使用scheduler-plugins实现自定义调度器
一、环境说明
| 开发环境 | 部署环境 | |
|---|---|---|
| 操作系统 | Windows10 | Centos7.9 |
| Go版本 | go version go1.24.2 windows/amd64 | go version go1.23.6 linux/amd64 |
| 插件版本 | Master分支 | |
| Docker版本 | Docker version 26.1.4, build 5650f9b | |
| k8s版本 | v1.28.0 (minikube) |
补充说明:
k8s环境是由minikube创建,CRI为docker,如果CRI为Containerd,也不影响,后面会说明如何部署。
二、开发
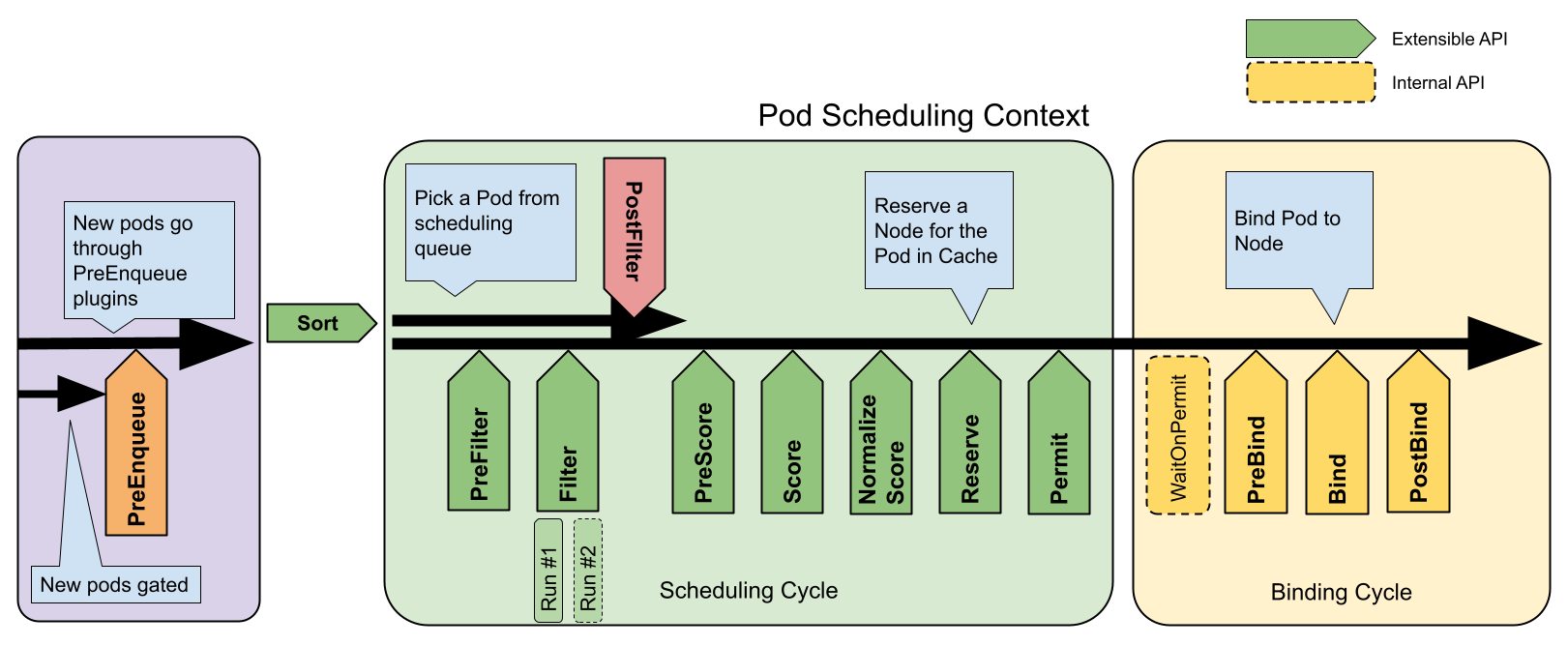
本次开发是在scheduler-plugins源码基础上进行开发。
通过上图可以看到,Filter和Score是两个核心,一般开发也是围绕着Filter和Score。
首先需要把scheduler-plugins的源码下载到本地,直接使用git进行拉取即可。
git clone https://github.com/kubernetes-sigs/scheduler-plugins.git
当然如果对版本有特定要求,请根据官方提供的readme进行分支切换。
插件的代码都放在pkg目录下, 现在需要自定义一个插件,当然也是在pkg目录下进行开发。
pkg目录下创建一个新的目录,比如叫prefernode,在prefernode目录下创建创建prefernode.go文件。
接下来就可以在prefernode.go里编写自定义调度器的核心逻辑了。
假如现在想让所有使用自定义调度器的pod都调度到指定的某个节点上,这里直接实现Score。
package prefernode1
import (
"context"
v1 "k8s.io/api/core/v1"
"k8s.io/kubernetes/pkg/scheduler/framework"
"k8s.io/apimachinery/pkg/runtime"
"k8s.io/klog/v2"
)
const Name = "PreferNode"
type PreferNode struct {
handle framework.Handle
}
func (p *PreferNode) Name() string {
return Name
}
func (p *PreferNode) Score(_ context.Context, _ *framework.CycleState, pod *v1.Pod, nodeName string) (int64, *framework.Status) {
klog.V(5).Infof("Scoring pod %s on node %s", pod.Name, nodeName)
if nodeName == "minikube-m03" {
return 100, nil
}
return 0, nil
}
func (p *PreferNode) ScoreExtensions() framework.ScoreExtensions {
return nil
}
func New(_ context.Context, _ runtime.Object, _ framework.Handle) (framework.Plugin, error) {
return &PreferNode{}, nil
}
以上代码,已经实现了具体需求,将所有使用我们自定义插件的Pod都调度到某个节点上。这里指定的是"minikube-m03"。
插件核心代码写好了,还需要进行注册,让框架知道我们是现在自定义插件。
返回项目根目录,进入到cmd/scheduler,编辑main.go,在command中进行注册。
func main() {
// Register prefernode1 plugins to the scheduler framework.
// Later they can consist of scheduler profile(s) and hence
// used by various kinds of workloads.
command := app.NewSchedulerCommand(
app.WithPlugin(capacityscheduling.Name, capacityscheduling.New),
app.WithPlugin(coscheduling.Name, coscheduling.New),
app.WithPlugin(loadvariationriskbalancing.Name, loadvariationriskbalancing.New),
app.WithPlugin(networkoverhead.Name, networkoverhead.New),
app.WithPlugin(topologicalsort.Name, topologicalsort.New),
app.WithPlugin(noderesources.AllocatableName, noderesources.NewAllocatable),
app.WithPlugin(noderesourcetopology.Name, noderesourcetopology.New),
app.WithPlugin(preemptiontoleration.Name, preemptiontoleration.New),
app.WithPlugin(targetloadpacking.Name, targetloadpacking.New),
app.WithPlugin(lowriskovercommitment.Name, lowriskovercommitment.New),
app.WithPlugin(sysched.Name, sysched.New),
app.WithPlugin(peaks.Name, peaks.New),
// Sample plugins below.
// app.WithPlugin(crossnodepreemption.Name, crossnodepreemption.New),
app.WithPlugin(podstate.Name, podstate.New),
app.WithPlugin(qos.Name, qos.New),
// 这是我们自定义的插件
app.WithPlugin(prefernode.Name, prefernode.New),
)
code := cli.Run(command)
os.Exit(code)
}
到此,开发完成。
如果你觉得上面的实现比较简陋,当然了,这里也提供一个同时实现Filter和Score的插件。
package prefernode
import (
"k8s.io/kubernetes/pkg/scheduler/framework"
"context"
"k8s.io/api/core/v1"
"k8s.io/klog/v2"
"fmt"
"sort"
"k8s.io/apimachinery/pkg/runtime"
)
const Name = "PreferNode"
type PreferNode struct {
handler framework.Handle
}
func (p *PreferNode) Name() string {
return Name
}
// Filter 实现预选逻辑
func (p *PreferNode) Filter(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
if nodeInfo == nil || nodeInfo.Node() == nil {
klog.Error("@@@ node not found @@@")
return framework.NewStatus(framework.Error, "node not found")
}
node := nodeInfo.Node()
klog.V(4).Infof("prefernode filter pod %s/%s:%s", pod.Namespace, pod.Name, node.Name)
// 检查节点是否可调度
if node.Spec.Unschedulable {
klog.V(4).Infof("Node %s is unschedulable", node.Name)
return framework.NewStatus(framework.Unschedulable, "node is unschedulable")
}
// 检查节点是否有足够的资源
podRequest := calculatePodResourceRequest(pod)
nodeAllocatable := node.Status.Allocatable
cpuAvailable := nodeAllocatable.Cpu().MilliValue()
memAvailable := nodeAllocatable.Memory().MilliValue()
if cpuAvailable < podRequest.cpu {
klog.V(4).Infof("Node %s doesn't have enough CPU: required %d, available: %d", node.Name, podRequest.cpu, cpuAvailable)
return framework.NewStatus(framework.Unschedulable, "Insufficient CPU")
}
if memAvailable < podRequest.memory {
klog.V(4).Infof("Node %s doesn't have enough Memory: required %d, available: %d", node.Name, podRequest.memory, memAvailable)
return framework.NewStatus(framework.Unschedulable, "Insufficient Memory")
}
// 检查节点标签是否匹配
if pod.Spec.NodeSelector != nil {
for key, value := range pod.Spec.NodeSelector {
nodeValue, exists := node.Labels[key]
if !exists || nodeValue != value {
klog.V(4).Infof("Node %s does not have label %s=%s", node.Name, key, value)
return framework.NewStatus(framework.Unschedulable, "Insufficient Label")
}
}
}
klog.V(4).Infof("Node %s passed all filters for pod %s/%s", node.Name, pod.Namespace, pod.Name)
return framework.NewStatus(framework.Success, "")
}
func (p *PreferNode) Score(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeName string) (int64, *framework.Status) {
klog.V(4).Infof("Scoring pod %s/%s on node %s", pod.Namespace, pod.Name, nodeName)
nodeInfo, err := p.handler.SnapshotSharedLister().NodeInfos().Get(nodeName)
if err != nil {
klog.Errorf("Error getting node %s from snapshot: %v", nodeName, err)
return 0, framework.NewStatus(framework.Error, fmt.Sprintf("getting node %s from snapshot: %v", nodeName, err))
}
node := nodeInfo.Node()
// 基础分 - 考虑节点负载和可用资源
score := int64(0)
// 1、计算CPU得分 - 优先选择CPU资源充足的节点
cpuCapacity := node.Status.Capacity.Cpu().MilliValue()
cpuAllocatable := node.Status.Allocatable.Cpu().MilliValue()
cpuUsed := cpuCapacity - cpuAllocatable
// 计算cpu使用率
var cpuUtilization float64
if cpuCapacity > 0 {
cpuUtilization = float64(cpuUsed) / float64(cpuCapacity)
}
// CPU得分,使用率越低得分越高,最高40分
cpuScore := int64((1 - cpuUtilization) * 40)
// 2、计算内存得分 - 优先选择内存资源充足的节点
memCapacity := node.Status.Capacity.Memory().Value()
memAllocatable := node.Status.Allocatable.Memory().Value()
memUsed := memCapacity - memAllocatable
// 计算内存使用率
var memUtilization float64
if memCapacity > 0 {
memUtilization = float64(memUsed) / float64(memCapacity)
}
// 内存得分, 使用率越低得分越高,最高40分
memScore := int64((1 - memUtilization) * 40)
// 2、节点标签偏好得分
labelScore := int64(0)
// 检查是否有特定角色标签
if value, exits := node.Labels["kubernetes.io/role"]; exits && value == "worker" {
labelScore += 10
}
if nodeName == "minikube-m03" {
labelScore += 10
}
// 计算总分
score = cpuScore + memScore + labelScore
klog.V(3).Infof("Score for pod %s/%s on node %s: %d (CPU: %d, Memory: %d, Labels: %d)",
pod.Namespace, pod.Name, nodeName, score, cpuScore, memScore, labelScore)
return score, nil
}
// ScoreExtensions 返回扩展接口
func (p *PreferNode) ScoreExtensions() framework.ScoreExtensions {
return p
}
// NormalizeScore 实现分数归一化
func (p *PreferNode) NormalizeScore(ctx context.Context, state *framework.CycleState, pod *v1.Pod, scores framework.NodeScoreList) *framework.Status {
// 找出最高分和最低分
var highest int64
var lowest = framework.MaxNodeScore
for _, nodeScore := range scores {
if nodeScore.Score > highest {
highest = nodeScore.Score
}
if nodeScore.Score < lowest {
lowest = nodeScore.Score
}
}
klog.V(4).Infof("Score range for pod %s/%s: [%d, %d]", pod.Namespace, pod.Name, lowest, highest)
// 如果所有节点得分相同,则不需要归一化
if highest == lowest{
klog.V(4).Infof("No need to normalize scores as all nodes have the same score")
return nil
}
// 归一化分数到0-100范围
for i := range scores{
scores[i].Score = framework.MaxNodeScore * (scores[i].Score - lowest) / (highest - lowest)
klog.V(4).Infof("Normalized score for node %s:%d",scores[i].Name,scores[i].Score)
}
// 按分数排序,记录结果
sortedScores := make(framework.NodeScoreList, len(scores))
copy(sortedScores, scores)
sort.Slice(sortedScores, func(i,j int) bool {
return sortedScores[i].Score > sortedScores[j].Score
})
klog.V(3).Infof("Final scores for pod %s/%s",pod.Namespace,pod.Name)
for i, nodeScroe := range sortedScores {
klog.V(5).Infof("@@@ %d. Node %s: %d",i+1, nodeScroe.Name,nodeScroe.Score)
}
return nil
}
// 资源请求结构体
type resourceRequest struct {
cpu int64
memory int64
}
// 计算Pod资源请求
func calculatePodResourceRequest(pod *v1.Pod) resourceRequest {
result := resourceRequest{}
for _, container := range pod.Spec.Containers {
if container.Resources.Requests != nil {
result.cpu += container.Resources.Requests.Cpu().MilliValue()
result.memory += container.Resources.Requests.Memory().Value()
}
}
// 如果没有明确指定资源请求,使用默认值
if result.cpu == 0 {
result.cpu = 100 // 默认100m CPU
}
if result.memory == 0 {
result.memory = 256 * 1024 * 1024 // 默认256Mi
}
return result
}
// New 创建一个新的PreferNode插件实例
func New(_ context.Context, _ runtime.Object, h framework.Handle) (framework.Plugin, error) {
return &PreferNode{
handler: h,
}, nil
}
三、部署
开发完成后,在编译环境中进行编译。
进入到scheduler-plugins目录下,直接运行make。
# make
go build -ldflags '-X k8s.io/component-base/version.gitVersion=v0.32.5 -w' -o bin/controller cmd/controller/controller.go
go build -ldflags '-X k8s.io/component-base/version.gitVersion=v0.32.5 -w' -o bin/kube-scheduler cmd/scheduler/main.go
可以看到编译好的文件放到了同级的bin/目录下,我们需要使用的是kube-scheduler。
现在需要将我们的插件编译成Docker镜像。
FROM debian:bullseye-slim
COPY bin/kube-scheduler /usr/local/bin/kube-scheduler
RUN chmod +x /usr/local/bin/kube-scheduler
ENTRYPOINT ["/usr/local/bin/kube-scheduler"]
执行命令进行编译,假如镜像名就叫custom-scheduler:v1.0
docker build -t custom-scheduler:v1.0 .
注意,这块需要补充一下,如果集群的容器使用containerd,则需要将docker镜像能让contained使用。
可以直接使用docker将镜像打包成tar,然后使用ctr解包。需要格外注意的是ctr需要指定-n命名空间,不然k8s识别不到。
docker save -o image.tar custom-scheduler:v1.0
ctr -n=k8s.io -images import image.tar
或者使用私有仓库。
镜像准备就绪后,就可以进行下一步操作了。将进行部署到k8s集群中。
这里不得不在提k8s环境了,我的环境是minikube起的,并且多节点,所以需要将镜像导入到minikube中,如果你使用的是kind,也需要进行类似的操作。
minikube image load custom-scheduler:v1.0
加载完成后,可以使用minikube image ls检查一下。
接下来需要创建configmap,先创建scheduler-config.yaml。注意:如果使用简陋版的,则不需要配置filter。
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
clientConnection:
kubeconfig: "/etc/kubernetes/kubeconfig"
leaderElection:
leaderElect: false
profiles:
- schedulerName: custom-scheduler
plugins:
filter:
enabled:
- name: PreferNode
score:
enabled:
- name: PreferNode
同时需要准备kubeconfig文件,这个文件可以在.kube下找到。同样为了方便,生成到当前目录下。
kubectl config view --flatten --minify > scheduler.kubeconfig
现在就可以创建configMap和Secret了。(其实完全可以创建两个configMap)
创建configMap和secret。
kubectl create configmap scheduler-config \
--from-file=scheduler-config.yaml=scheduler-config.yaml \
-n kube-system
kubectl create secret generic scheduler-kubeconfig \
--from-file=kubeconfig=scheduler.kubeconfig \
-n kube-system
RBAC准入这块也需要进行设置。
apiVersion: v1
kind: ServiceAccount
metadata:
name: custom-scheduler
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: custom-scheduler-rolebinding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:kube-scheduler
subjects:
- kind: ServiceAccount
name: custom-scheduler
namespace: kube-system
到此为止,部署的准备工作基本完成了,接下来就是部署自定义调度器了。
apiVersion: apps/v1
kind: Deployment
metadata:
name: custom-scheduler
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
component: custom-scheduler
template:
metadata:
labels:
component: custom-scheduler
spec:
serviceAccountName: custom-scheduler
containers:
- name: custom-scheduler
image: docker.io/library/custom-scheduler:v1.0
args:
- --config=/etc/kubernetes/scheduler-config.yaml
- --v=5
volumeMounts:
- name: scheduler-config
mountPath: /etc/kubernetes/scheduler-config.yaml
subPath: scheduler-config.yaml
- name: scheduler-kubeconfig
mountPath: /etc/kubernetes/kubeconfig
subPath: kubeconfig
volumes:
- name: scheduler-config
configMap:
name: scheduler-config
- name: scheduler-kubeconfig
secret:
secretName: scheduler-kubeconfig
部署完成后,查看pod的运行状况。
四、测试
这里提交一个简单的pod进行测试
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
schedulerName: custom-scheduler
containers:
- name: nginx
image: nginx:1.17.1
查看,可以发现pod被调度到m03节点上了。
kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-pod 1/1 Running 0 37m 10.96.151.14 minikube-m03 <none> <none>
同样可以查看下自定义调度器的日志。可以看到03节点得了100分。
...
I0607 08:46:21.638574 1 prefernode.go:31] prefernode filter pod default/test-pod:minikube
I0607 08:46:21.638587 1 prefernode.go:67] Node minikube passed all filters for pod default/test-pod
I0607 08:46:21.638597 1 prefernode.go:31] prefernode filter pod default/test-pod:minikube-m02
I0607 08:46:21.638603 1 prefernode.go:67] Node minikube-m02 passed all filters for pod default/test-pod
I0607 08:46:21.638610 1 prefernode.go:31] prefernode filter pod default/test-pod:minikube-m03
I0607 08:46:21.638614 1 prefernode.go:67] Node minikube-m03 passed all filters for pod default/test-pod
I0607 08:46:21.638759 1 prefernode.go:72] Scoring pod default/test-pod on node minikube
I0607 08:46:21.638770 1 prefernode.go:128] Score for pod default/test-pod on node minikube: 80 (CPU: 40, Memory: 40, Labels: 0)
I0607 08:46:21.638782 1 prefernode.go:72] Scoring pod default/test-pod on node minikube-m02
I0607 08:46:21.638787 1 prefernode.go:128] Score for pod default/test-pod on node minikube-m02: 80 (CPU: 40, Memory: 40, Labels: 0)
I0607 08:46:21.638797 1 prefernode.go:72] Scoring pod default/test-pod on node minikube-m03
I0607 08:46:21.638808 1 prefernode.go:128] Score for pod default/test-pod on node minikube-m03: 90 (CPU: 40, Memory: 40, Labels: 10)
I0607 08:46:21.638838 1 prefernode.go:154] Score range for pod default/test-pod: [80, 90]
I0607 08:46:21.638844 1 prefernode.go:165] Normalized score for node minikube:0
I0607 08:46:21.638847 1 prefernode.go:165] Normalized score for node minikube-m02:0
I0607 08:46:21.638850 1 prefernode.go:165] Normalized score for node minikube-m03:100
I0607 08:46:21.638857 1 prefernode.go:175] Final scores for pod default/test-pod
I0607 08:46:21.638861 1 prefernode.go:177] @@@ 1. Node minikube-m03: 100
I0607 08:46:21.638864 1 prefernode.go:177] @@@ 2. Node minikube: 0
I0607 08:46:21.638867 1 prefernode.go:177] @@@ 3. Node minikube-m02: 0
...
使用scheduler-plugins实现自定义调度器的更多相关文章
- scrapy 基础组件专题(七):scrapy 调度器、调度器中间件、自定义调度器
一.调度器 配置 SCHEDULER = 'scrapy.core.scheduler.Scheduler' #表示scrapy包下core文件夹scheduler文件Scheduler类# 可以通过 ...
- Linux IO Scheduler(Linux IO 调度器)【转】
每个块设备或者块设备的分区,都对应有自身的请求队列(request_queue),而每个请求队列都可以选择一个I/O调度器来协调所递交的request.I/O调度器的基本目的是将请求按照它们对应在块设 ...
- Linux IO Scheduler(Linux IO 调度器)
每个块设备或者块设备的分区,都对应有自身的请求队列(request_queue),而每个请求队列都可以选择一个I/O调度器来协调所递交的request.I/O调度器的基本目的是将请求按照它们对应在块设 ...
- 【Cocos2d-x 3.x】 调度器Scheduler类源码分析
非个人的全部理解,部分摘自cocos官网教程,感谢cocos官网. 在<CCScheduler.h>头文件中,定义了关于调度器的五个类:Timer,TimerTargetSelector, ...
- JStorm与Storm源码分析(三)--Scheduler,调度器
Scheduler作为Storm的调度器,负责为Topology分配可用资源. Storm提供了IScheduler接口,用户可以通过实现该接口来自定义Scheduler. 其定义如下: public ...
- (5)调度器(scheduler)
继承关系 原理介绍 Cocos2d-x调度器为游戏提供定时事件和定时调用服务.所有Node对象都知道如何调度和取消调度事件,使用调度器有几个好处: 每当Node不再可见或已从场景中移除时,调度器会停止 ...
- scrapy-redis(调度器Scheduler源码分析)
settings里面的配置:'''当下面配置了这个(scrapy-redis)时候,下面的调度器已经配置在scrapy-redis里面了'''##########连接配置######## REDIS_ ...
- MySQL事件调度器Event Scheduler
我们都知道windows的计划任务和linux的crontab都是用来实现一些周期性的任务和固定时间须要运行的任务. 在mysql5.1之前我们完毕数据库的周期性操作都必须借助这些操作系统实现. 在m ...
- Superior Scheduler:带你了解FusionInsight MRS的超级调度器
摘要:Superior Scheduler是一个专门为Hadoop YARN分布式资源管理系统设计的调度引擎,是针对企业客户融合资源池,多租户的业务诉求而设计的高性能企业级调度器. 本文分享自华为云社 ...
- 【技术干货】华为云FusionInsight MRS的自研超级调度器Superior Scheduler
Superior Scheduler是一个专门为Hadoop YARN分布式资源管理系统设计的调度引擎,是针对企业客户融合资源池,多租户的业务诉求而设计的高性能企业级调度器. Superior Sch ...
随机推荐
- 三分钟构建高性能WebSocket服务 | 超优雅的Springboot整合Netty方案
前言 每当使用SpringBoot进行Weboscket开发时,最容易想到的就是spring-boot-starter-websocket(或spring-websocket).它可以让我们使用注解, ...
- javascript 利用 Math.min 与 Math.max 优化逻辑判断
文章同步发布:https://blog.jijian.link/2020-04-08/js-math-min-max/ Math.min 和 Math.max 方法常用来获取多个数值的最小值和最大值, ...
- [tldr] 配置windows terminal使用git bash
windows terminal默认使用power shell作为shell,但是power shell不好用,还是习惯linux的命令行行为. 参考Windows Terminal 配置 Git B ...
- Nginx: stat() failed (13: permission denied)
解决 server { listen [::]:80 default_server; # SSL configuration # # listen 443 ssl default_server; # ...
- browser-use 对 playwright 做了哪些事情
browser-use 是基于 Playwright 的增强工具,专注于将 AI 代理与浏览器自动化结合,通过简化操作和扩展功能提升了开发效率. 以下是它对 Playwright 的主要增强点: AI ...
- 搭建自己的OCR服务,第二步:PaddleOCR环境安装
PaddleOCR环境安装,遇到了很多问题,根据系统不同问题也不同,不要盲目看别人的教程,有的教程也过时了,根据实际情况自己调整. 我这边目前是使用windows 10系统+CPU + python ...
- [每日算法 - 华为机试] leetcode680. 验证回文串 II
入口 力扣https://leetcode.cn/problems/valid-palindrome-ii/submissions/ 题目描述 给你一个字符串 s,最多 可以从中删除一个字符. 请你判 ...
- 深入理解Hadoop读书笔记-2
背景 公司的物流业务系统目前实现了使用storm集群进行过门事件的实时计算处理,但是还有一个需求,我们需要存储每个标签上传的每条明细数据,然后进行定期的标签报表统计,这个是目前的实时计算框架无法满足的 ...
- 超简单电脑本地部署deepseek,另附”一键使用脚本“撰写与联网使用方法
在电脑上部署deepseek,总共分三步 1.打开ollama官网点击Download按钮 2.在ollama官网搜索deepseek-r1模型,选择对应规模,并复制ollama命令,比如这里,我的o ...
- 最火的 Python 异步 Web 框架的综合对比分析
以下是当前最火的 Python 异步 Web 框架的综合对比分析,涵盖性能.技术特性和适用场景,并补充其他值得关注的框架: 一.主流异步框架横向对比 1. FastAPI • 核心优势:基于 Star ...