初学Python——文件操作第三篇
一、引言
什么?有了第二篇文件操作还不够?远远不够!而且在读完第三篇文件操作还是不够。关于文件的操作,后续的学习中将不断学习新的操作方式,使用更加合适的方法。
进入正题,上一篇讲到,Python对文件最基本的读取写入操作,都必须是字符串,所有的数据必须要转化成字符串写入,都出来的也全部都是字符串,这会给我们实际应用中造成一些困扰,上一篇文章讲述了如何使用eval()函数,但是也有局限性,比如:字符串格式稍有错误(结尾带有换行符\n)就会转换出错;写入文件之前在内存中的int型数据,写入读取仔eval后无法变回int型等。因此,我们需要更加标准、更加合理的方法来完成文件读写。
接下来将一一介绍四个模块:json, pickle, shelve, shutil
先将个概念:序列化。即将内存中各种类型的数据转成能够写入文件的格式的标准过程。反序列化是序列化的反过程。
二、json模块
json模块提供一些功能,能够处理简单的数据类型:布尔型、(长)整形、字符型、浮点型等,以及列表、字典等。将这些类型的数据通过序列化即可写入文件,读取文件时通过反序列化即可在内存中正常使用。json是可以跨平台使用的,python、java等语言都可以使用它,并进行不同语言之间的数据交互。
1、dumps() 和 loads() 方法
import json # 导入json模块
kwargs={
"name":"Alex",
"age":21,
}
args=[1,6,8,4]
acer="woshishei"
f=open("序列化","w",encoding="utf-8")
f.write(json.dumps(kwargs)) # 将字典序列化写入文件
f.write("\n")
f.write(json.dumps(args)) # 将列表序列化写入文件
f.write("\n")
f.write(json.dumps(acer)) # 将字符串序列化写入文件
f.write("\n")
f.close()
print(type(json.dumps(args))) #输出序列化后的类型
f=open("序列化","r",encoding="utf-8")
data=f.readlines() #读取文件
f.close()
for i,j in enumerate(data):
data[i]=json.loads(j) # 逐个反序列化
print(data[0]) # 输出
print(data[1])
print(data[2])
print(data[0]["age"])
print(data[1][1])
运行结果:
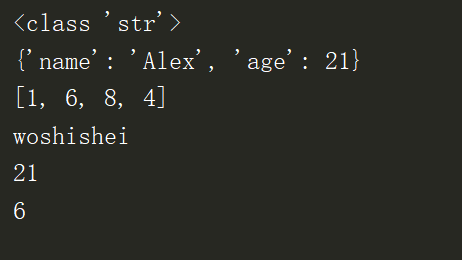
运行结果显示: json序列化就是将其转化成字符串(标准、规范的操作)
2、dump() 和 load() 方法
上面了解到,序列化的语句是 json.dumps(<被转化变量>),反序列化语句是 json.loads(<从文件读出的数据>)
同时也应该注意到,我是一行一行写读的,一个数据写一行,一行绝对不能写两个数据。
dump() 和 load() 只是写法不同,功能是一样的
f=open("序列化","w",encoding="utf-8")
json.dump(kwargs,f)
f.close()
f=open("序列化","r",encoding="utf-8")
data=json.load(f) #读取文件并将其反序列化
f.close()
有了json模块,可以很方便地在内存中复原数据。
三、pickle模块
pickle模块和json模块的功能基本相同。不同点是:pickle模块不能跨平台使用,是Python专用的模块,但是可以使用复杂的数据类型,函数等都可以。
1、dumps() 和 loads() 方法
import pickle
f=open("序列化","wb") #如果用pickle,必须用二进制文件的打开方式
f.write(pickle.dumps(kwargs)) #与json完全一样的操作
f.close()
print(type(pickle.dumps(kwargs))) #将数据类型转化成何种类型
f=open("序列化","rb")
data=pickle.loads(f.read()) # 反序列化
f.close()
print(data["age"])
运行结果:
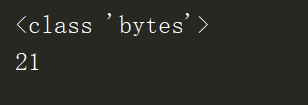
结果显示,pickle序列化后,将数据转化成bytes类型。
2、dump() 和 load() 方法
def text(name):
print("hello,",name) kwargs={
"name":"Alex",
"age":21,
"function":text
} f=open("序列化","wb")
pickle.dump(kwargs,f)
f.close() f=open("序列化","rb")
data=pickle.load(f)
f.close()
data["function"]("alex")
结果:
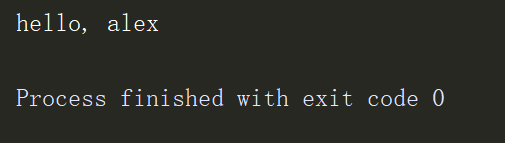
运行结果证明,函数被序列化写入文件,并成功反序列化回来,运行无误。
对于反序列化来说,如果反序列化操作在另外一个程序,读取之前写入的函数时会报错。因为序列化的程序在结束时函数已经不存在。
如果想要在反序列化的程序里正常使用,只能从原来的文件里copy函数过来。
新建一个.py文件,测试一下:
f=open("序列化","rb")
data=pickle.load(f)
f.close()
data["function"]("alex")

程序报错!
在这里强调一点:json序列化写入文件的时候,可以将多个数据分行写入;但是pickle序列化则不可以,一个数据只能写入一个文件!
四、shelve模块
shelve模块是一个将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的Pyhton模块。可以理解是对pickle更高一层的封装,能够非常方便地写入和读取数据。
import shelve
import datetime info={"age":22,"sex":"man"}
name=["hello","good","nice"] # 写入文件
d=shelve.open("shelve_text") # 打开一个文件
d["name"]=name # 持久化列表
d["info"]=info # 持久化字典
d["date"]=datetime.datetime.now() # 持久化时间
d.close() # 读取文件
d=shelve.open("shelve_text")
a=d.get("name")
b=d.get("info")
c=d.get("date")
d.close() print(a)
print(b)
print(c)
运行结果:

完美运行。可以看到,shelve模块读写文件的操作更加简洁方便。
五、shutil模块
更高级的操作来了——shutil模块。不过,它不止能对普通文件操作,还可以处理文件夹和压缩包。
1.普通文件、文件夹操作部分:
import shutil
f1=open("text1","r",encoding="utf-8")
f2=open("text2","w",encoding="utf-8")
shutil.copyfileobj(f1,f2) # 将文件内容拷贝到另一个文件中(必须先打开文件才能操作)
f1.close()
f2.close()
运行情况就不上图了,可以自己试一下。
还有丰富的操作手法:
shutil.copyfile("text1","text3") # 不需要打开文件,直接复制文件(如果有文件直接覆盖,如果没有文件则创建)
shutil.copymode("text1","text2") # 仅拷贝权限,内容、组、用户均不拷贝
shutil.copystat("text1","text2") # 拷贝状态的信息,不拷贝内容
shutil.copy("text1","text2") # 将文件和权限都复制过来(源代码中:copy == copyfile + copymode )
shutil.copy2("text1","text2") # 将文件和状态信息拷贝(源代码中:copy2 == copyfile + copystat )
shutil.copytree("package2","new_package2") # 递归地去拷贝文件(复制文件夹)
shutil.rmtree("new_package2") # 删除一个文件夹
shutil.move("F:\\Pythonfiles\\day5\\package2","D:\\") # 移动文件(夹)的位置( 旧路径(完整)-->新路径(父目录) )
shutil.move("D:\\package2","F:\\Pythonfiles\\day5")
2.压缩包操作部分:
① shutil.make_archive() 方法:创建压缩包并返回路径,
参数:
base_name:压缩包名,也可以是压缩包路径。如果只是名称,默认当前路径
format:压缩包格式,"zip","tar","bztar","gztar"
root_dir:被压缩文件的路径,默认当前路径
owner:用户,默认当前用户
group:组,默认当前组
logger:用于记录日志,通常是logging.Logger对象
#res=shutil.make_archive("压缩包","zip","package2") #如果多次执行此语句,将覆盖同名压缩包
#print("路径是:",res)
#res1=shutil.make_archive("压缩包2","zip","packaged")
#print("路径2是",res1)
② shutil对压缩包的操作是通过 zipfile 和 tarfile 两个模块来完成的:
先说zipfile:
import zipfile #压缩文件
z=zipfile.ZipFile("压缩包.zip","a") #打开压缩包
z.write("text1")
z.write("random_module.py")
z.write("asdf.xlsx")
z.write("135456.txt")
z.close() #关闭压缩包 '''
"w"方式打开并写入,会覆盖包内所有的文件
"a"方式可以追加文件,但需要注意的是,不能重复写入同名文件,否则会报错
''' #解压文件
z=zipfile.ZipFile("压缩包.zip","r")
#z.extractall() #将所有文件解压到当前路径下
z.extractall("wooo") #将所有文件解压到指定路径下
z.extract("asdf.xlsx","解压") #将指定文件解压(参数:member成员,path默认当前路径)
print(zipfile.ZipFile.namelist(z)) #输出文件列表
print(z.namelist()) #输出文件列表
z.close()
#在使用zipfile文件句柄z时,跟open打开文件不同,没有光标这种概念 print(zipfile.is_zipfile("压缩包.zip")) #判断文件是不是压缩文件
有兴趣可以在自己电脑上测试。
再讲tarfile:
import tarfile # 压缩
tar = tarfile.open('your.tar','w')
print(help(tar.add))
tar.add('135456.txt',arcname="bbs2") # arcname="bbs2" 为存档的文件指定别名
tar.add('asdf.xlsx',arcname="cmdb")
tar.close() # 解压
tar = tarfile.open('your.tar','r')
tar.extractall("waaa") # 可设置解压地址
tar.close()
六、chardet模块
可以智能检测编码,第三方模块,需要安装。
在命令行直接输入 pip3 install chardet 即可安装
使用:
import chardet
f = open("文件","rb")
data = f.read()
f.close()
res = chardet.detect(data)
printf(res)
结果:{'encoding': 'GB2312', 'confidence': 0.99, 'language': 'Chinese'}
confidence翻译过来是自信程度,0.99,类似于机器学习
初学Python——文件操作第三篇的更多相关文章
- 初学Python——文件操作第二篇
前言:为什么需要第二篇文件操作?因为第一篇的知识根本不足以支撑基本的需求.下面来一一分析. 一.Python文件操作的特点 首先来类比一下,作为高级编程语言的始祖,C语言如何对文件进行操作? 字符(串 ...
- 初学Python——文件操作
一.文件的打开和关闭 1.常用的打开关闭语句 f=open("yesterday","r",encoding="utf-8") #打开文件 ...
- Python基础篇【第2篇】: Python文件操作
Python文件操作 在Python中一个文件,就是一个操作对象,通过不同属性即可对文件进行各种操作.Python中提供了许多的内置函数和方法能够对文件进行基本操作. Python对文件的操作概括来说 ...
- 【转】C语言文件操作解析(三)
原文网址:http://www.cnblogs.com/dolphin0520/archive/2011/10/07/2200454.html C语言文件操作解析(三) 在前面已经讨论了文件打开操作, ...
- [Python学习笔记][第七章Python文件操作]
2016/1/30学习内容 第七章 Python文件操作 文本文件 文本文件存储的是常规字符串,通常每行以换行符'\n'结尾. 二进制文件 二进制文件把对象内容以字节串(bytes)进行存储,无法用笔 ...
- 关于python 文件操作os.fdopen(), os.close(), tempfile.mkstemp()
嗯.最近在弄的东西也跟这个有关系,由于c基础渣渣.现在基本上都忘记得差不多的情况下,是需要花点功夫才能弄明白. 每个语言都有相关的文件操作. 今天在flask 的例子里看到这样一句话.拉开了文件操作折 ...
- Python之路Python文件操作
Python之路Python文件操作 一.文件的操作 文件句柄 = open('文件路径+文件名', '模式') 例子 f = open("test.txt","r&qu ...
- Python:文件操作技巧(File operation)(转)
Python:文件操作技巧(File operation) 读写文件 # ! /usr/bin/python # -*- coding: utf8 -*- spath = " D:/dow ...
- Python文件操作:文件的打开关闭读取写入
Python文件操作:文件的打开关闭读取写入 一.文件的打开关闭 Python能以文本和二进制两种方式处理文件,本文主要讨论在Python3中文本文件的操作. 文件操作都分为以下几个步骤: 1.打开文 ...
随机推荐
- elementUI vue v-model的修饰符
v-model的修饰符 v-model.lazy 只有在input输入框发生一个blur时才触发 v-model.trim 将用户输入的前后的空格去掉 v-model.number 将用户输入的字符串 ...
- 微信小程序调用地图选取位置后返回信息
先看一下wxml的代码,绑定个事件! <view class='carpool_data_all'> <view class='aa'> <text>*出发地< ...
- POJ1201 Intervals(差分约束)
Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 28416 Accepted: 10966 Description You ...
- Netty实现一个简单聊天系统(点对点及服务端推送)
Netty是一个基于NIO,异步的,事件驱动的网络通信框架.由于使用Java提供 的NIO包中的API开发网络服务器代码量大,复杂,难保证稳定性.netty这类的网络框架应运而生.通过使用netty框 ...
- Spring学习之旅(五)极速创建Spring AOP java工程项目
编译工具:eclipse. 简单说一下,Spring AOP是干嘛的? 假设你创建了一群类:类A,类B,类C,类D.... 现在你想为每个类都增加一个新功能,那么该怎么办呢?是不是想到了为每个类增加 ...
- MySQL 5.6.20-enterprise-commercial的参数文件位置问题
今天在折腾MySQL的参数文件时,突然发现MySQL 5.6.20-enterprise-commercial-advanced-log这个版本数据库的参数文件my.cnf的位置有点奇怪,如下所示: ...
- Oracle笔记----oracle数字类型number自增
创建序列 create sequence seq_student start increment maxvalue nominvalue nocycle nocache; 创建触发器 create o ...
- 洗礼灵魂,修炼python(87)-- 知识拾遗篇 —— 线程(1)
线程(上) 1.线程含义:一段指令集,也就是一个执行某个程序的代码.不管你执行的是什么,代码量少与多,都会重新翻译为一段指令集.可以理解为轻量级进程 比如,ipconfig,或者, python ...
- c/c++ 多态的实现原理分析
多态的实现原理分析 当类里有一个函数被声明成虚函数后,创建这个类的对象的时候,就会自动加入一个__vfptr的指针, __vfptr维护虚函数列表.如果有三个虚函数,则__vfptr指向的是第一个虚函 ...
- python创建列表和向列表添加元素方法
今天的学习内容是python中的列表的相关内容. 一.创建列表 1.创建一个普通列表 >>> tabulation1 = ['大圣','天蓬','卷帘'] >>> ...