从零开始搭建django前后端分离项目 系列六(实战之聚类分析)
项目需求
本项目从impala获取到的数据为用户地理位置数据,每小时的数据量大概在8000万条,数据格式如下:

公司要求对这些用户按照聚集程度进行划分,将300米范围内用户数大于200的用户划分为一个簇,并计算这个簇的中心点和簇的边界点。
附模拟的数据:https://files.cnblogs.com/files/dotafeiying/test.zip
实现原理
下面我们来一步一步实现上述需求:
1、将用户按照聚集程度进行划分
我们可以选择基于密度的聚类算法DBscan算法,DBSCAN算法的重点是选取的聚合半径参数eps和聚合所需指定的数目min_samples,正好对应这里的300米和200个用户。但是需要注意的是,dbscan算法的默认距离度量为欧几里得距离,而我们需要的是球面距离,所以需要定制我们自己的距离算法运用到dbscan算法中。解决方法是:将dbscan设置为 metric='precomputed' ,这时fit传入的X参数必须为相似度矩阵,然后fit函数会直接用你这个矩阵来进行计算。这意味着我们可以用我们自定义的距离事先计算好各个向量的相似度,然后调用这个函数来获得结果。
2、识别簇的边界点
这里我使用凸包算法来计算簇的边界点,那么问题就变成:如何求一个平面内所有点的最小凸边形。在scipy.spatial 和opencv 分别有计算凸包的函数,不清楚的可以自行百度。
3、计算簇的中心点
由于dbscan算法中并没有提到获取簇中心点的方法,那么我们就需要自己设计来计算簇的中心点。现在簇的所有点已知,我们可以利用k-means算法来计算簇的中心点,只需要设置K=1(即质心为1)。
实现代码
# -*- coding:utf-8 -*-
from math import radians, cos, sin, asin, sqrt,degrees
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN, KMeans
from scipy.spatial import ConvexHull
from sklearn.cluster import MeanShift, estimate_bandwidth
from scipy.spatial.distance import pdist, squareform
from sklearn import metrics pd.set_option('display.width', 400)
pd.set_option('display.expand_frame_repr', False)
pd.set_option('display.max_columns', 70) def haversine(lonlat1, lonlat2):
lat1, lon1 = lonlat1
lat2, lon2 = lonlat2
lon1, lat1, lon2, lat2 = map(radians, [lon1, lat1, lon2, lat2])
dlon = lon2 - lon1
dlat = lat2 - lat1
a = sin(dlat / 2) ** 2 + cos(lat1) * cos(lat2) * sin(dlon / 2) ** 2
c = 2 * asin(sqrt(a))
r = 6371 # Radius of earth in kilometers. Use 3956 for miles
return c * r if __name__=='__main__':
df=pd.read_csv('test.csv')
print(df.head())
X=df[['mr_longitude','mr_latitude']].values radius = 200
epsilon = radius / 100000
min_samples = 40 # model = DBSCAN(eps=epsilon, min_samples=min_samples)
# y_pred = model.fit_predict(X) # # 自定义度量距离
distance_matrix = squareform(pdist(X, (lambda u, v: haversine(u, v))))
db = DBSCAN(eps=300, min_samples=200, metric='precomputed')
y_pred = db.fit_predict(distance_matrix)
print(y_pred.tolist()) n_clusters_ = len(set(y_pred)) - (1 if -1 in y_pred else 0) # 获取分簇的数目
print('分簇的数目:',n_clusters_)
df['label'] = y_pred df_group = df[df['label'] != -1][['mr_longitude', 'mr_latitude', 'label']].groupby(['label'])
plt.figure(facecolor='w')
for label, group in df_group:
points = group[['mr_longitude', 'mr_latitude']].values
# 得到凸轮廓坐标的索引值,逆时针画
hull = ConvexHull(points).vertices.tolist()
hull.append(hull[0])
plt.plot(points[hull, 0], points[hull, 1], 'r--^', lw=2)
for i in range(len(hull) - 1):
plt.text(points[hull[i], 0], points[hull[i], 1], str(i), fontsize=10)
plt.scatter(X[:, 0], X[:, 1], c=y_pred,s=4)
plt.grid(True)
plt.show()
可视化
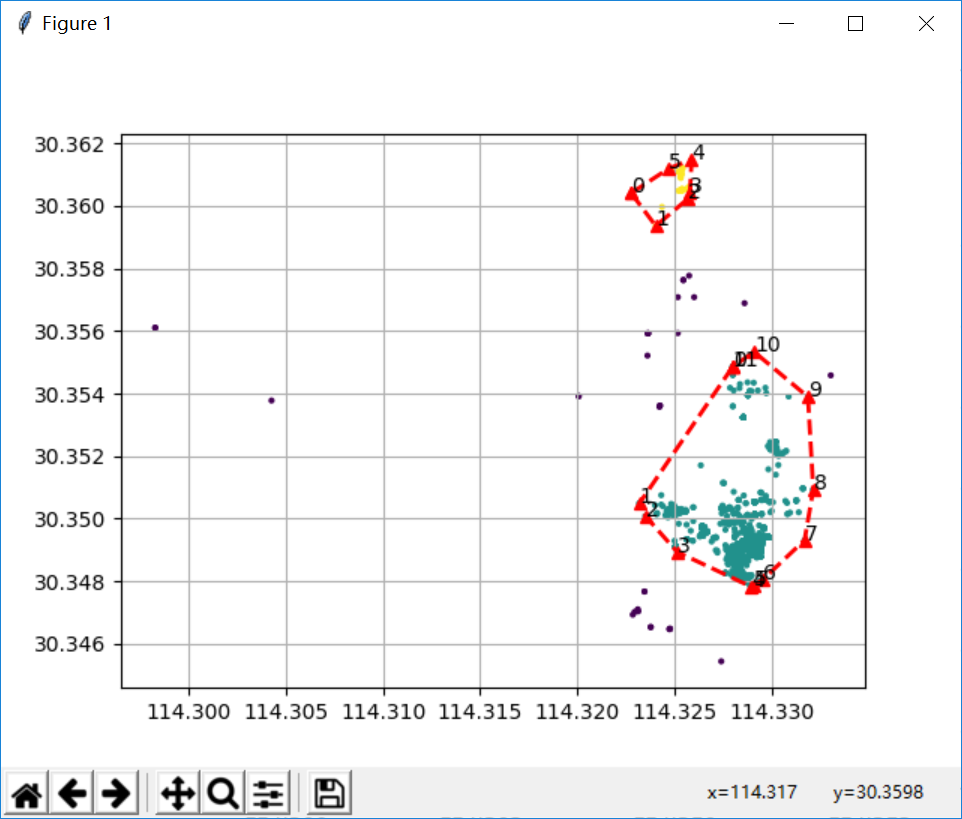
实际项目中的效果图

从零开始搭建django前后端分离项目 系列六(实战之聚类分析)的更多相关文章
- 从零开始搭建django前后端分离项目 系列一(技术选型)
前言 最近公司要求基于公司的hadoop平台做一个关于电信移动网络的数据分析平台,整个项目需求大体分为四大功能模块:数据挖掘分析.报表数据查询.GIS地理化展示.任务监控管理.由于页面功能较复杂,所以 ...
- 从零开始搭建django前后端分离项目 系列四(实战之实时进度)
本项目实现了任务执行的实时进度查询 实现方式 前端websocket + 后端websocket + 后端redis订阅/发布 实现原理 任务执行后,假设用变量num标记任务执行的进度,然后将num发 ...
- 从零开始搭建django前后端分离项目 系列三(实战之异步任务执行)
前面已经将项目环境搭建好了,下面进入实战环节.这里挑选项目中涉及到的几个重要的功能模块进行讲解. celery执行异步任务和任务管理 Celery 是一个专注于实时处理和任务调度的分布式任务队列.由于 ...
- 从零开始搭建django前后端分离项目 系列二(项目搭建)
在开始项目之前,假设你已了解以下知识:webpack配置.vue.js.django.这里不会教你webpack的基本配置.热更新是什么,也不会告诉你如何开始一个django项目,有需求的请百度,相关 ...
- 从零开始搭建django前后端分离项目 系列五(实战之excel流式导出)
项目中有一处功能需求是:需要在历史数据查询页面进行查询字段的选择,然后由后台数据库动态生成对应的excel表格并下载到本地. 如果文件较小,解决办法是先将要传送的内容全生成在内存中,然后再一次性传入R ...
- Django前后端分离项目部署
vue+drf的前后端分离部署笔记 前端部署过程 端口划分: vue+nginx的端口 是81 vue向后台发请求,首先发给的是代理服务器,这里模拟是nginx的 9000 drf后台运行在 9005 ...
- luffy项目搭建流程(Django前后端分离项目范本)
第一阶段: 1.版本控制器:Git 2.pip安装源换国内源 3.虚拟环境搭建 4.后台:Django项目创建 5.数据库配置 6.luffy前 ...
- nginx+vue+uwsgi+django的前后端分离项目部署
Vue+Django前后端分离项目部署,nginx默认端口80,数据提交监听端口9000,反向代理(uwsgi配置)端口9999 1.下载项目文件(统一在/opt/luffyproject目录) (1 ...
- List多个字段标识过滤 IIS发布.net core mvc web站点 ASP.NET Core 实战:构建带有版本控制的 API 接口 ASP.NET Core 实战:使用 ASP.NET Core Web API 和 Vue.js 搭建前后端分离项目 Using AutoFac
List多个字段标识过滤 class Program{ public static void Main(string[] args) { List<T> list = new List& ...
随机推荐
- Javascript 对象 - 数组对象
JavaScript核心对象 数组对象Array 字符串对象String 日期对象Date 数学对象Math 数组对象 数组对象是用来在单一的变量名中存储一系列的值.数组是在编程语言中经常使用的一种数 ...
- Android为TV端助力 转载自jguangyou的博客,XML基本属性大全
android:layout_width 指定组件布局宽度 android:layout_height 指定组件布局高度 android:alpha 设置组件透明度 android:backgroun ...
- (网页)websocket例子
转载自博客园张果package action; import javax.websocket.CloseReason; import javax.websocket.OnClose; import j ...
- 设计模式java----单例模式
一.懒汉式单例 在第一次调用的时候实例化自己,Singleton的唯一实例只能通过getInstance()方法访问.线程不安全 /** * Created by Admin on 2017/3/19 ...
- List删除
使用for循环,倒序删除: ; i >= ; i--) { var item = list[i]; ") { list.Remove(item); } }
- c/c++ 标准库 map set 插入
标准库 map set 插入 一,插入操作 有map如下: map<string, size_t> cnt; 插入方法: 插入操作种类 功能描述 cnt.insert({"abc ...
- Turtle绘制带颜色和字体的图形(Python3)
转载自https://blog.csdn.net/wumenglu1018/article/details/78184930 在Python中有很多编写图形程序的方法,一个简单的启动图形化程序设计的方 ...
- web测试笔记
WEB兼容性测试 一.客户端兼容性 1.浏览器的兼容性测试 a.内核角度 Tridnt内核:代表作IE.腾讯.遨游.世界之窗等 Gecko内核:代表作Firefox webkit内核:代表作Safar ...
- March 04th, 2018 Week 10th Sunday
Tomorrow never comes. 我生待明日,万事成蹉跎. Most of my past failures can be chalked up to the bad habit of pr ...
- 让EntityFramework.Extended支持MySql
EF:Entity Framework EFEL:Entity Framework Extended Library EFEL5.0时代是不支持MySql的,现在升级到6.0之后,已经支持MySql了 ...