Hive explain执行计划详解
简介:HIVE提供了EXPLAIN命令来展示一个查询的执行计划,这个执行计划对于我们了解底层原理,hive 调优,排查数据倾斜等很有帮助
一、EXPLAIN 参数介绍
语法 :
EXPLAIN [EXTENDED|CBO|AST|DEPENDENCY|AUTHORIZATION|LOCKS|VECTORIZATION|ANALYZE] querySql二、简单sum例子
2.1 执行计划查询Sql和结果
explain select sum(id) from dw.ods_bdg_db_statistics_compass_property where dt='20220627';
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: ods_bdg_db_statistics_compass_property
Statistics: Num rows: 7794 Data size: 31177 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int)
outputColumnNames: id
Statistics: Num rows: 7794 Data size: 31177 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: sum(id)
mode: hash
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
sort order:
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
value expressions: _col0 (type: bigint)
Reduce Operator Tree:
Group By Operator
aggregations: sum(VALUE._col0)
mode: mergepartial
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: true
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink2.2 执行计划最外层
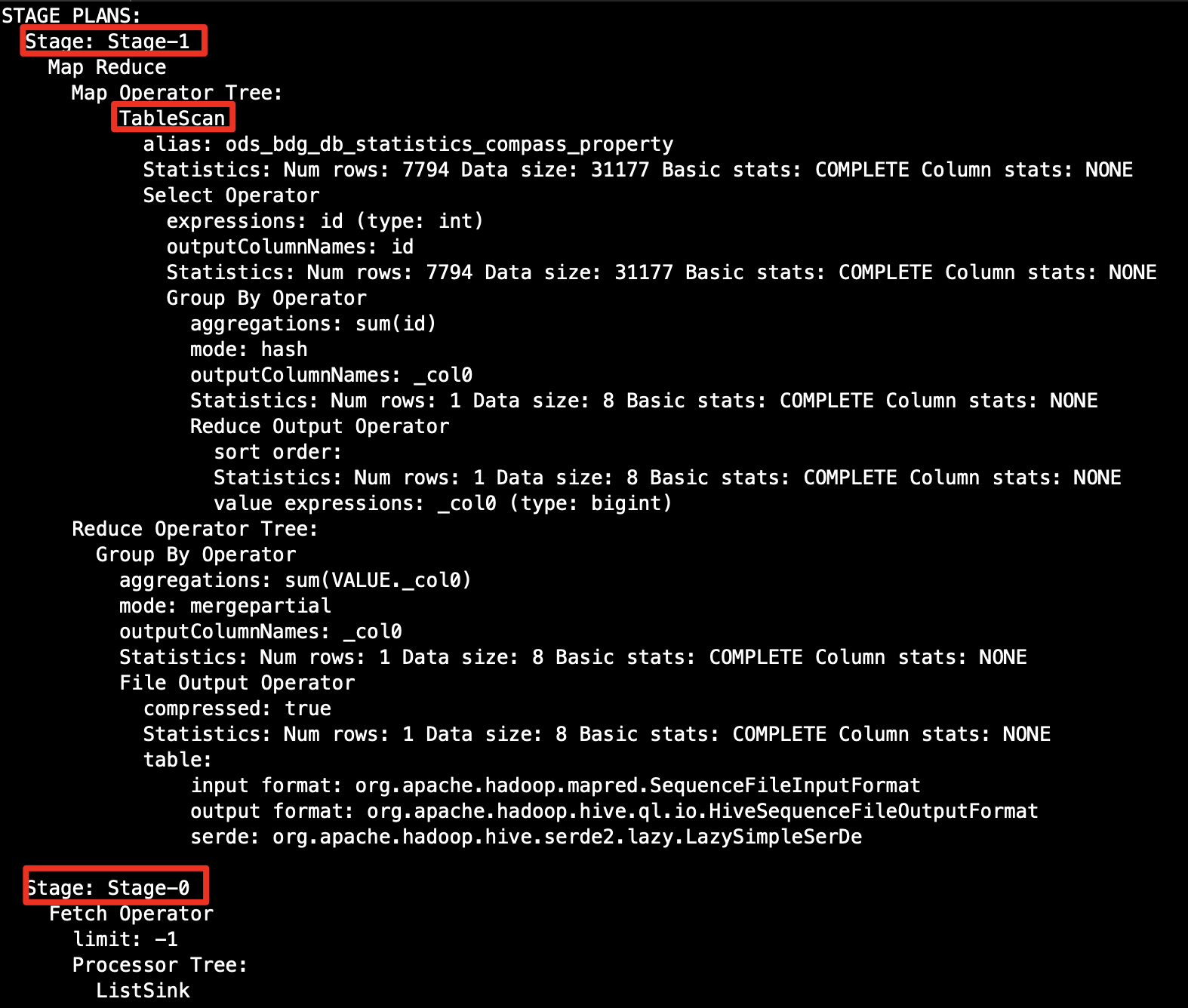
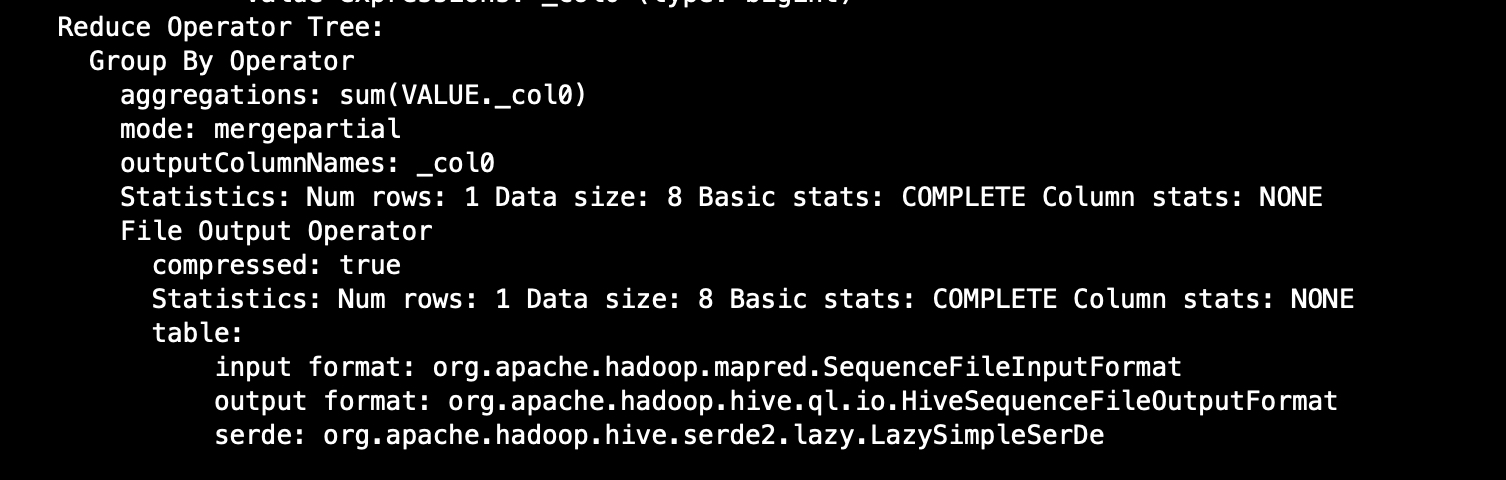
sql是sum,所以算子是group by
2.2.2.1.3 其它操作
例1
explain
SELECT
tab1.event_id,
tab2.id
from dw.ods_bdg_db_statistics_tab1 tab1
LEFT JOIN dw.ods_bdg_db_statistics_tab2 tab2
ON tab1.property_id = tab2.id and tab1.dt=tab2.dt
WHERE tab1.dt = '20220627'
and tab1.property_id=983
例2
explain
SELECT tab1.event_id,tab2.id
FROM (select dt,event_id,property_id from dw.ods_bdg_db_statistics_tab1 where dt = '20220627' and property_id=983) tab1
LEFT JOIN dw.ods_bdg_db_statistics_tab2 tab2
ON tab1.property_id = tab2.id and tab1.dt=tab2.dt
WHERE tab1.dt = '20220627' 生成的执行计划,该例子不带子查询性能要好些
left join不带子查询例子,tab2自动带筛选条件性能还高。子查询tab2没筛选,扫描数据量大一些
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: tab1
Statistics: Num rows: 789 Data size: 82063 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (property_id = 983) (type: boolean)
Statistics: Num rows: 394 Data size: 40979 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: property_id (type: int), dt (type: string)
sort order: ++
Map-reduce partition columns: property_id (type: int), dt (type: string)
Statistics: Num rows: 394 Data size: 40979 Basic stats: COMPLETE Column stats: NONE
value expressions: event_id (type: string)
TableScan
alias: tab2
Statistics: Num rows: 7794 Data size: 31177 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (id = 983) (type: boolean)
Statistics: Num rows: 3897 Data size: 15588 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: id (type: int), dt (type: string)
sort order: ++
Map-reduce partition columns: id (type: int), dt (type: string)
Statistics: Num rows: 3897 Data size: 15588 Basic stats: COMPLETE Column stats: NONE
Reduce Operator Tree:
Join Operator
condition map:
Left Outer Join0 to 1
keys:
0 property_id (type: int), dt (type: string)
1 id (type: int), dt (type: string)
outputColumnNames: _col1, _col10
Statistics: Num rows: 4286 Data size: 17146 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col1 (type: string), _col10 (type: int)
outputColumnNames: _col0, _col1
Statistics: Num rows: 4286 Data size: 17146 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: true
Statistics: Num rows: 4286 Data size: 17146 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSinkHive explain执行计划详解的更多相关文章
- MySQL性能分析, mysql explain执行计划详解
MySQL性能分析 MySQL性能分析及explain用法的知识是本文我们主要要介绍的内容,接下来就让我们通过一些实际的例子来介绍这一过程,希望能够对您有所帮助. 1.使用explain语句去查看分析 ...
- MySql——Explain执行计划详解
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
- ( 转 ) MySQL高级 之 explain执行计划详解
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
- MySQL高级 之 explain执行计划详解
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
- MySQL高级 之 explain执行计划详解(转)
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
- Mysql探索之Explain执行计划详解
前言 如何写出效率高的SQL语句,提到这必然离不开Explain执行计划的分析,至于什么是执行计划,如何写出高效率的SQL,本篇文章将会一一介绍. 执行计划 执行计划是数据库根据 SQL 语句和相关表 ...
- Hive底层原理:explain执行计划详解
不懂hive中的explain,说明hive还没入门,学会explain,能够给我们工作中使用hive带来极大的便利! 理论 本节将介绍 explain 的用法及参数介绍 HIVE提供了EXPLAIN ...
- 【夯实Mysql基础】mysql explain执行计划详解
原文地址 1).id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询. 2).select_type列常见的有: A ...
- mysql explain执行计划详解
1).id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询. 2).select_type列常见的有: A:simp ...
- explain 执行计划详解
id:id是一组数字,表示查询中执行select子句或操作表的顺序,如果id相同,则执行顺序从上至下,如果是子查询,id的序号会递增,id越大则优先级越高,越先会被执行. id列为null的就表是这是 ...
随机推荐
- TOML 1.0格式语法
github: https://github.com/BurntSushi/toml TOML 旨在成为一个语义显著而易于阅读的最低限度的配置文件格式.TOML 被设计地能够无歧义地转化为哈希表.TO ...
- Node.js 介绍和特点
1.node.js是什么 node.js不是一门语言,而是一个开发平台,是一个基于 Chrome V8 引擎的 JavaScript 运行环境. 何为开发平台:有对应的语言和实现特定功能的api 2. ...
- 在不同形式的for循环中使用break、continue、return的效果
我们在循环中,经常会有跳出循环,跳出本次循环继续下次循环等的场景,今天我们简单分享下.主要使用到的关键字是,break.continue.return.先将结果总结: ①在foreach中不能使用br ...
- AFL分析与实战
文章一开始发表在微信公众号 https://mp.weixin.qq.com/s?__biz=MzUyNzc4Mzk3MQ==&mid=2247486292&idx=1&sn= ...
- 【分块】LibreOJ 6282 数列分块入门6
题目 https://loj.ac/p/6282 题解 数据范围 \(1 \leq n \leq 10^5\),因此进行分块最多分 \(\sqrt{10^5} ≈ 318\) 块.且数据是随机生成的, ...
- win10重装如何跳过微软账号直接设置本地帐户
在添加你的帐户界面,选择脱机帐户 第二个页面,选择有限的体验 第三个页面,设置自己本地的用户名 第四个页面,设置自己本地的密码
- zz 云原生时代,Java的危与机
https://icyfenix.cn/tricks/2020/java-crisis/qcon.html 另一方面,在微服务的背景下,提倡服务围绕业务能力而非技术来构建应用,不再追求实现上的一致,一 ...
- 【SpringMVC】框架搭建
pom.xml 注意,下面代码只是pom.xml中的dependencies部分 <dependencies> <!-- 萌狼蓝天 mllt.cc--> <!-- htt ...
- Spring Boot 2.4 中文
Spring Boot 2.4 中文 https://runebook.dev/zh-CN/docs/spring_boot/spring-boot-features
- 【转载】Spring Cloud Gateway-路由谓词工厂详解(Route Predicate Factories)
http://www.imooc.com/article/290804 TIPS 本文基于Spring Cloud Greenwich SR2编写,兼容Spring Cloud Finchley及更高 ...