机器学习算法总结(五)——聚类算法(K-means,密度聚类,层次聚类)
本文介绍无监督学习算法,无监督学习是在样本的标签未知的情况下,根据样本的内在规律对样本进行分类,常见的无监督学习就是聚类算法。
在监督学习中我们常根据模型的误差来衡量模型的好坏,通过优化损失函数来改善模型。而在聚类算法中是怎么来度量模型的好坏呢?聚类算法模型的性能度量大致有两类:
1)将模型结果与某个参考模型(或者称为外部指标)进行对比,私认为这种方法用的比较少,因为需要人为的去设定外部参考模型。
2)另一种是直接使用模型的内部属性,比如样本之间的距离(闵可夫斯基距离)来作为评判指标,这类称为内部指标。
1、K-means聚类
K-means算法是聚类算法的一种,实现起来比较简单,效果也不错。K-means的思想很简单,对于给定的样本集,根据样本之间距离的大小将样本划分为K个簇(在这里K是需要预先设定好的),在进行划分簇时要尽量让簇内的样本之间的距离很小,让簇与簇之间的距离尽量大。
在给定的数据集D的条件下,将数据集划分为K类,则K-means的数学模型可以表示为:
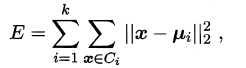
其中$C_i$为第$i$类的集合,$\mu_i$为第$i$类的簇心(该簇内所有样本的均值,也称为均值向量)
K-means算法的具体流程如下(数据来源 机器学习-周志华版):

在这里主要核心有两步:一是计算样本到各簇心的距离,将样本划分到距离最小的那一簇中;二是在将所有的样本都划分完之后,计算各簇心的样本均值向量,然后将该均值向量设为新的簇心。而迭代的终止条件是当前均值向量和簇心是基本一致。
对于K-means有两个可以优化的地方:
1)在初始化时,随机选择K个样本作为初始的簇心,倘若此时随机的结果不好,比如两个随机的簇心挨得很近,这可能会导致模型收敛的速度减慢,常见的解决方式是先随机选取一个样本作为簇心,计算样本到该簇心的距离,随机选择下一个簇心,此时选取时会倾向于选择和与最近簇心之间距离较大的样本作为簇心,直到选择完K个簇心。
2)每次迭代时都要计算所有样本和所有簇心之间的距离,若此时样本很大,或者簇心很多时,计算代价是非常大的,因此每次随机抽取一小批样本来更新当前的簇心(通过无放回随机采样)。除了这种方式之外还有一种K-means方法(elkan K-means)也可以减少距离的计算。
K-means算法的优点:
1)原理简单,实现容易,且收敛速度也较快。
2)聚类效果较好,而且可解释性较强。
3)参数很少,需要调的参数只有簇的个数K。
K-means算法的缺点:
1)K值的选取比较难
2)对于非凸数据集收敛比较难
3)如果隐含类别的数据不平衡,则聚类效果不佳,比如隐含类型的方差不同,方差较大的类中的样本可能会被聚类到其他类别中,在聚类时原则上没啥影响,但是聚类或者说无监督学习大多时候都是一些预训练,聚类后的数据可能之后会被用于其他的分类回归模型中
4)对噪声和异常点比较敏感
5)迭代得到的结果只是局部最优
2、密度聚类与DBSCAN
密度聚类算法假定聚类结构能通过样本分布的紧密程度来确定。同一类别的样本,他们之间是紧密相连的,通过样本密度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇以获得最终的聚类结果。因此密度聚类也是不需要提前设置簇数K的值的。
DBSCAN是基于一组领域来描述样本集的紧密程度的,在描述DBSCAN算法之前我们先引入几个概念:
给定数据集D{x1, x2, ......xn}
1)ϵ- 邻域:对于xi ,其邻域中包含了所有与xi 的距离小于ϵ 的样本
2)核心对象:对于任一样本xj∈D,如果其ϵ-邻域对应的N ϵ (xj)至少包含MinPts个样本,即如果|N ϵ (xj)| ≥ MinPts,则xj是核心对象
3)密度直达:如果xi 位于xj 的ϵ-邻域中,且xj 是核心对象,则称xi 由xj 密度直达。注意反之不一定成立,即此时不能说xj 由xi 密度直达, 除非且xi 也是核心对象
4)密度可达:对于xi和xj,如果存在样本样本序列p1, p2,..., pT,满足p1=xi,pT=xj,且pt+1由pt 密度直达,则称xj 由xi 密度可达。也就是说,密度可达满足传递性。此时序列中的传递样本p1,p2,...,pT−1均为核心对象,因为只有核心对象才能使其他样本密度直达。注意密度可达也不满足对称性,这个可以由密度直达的不对称性得出
5)密度相连:对于xi和xj,如果存在核心对象样本xk,使xi和xj均由xk密度可达,则称xi和xj密度相连。注意密度相连关系是满足对称性的
如下图所示,对于给定的MinPts=5,红点都是核心对象,黑色的样本点都是非核心对象。
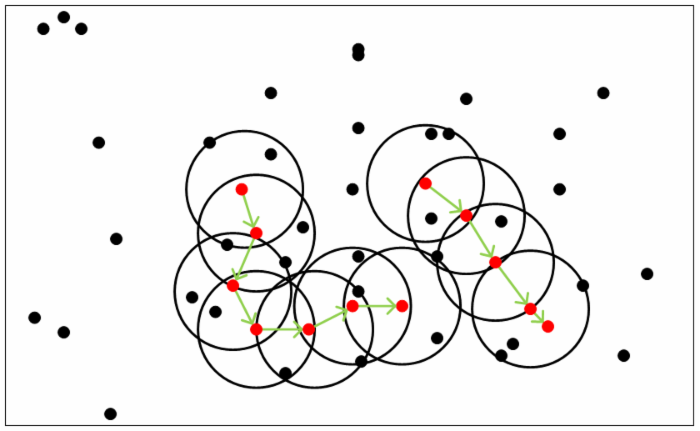
DBSCAN的核心思想:有密度可达关系导出的最大的密度相连样本集合。即分类簇C必须满足:
1)连接性:xi∈ C,xj∈ C,可以直接推出xi 与xj 密度相连,同簇内的元素必须满足密度相连
2)最大性:xi∈ C,xj 有xi 密度可达可以推出xj ∈C
DBSCAN算法的具体流程如下:
1)根据预先给定的(ϵ,MinPts)确定核心对象的集合
2)从核心对象集合中任选一核心对象,找出由其密度可达的对象生成聚类簇
3)从核心对象中除掉已选的核心对象和已分配到簇中的核心对象(这说明在一个簇内肯能存在多个核心对象)
4)重复2,3 步骤,直到所有的核心对象被用完
DBSACN算法理解起来还是比较简单的,但是也存在一些问题:
1)在所有的核心对象都被用完之后,可能还是会存在一些样本点没有被分配到任何簇中,此时我们认为这些样本点是异常点
2)对于有的样本可能会属于多个核心对象,而且这些核心对象不是密度直达的,那么在我们的算法中事实上是采用了先来先到的原则
与K-means算法相比,DBSCAN算法有两大特点,一是不需要预先设定簇数K的值,二是DBSCAN算法同时适用于凸集和非凸集,而K-means只适用于凸集,在非凸集上可能无法收敛。对于DBSCAN算法适用于稠密的数据或者是非凸集的数据,此时DBSCAB算法的效果要比K-means算法好很多。因此若数据不是稠密的,我们一般不用DBSCAN算法。
DBSCAN算法的优点:
1)可以对任意形状的稠密数据进行聚类(包括非凸集)
2)可以在聚类是发现异常点,对异常点不敏感
3)聚类结果比较稳定,不会有什么偏倚,而K-means中初始值对结果有很大的影响
DBSCAN算法的缺点:
1)样本集密度不均匀时,聚类间距相差很大时,聚类效果不佳
2)样本集较大时,收敛时间长,可以用KD树进行最近邻的搜索
3)需要调试的参数比K-means多些,需要去调试ϵ 和MinPts参数(联合调参,不同的组合的结果都不一样)
3、层次聚类和AGNES算法
层次聚类试图在不同的层次上对数据集进行划分,从而形成树形的聚类结构,数据集的划分可采用 “自底向上”的聚类策略,也可以采用“ 自顶向下” 的策略。在构建树之后,所有的样本都位于叶节点中,叶节点的个数就是簇数。
AGNES是一种采用自底向上的聚类策略的层次聚类算法。AGNES的核心思想是先将数据集中的每个样本看作一个初始聚类簇,然后每次迭代时找出距离最近的两个簇进行合并,依次迭代知道簇类的个数达到我们指定的个数K为止,这种方法的好处是随着簇类数量的减少,需要计算的距离也会越来越少,而且相对K-means,不需要考虑初始化时随机簇心对模型到来的影响。
之前讲到的距离计算都是样本之间的计算,那么关于簇与簇之间的距离该如何计算呢,在这里主要有三种计算策略:
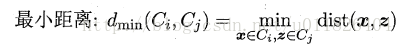
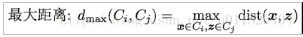
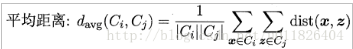
AGNES具体的算法流程如下(数据来源 机器学习-周志华版):

关于层次聚类,除了AGNES算法之外,还有BIRCH算法,BIRCH算法适用于数据量大,簇类K的数量较多的情况下,这种算法只需要遍历一遍数据集既可以完成聚类,运行速度很快。BIRCH算法利用了一个类似于B+树的树结构来帮助我们快速聚类,一般我们将它称为聚类特征数(简称CF Tree),BIRCH算法属于自上向下的层次聚类算法(根据数据集的导入自上而下不断的分裂加层来构建CF 树),CF 树中的每个叶节点就对应着一个簇。因此BIRCH算法事实上就是在构建一颗树,构建完之后,树的叶节点就是对应的簇,叶节点中的样本就是每个簇内的样本。BIRCH适用于大样本集,收敛速度快,且不需要设定簇数K的值,但是要设定树的结构约束值(比如叶节点中样本的个数,内节点中样本的个数),此外BIRCH算法对于数据特征维度很大的样本(比如大于20维)不适合。
机器学习算法总结(五)——聚类算法(K-means,密度聚类,层次聚类)的更多相关文章
- 聚类算法:K均值、凝聚层次聚类和DBSCAN
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- 常见聚类算法——K均值、凝聚层次聚类和DBSCAN比较
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- 软件——机器学习与Python,聚类,K——means
K-means是一种聚类算法: 这里运用k-means进行31个城市的分类 城市的数据保存在city.txt文件中,内容如下: BJ,2959.19,730.79,749.41,513.34,467. ...
- 个性化排序算法实践(五)——DCN算法
wide&deep在个性化排序算法中是影响力比较大的工作了.wide部分是手动特征交叉(负责memorization),deep部分利用mlp来实现高阶特征交叉(负责generalizatio ...
- 机器学习Sklearn系列:(五)聚类算法
K-means 原理 首先随机选择k个初始点作为质心 1. 对每一个样本点,计算得到距离其最近的质心,将其类别标记为该质心对应的类别 2. 使用归类好的样本点,重新计算K个类别的质心 3. 重复上述过 ...
- Mahout机器学习平台之聚类算法具体剖析(含实例分析)
第一部分: 学习Mahout必需要知道的资料查找技能: 学会查官方帮助文档: 解压用于安装文件(mahout-distribution-0.6.tar.gz),找到例如以下位置.我将该文件解压到win ...
- 机器学习:Python实现聚类算法(三)之总结
考虑到学习知识的顺序及效率问题,所以后续的几种聚类方法不再详细讲解原理,也不再写python实现的源代码,只介绍下算法的基本思路,使大家对每种算法有个直观的印象,从而可以更好的理解函数中参数的意义及作 ...
- 【Python机器学习实战】聚类算法(1)——K-Means聚类
实战部分主要针对某一具体算法对其原理进行较为详细的介绍,然后进行简单地实现(可能对算法性能考虑欠缺),这一部分主要介绍一些常见的一些聚类算法. K-means聚类算法 0.聚类算法算法简介 聚类算法算 ...
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
- 密度峰值聚类算法(DPC)
密度峰值聚类算法(DPC) 凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 1. 简介 基于密度峰值的聚类算法全称为基于快速搜索和发现密度峰值的聚类算法(cl ...
随机推荐
- JVM运行时数据区内容简述
JVM运行时数据区分为五个部分:程序计数器.虚拟机栈.本地方法栈.堆.方法区.如下图所示,五部分其中又分为线程共享区域和线程私有区域,下面将分别介绍每一部分. 1. PC程序计数器 程序计数器是一块较 ...
- 应用分类&练手项目计划
应用分类 练手项目 [应用] 通讯录 xx管理 聊天室 [组件] web容器 db 中间件
- 使用Vue-Router 2实现路由功能
转自:http://blog.csdn.net/sinat_17775997/article/details/54710420 注意:vue-router 2只适用于Vue2.x版本,下面我们是基于v ...
- BZOJ3453: tyvj 1858 XLkxc(拉格朗日插值)
题意 题目链接 Sol 把式子拆开,就是求这个东西 \[\sum_{i = 0} ^n \sum_{j = 1}^{a + id} \sum_{x =1}^j x^k \pmod P\] 那么设\(f ...
- CSS的基本语法
W3School离线手册(2017.03.11版)下载:https://pan.baidu.com/s/1c6cUPE7jC45mmwMfM6598A CSS(层叠样式表) ...
- mac下编译node源码
看过一篇win7 64x下面编译node的文章,链接地址:编译nodejs及其源码研究 下面学习一下在mac下面如何编译node源码. 过程也挺简单. 1.下载源码. > mkdir nodes ...
- GlusterFS 安装 on centos7
本文演示如何在CentOS7上安装,配置和使用GlusterFS. 1 准备工作 1.1 基础设施 编号 IP OS 主机名 角色 说明 A 192.168.1.101 CentOS7.4 ddc_n ...
- Symantec Backup Exec 2010 安装报 bad ELF interpreter: No such file or directory
在64位的Red Hat Enterprise Linux Server release 6.6上安装Symantec Backup Exec 2010时, 遇到下面错误: # ./installra ...
- ORACLE归档日志比联机重做日志小很多的情况总结
ORACLE归档日志比联机重做日志小很多的情况 前几天一网友在群里反馈他遇到归档日志比联机重做日志(redo log)小很多的情况,个人第一次遇到这种情况,非常感兴趣,于是在一番交流沟通后,终于弄 ...
- 前后端分离djangorestframework——版本控制组件
什么是版本控制 在实际开发中,随着时间的更新迭代,我们维护的项目可能会有很多个版本,所以我们写的API也有很多个版本,但是迭代到高版本,不可能以前的版本就不用了,比如一个手机端的app,不定期发布新版 ...