文来自于腾讯Bugly公众号(weixinBugly),未经作者同意,请勿转载,原文地址:https://mp.weixin.qq.com/s/2MsEAR9pQfMr1Sfs7cPdWQ 导语 智 ...
- Senparc.Weixin.TenPay 正式发布
微信支付刚出来的时候,和公众号的绑定关系很深(甚至旧版本使用的就是公众号的appId),随着微信生态的逐步丰富,微信支付越来越成为一个独立的平台,同时服务于公众号.小程序.开放平台.企业号/企业微信等 ...
- 手把手教你Chrome浏览器安装Postman(含下载云盘链接)【转载】
转载自:http://www.ljwit.com/archives/php/278.html 说明: Postman不多介绍,是一款功能强大的网页调试与发送网页HTTP请求的Chrome插件.本文主要 ...
- jenkins在windows服务器上执行含git push命令的脚本权限不足的解决方法
错误摘要 默认情况下执行脚本是没问题的,但是脚本中含有git push命令就无法执行了 用jenkins部署hexo博客时候遇到的,执行hexo d -g一直阻塞至Build was aborted, ...
- OpenProject 分类专栏说明
OpenProject 顾名思义 开源项目. 一.为何创建 OpenProject 专栏 主要是因为GitHub上收藏的项目越来越多,想在GitHub上查找一些收藏的内容,开始变得比较费时,为了简化搜 ...