Python转页爬取某铝业网站上的数据
天行健,君子以自强不息;地势坤,君子以厚德载物!
好了废话不多说,正式进入主题,前段时间应朋友的请求,爬取了某铝业网站上的数据。刚开始呢,还是挺不愿意的(主要是自己没有完整的爬取过网上的数据哎,即是不自信),但是在兄弟伙的面前不能丢脸卅,硬起头皮都要上,于是乎答应了他,好吧~~~~
我们的爬取目标:
http://www.chalco.com.cn/chalco/ywycp/cpbj/A120401web_1.htm
1、总共63页,每页有十几条的链接
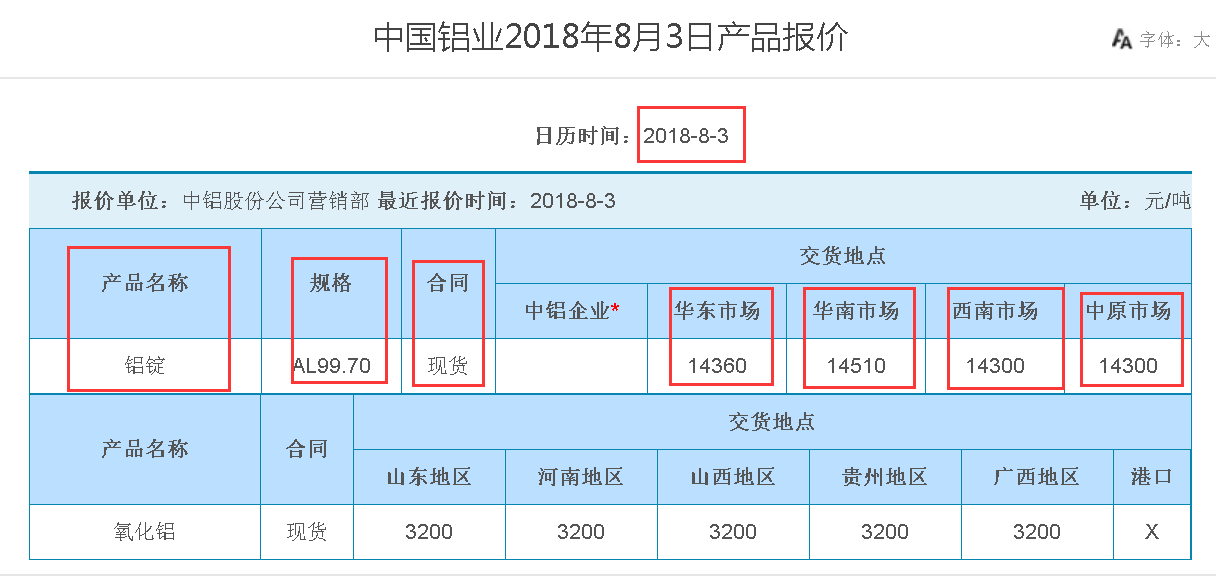
2、爬取连接里面的数据(主要有产品名称、规格、合同、华东市场、华南市场、西南市场、中原市场、产品报价时间)
3、爬取的数据存为CSV格式
一、网页源代码分析:
1、分析网站每页的网址
第一页的网址:http://www.chalco.com.cn/chalco/ywycp/cpbj/A120401web_1.html
第二页的网址:http://www.chalco.com.cn/chalco/ywycp/cpbj/A120401web_2.html
第三页的网址:http://www.chalco.com.cn/chalco/ywycp/cpbj/A120401web_3.html
依次类推
咱们可以发现第63页的网址是:http://www.chalco.com.cn/chalco/ywycp/cpbj/A120401web_63.html
2、分析每页网页的源代码
通过查看第一页的网页的源代码,可以发现,第一页上的每天的产品报价的链接。

则,整体思路为:
(1)拼接所有页的网址(http://www.chalco.com.cn/chalco/ywycp/cpbj/A120401web_1.html);
(2)解析出每页中的数据链接(<A href=/chalco/ywycp/cpbj/webinfo/2018/08/1533256568236442.htm target=_blank>中国铝业2018年8月3日产品报价</A>);
(3)通过链接正则匹配出所需要的数据。
二、Python源码
此次爬取,使用的是request和re包!
__Author__ = "MEET Shen"
import requests
import re
import pandas as pd def get_allpage_url(n):
'''
得到所有页的连接
'''
totalpage_urls=[]
for i in range(n):
i=i+1
url_change_page="http://www.chalco.com.cn/chalco/ywycp/cpbj/A120401web_{0}.htm".format(str(i))
totalpage_urls.append(url_change_page)
return totalpage_urls
url=get_allpage_url(20)
def get_datapage_url(data):
'''
http://www.chalco.com.cn/chalco/ywycp/cpbj/webinfo/2018/06/1530058323659676.htm
/chalco/ywycp/cpbj/webinfo/2018/06/1530058323659676.htm
:return:
'''
#正则表达式进行解析出所有的数据连接
pattern=re.compile('.*?</DIV><DIV class=cpbj-item-xz><A href=(.*?) target=_blank>.*?',re.S)
items=re.findall(pattern,data)
del items[0]
result_url=[]
for i in items:
joint="http://www.chalco.com.cn{0}".format(i)
result_url.append(joint)
items_len=len(items)
return result_url,items_len headers={"User-Agent":'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36'
' (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 '
'Core/1.53.4482.400 QQBrowser/9.7.13001.400'} def get_everypage_data(result_url):
response = requests.get(url=result_url, headers=headers)
data = response.text
pattern=re.compile('.*?<P><STRONG>日历时间:</STRONG>(.*?)</P>.*?'
'<TD bgColor=#ffffff>(.*?)</TD>.*?'
'<TD bgColor=#ffffff>(.*?) </TD>.*?'
'<TD bgColor=#ffffff>(.*?)</TD>.*?'
'<TD bgColor=#ffffff>(.*?)</TD>.*?'
'<TD bgColor=#ffffff>(.*?)</TD>.*?'
'<TD bgColor=#ffffff>(.*?)</TD>.*?'
'<TD bgColor=#ffffff>(.*?)</TD>.*?'
'<TD bgColor=#ffffff>(.*?)</TD>.*?'
,re.S)
items=re.findall(pattern,data)
items1=list(items[0])
items1[7] = items1[7].replace('<p>','')
items1[7] = items1[7].replace('</p>','')
items1[8] = items1[8].replace('<p>','')
items1[8] = items1[8].replace('</p>','')
items1[8] = items1[8].replace(' </P>', '')
items1[5] = items1[5].replace('<FONT size=3 face="Times New Roman">', '')
items1[5] = items1[5].replace('</FONT>', '')
items1[6] = items1[6].replace('<FONT size=3 face="Times New Roman">', '')
items1[6] = items1[6].replace('</FONT>', '')
items1[7] = items1[7].replace('<FONT size=3 face="Times New Roman">', '')
items1[7] = items1[7].replace('</FONT>', '')
items1[8] = items1[8].replace('<FONT size=3 face="Times New Roman">', '')
items1[8] = items1[8].replace('</FONT>', '')
return items1 def get_asignpage_data():
items = []
for i in range(len(url)):
response = requests.get(url=url[i], headers=headers)
data = response.text
result_url,items_len = get_datapage_url(data)
for i in range(items_len):
item=get_everypage_data(result_url[i])
items.append(item)
return items items=get_asignpage_data() #存为CSV格式
import pandas as pd
data=pd.DataFrame(items,columns={'time','产品名称','规格','合同','中铝企业','华东市场','华南市场','西南市场','中原市场'})
print(data)
data.to_csv('C:/Users/Administrator/PycharmProjects/untitled/data/lvye1.csv',sep=',')
三、爬取的最终结果
由于数据不很大,爬取的速度还是能够接受的,最终爬取的数据,且形成的CSV文件如下所示:

笔者还处于学习的状态,如有写得不够专业或有错误的地方,真心希望各位读者前来探讨!!!!!
Python转页爬取某铝业网站上的数据的更多相关文章
- Python开发爬虫之BeautifulSoup解析网页篇:爬取安居客网站上北京二手房数据
目标:爬取安居客网站上前10页北京二手房的数据,包括二手房源的名称.价格.几室几厅.大小.建造年份.联系人.地址.标签等. 网址为:https://beijing.anjuke.com/sale/ B ...
- 04 Python网络爬虫 <<爬取get/post请求的页面数据>>之requests模块
一. urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib ...
- Scrapy实战篇(七)之爬取爱基金网站基金业绩数据
本篇我们以scrapy+selelum的方式来爬取爱基金网站(http://fund.10jqka.com.cn/datacenter/jz/)的基金业绩数据. 思路:我们以http://fund.1 ...
- 利用python实现爬虫爬取某招聘网站,北京地区岗位名称包含某关键字的所有岗位平均月薪
#通过输入的关键字,爬取北京地区某岗位的平均月薪 # -*- coding: utf-8 -*- import re import requests import time import lxml.h ...
- Python 2.7_爬取妹子图网站单页测试图片_20170114
1.url= http://www.mzitu.com/74100/x,2为1到23的值 2.用到模块 os 创建文件目录; re模块正则匹配目录名 图片下载地址; time模块 限制下载时间;req ...
- python+xpath+requests爬取维基百科历史上的今天
import requests import urllib.parse import datetime from lxml import etree fhout = open("result ...
- [代码]--python爬虫联系--爬取成语
闲来无事,玩了个成语接龙,于是就想用python爬取下成语网站上的成语,直接上代码: #coding=utf-8 import requests from bs4 import BeautifulSo ...
- Python爬虫《爬取get请求的页面数据》
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- [Python]爬取 游民星空网站 每周精选壁纸(1080高清壁纸) 网络爬虫
一.检查 首先进入该网站的https://www.gamersky.com/robots.txt页面 给出提示: 弹出错误页面 注: 网络爬虫:自动或人工识别robots.txt,再进行内容爬取 约束 ...
随机推荐
- asp.net 抽象方法和虚方法的用法区别,用Global类重写Application_BeginRequest等方法为例子
不废话,直接贴代码 public abstract class LogNetGlobal : System.Web.HttpApplication { protected void Applicati ...
- 2018-04-10 我的GitHub诞生的日子,欢迎大家吐槽批评
我的GitHub,诞生的日子,欢迎大家吐槽与批评,嘻嘻 首先是自己想刷一下LeetCode上的代码,其次创建了自己的读书笔记以及面试经验与教训 下边是仓库的Git链接,欢迎大家的批评与修正,谢谢: L ...
- C++: cin
cin字符的时候, 会忽略掉'\n', ' '等空白符
- bootstrap中的dropdown组件扩展hover事件
bootstrap的下拉组件,需要点击click时,方可展示下拉列表.因此对于喜欢简单少操作的大家来说,点击一下多少带来不便,因此,引入hover监听,鼠标经过自动展示下拉框.其实在bootstrap ...
- Python TVTK 标量数据可视化与矢量数据可视化,空间轮廓线可视化
Python数据可视化分为 标量可视化,矢量可视化,轮廓线可视化 标量又称无向量,只有大小没有方向,运算遵循代数运算法则比如质量,密度,温度,体积,时间 矢量又称向量,它是由大小,方向共同确定的量,运 ...
- windows putty xming virt-manager
记一次windows环境使用linux下使用virt-manager软件的问题 环境:windows server 2008.ubuntu-server 软件:putty.virt-manager.x ...
- python网络编程 双人多人聊天
在学习网路编程时,我们首先要考虑的是其中的逻辑,我们借助打电话的形式来了解网络编程的过程, 我们打电话时属于呼叫方,接电话的属于被呼叫方,那么被呼叫方一直保持在待机状态,等待主呼叫方 呼叫,只有在被呼 ...
- 基于coridc算法的定点小数除法器的实现
`timescale 1ns / 1ps /////////////////////////////////////////////////////////////////////////////// ...
- View事件分发
NOTE: 笔记,碎片式内容 控件 App界面的开主要就是使用View,或者称为控件.View既绘制内容又响应输入,输入事件主要就是触摸事件. ViewTree 控件基类为View,而ViewGrou ...
- 折腾nock给jsonp进行单元测试
概述 前几天学习用Jest和nock.js对异步api进行单元测试.在项目中,我用到了jsonp,自然想到对jsonp进行单元测试. 过程很折腾,结果很有趣. jsonp.js 首先axios或者fe ...