Hive explain执行计划详解
简介:HIVE提供了EXPLAIN命令来展示一个查询的执行计划,这个执行计划对于我们了解底层原理,hive 调优,排查数据倾斜等很有帮助
一、EXPLAIN 参数介绍
语法 :
EXPLAIN [EXTENDED|CBO|AST|DEPENDENCY|AUTHORIZATION|LOCKS|VECTORIZATION|ANALYZE] querySql二、简单sum例子
2.1 执行计划查询Sql和结果
explain select sum(id) from dw.ods_bdg_db_statistics_compass_property where dt='20220627';
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: ods_bdg_db_statistics_compass_property
Statistics: Num rows: 7794 Data size: 31177 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int)
outputColumnNames: id
Statistics: Num rows: 7794 Data size: 31177 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: sum(id)
mode: hash
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
sort order:
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
value expressions: _col0 (type: bigint)
Reduce Operator Tree:
Group By Operator
aggregations: sum(VALUE._col0)
mode: mergepartial
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: true
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink2.2 执行计划最外层
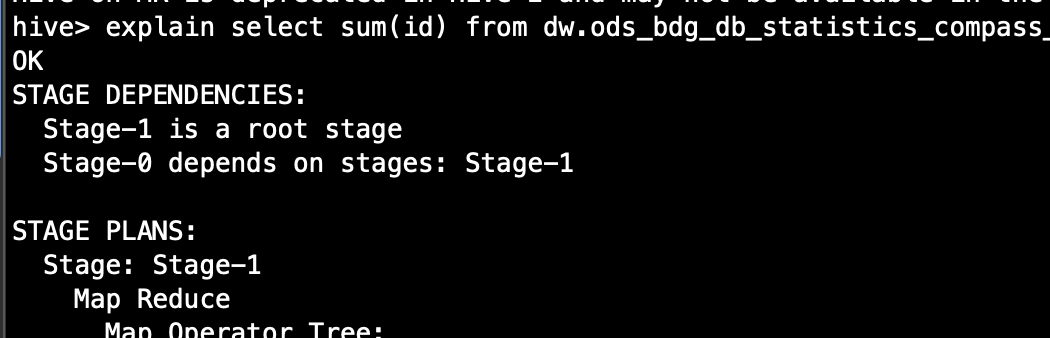
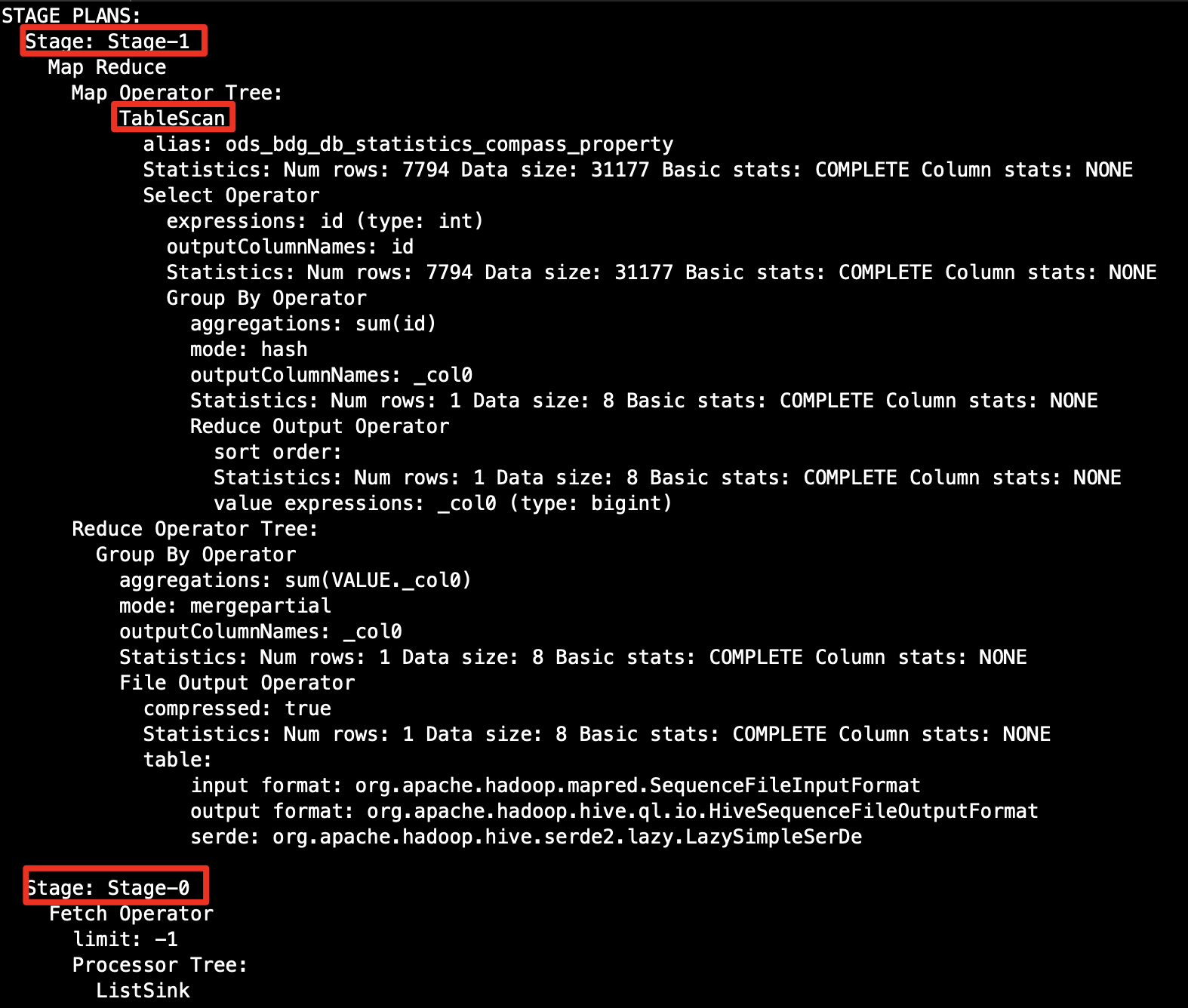
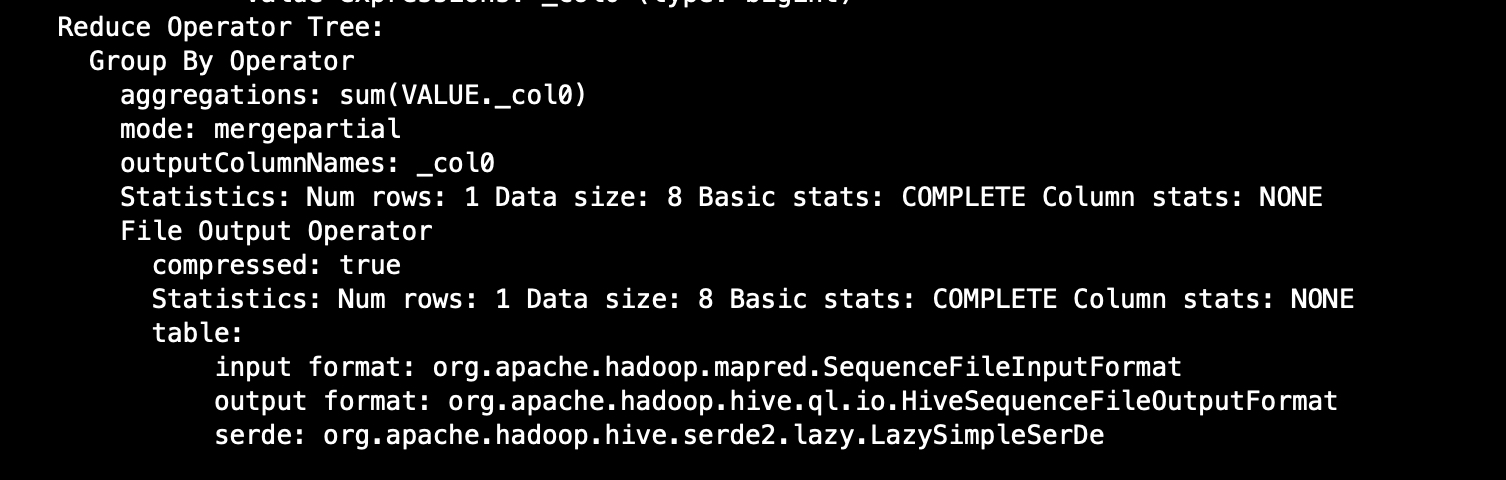
sql是sum,所以算子是group by
2.2.2.1.3 其它操作
例1
explain
SELECT
tab1.event_id,
tab2.id
from dw.ods_bdg_db_statistics_tab1 tab1
LEFT JOIN dw.ods_bdg_db_statistics_tab2 tab2
ON tab1.property_id = tab2.id and tab1.dt=tab2.dt
WHERE tab1.dt = '20220627'
and tab1.property_id=983
例2
explain
SELECT tab1.event_id,tab2.id
FROM (select dt,event_id,property_id from dw.ods_bdg_db_statistics_tab1 where dt = '20220627' and property_id=983) tab1
LEFT JOIN dw.ods_bdg_db_statistics_tab2 tab2
ON tab1.property_id = tab2.id and tab1.dt=tab2.dt
WHERE tab1.dt = '20220627' 生成的执行计划,该例子不带子查询性能要好些
left join不带子查询例子,tab2自动带筛选条件性能还高。子查询tab2没筛选,扫描数据量大一些
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: tab1
Statistics: Num rows: 789 Data size: 82063 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (property_id = 983) (type: boolean)
Statistics: Num rows: 394 Data size: 40979 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: property_id (type: int), dt (type: string)
sort order: ++
Map-reduce partition columns: property_id (type: int), dt (type: string)
Statistics: Num rows: 394 Data size: 40979 Basic stats: COMPLETE Column stats: NONE
value expressions: event_id (type: string)
TableScan
alias: tab2
Statistics: Num rows: 7794 Data size: 31177 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (id = 983) (type: boolean)
Statistics: Num rows: 3897 Data size: 15588 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: id (type: int), dt (type: string)
sort order: ++
Map-reduce partition columns: id (type: int), dt (type: string)
Statistics: Num rows: 3897 Data size: 15588 Basic stats: COMPLETE Column stats: NONE
Reduce Operator Tree:
Join Operator
condition map:
Left Outer Join0 to 1
keys:
0 property_id (type: int), dt (type: string)
1 id (type: int), dt (type: string)
outputColumnNames: _col1, _col10
Statistics: Num rows: 4286 Data size: 17146 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col1 (type: string), _col10 (type: int)
outputColumnNames: _col0, _col1
Statistics: Num rows: 4286 Data size: 17146 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: true
Statistics: Num rows: 4286 Data size: 17146 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSinkHive explain执行计划详解的更多相关文章
- MySQL性能分析, mysql explain执行计划详解
MySQL性能分析 MySQL性能分析及explain用法的知识是本文我们主要要介绍的内容,接下来就让我们通过一些实际的例子来介绍这一过程,希望能够对您有所帮助. 1.使用explain语句去查看分析 ...
- MySql——Explain执行计划详解
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
- ( 转 ) MySQL高级 之 explain执行计划详解
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
- MySQL高级 之 explain执行计划详解
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
- MySQL高级 之 explain执行计划详解(转)
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
- Mysql探索之Explain执行计划详解
前言 如何写出效率高的SQL语句,提到这必然离不开Explain执行计划的分析,至于什么是执行计划,如何写出高效率的SQL,本篇文章将会一一介绍. 执行计划 执行计划是数据库根据 SQL 语句和相关表 ...
- Hive底层原理:explain执行计划详解
不懂hive中的explain,说明hive还没入门,学会explain,能够给我们工作中使用hive带来极大的便利! 理论 本节将介绍 explain 的用法及参数介绍 HIVE提供了EXPLAIN ...
- 【夯实Mysql基础】mysql explain执行计划详解
原文地址 1).id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询. 2).select_type列常见的有: A ...
- mysql explain执行计划详解
1).id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询. 2).select_type列常见的有: A:simp ...
- explain 执行计划详解
id:id是一组数字,表示查询中执行select子句或操作表的顺序,如果id相同,则执行顺序从上至下,如果是子查询,id的序号会递增,id越大则优先级越高,越先会被执行. id列为null的就表是这是 ...
随机推荐
- 服务器安全之DenyHosts
情景:今天登录服务器,突然发现登录之后展示的信息有点多,仔细端倪发现: There were 3975 failed login attempts since the last successful ...
- Nuxt.js 应用中的 dev:ssr-logs 事件钩子
title: Nuxt.js 应用中的 dev:ssr-logs 事件钩子 date: 2024/11/28 updated: 2024/11/28 author: cmdragon excerpt: ...
- PythonDay3Advance
PythonDay3Advance 运算符 位运算符 进制: 将整数分了几种进制表示法 二进制:由0,1构成,逢2进1,以0b开头 八进制:由0,1,2,3,4,5,6,7构成,逢8进1,以0开头 十 ...
- 构造SLR语法分析表
构造SLR语法分析表 方法: 1)构造G'的规范LR(0)项集族 2)根据规则生成动作 3)生成转换 4)设置报错 /** * P157 规范LR(0)项集族 * @param grammar */ ...
- 记ios的input框获取焦点之后界面放大问题
在移动端开发项目中,发现页面在使用 iPhone 访问的时候,点击 input 和 textarea 等文本输入框聚焦 focus() 时,页面会整体放大,而且失去焦点之后页面不能返回原来的样子.检查 ...
- Pwn2own 2023 Tesla 利用链摘要
Pwn2own 2023 Tesla 利用链摘要 https://www.youtube.com/watch?v=6KddjKKKEL4 攻击链: 利用蓝牙协议栈自己实现的 BIP 子协议中的堆溢出, ...
- 【前缀和+开区间二分】codeforces 1187 B. Letters Shop
题意 第一行,输入一个正整数 \(n(1 \leq n \leq 2*10^5)\),代表字符串 \(s\) 的长度. 第二行,输入一个字符串 \(s\). 第三行,输入一个正整数 \(m(1 \le ...
- 中电金信:四川农担X中电金信大数据智能风控平台 护航金融服务乡村振兴
高质量金融服务是乡村振兴的重要支撑.四川省农业融资担保有限公司(以下简称"四川农担")持续探索融资担保服务,努力满足"三农"领域多样化.多层次融资担保需求的同 ...
- NoSQL 述评
作为主库的 nosql 只有 CockroachDB.TiKV 以及 MongoDB(从4.0后事务似乎可用了),CockrouchDB 已经收费,另外 YugabyteDB 也可选,但大家的反馈都不 ...
- 【数据结构】【冒泡排序法】Java写冒泡排序法
public class 冒泡 { public static int[] maopao(int[] arr){ for(int i=0;i<arr.length-1;i++){ for(int ...