开源共建 | TIS整合数据同步工具ChunJun,携手完善开源生态
TIS整合ChunJun实操
B站视频:
https://www.bilibili.com/video/BV1QM411z7w5/?spm_id_from=333.999.0.0
一、ChunJun 概述
ChunJun是一款易用、稳定、高效的批流统一的数据集成框架,可基于实时计算引擎Flink实现多种异构数据源之间的数据同步与计算,既可以采集静态的数据,比如MySQL,HDFS等,也可以采集实时变化的数据,比如Binlog,Kafka等。
目前的核心功能包括:
· 多源异构数据汇聚
作为一个开放式系统,用户可以根据需要开发新的插件,接入新的数据库类型,也可以使用内置的数据库插件。目前兼容30+异构数据源的数据读写与SQL计算。
· 断点续传
针对网络波动等异常情况,导致数据同步失败的任务,在下一次任务时自动从上一次失败的数据点进行数据同步,避免全部重跑。
· 数据还原
除了DML操作以外,一些源端数据库的DDL操作也能做到同步,最大程度保证源端数据库和目标端数据库的数据统一和结构统一,做到数据还原。
· 脏数据管理
数据传输过程中,因数据质量或主键约束等其他因素导致数据无法同步到目标数据库,针对这些脏数据进行统计和管理,便于后续进行脏数据分析。
· 速率控制
数据同步过程中,数据传输效率是关键。ChunJun针对各种场景,有的放矢地控制速率,最大程度保证数据同步的正常进行。
更多详见:
Github:https://github.com/DTStack/chunjun
Gitee:https://gitee.com/dtstack_dev_0/chunjun
官网:https://dtstack.github.io/chunjun/
ChunJun架构:
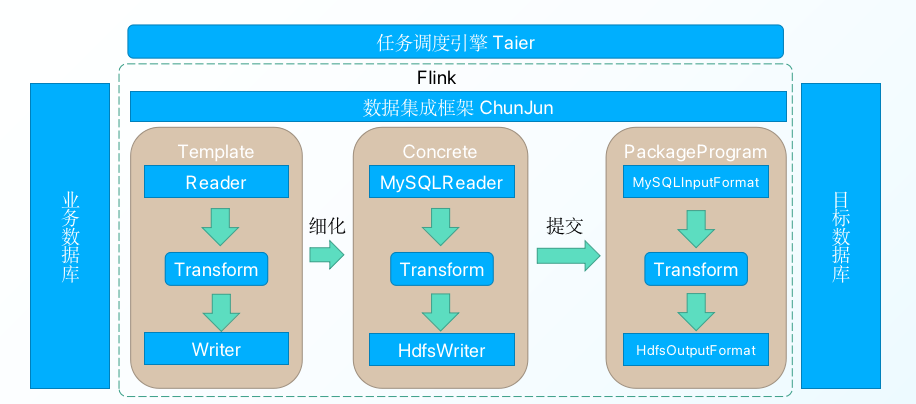
二、TIS 概述
TIS最早是基于Solr为用户提供一站式开箱即用、自助服务的搜索引擎中台产品。在2020年之前,当Flink和MPP引擎还没有形成影响力时 ,TIS就已经在为互联网企业内部提供实时OLAP分析需求的服务。
为满足大数据业务需求,快速将工具栈进行整合。TIS从2019年底开始转型,开始全方位支持现有实时数仓中台,从原先与搜索引擎强耦合的技术架构进行重构。从只处理搜索引擎一个场景,兼容到所有数据端的大数据生态场景。
经过TIS开发者的努力,现在的TIS内部有一套强大的元数据管理系统,根据用户需求大部分的工作脚本可自动生成(TIS是基于模型的DataOps,区别于市面上其他基于脚本任务的DevOps系统,摒弃掉所有繁琐的脚本操作),等到任务所需资源准备好,用户轻点数据系统就开始运行。
另外更为关键的是,TIS能够将专业大数据技术人员和大数据分析师这两种角色解耦。一个实时数仓中台,使用它的人并不需要了解里面的技术细节,并不需要知道Flink、Hive、Hadoop的技术细节,只要知道他们是干什么的就行。基于以上,TIS改造之初并没有针对实时数仓进行编码,而是花了将近一年时间对TIS产品底座进行构建,着重进行了以下几方面的构建:
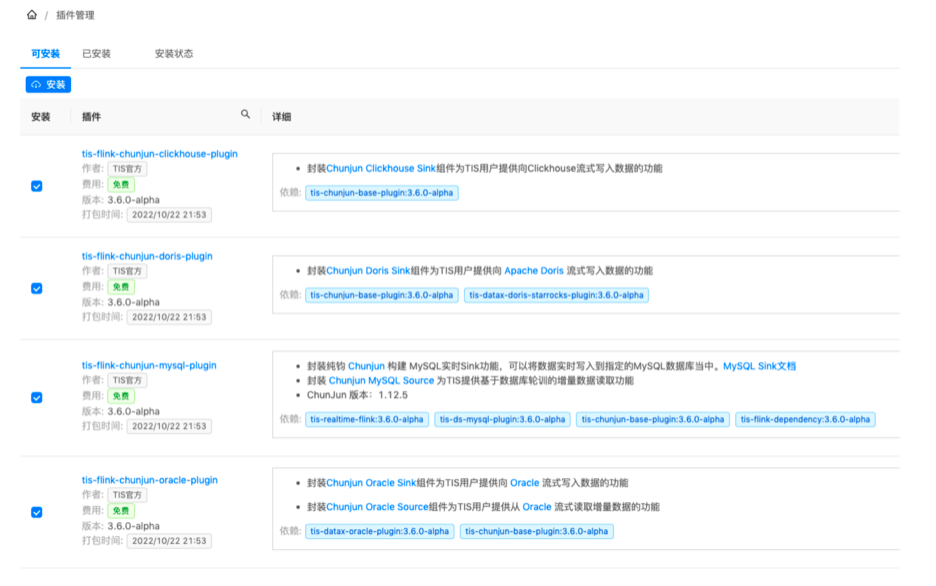
插件仓库/热生效机制
现有行业中提供的工具栈,需要在后台系统中自行部署,TIS则简化了这一流程,TIS在构建项目之时会统一将第三方的依赖包进行打包,预先部署到远端仓库中,用户在TIS中可以查看到可用插件清单。在使用时,只需鼠标点击下载且热生效就可使用,操作体验流畅。
全流程建模
针对ETL的各流程进行建模,将可变因素进行抽象,抽取成一个TIS系统中的扩展点,统一归档到TIS的主工程中,在主工程中没有任何具体业务代码的实现,这样在进行具体业务逻辑实现中就不需要更改任何主工程的代码,在架构层面最大限度地贯彻了OCP原则。
例如以下是对ETL中,针对结构化(支持JDBC接口)和非结构化数据源的执行流程图:
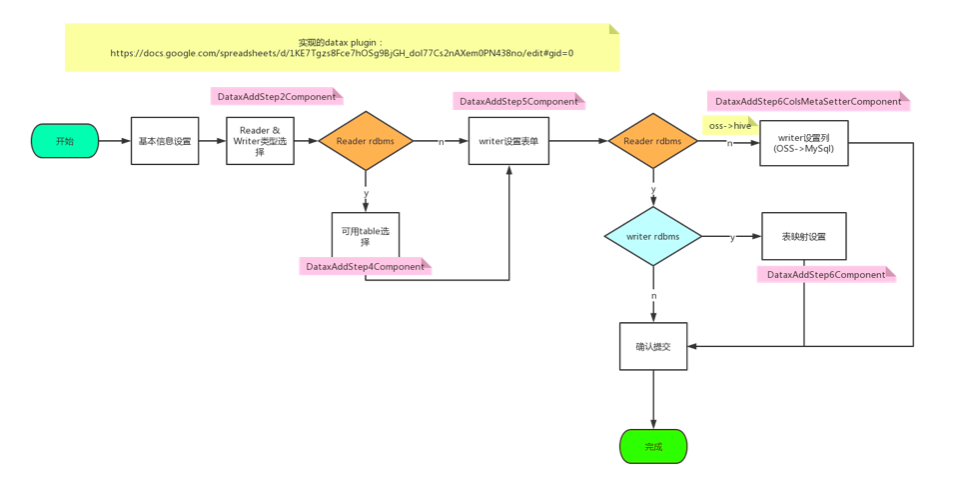
构建UI-DSL系统
随着整合进TIS的功能组件越来越多,需要单独开发的UI工作量巨大且风格难以统一,大量重新代码维护困难,同时由于行业分工精细化,流程需要前后端工程师相互协作,导致开发效率低,如何让没有前端开发经验的后端开发工程师,能够独立且畅快地完成一个UI组件的开发,成为一个重要的课题。为解决这个问题,TIS在底座中实现了一个UI-DSL的系统,后端开发工程师使用JAVA语言编写一个表单对应的MetaData脚本,里面定义表单的布局,输入项的校验等信息,运行期会自动将MetaData脚本渲染成前端的表单,从而完美解决这个课题。
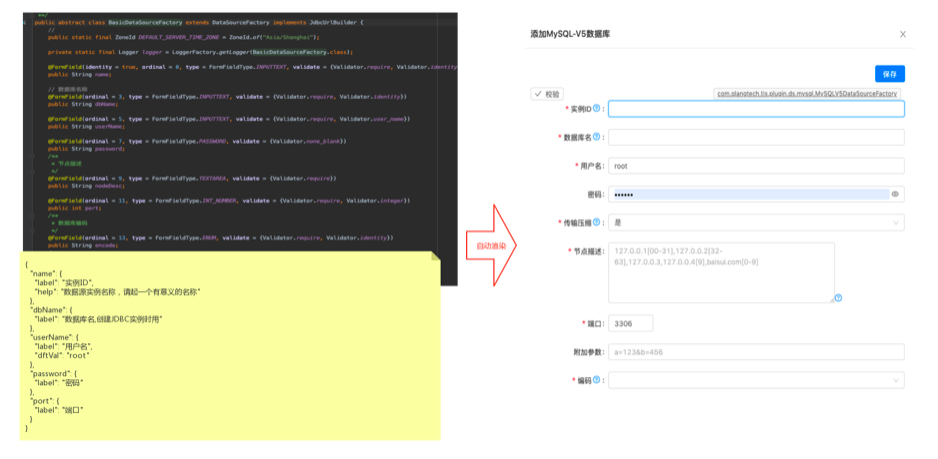
如上,是TIS中定义的MySQL数据源插件,只需要在对应POJO上为对应的属性添加FormFieldAnnotation标识,在配上字段对应的默认值、label等信息描述文件:
@FormField(ordinal = 3, // 表单中的排位顺序
type = FormFieldType.INPUTTEXT // 表单中控件类型
, validate = {Validator.require, Validator.identity}) // 输入项的校验规则
public String dbName;
DataSourceFactory.json
{ "dbName": {
"label": "数据库名",
"help": "数据库名,创建JDBC实例时用"
}}
三、整合 ChunJun 完善 TIS 生态
经过几个月时间的研发,TIS V3.6.0-alpha版本终于发布了。该版本的最大亮点,即整合了大数据领域数据同步工具的翘楚ChunJun,将TIS的业务能力提升到了新高度。
TIS的最新版本:
https://github.com/qlangtech/tis/releases/tag/v3.6.0-alpha
早在 V3.6.0-alpha之前,TIS已经整合了Alibaba DataX和 Flink-CDC。离线批量同步利用DataX组件实现,而在实时数据变更Source组件方面,TIS是基于Flink-CDC来实现的。至于Sink部分,则一直是基于各种数据端提供的生态API包经过二次开发完成的。
其中存在的问题是,开发周期长,调试困难,例如,仅仅为了实现StarRocks一个Sink端实现一个基于StreamFunction的Sink实现,连开发带测试花去了整整三个星期的时间。
直到整合ChunJun之后才解决了这些问题。ChunJun已经很好地支持了大数据领域的大部分数据端,包括Source和Sink。它的Source端基于Polling轮询机制来实现,相较与Flink CDC实现的Source端是有自己的特色的。
例如,并不是所有的端都支持类似MySQL binlog这样的实时同步机制,即使支持类似Oracle的LogMiner,如需开启,也需要专业Oracle DBA协助,不然设置权限就会吓退很多用户。而基于Polling机制的实时更新订阅却可以支持所有的Source端,只要实现了JDBC接口就行。
所以ChunJun的Source端通用性非常好,比之于Flink CDC的唯一劣势是实时性要低,不过一般在大部份OLAP的场景下用户对实时性的要求并没有那么高,所以一般情况下推荐使用ChunJun的Source来监听实时数据变更。
另外,ChunJun的Sink端实现也是一大特色,一般情况下数据端的生态产品中会提供Flink Sink的实现,例如:ElasticSearch的Flink官网提供了一个基于SinkFunction的实现,StarRocks在官网也提供了Sink实现。但是各家实现方式各不相同,没有一个统一的抽象模型。另外各厂商提供的实现中基本上只是一些半成品,像容灾、监控等都没有提供,导致TIS在整合各家Sink端时着实花了不少精力且很难做得完美。
因此在 TIS v3.6.0 中利用 ChunJun v1.12.5 全面改写了TIS原有的Sink端实现,由于ChunJun实现是一个封装好并且已经在生产环境中经过检验的,并且在实现方式上已经通过统一建模,每种端的接入方式可以统一,对TIS来说大大提高了整合开发效率,而且将容灾、监控、脏数据管理也一并实现。
ChunJun支持的Connector端非常丰富,TIS v3.6.0 中只是拣取了几个用户高频使用的端来封装,其他端的封装会在后续版本中逐步实现。以下是 v3.6.0版本中实现的端类型:
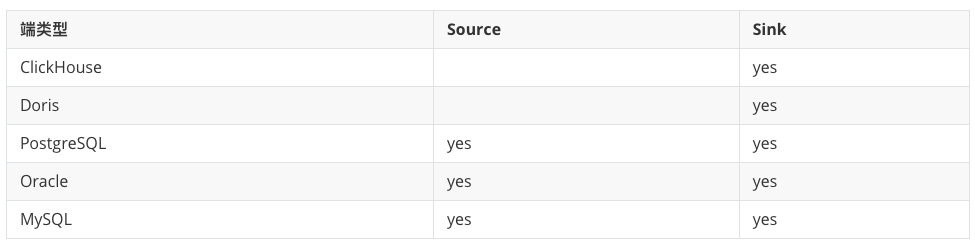
四、TIS 是如何整合 ChunJun
利用 TIS元数据管理系统接管 ChunJun流数据类型控制
ChunJun 流处理中构建的RowData实例是通过目标端Jdbc MetaData自动生成的(用户不需要在JSON配置文件中设置),内部需要通过目标端(Source/Sink)字段JDBC中的元数据信息的fieldType作为参数来映射 flink的DataType实例,调用的接口是com.dtstack.chunjun.converter.RawTypeConverter,
public interface RawTypeConverter {
DataType apply(String type);
}
在实际处理过程中发现,仅仅利用 JDBC col metaDatafieldType作为参数还是不够, 例如:MySQL的表定义为bigint,int,smallint的整型,当用户添加unsigned修饰,bigint在Flink中的映射类型需要从BigIntType变成DataTypes.DECIMAL,原smallint类型需要变成IntType,不然执行就会出错。另外像 Oracle的Jdbc内部实现了一套区别于Jdbc标准的类型规范oracle.jdbc.OracleTypes,当得到Oracle的类型之后需要归一化成Jdbc的类型java.sql.Types,不然没法正常执行。
类型映射虽然很简单,但由于Java是强类型语言,在流处理执行过程中稍有不慎就会出现ClassCastException,所以得格外小心地处理,因此TIS在ChunJun中引入了一个新的类型抽象com.qlangtech.tis.plugin.ds.ColMeta来封装Jdbc MetaData的列信息,在具体执行过程中可以更加细腻地控制Flink 内部的列类型。
public interface RawTypeConverter {
DataType apply(ColMeta type);
}
public class ColMeta implements Serializable {
public final String name;
public final DataType type;
public final boolean pk;
public ColMeta(String name, DataType type, boolean pk) {
this.name = name;
this.type = type;
this.pk = pk;
}
//...
}
public class DataType implements Serializable {
public final int type;
public final int columnSize;
public final String typeName;
// decimal 的小数位长度
private Integer decimalDigits;
public DataType(int type, String typeName, int columnSize) {
this.type = type;
this.columnSize = columnSize;
this.typeName = typeName;
}
/**
* is UNSIGNED
*/
public boolean isUnsigned() {
//...
}
}
取代基于JSON配置驱动的任务变为基于元数据模型驱动任务
有了TIS底层元数据关系管理的支持,数据同步任务定义的大部分工作可以自动生成,用户只需要做一些辅助工作,例如,用户需要导入一个张表,表有10列,用户需要做的是辅助确认:对于Source端确认表主键,Polling策略的轮询间隔时间及轮询列名,对于Sink端选取Insert的插入策略,这些都只需要点击鼠标就能完成,页面UI中的显示逻辑和ChunJun的规则相一致。
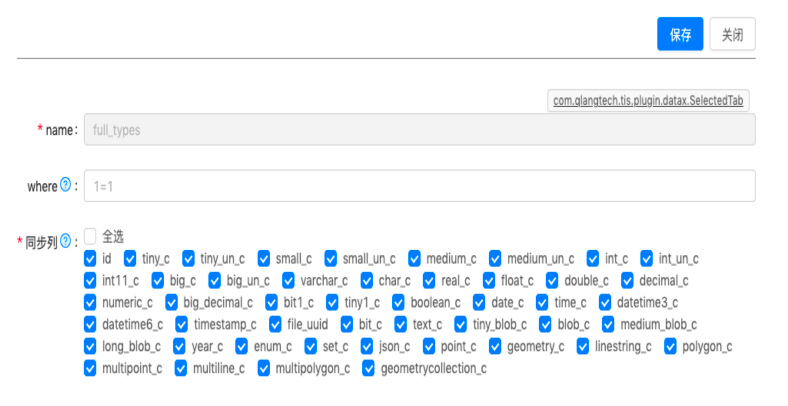
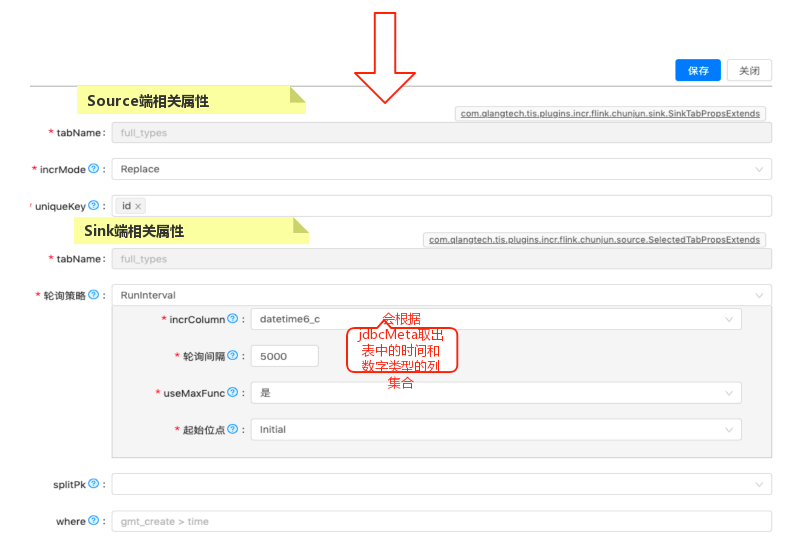
为ChunJun添加新的TIS扩展点
想要在 v3.6.0 版本顺利地将ChunJun Connector整合进TIS,需要添加两个功能扩展点,一是为增量Source端表的属性设置com.qlangtech.tis.plugins.incr.flink.chunjun.source.SelectedTabPropsExtends,二是为Sink端表的属性设置com.qlangtech.tis.plugins.incr.flink.chunjun.sink.SinkTabPropsExtends
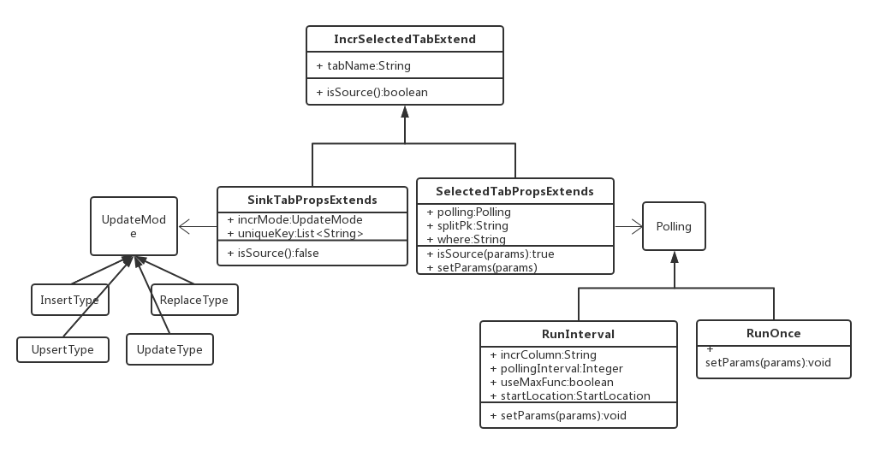
五、开源共建,繁荣生态
TIS的构建理念是坚决避免重复造轮子,必须站在行业的巨人的肩膀上,做大数据行业中优秀工具栈的粘合剂。TIS V3.6.0alpha 有幸能按时发布,得益于行业中有像ChunJun、DataX、Flink-CDC、Flink这样优秀的开源项目存在 ,使得TIS整体可靠性得到保障。特别要感谢Apache Flink,提供了一个强大的实时计算生态,Flink CDC、ChunJun和TIS都是生长在这个生态中的茁壮成长的小树苗,每个项目都专注于自己擅长的领域,且相互补充。
临近发布,发现一个很有意思的使用场景,那就是用户可以选择基于Flink-CDC的MySQL Source插件来监听MySQL 表的增量变更,将数据同步到以 ChunJun 构建的 Sink中去,这样的混搭使用方式给用户带来了更多的选择自由度,也避免了在Flink-CDC和ChunJun各自的框架内部重复造轮子从而造成生态内卷。
六、拥抱CloudNative
云原生(CloudNative)时代的到来为我们描绘了一副美好的画卷,对于终端用户来说提供了低成本、可靠的IT基础服务,可以专注于业务开发,这非常好。
但对于互联网技术从业者来说,似乎有隐忧,那就是互联网红利将会被阿里云这样的云厂商通吃,小厂商只有干瞪眼的份,那我们煞费苦心构建的像TIS这样的开源项目在云时代还有用武之地吗?其实这样的担心是多余的。
一个健康的生态,必须要保证生物多样性,生态中各个物种并不是独立,他们之间存在相互依存的关系。同样在大数据生态中如果只有像阿里云、亚马逊这样互联网大厂活得很滋润,并且构成了一个人才黑洞,把其他小厂的资源全部吸干了,想必这样的生态也不可能长远。
从本质来说,促成任何个人或组织之间的合作都有一个前提,那就是存在比较优势,就如同瞎子背瘸子相互协助前行,国家之间的合作也是,中国具有廉价劳动力和广阔的市场与发达国家的技术优势进行互补,这种合作是可持续的。
云大厂可以把昂贵的互联网基础设置,用集约化采购的规模优势大大地降低成本,然后用技术手段将这些设备云化成IAAS服务提供给客户,小厂技术具有灵活高效与较低的技术人员薪资成本优势,以这种优势在IAAS之上构建PAAS服务,类似任务调度,实时数仓非常合适。国外也已经有成功的案例,比如Snowflake提供的云原生实时数仓和亚马逊等云厂商之间的合作,有同学肯定会问:"为啥亚马逊不能自己搞一个像snowflake呢?",其实答案前面已经提到。
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
添加【小袋鼠:dtstack001】入qun,免费获取大数据&开源干货
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
开源共建 | TIS整合数据同步工具ChunJun,携手完善开源生态的更多相关文章
- Spark记录-阿里巴巴开源工具DataX数据同步工具使用
1.官网下载 下载地址:https://github.com/alibaba/DataX DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL.Oracle.SqlSe ...
- Linux实战教学笔记21:Rsync数据同步工具
第二十一节 Rsync数据同步工具 标签(空格分隔): Linux实战教学笔记-陈思齐 ---本教学笔记是本人学习和工作生涯中的摘记整理而成,此为初稿(尚有诸多不完善之处),为原创作品,允许转载,转载 ...
- Rsync数据同步工具
Rsync数据同步工具 什么是Rsync? Rsync是一款开源的.快速的.多功能的,可以实现全量及增量的本地或原程数据同步备份 ...
- rsync数据同步工具的配置
rsync数据同步工具的配置 1. rsync介绍 1.1.什么是rsync rsync是一款开源的快速的,多功能的,可实现全量及增量的本地或远程数据同步备份的优秀工具.Rsync软件适用于 unix ...
- 环境篇:数据同步工具DataX
环境篇:数据同步工具DataX 1 概述 https://github.com/alibaba/DataX DataX是什么? DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 ...
- 【基础】:Rsync数据同步工具
第二十一节 Rsync数据同步工具 1.1 Rsync介绍 1.1.1 什么是Rsync? 1.1.2 Rsync简介 1.3 Rsync的特性 1.1.4 Rsync的企业工作场景说明 1.2 Rs ...
- 数据同步工具Sqoop和DataX
在日常大数据生产环境中,经常会有集群数据集和关系型数据库互相转换的需求,在需求选择的初期解决问题的方法----数据同步工具就应运而生了.此次我们选择两款生产环境常用的数据同步工具进行讨论 Sqoop ...
- Linux系统备份还原工具4(rsync/远程数据同步工具)
rsync即是能备份系统也是数据同步的工具. 在Jenkins上可以使用rsync结合SSH的免密登录做数据同步和分发.这样一来可以达到部署全命令化,不需要依赖任何插件去实现. 命令参考:http:/ ...
- rsync---远程数据同步工具
rsync命令是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件.rsync使用所谓的“rsync算法”来使本地和远程两个主机之间的文件达到同步,这个算法只传送两个文件的不同部分,而 ...
- kafka2x-Elasticsearch 数据同步工具demo
Bboss is a good elasticsearch Java rest client. It operates and accesses elasticsearch in a way simi ...
随机推荐
- Netty源码—7.ByteBuf原理二
大纲 9.Netty的内存规格 10.缓存数据结构 11.命中缓存的分配流程 12.Netty里有关内存分配的重要概念 13.Page级别的内存分配 14.SubPage级别的内存分配 15.Byte ...
- 深度剖析 StarRocks 读取 ORC 加密文件背后的技术
作者:vivo 互联网大数据团队 - Zheng Xiaofeng 本文介绍了StarRocks数据库如何读取ORC加密文件,包括基础概念以及具体实现方案.深入探讨了利用ORC文件的四层结构和三层索引 ...
- php文件和文件夹操作类
文件和文件夹操作 移动 | 复制 | 删除 | 重命名 | 下载 <?php namespace Framework\Tools; use PharData; class FileManager ...
- 【Linux】1.1 Linux课程介绍
Linux课程介绍 1. 学习方向 linux运维工程师: 维护linux的服务器(一般大型企业) linux嵌入式工程师: linux做驱动开发,或者linux的嵌入式 linux下开发项目 2. ...
- cpp简单总结
1.简述智能指针的特点,简述new和malloc的区别. shared_ptr,显现共享式特点,多个同类型的shared指针可以共享一个对象,当持有者的计数归0,shared_ptr指向的指针就会被释 ...
- 使用Python解决氢原子问题
引言 大家好!今天我们将讨论一个非常经典的物理问题-氢原子问题,并使用 Python 来进行求解.氢原子问题是量子力学中的基础问题,它帮助我们理解原子内部的电子结构及其能量水平.通过这篇文章,大家将学 ...
- 🎀Java-Exception与RuntimeException
简介 Exception Exception 类是所有非致命性异常的基类.这些异常通常是由于编程逻辑问题或外部因素(如文件不存在.网络连接失败等)导致的,可以通过适当的编程手段来恢复或处理.Excep ...
- CTF靶场学习-XXE漏洞篇
XXE漏洞1(无限制) XXE特征:在HTTP的Request报文出现一下请求报文,即表明此时是采用XML进行数据传输,就可以测试是否存在XML漏洞. 默认xxe,没有任何限制,可以直接读取flag ...
- github项目收集
web模块 Nginx 监控模块vts: https://github.com/vozlt/nginx-module-vts
- AI Agent离我们有多远?认知革命的开始(上篇)
认知是成本最低的对冲. --张三思维进化论 深夜3点,我与AI Agent的惊人对话 2025年的一个深夜,我习惯性地打开电脑处理一些工作.身为一个从大厂转型的自由职业者,夜晚往往是我效率最高的时段. ...