【SQL周周练】一千条数据需要做一天,怎么用 SQL 处理电表数据(如何动态构造自然月)
大家好,我是“蒋点数分”,多年以来一直从事数据分析工作。从今天开始,与大家持续分享关于数据分析的学习内容。
本文是第 6 篇,也是【SQL 周周练】系列的第 5 篇。该系列是挑选或自创具有一些难度的 SQL 题目,一周至少更新一篇。后续创作的内容,初步规划的方向包括:
后续内容规划
1.利用 Streamlit 实现 Hive 元数据展示、SQL 编辑器、 结合Docker 沙箱实现数据分析 Agent
2.时间序列异常识别、异动归因算法
3.留存率拟合、预测、建模
4.学习 AB 实验、复杂实验设计等
5.自动化机器学习、自动化特征工程
6.因果推断学习
7. ……
欢迎关注,一起学习。
第 5 期题目
题目来源:改编题目,在某 Excel 论坛看到的;求助希望使用 VBA 处理(求助者自称手工处理,上千条数据就需要做一天)。我参照他的数据格式改编为 SQL 题目(我的数据完全由自己模拟生成,并没有使用求助者的数据)
一、题目介绍
有一张记录了电表缴费数据的表,缴费的时间间隔是不固定的。领导希望将这张表重新拆解按照月份来汇总,分析每月的日均使用电量等等。求助者的原始数据还有站点编码、电表号、供电类型等等,我这里将问题简化,省略这些信息,就假设只有一个电表。
注:只有缴费区间的总电量,没有每日电量;利用平均值拆分到每天再根据不同区间汇总到自然月。针对最开始的日期和结束日期,如果不满整月,就按照实际存在的日期区间来计算(时间维度按日来处理,不考虑小时等更精细的级别 | 求助者给的数据也是精确到日期而不是小时)
| 列名 | 数据类型 | 注释 |
|---|---|---|
| period_start | string | 缴费区间开始日期 |
| period_end | string | 缴费区间结束日期 |
| electricity_usage | int | 这段区间使用的电量 |
| daily_electricity_usage | int | 这段区间的日平均电量 (本应该设置为浮点类型,但是我用整数生成的) 这字段本来也没必要存在,只不过省得在 SQL 再算一遍 |
| period | int | 这段日期有几天(没啥用,我生成数据后二次校验用的) |
部分样例数据(完整生成逻辑参见第三节)
| period_start | period_end | electricity_usage | daily_electricity_usage | period |
|---|---|---|---|---|
| 2023-12-01 | 2023-12-30 | 14700 | 490 | 30 |
| 2023-12-31 | 2024-01-06 | 420 | 60 | 7 |
| 2024-01-07 | 2024-01-07 | 230 | 230 | 1 |
| 2024-01-08 | 2024-02-04 | 13160 | 470 | 28 |
| ... | ... | ... | ... | ... |
| 2025-02-11 | 2025-02-24 | 3360 | 240 | 14 |
| 2025-02-25 | 2025-03-10 | 6020 | 430 | 14 |
二、题目思路
想要答题的同学,可以先思考答案。
.……
.……
.……
我来谈谈我的思路,这道题目要解决两个问题点:
1.根据整个电费缴纳涵盖的区间,生成自然月的“维度表”。暴力的方法,那就是取最大最小日期,然后构造一个递增序列求出每一天,再分组/去重汇总成月,但是太低效了。直接的方法是获取最大最小日期之间有多少个月,然后 add_months 加上去,除了最大最小日期的端点,取出每一个月的 1 号和当月最后一天
是不是一定要做这一步?实际工作中可以使用固定日期范围或者数仓里现成的维度表
dim_date等等。但是动态日期维度表生成一方面更符合这个场景的逻辑;另一方面也是笔试的考点,只不过动态生成每一天日期更常见。
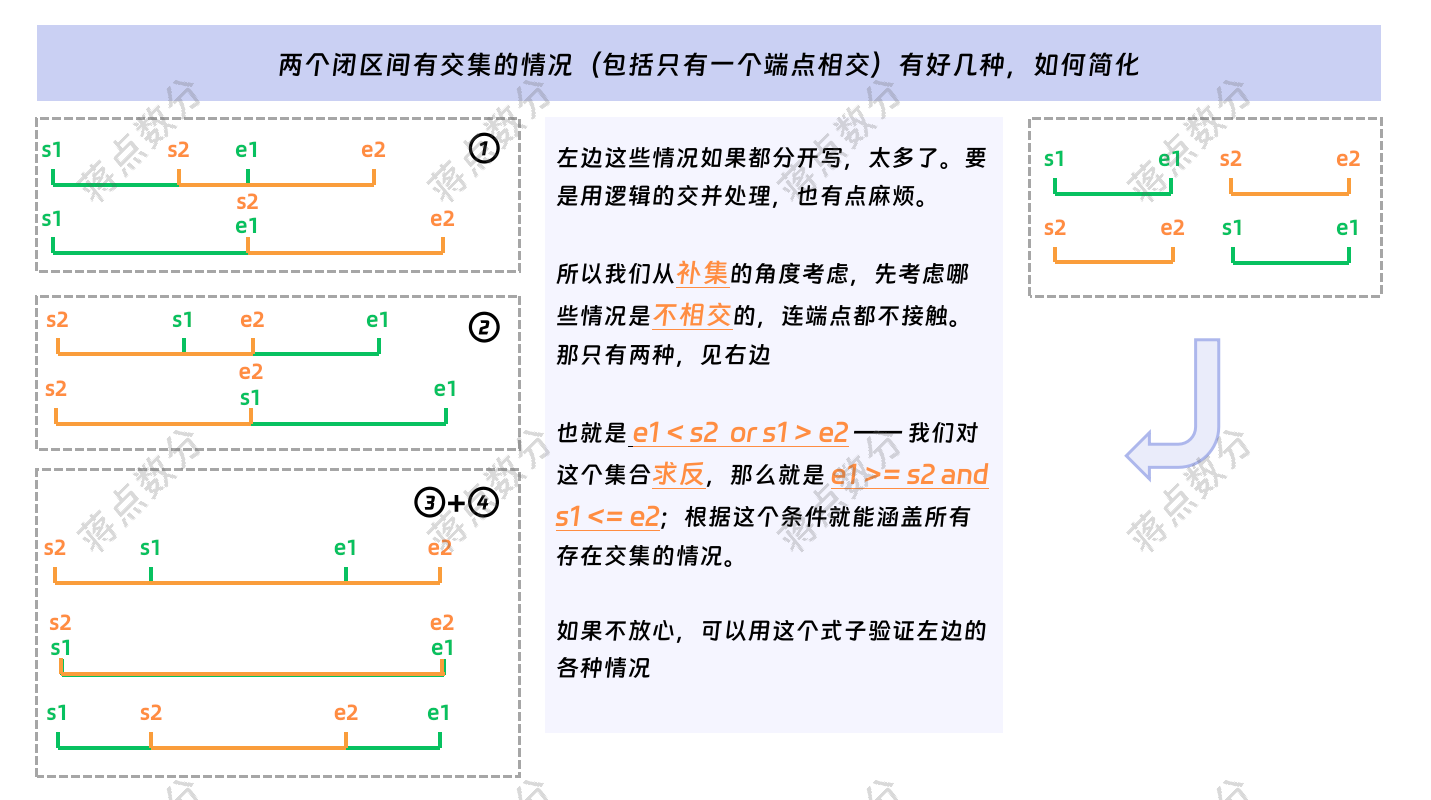
2.根据上一步获取的自然月区间,来与缴费区间关联,关联的条件是存在交集。这又涉及到两点,第一是如何判断有交集(包括哪怕只有端点一天相交),第二是如何取交集区间的数据来进行后续的计算
(目前【SQL 周周练】系列默认讨论 Hive,但很多思路可以移植到其他 SQL 方言;我了解到诸如 Oracle 和 Postgre 是有非常多函数的,可能相对于 Hive 会有更直接更好用的方法 | SparkSQL 一般都能兼容 Hive,后期我会逐步拓展到 MySQL、DuckDB、Doris/Starrocks)
下面,我用 NumPy 和 Scipy 生成模拟的数据集:
三、用 Python 生成模拟数据
只关心 SQL 代码的同学,可以跳转到第四节(我在工作中使用 Hive 较多,因此采用 Hive 的语法)
模拟代码如下:
- 构造日期间隔,并将顺序随机打乱,作为“缴费”日期区间:
import numpy as np
import pandas as pd
from datetime import datetime, timedelta
# 确定随机数种子
np.random.seed(2025)
# 构造日期间隔
date_interval_list = [1, 3, 7, 14, 15, 28, 30, 45, 90] * 2
# 打乱顺序,注意它是直接修改没有返回
np.random.shuffle(date_interval_list)
print(date_interval_list)
- 随机抽样生成“缴费”区间的日耗电量,构造“缴费”区间的起始日期、结束日期。将前面生成的数据转为
pd.DataFrame,并输出为csv文件:
power_consumption = range(50, 510, 10)
# 随机抽取数值,作为缴费区间的平均日消耗电量
daily_electricity_usage = np.random.choice(
power_consumption, size=len(date_interval_list), replace=False
)
df = pd.DataFrame(
{
"period_start": [
datetime(2023, 12, 1) + timedelta(days=sum(date_interval_list[:i]) )
for i in range(len(date_interval_list))
],
"period_end": [
datetime(2023, 12, 1) + timedelta(days=sum(date_interval_list[:i])-1)
for i in range(1, len(date_interval_list) + 1)
],
"electricity_usage": date_interval_list * daily_electricity_usage,
"daily_electricity_usage": daily_electricity_usage,
"period": date_interval_list,
}
)
# 在 Jupyter 环境中显示 dataframe,其他环境执行可能报错
display(df)
out_csv_path = "dwd_electricity_usage_records.csv"
df.to_csv(out_csv_path, index=False, header=False, encoding="utf-8-sig")
- 如果表存在则删除,创建新的
Hive表,并将数据load到表中:
from pyhive import hive
# 配置连接参数
host_ip = "127.0.0.1"
port = 10000
username = "Jiang"
with hive.Connection(host=host_ip, port=port) as conn:
cursor = conn.cursor()
hive_table_name = 'data_exercise.dwd_electricity_usage_records'
drop_table_sql = f"""
drop table if exists {hive_table_name}
"""
print('删除表语句:\n', drop_table_sql)
cursor.execute(drop_table_sql)
create_table_sql = f"""
create table if not exists `{hive_table_name}` (
period_start string comment '费用期始',
period_end string comment '费用期终',
electricity_usage int comment '计费期间总用电量',
daily_electricity_usage int comment '计费期间日均电量(用来核对结果)',
period int comment '期间天数'
)
comment "不定期的电表计费数据 | author: 蒋点数分 | 文章编号:04d08f61"
row format delimited fields terminated by ','
stored as textfile
"""
print("创建表语句:\n", create_table_sql)
cursor.execute(create_table_sql)
import os
load_data_sql = f"""
load data local inpath "{os.path.abspath(out_csv_path)}"
overwrite into table {hive_table_name}
"""
print("覆盖写入数据语句:\n", load_data_sql)
cursor.execute(load_data_sql)
cursor.close()
我通过使用
PyHive包实现 Python 操作Hive。我个人电脑部署了Hadoop及Hive,但是没有开启认证,企业里一般常用Kerberos来进行大数据集群的认证。
四、SQL 解答
我使用 CTE 的语法,这样将步骤串行展示,逻辑比较清晰,下面分成几部分解释 SQL 语句:
1.这部分代码的逻辑是,先求出所有缴费区间最大最小的日期;然后利用求出来两个日期之间的有多少自然月(包含两个端点所在的自然月);有的同学会问,Hive 中是存在 months_between 的,为什么你不用,而要自己“年-年”、“月-月”的这么算?当然可以用,但是要额外处理一下,此代码块后面,我解释一下,如何额外处理:
with get_date_interval as (
-- 获取总体的开始、结束日期:这里只是一个电表
-- 多个电表注意后续的逻辑该带分组的分组
select
min(period_start) as all_start
, max(period_end) as all_end
from data_exercise.dwd_electricity_usage_records
)
, get_inner_months as (
-- 获取两个日期之间有多少个月;“年-年”*12“+ 月-月”
-- 请参看文章的解释;如果按照“数数”的规则,注意结果加 1
-- 如果要用 months_between 函数,该怎么处理?
-- 根据官方文档,如果 两个日期的 day 部分不一样或者不是当月的最后一天
-- 则是按照 31 天的月份来计算小数部分 `fractional portion`
-- 注意 months_between 返回的小数,要取整
select
all_start, all_end
, (year(all_end) - year(all_start))*12 + month(all_end) - month(all_start) + 1 as month_cnt
-- , int(months_between(last_day(all_start), last_day(all_start)))+1 as month_cnt
from get_date_interval
)
……
关于 months_between 函数,我查看了 Hive 的官方文档,人家是这么说的 —— “If date1 and date2 are either the same days of the month or both last days of months, then the result is always an integer. Otherwise the UDF calculates the fractional portion of the result based on a 31-day month and considers the difference in time components date1 and date2.” 翻译后是 “如果 date1 和 date2 在当月的日期是相同的,或者都是各自月份的最后一天 ,那么结果始终是一个整数。否则,该函数会基于一个31天的月份来计算结果的小数部分,并考虑 date1 和 date2 的时间部分差异。”
我没有看源代码,但是这里面说的是 fractional portion 小数部分按照 31 天的月来处理,什么意思呢?我稍微实验了一下,小数部分应该就是 (day(...)-day(...))/31(负数就向前借位),它的结果是四舍五入保留 8 位数。我们想避开这个小数,就想让它返回整数月份怎么办呢(因为情况比较多,单独用向上取整、向下取整或者四舍五入取整都有问题,要综合判断,直接返回整数月份最好)
我这里的最大最小日期,大概率 day 部分是不一样的,也不太可能都是每个月份的最后一天。这样会涉及小数,那么咱手工处理一下 —— 比如将最大最小日期改成当月的最后一天,这个很简单,使用 last_day 函数即可;还可以改成当月的第一天,使用 trunc(...,'MM'),也满足使用条件。甚至咱追求个性,将日期的年月部分取出来,日部分都写个 5 号、13 号也可以,只要不超过 28 号,就不用考虑日期合法性问题。
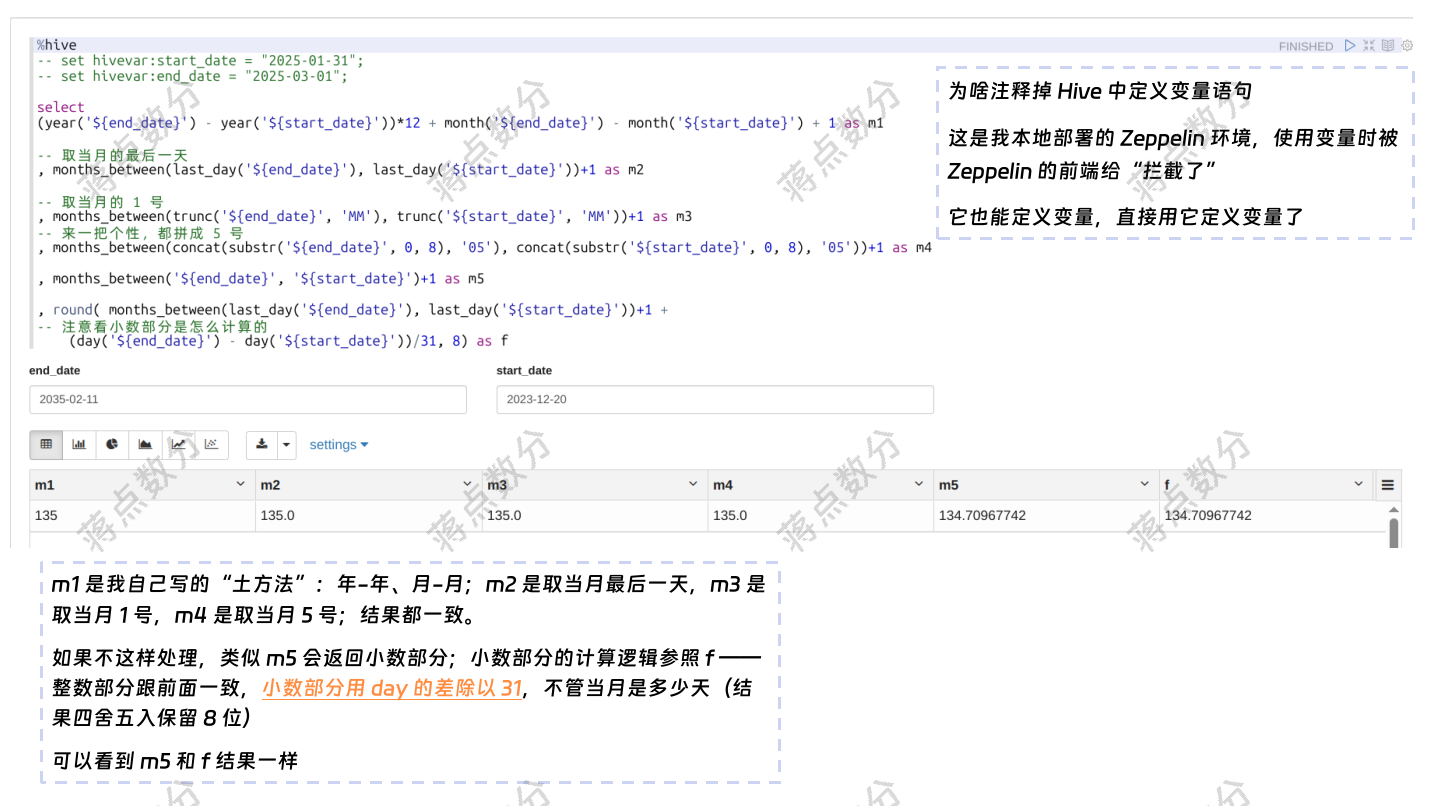
图片里 m1 到 m4 的写法都是可以的,只不过后面要转换为整数。
2.使用 repeat 和 split 加上 posexplode 构造一个指定长度的递增序列,这也是 Hive 的常见技巧。explode 更常见,posexplode 就是多返回一个“位置”列。(我个人电脑部署的 Hive 版本是 3.1.3,我验证过没有 sequence 函数)。如果根据日期取某个自然月的 1 号和最后一天,上一小节我已经解释过;注意最早最晚日期根据我题目的定义,要按照实际日期来计算:
……
, get_every_month_start as (
select
(case
-- 对于非开始日期的那个月,取当月的 1 号
when idx > 0 then add_months(trunc(g.all_start, 'MM'), idx)
-- 如果是开始日期,直接用开始日期,不管它是不是当月的 1 号
when idx = 0 then g.all_start
end) as month_start
, all_end
from get_inner_months g
lateral view posexplode(split(repeat(',', month_cnt-1), ',')) month_table as idx, m
)
, get_every_month_end as (
select
month_start
-- 如果是结束日期的那个月,结束日期就取截止日期
-- 否则取每个月的最后一天,即 last_day
, if(date_format(month_start, 'yyyy-MM') = date_format(all_end, 'yyyy-MM'), all_end,
last_day(month_start)) as month_end
from get_every_month_start
)
……
3.这一步是将前面构造的自然月维度表 get_every_month_end 与电费数据集,进行关联。关联的条件是判断有交集,为什么这两个条件可以保证有交集,我在代码下面用图片结合文字论述。另外就是当两者有交集的情况下,取交集的逻辑是 —— 起点选择最晚 greatest 的那个,终点选择最早 least 的那个。
Hive 非常早期的版本是不支持不等值连接的。这个时候要小心处理 on 后面的条件,如果是 inner join 一般将 on 后面的条件移到 where 中,而 outer join 如果 on 不匹配,只是代表关联的表没有匹配的数据,可以理解为给你一个 null;比如拿 left outer join 举例,左表的数据是不会被 on 条件过滤掉的,如果 on 能导致一条数据匹配多条,左表的部分数据甚至全部数据还会翻倍上涨。这个时候,不能将 on 的条件直接移到 where 中,而是需要保持 on 里面的最粗糙的匹配逻辑(这个场景不行,因为两个条件都是不等值,需要人工造一个无用的关联),在 select 中对于右表的列,在使用时进行 on 条件的完整判断 if,如果满足,返回右表列的值;否则返回 null。这种方法缺点是每一个用到右表的列,都需要这么处理。
……
, get_interval_power_usage as (
select
e.month_start as month_start
, e.month_end as month_end
-- 注意取两个日期区间的交集
-- 非常重要,别忘了取区间的交集
-- 起点取最后面的那个,终点取最早的那个
, greatest(r.period_start,e.month_start) as period_start
, least(r.period_end,e.month_end) as period_end
, nvl(r.daily_electricity_usage,0) as daily_electricity_usage
from get_every_month_end e
left outer join data_exercise.dwd_electricity_usage_records r
on r.period_end >= e.month_start
and r.period_start <= e.month_end
)
……
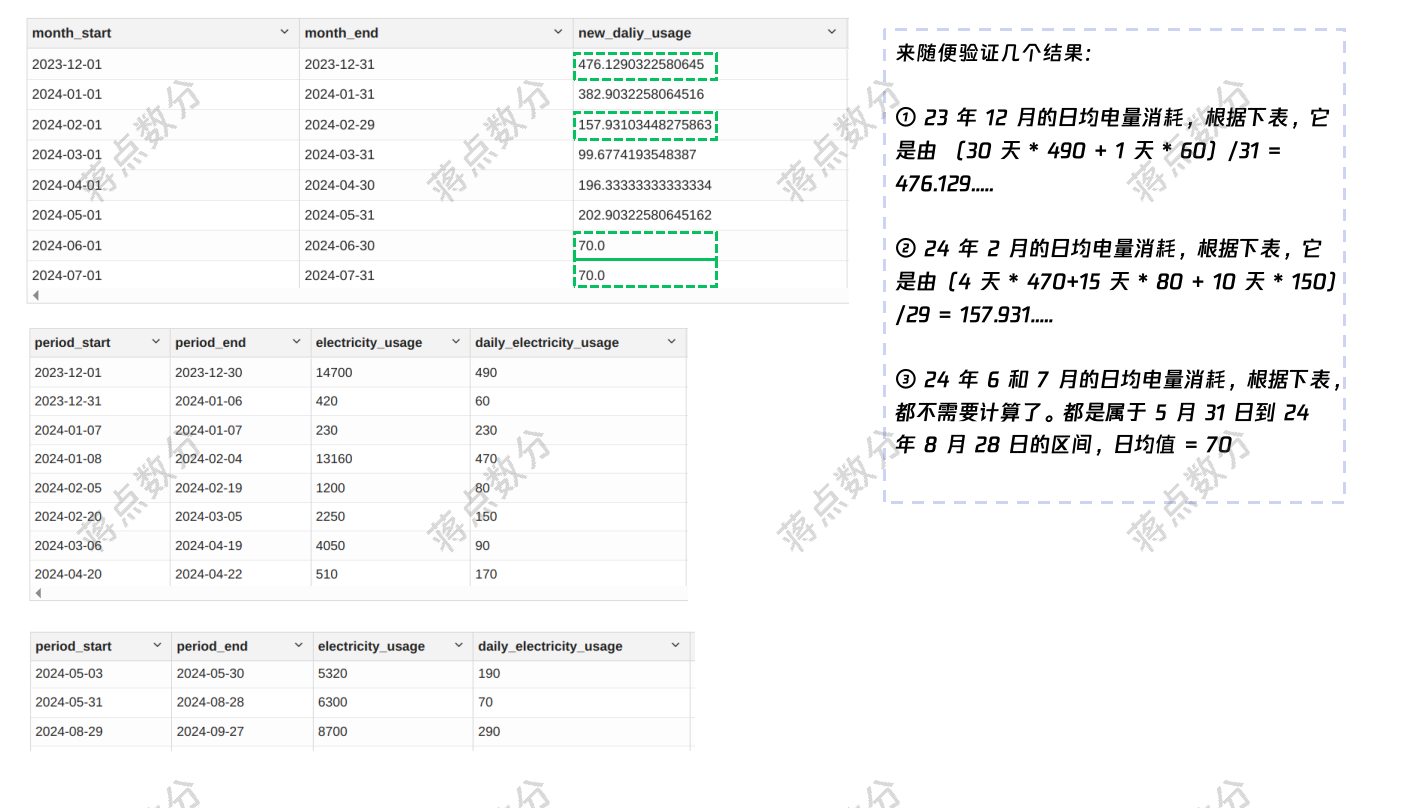
4.这是最后求结果的 SQL 部分,注意前面取交集后,会划分称成若干“子”区间,每个区间计算时用原来的日均值乘以区间长度(注意 datediff 结果加 1)计算该区间的总电量消耗。group by 加和整月的电量,整月的长度可以用子区间长度叠加 days_cnt 列,也可以直接求 days_cnt2 列,注意我这里的 month_start,month_end 在最开始与最晚日期是根据实际日期定义的,因此可以用 days_cnt2 的逻辑。
另外,这里只靠 month_start 就足以标记统计的自然月,没必要将 month_end 也作为 group by 的分组标识,用 max/min 当成维度值处理,这也是最基本的技巧。(我已经验证Hive 3.1.3 也没有 any_value)在数据量很大时或者分组 key 比较多时,有助于提高计算速度、减少资源消耗:
……
select
month_start
, max(month_end) as month_end
, sum(daily_electricity_usage * (datediff(period_end, period_start)+1))
/ sum(datediff(period_end, period_start)+1) as new_daliy_usage
-- 用哪个做分母都行
-- , sum(datediff(period_end, period_start)+1) as days_cnt
--, max(datediff(month_end, month_start)+1) as days_cnt2
from get_interval_power_usage
group by month_start
5.完整的 SQL 语句:
with get_date_interval as (
-- 获取总体的开始、结束日期:这里只是一个电表
-- 多个电表注意后续的逻辑该带分组的分组
select
min(period_start) as all_start
, max(period_end) as all_end
from data_exercise.dwd_electricity_usage_records
)
, get_inner_months as (
-- 获取两个日期之间有多少个月;为什么不用 months_between
-- 请参看文章的解释;如果按照“数数”的规则,注意结果加 1
select
all_start, all_end
, (year(all_end) - year(all_start))*12 + month(all_end) - month(all_start) + 1 as month_cnt
from get_date_interval
)
, get_every_month_start as (
select
(case
-- 对于非开始日期的那个月,取当月的 1 号
when idx > 0 then add_months(trunc(g.all_start, 'MM'), idx)
-- 如果是开始日期,直接用开始日期,不管它是不是当月的 1 号
when idx = 0 then g.all_start
end) as month_start
, all_end
from get_inner_months g
lateral view posexplode(split(repeat(',', month_cnt-1), ',')) month_table as idx, m
)
, get_every_month_end as (
select
month_start
-- 如果是结束日期的那个月,结束日期就取截止日期
-- 否则取每个月的最后一天,即 last_day
, if(date_format(month_start, 'yyyy-MM') = date_format(all_end, 'yyyy-MM'), all_end,
last_day(month_start)) as month_end
from get_every_month_start
)
, get_interval_power_usage as (
select
e.month_start as month_start
, e.month_end as month_end
-- 注意取两个日期区间的交集
-- 非常重要,别忘了取区间的交集
-- 起点取最后面的那个,终点取最早的那个
, greatest(r.period_start,e.month_start) as period_start
, least(r.period_end,e.month_end) as period_end
, r.daily_electricity_usage as daily_electricity_usage
from get_every_month_end e
left outer join data_exercise.dwd_electricity_usage_records r
on r.period_end >= e.month_start
and r.period_start <= e.month_end
)
select
month_start
, max(month_end) as month_end
, sum(daily_electricity_usage * (datediff(period_end, period_start)+1))
/ sum(datediff(period_end, period_start)+1) as new_daliy_usage
-- 用哪个做分母都行
-- , sum(datediff(period_end, period_start)+1) as days_cnt
--, max(datediff(month_end, month_start)+1) as days_cnt2
from get_interval_power_usage
group by month_start
我现在正在求职数据类工作(主要是数据分析或数据科学);如果您有合适的机会,即时到岗,不限城市。
【SQL周周练】一千条数据需要做一天,怎么用 SQL 处理电表数据(如何动态构造自然月)的更多相关文章
- 一个batch的数据如何做反向传播
一个batch的数据如何做反向传播 对于一个batch内部的数据,更新权重我们是这样做的: 假如我们有三个数据,第一个数据我们更新一次参数,不过这个更新只是在我们脑子里,实际的参数没有变化,然后使用原 ...
- Oracle 每五千条执行一次的sql语句
今天碰到一个问题,更新历史数据时,由于数据库表数据量太大,单行更新速度很慢,要求每五千条执行一次提交进行更新.执行SQL如下: declare i_count int; i_large int; be ...
- MySQL往表里插入千条数据 存储过程
工作中遇到的问题,先记录一下,方便以后查看 存在两张表,user表和friend表 user表部分字段,如上图 friend表部分字段,如上图 往friend表插入千条数据,friend表中的user ...
- mysql中造3千条数据(3种方法)
方法一:存储过程 1.存储过程如下: delimiter $$ DROP PROCEDURE IF EXISTS data CREATE PROCEDURE data(in i int) BEGIN ...
- SQL Server将同一列多条数据合并成一行
Sql server中,将同一字段多条数据用字符拼接为一个字符串方式. 原数据查询展示: 使用 STUFF 函数,将结果列拼接成一行.结果如下: STUFF: 1.作用 stuff(param1, s ...
- 测试一个服务器的性能,客户要求向数据库(Sqlserver2012)内 1000/s(每插入一千条数据) 的处理能力
通过jmeter很简单就可以完成,可以参考我以前的一篇文章<jmeter创建数据库(Sqlserver2012)测试>. 前提条件:一个数据库:test 数据库下面有一张表:user ...
- Oracle之SQL语句性能优化(34条优化方法)
(1)选择最有效率的表名顺序(只在基于规则的优化器中有效): ORACLE的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表 driving table)将被最先处 ...
- WPF画线问题,几千条以后就有明显的延迟了。
我现在是这么画的,class A { private GeometryGroup _lines; private Path _path; public A() { _path.Data = ...
- Spring+SpringMVC+MyBatis+easyUI整合优化篇(十一)数据层优化-druid监控及慢sql记录
本文提要 前文也提到过druid不仅仅是一个连接池技术,因此在将整合druid到项目中后,这一篇文章将去介绍druid的其他特性和功能,作为一个辅助工具帮助提升项目的性能,本文的重点就是两个字:监控. ...
- Spring+SpringMVC+MyBatis+easyUI整合优化篇(十二)数据层优化-explain关键字及慢sql优化
本文提要 从编码角度来优化数据层的话,我首先会去查一下项目中运行的sql语句,定位到瓶颈是否出现在这里,首先去优化sql语句,而慢sql就是其中的主要优化对象,对于慢sql,顾名思义就是花费较多执行时 ...
随机推荐
- Linux - 基础环境检查
检查操作系统:建议根据实际产品需要进行安装 检查主机名:集群中统一前缀并区分服务器功能,小写命名 检查内存:建议至少128G 检查CPU:建议至少2个支持超线程技术的10核芯片 检查磁盘:同一功能的服 ...
- pnpm : 无法加载文件 \AppData\Roaming\npm\pnpm.ps1,因为在此系统上禁止运行脚本。
1. 安装pnpm npm install -g pnpm #安装 pnpm pnpm --version #查看pnpm版本 安装完成后查看版本时报错 pnpm : 无法加载文件 C:\Users\ ...
- MySQL索引最左原则:从原理到实战的深度解析
MySQL索引最左原则:从原理到实战的深度解析 一.什么是索引最左原则? 索引最左原则是MySQL复合索引使用的核心规则,简单来说: "当使用复合索引(多列索引)时,查询条件必须从索引的最左 ...
- go的异常抛出
defer func() { if r := recover(); r != nil { fmt.Println("Recovered:", r) } }() 在任何涉及到数组取值 ...
- 文件批量重命名神器:Bulk Rename Utility
内容摘要: 你还在手动给文件重命名吗?介绍一款免费而强大的批量重命名神器:Bulk Rename Utility,它将满足你对批量改名的所有期待.让它将你从痛苦的重命名工作中解放吧! 软件获取地址 云 ...
- 几款ZooKeeper可视化工具,最后一个美炸了~
首发于公众号:BiggerBoy 欢迎关注,查看更多技术文章 ZooKeeper是我们工作中常用一个开源的分布式协调服务,提供分布式数据一致性解决方案,分布式应用程序可以实现数据发布订阅.负载均衡.命 ...
- 【Docker】容器数据卷
Docker容器数据卷 第一次听说这个名字,我一直以为是数据卷(juǎn),后来查看官方英文文档的"volume"这个单词的时候,我才反应过来,这是容器数据卷(juàn),书卷的卷 ...
- 【虚拟机】VirualBox安装macOS系统
[虚拟机]VirualBox安装macOS系统 零.创建虚拟机 类型选择 Mac OS X 版本选择 macOS 10.13 High Sierra (64-bit) 注意:这边我设置的名称为 Mac ...
- SQL Server 查看版本信息
SQL Server 查看版本信息3种方法: 1) 使用命令行查看 [Win + R]键 -> 打开cmd 2) 使用SSMS查看 打开并连接SSMS后查看 3) 通过服务器属性查看 使用SSM ...
- leetcode每日一题:转换二维数组
题目 2610. 转换二维数组 给你一个整数数组 nums .请你创建一个满足以下条件的二维数组: 二维数组应该 只 包含数组 nums 中的元素. 二维数组中的每一行都包含 不同 的整数. 二维数组 ...