阿里云-数据库-表格存储Tablestore
入门篇一 初步调研了解
Step.1 场景锲合度判断
选择使用表格存储前关键需要明确你的场景是否适合。
表格存储是阿里云自2010起自研使用的一个多模型NoSQL数据库,面向海量大数据存储,身经百战。非常适合存储如下结构化/半结构化数据:

这些场景特点是:1. 数据规模大,常见的关系型数据库难以存储。2.需要支持很高的读写吞吐与极低的响应延迟。 3. 数据结构相对简单,无跨数据表的关联查询,数据存储写入是无需复杂的事务机制。
典型的案例推荐:
| 案例推荐 | 存储数据 |
|---|---|
| 打造亿量级订单管理解决方案 | 历史订单 |
| 现代IM中消息系统构建 | 聊天消息 |
| 管理海量快递轨迹数据架构实现 | 轨迹信息(时序数据) |
| 海量气象格点数据解决方案实战 | 气象监控(时序数据) |
| 百亿级全网舆情分析系统存储设计 | 爬虫信息 |
| 共享汽车管理平台 | Iot信息(元数据、时序数据) |
入门篇二、开通与构建数据
Step.1 开通产品,创建实例
表格存储是Serverless的产品,直接在产品详情页点击开通即可。开通产品不会有任何费用产生。
开通后可以立马在控制台创建实例,可以根据业务场景需求创建不同的实例类型,详情可以参考实例类型说明:
| 类型 | 使用场景 | 读性能 | 写性能 | 并发力 |
|---|---|---|---|---|
| 高性能实例 | 适用于对读写性能和并发都要求非常高的场景,例如游戏、金融风控、社交应用、推荐系统等。 | 高 | 高 | 高 |
| 容量型实例 | 适用于对读性能不敏感,但对成本较为敏感的业务,例如日志监控数据、车联网数据、设备数据、时序数据、物流数据、舆情监控等。 | 中 | 高 | 中 |
然后就可以在控制台中创建实例:控制台创建实例说明。
Step.2 选择数据模型,设计表结构
表格存储是一个多模态的数据库产品,支持多种数据模型适配不同的应用场景:
| 实例模型 | 适用场景 | 详情 |
|---|---|---|
| 宽行模型(WideColumn) | 表格存储数据模型,适合元数据、大数据场景 | 点击查看 |
| 时间线模型(Timestream) | 时序场景,如轨迹,监控等 | 点击查看 |
| 轻量级消息模型(Timeline) | 消息场景如IM,Feed流等 | 点击查看 |
| 格点模式(Grid) | 多维网格数据的存储、查询和管理。如 | 点击查看 |
可以根据实际使用场景选择不同的数据模型,这里需要注意的是宽行模型是当前表格存储的基础数据模型。其他的数据模型基于此封装输出。如果场景匹配度较高,可以直接使用后面封装完整的模式。当前也可以根据实际场景设计表结构。
如果使用宽行模型,表结构的设计是我们的能够发挥表格存储能力、满足业务需求的关键。需要考虑:
- 如何避免热点,提升整体服务能力,避免系统瓶颈
- 如何设计主键顺序,满足业务查询需求
入门篇三、基础数据的读写
在完成表设计,创建表以后既可以尝试写入数据。表格存储的读写接口都非常简单,可以简单分为单行数据操作与多行数据操作。详情参考数据基础读写。
| 操作类型 | 接口 | 说明 |
|---|---|---|
| 单行数据操作 (Java示例) |
GetRow | 读取一行数据。 |
| PutRow | 新写入一行数据 | |
| UpdateRow | 更新一行数据。 | |
| DeleteRow | 删除一行数据。 | |
| 多行数据操作 (Java 示例) |
BatchGetRow | 批量读取一个或多个表中多行数据。 |
| BatchWriteRow | 批量插入、更新或者删除一个或多个表中的多行数据。 | |
| GetRange | 读取表中指定主键范围内的数据。 |
进阶篇——多元索引
表格存储的宽行模型本身设计只提供了相对简单的数据查询能力,而由于业务场景的需求,往往需要较为多维度的查询需求(尤其是非主键查询)。而表格存储的索引能力能够满足该需求。我们将原本的数据称之为主表,在这个基础上面提供二级索引&多元索引能力。
| 索引类型 | 原理 | 场景 |
|---|---|---|
| 数据表主表 | 数据表类似于一个巨大的Map,它的查询能力也就类似于Map,只能通过主键查询。 | 适用于可以确定完整主键(Key)或主键前缀(Key prefix)的场景。 |
| 全局二级索引 | 通过创建一张或多张索引表,使用索引表的主键列查询,相当于把数据表的主键查询能力扩展到了不同的列。 | 适用于能提前确定待查询的列,待查询列数量较少,且可以确定完整主键或主键前缀的场景。 |
| 多元索引 | 使用了倒排索引、BKD树、列存等结构,具备丰富的查询能力。 | 适用于除数据表主键和全局二级索引之外的其他所有查询和分析场景。 |
可以根据上面的场景选择不同的索引能力,可以直接在控制台创建多元索引。
进阶篇——计算引擎的对接
表格存储中存储的多为数据中台类数据,除了面向TP类业务还是非常大的需求需要针对这部分数据进行分析处理。而当前产品已经与基本主流的计算引擎无缝对接,支持流、批等多种开源、阿里云产品生态。能够挖掘使用数据价值。
| 数据计算类型 | 使用文档(计算引擎选择) | 场景 |
|---|---|---|
| 批计算 | - Maxcompute - Spark - Hive/HadoopMR |
海量数据分析 |
| 流计算 | - Blink/Flink | 流式数据分析、清洗 |
| 交互式分析 | - DLA | 即席数据分析 |
| 事件触发(函数计算) | - 函数计算FunctionCompute | 数据清洗、同步等 |
进阶篇——数据实时消费通道
Tunnel能够实时捕获表内数据的变化,返回一个有序的行级的数据变更记录。提供全增量一体数据实时消费通道,高效完成数据全链路处理分析。
由于捕获数据变化的能力,可以方便的完成数据的迁移、流式计算、事件触发、数据消费等。尤其针对数据需要连续计算、清洗的场景,可以非常便捷的通过通道服务实现。
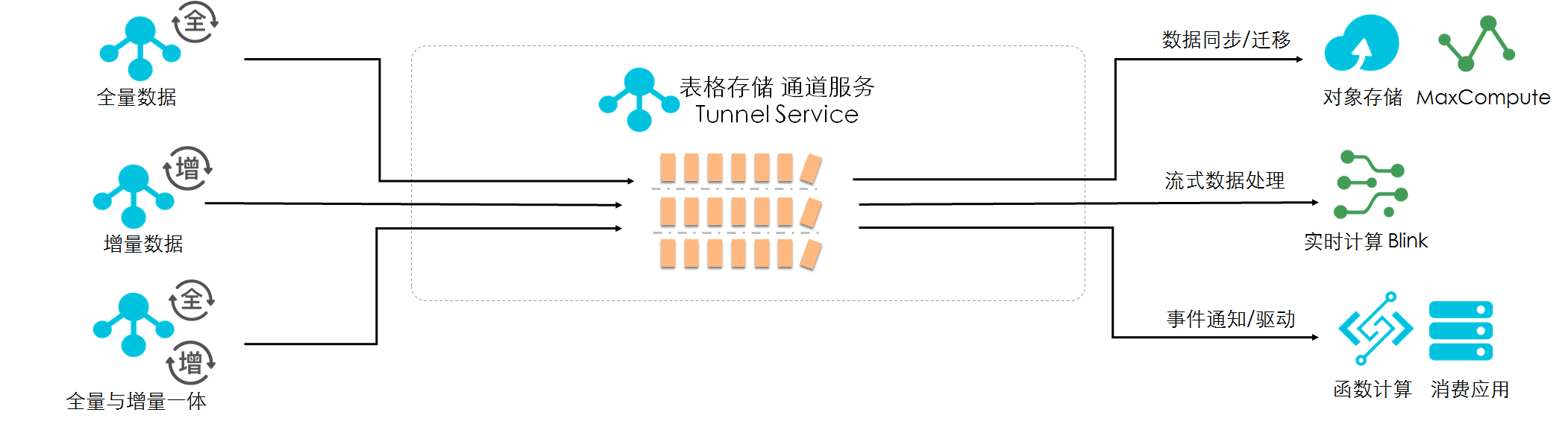
进阶篇——数据安全
这里简单总结了一些安全相关的功能点,涉及数据安全相关需求,可以参考这里:
| 功能点 | 解决问题 |
|---|---|
| VPC绑定 | 网络安全问题。限制实例仅仅被指定VPC网络访问 |
| 数据多版本 | 数据误操作等问题。提供多数据版本,支持读取指定版本数据。 |
| 访问权限管控(RAM&STS) | 访问权限问题。提供精细到API级别的权限管控能力。 |
Tablestore存储和索引引擎详解
前言
表格存储Tablestore是阿里云自研的面向海量结构化数据存储的Serverless NoSQL多模型数据库。Tablestore在阿里云官网上有各种文档介绍,也发布了很多场景案例文章,这些文章收录在这个合集中
《表格存储Tablestore权威指南》。值得一提的是,Tablestore可以支撑海量的数据规模,也提供了多种索引来支持丰富的查询模式,同时作为一个多模型数据库,提供了多种模型的抽象和特有接口。本文主要对Tablestore的存储和索引引擎进行介绍和解读,让大家对Tablestore引擎层的原理和能力,索引的作用和使用方式等有一个认识。
基本架构
Tablestore是一款云上的Serverless的分布式NoSQL多模型数据库,提供了丰富的功能。假设用户可以采用各种开源组件搭建一套类似服务,可以说是成本非常高昂,而使用Tablestore仅需在控制台上创建一个实例即可享受全部功能,而且是完全按量计费,可以说是0门槛。
整体架构如下图所示,本文不展开叙述每个模块的功能。
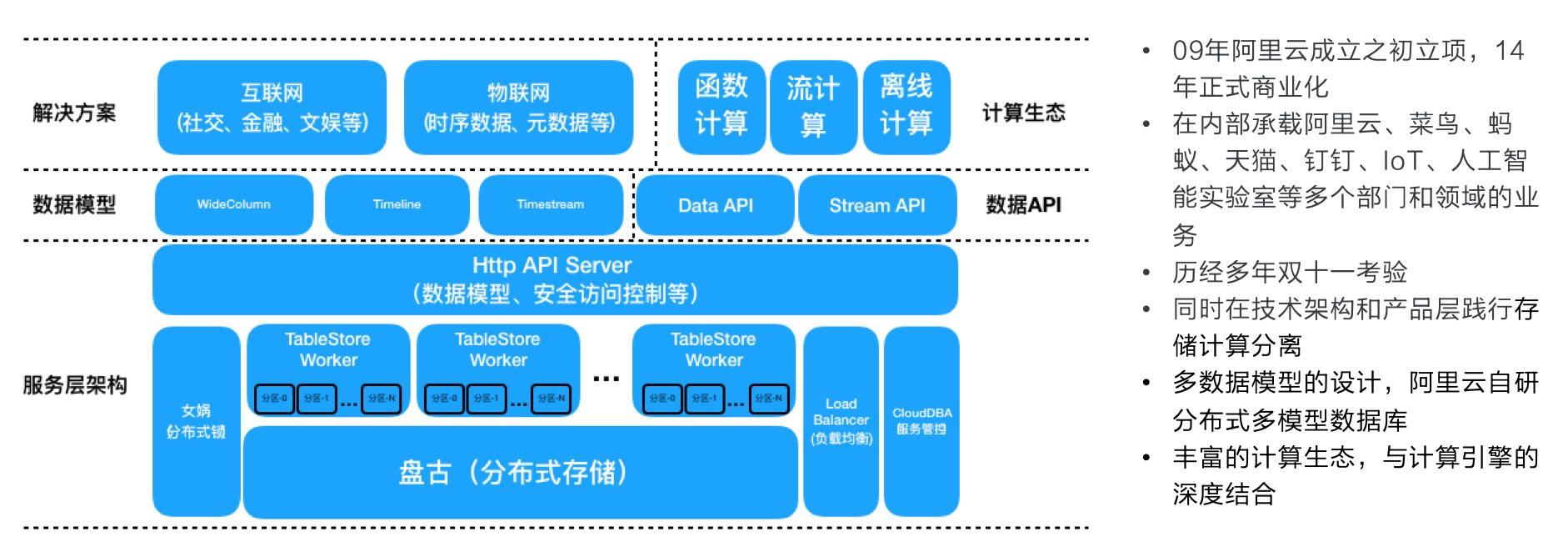
在服务端引擎层中,存在两个引擎:存储引擎和索引引擎。这两个引擎的数据结构和原理不同,为了方便读者理解,本文将这两个引擎称为表引擎(Table)和多元索引引擎(Searchindex)。整体来说,引擎层是基于LSM架构和共享存储(盘古),支持自动的Sharding和存储计算分离。
表引擎
表引擎的整体架构类似于Google的BigTable,在开源领域的实现有HBase等。
数据模型可以定义为宽行模型,如下图所示。其中不同的分区可以加载到不同的机器上,实现水平扩展:
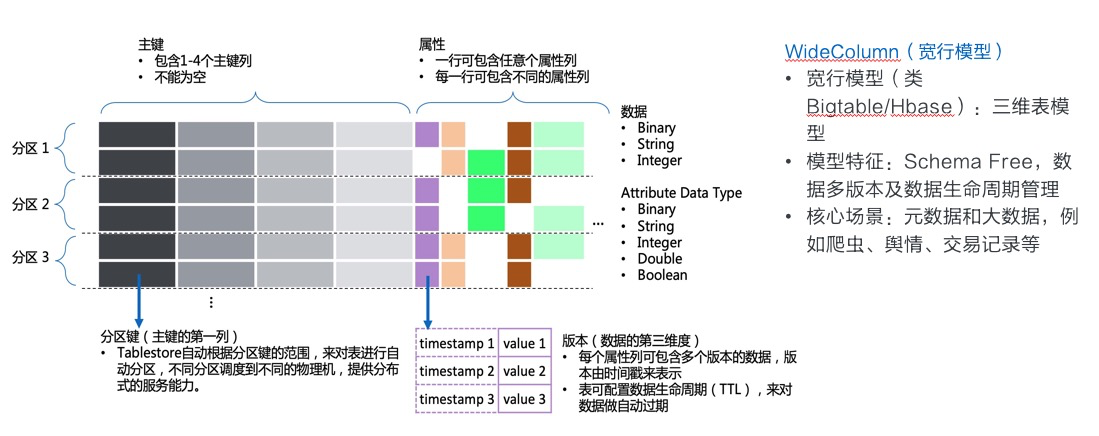
首先说明一下为什么Tablestore的主键可以包含多个主键列,而像HBase只有一个RowKey。这里有几点:
- 多列主键列按照顺序共同构成一个主键,类似MySQL的联合主键。如果使用过HBase,可以把这里的多列主键列,拼接起来看作一个RowKey,每一列其实都只是整体主键的一部分。
- 第一列主键列是分区键,使用分区键的范围进行分区划分,保证了分区键相同的行,一定在同一个分区(Partition)上。一些功能依赖这一特性,比如分区内事务(Transection),本地二级索引(LocalIndex, 待发布),分区内自增列等。
- 业务上常需要多个字段来构成主键,如果只支持一个主键列,业务需要进行拼接,多列主键列避免了业务层做主键拼接和拆解。
- 许多用户第一次看到多列主键列时,常会有误解,认为主键的范围查询(GetRange接口)可以针对每一列单独进行,实际上这里的主键范围指的是整体主键的范围,而非单独某一列的范围。
这个模型具有这样的一些优势:
- 完全水平扩展,因此可支撑的读写并发和数据规模几乎无上限。Tablestore线上也有一些业务在几千万级的tps/qps,以及10PB级的存储量。可以说一般业务达不到这样的上限,实际的上限仅取决于集群目前的机器资源,当业务数据量大量上涨时,只要增加机器资源即可。同时,基于共享存储的架构也很方便的实现了动态负载均衡,不需要数据库层进行副本数据复制。
- 提供了表模型,相比纯粹的KeyValue数据库而言,具有列和多版本的概念,可以单独对某列进行读写。表模型也是一种比较通用的模型,可以方便与其他系统进行数据模型映射。
- 表模型中,按照主键有序存储,而非Hash映射,因此支持主键的范围扫描。类似于HashMap与SortedMap的区别,这个模型中为SortedMap。
- Schema Free, 即每行可以有不同的属性列,数据列个数也不限制。这很适合存储半结构化的数据,同时业务在运行过程中,也可以进行任意的属性列变更。
- 支持数据自动过期和多版本。每列都可以存储多个版本的值,每个值会有一个版本号,同时也是一个时间戳,如果设置了数据自动过期,就会按照这个时间戳来判断数据是否过期,后台对过期数据自动清理。
这个模型也有一些劣势:
数据查询依赖主键。可以把这个数据模型理解为SortedMap,大家知道,在SortedMap上只能做点查和顺/逆序扫描,比如以下查询方式:
- 主键点查:通过已知主键,精确读取表上的一行。
- 主键范围查:按照顺序从开始主键(StartPrimaryKey)扫描到结束主键(EndPrimaryKey),或者逆序扫描。即对Table进行顺序或逆序遍历,支持指定起始位置和结束位置。
- 主键前缀范围查:其实等价于主键范围查,这里只是说明,主键前缀的一个范围,其实可以转换成主键的一个范围,在表上进行顺序扫描即可。
- 针对属性列的查询需要使用Filter,Filter模式在过滤大量数据时效率不高,甚至变成全表扫描。通常来说,数据查询的效率与底层扫描的数据量正相关,而底层扫描的数据量取决于数据分布和结构。数据默认仅按照主键有序存储,那么要按照某一属性列查询,符合条件的数据必然分布于全表的范围内,需要扫描后筛选。全表数据越多,扫描的数据量也就越大,效率也就越低。
那么在实际业务中,主键查询常常不能满足需求,而使用Filter在数据规模大的情况下效率很低,怎么解决这一问题呢?
上面提到,数据查询的效率与底层扫描的数据量正相关,而Filter模式慢在符合条件的数据太分散,必须扫描大量的数据并从中筛选。那么解决这一问题也就有两种思路:
- 让符合条件的数据不再分散分布:使用全局二级索引,将某列或某几列作为二级索引的主键。相当于通过数据冗余,直接把符合条件的数据预先排在一起,查询时直接精确定位和扫描,效率极高。
- 加快筛选的速度: 使用多元索引,多元索引底层提供了倒排索引,BKD-Tree等数据结构。以上面查询某属性列值为例,我们给这一列建立多元索引后,就会给这一列的值建立倒排索引,倒排索引实际上记录了某个值对应的所有主键的集合,即Value -> List, 那么要查询属性列为某个Value的所有记录时,直接通过倒排索引获取所有符合条件的主键,进行读取即可。本质上是加快了从海量数据中筛选数据的效率。
全局二级索引
全局二级索引采用的仍然是表引擎,给主表建立了全局二级索引后,相当于多了一张索引表。这张索引表相当于给主表提供了另外一种排序的方式,即针对查询条件预先设计了一种数据分布,来加快数据查询的效率。索引的使用方式与主表类似,主要的查询方式仍然是上面讲的主键点查,主键范围查,主键前缀范围查。常见的关系型数据库的二级索引也是类似的原理。
列举一个最简单的例子,比如我们有一张表存储文件的MD5和SHA1值,表结构如下:
| FilePath(主键列) | MD5(属性列) | SHA1(属性列) |
|---|---|---|
| oss://abc/files/1.txt | 0cc175b9c0f1b6a831c399e269772661 | 86f7e437faa5a7fce15d1ddcb9eaeaea377667b8 |
| oss://abc/files/2.txt | 92eb5ffee6ae2fec3ad71c777531578f | e9d71f5ee7c92d6dc9e92ffdad17b8bd49418f98 |
| oss://abc/files/3.txt | 4a8a08f09d37b73795649038408b5f33 | 84a516841ba77a5b4648de2cd0dfcb30ea46dbb4 |
通过这张表,我们可以查询文件对应的MD5和SHA1值,但是通过MD5或SHA1反查文件名却不容易。我们可以给这张表建立两张全局二级索引表,表结构分别为:
索引1:
| MD5(主键列1) | FilePath(主键列2) |
|---|---|
| 0cc175b9c0f1b6a831c399e269772661 | oss://abc/files/1.txt |
| 4a8a08f09d37b73795649038408b5f33 | oss://abc/files/3.txt |
| 92eb5ffee6ae2fec3ad71c777531578f | oss://abc/files/2.txt |
索引2:
| SHA1(主键列1) | FilePath(主键列2) |
|---|---|
| 84a516841ba77a5b4648de2cd0dfcb30ea46dbb4 | oss://abc/files/3.txt |
| 86f7e437faa5a7fce15d1ddcb9eaeaea377667b8 | oss://abc/files/1.txt |
| e9d71f5ee7c92d6dc9e92ffdad17b8bd49418f98 | oss://abc/files/2.txt |
为了确保主键的唯一性,全局二级索引中,会将原主键的主键列也放到主键列中,比如上面的FilePath列。有了上面两张索引表,就可以通过主键前缀范围查的方式里精确定位某个MD5/SHA1对应的文件名了。
多元索引引擎
多元索引引擎相比于表引擎,底层增加了倒排索引,多维空间索引等,支持多条件组合查询、模糊查询、地理空间查询,以及全文索引等,还提供一些统计聚合能力(统计聚合功能待发布)。因为功能较单纯的二级索引更加丰富,而且一个索引就可以满足多种维度的查询,因此命名为多元索引。
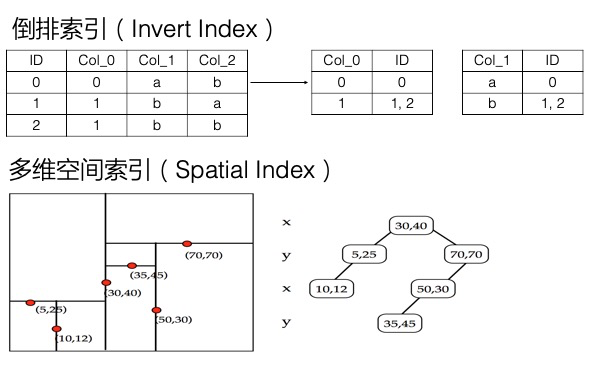
上面在讲解决Filter模式查询慢的问题时,提到倒排索引加快了数据筛选的速度,因为记录了某列的Value到符合条件的行的映射,Value -> List 。实际上,倒排索引这一方式,不仅可以解决单列值的检索问题,也可以解决多条件组合查询的问题。
我们举一个订单场景的例子,比如下表为一个订单记录:
| 订单号 | 订单(md5)(主键) | 消费者编号 | 消费者姓名 | 售货员编号 | 售货员姓名 | 产品编号 | 产品名 | 产品品牌 | 产品类型 | 下单时间 | 支付时间 | 支付状态 | 产品单价 | 数量 | 总价钱 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| o0000000000 | c49f5fd5aba33159accae0d3ecd749a7 | c0019 | 消陈九 | s0020 | 售楚十 | p0003004 | vivo x21 | vivo | 手机 | 2018-07-17 21:00:00 | 否 | 2498.99 | 2 | 4997.98 |
上面一共16个字段,我们希望按照任意多个字段组合查询,比如查询某一售货员、某一产品类型、单价在xx元之上的所有记录。可以想到,这样的排列组合会有非常多种,因此我们不太可能预先将任何一种查询条件的数据放到一起,来加快查询的效率,这需要建立很多的全局二级索引。而如果采用Filter模型,又很可能需要扫描全表,效率不高。折中的方式是,可以先对某个字段建立二级索引,缩小数据范围,再对其中数据进行Filter。那么有没有更好的方式呢?
多元索引可以很好的解决这一问题,而且只需要建立一个多元索引,将所有可能查询的列加入到这个多元索引中即可,加入的顺序也没有要求。多元索引中的每一列默认都会建立倒排,倒排就记录了Value到List的映射。针对多列的多个条件,在每列的倒排表中找到对应的List,这个称为一个倒排链,而筛选符合多个条件的数据即为计算多个倒排链的交并集,这里底层有着大量的优化,可以高效的实现这一操作。因此多元索引在处理多条件组合查询方面效率很高。
此外,多元索引还支持全文索引、模糊查询、地理空间查询等,以地理空间查询为例,多元索引通过底层的BKD-Tree结构,支持高效的查询一个地理多边形内的点,也支持按照地理位置排序、聚合统计等。
索引选择
不是一定需要索引
- 如果基于主键和主键范围查询的功能已经可以满足业务需求,那么不需要建立索引。
- 如果对某个范围内进行筛选,范围内数据量不大或者查询频率不高,可以使用Filter,不需要建立索引。
- 如果是某种复杂查询,执行频率较低,对延迟不敏感,可以考虑通过DLA(数据湖分析)服务访问Tablestore,使用SQL进行查询。
全局二级索引还是多元索引
- 一个全局二级索引是一个索引表,类似于主表,其提供了另一种数据分布方式,或者认为是另一种主键排序方式。一个索引对应一种查询条件,预先将符合查询条件的数据排列在一起,查询效率很高。索引表可支撑的数据规模与主表相同,另一方面,全局二级索引的主键设计也同样需要考虑散列问题。
- 一个多元索引是一系列数据结构的组合,其中的每一列都支持建立倒排索引等结构,查询时可以按照其中任意一列进行排序。一个多元索引可以支持多种查询条件,不需要对不同查询条件建立多个多元索引。相比全局二级索引,也支持多条件组合查询、模糊查询、全文索引、地理位置查询等。多元索引本质上是通过各种数据结构加快了数据的筛选过程,功能非常丰富,但在数据按照某种固定顺序读取这种场景上,效率不如全局二级索引。多元索引的查询效率与倒排链长度等因素相关,即查询性能与整个表的全量数据规模有关,在数据规模达到百亿行以上时,建议使用RoutingKey对数据进行分片,查询时也通过指定RoutingKey查询来减少查询涉及到的数据量。简而言之,查询灵活度和数据规模不可兼得。
关于使用多元索引还是全局二级索引,也有另外一篇文章描述:《Tablestore索引功能详解》。
除了全局二级索引之外,后续还会推出本地二级索引(LocalIndex),推出后再进行详细介绍。
常见组合方案
丰富的查询功能当然是业务都希望具备的,但是在数据规模很大的情况下,灵活的查询意味着成本。比如万亿行数据的规模,对于表引擎来说,因为水平扩展能力很强,成本也很低,问题不大,但是建立多元索引,费用就会非常高昂。全局二级索引成本较低,但是只适合固定维度的查询。
常见的超大规模数据,都带有一些时间属性,比如大量设备产生的数据(监控数据),或者人产生的数据(消息、行为数据等),这类数据非常适合采用Tablestore存储。对这类数据建立索引,会有一些组合方案:
对元数据表建立多元索引,全量数据表不建立索引或采用全局二级索引。
- 元数据表可以是产生数据的主体表,比如设备信息表,用户信息表等。在时序模型中,产生数据的主体也可以认为是一个时间线,这条线会不断的产生新的点。
- Tablestore的时序数据模型(Timestream)采用的也是类似的方式,对时序数据中的时间线建立一张表,专门用来记录时间线的元数据,每个时间线一行。时间线表建立多元索引,用来做时间线检索,而全量数据则不建立索引。在检索到时间线后,对某个时间线下的数据进行范围扫描,来读取这个时间线的数据。
热数据建立多元索引,老数据不建立索引或者采用全局二级索引:
- 很多情况下仅需要对非常热的数据进行多种维度查询,对冷数据采取固定维度查询即可。因此冷热分离可以给业务提供更高的性价比。
- 目前多元索引还不支持TTL(后续会支持),需要业务层区分热数据和冷数据。
Tablestore表设计最佳实践
什么是Tablestore
Tablestore是阿里云上的一款Serverless NoSQL多模型数据库(官网页面)。
Tablestore广泛应用在各种业务场景中,这些场景案例有一些实践文章介绍,文章收录在合集《表格存储Tablestore权威指南》。
产品架构可参考下图:
为什么需要最佳实践
作为一个数据库产品和云服务,简单好用是很大的一个竞争力,简单好用往往也意味着使用者不需要关心太多数据库原理或者表设计,能够直接上手。确实,很多用户是看了Tablestore的场景案例文章,直接创建一个Tablestore实例开始测试,熟悉常用接口后,很快实现了一套基于Tablestore的架构来满足业务需求,也没有遇到什么问题。
那么什么时候特别需要根据最佳实践进行设计呢?
数据规模大,应对海量数据仍需要在数据库功能或表设计上做一些取舍。
- 数据库产品的功能丰富度和数据规模存在着矛盾。即针对PB级数据设计的架构和功能,在查询丰富度上就会有取舍,难以满足非常灵活的查询。另一方面,选择了非常灵活的查询方式,可能也意味着数据整体规模存在着瓶颈,或者是成本较高。因此用户还是不可避免的面临数据库选型或者是功能选型。
- 分布式数据库需要做sharding,而sharding方式一般跟用户表设计或者用户数据相关。数据规模小时,数据倾斜问题不大,而数据规模大到一定程度,用户就需要关心这一问题。
- 数据库的整体性能跟用户的使用方式、业务代码的质量等有很强的关系。有时,业务层感受到的数据库性能取决于业务层的DBA或者架构师对于数据库的了解和自身的代码水平。加深对数据库的了解,可以让大家更好的应用这一产品。
为什么选型Tablestore
上面讲了什么是Tablestore,在讲怎么用Tablestore之前,我们先看下为什么选择Tablestore。为什么用Tablestore其实是一个大话题,Tablestore提供了非常丰富和通用的功能,也有一些独特的功能特性,可以见最上面的架构图,
这里简单提供一些选择Tablestore的理由:
- 完全0运维,即开即用、按量付费。Tablestore是阿里云上唯一一个Serverless的数据库,用户不需要预定任何资源来搭建服务,整个平台完全为你所用,只需要为使用量付费。实际上我们有一些免费额度,很多用户常年使用Tablestore,但一直在免费额度内免费使用。许多人没有使用过一些开源领域内针对大数据的数据库产品,原因就在于这些产品依赖很多,也需要很多资源来部署,运维成本也比较高。Tablestore提供了完全0门槛的方式,来满足你的大数据需求。
- 适用于多种工作负载,提供水平扩展能力(scalability)的同时提供丰富查询能力。NoSQL阵营有很多产品,各有所长,Tablestore天生为大数据设计,满足PB级数据的存储和查询,同时通过全局二级索引、多元索引等功能扩充查询能力,满足多种工作负载和查询需求。
- 一个产品解决多种需求,减少业务层维护多产品的负担和数据同步负担。很多业务为了满足不同查询需求,组合使用MySQL、HBase、Elasticsearch等多款产品,并在这些产品之间进行数据同步。了解到Tablestore具有多种能力后,一些用户开始迁移到Tablestore,通过一个产品满足多种需求,也彻底解决了数据同步的负担。
- 提供多模型和丰富场景案例,以及专家在线支持。我们针对特定领域提供了特定的模型,简化业务的设计和开发,比如消息和feed流领域提供Timeline模型,时序数据提供Timestream模型,科学大数据的多维格点数据提供Grid模型等。针对典型的场景,定期推出场景案例文章,并提供代码示例。建立专门的用户支持大群和针对特定客户的支持小群,研发人员轮班来进行技术支持和答疑工作,也帮助用户进行方案设计。
- 平台化功能演进,与大数据生态对接,提供数据通道等。Tablestore是阿里云上的自研产品,也在不断的向着多模型和平台化的方向演进,提供更多的功能,与各种生态对接,提供领域化的解决方案。用户使用Tablestore后,即可不断享受最新的技术红利,这也是云计算的优势。
业务的一般接入流程
假设你有一块业务打算用Tablestore来作为数据库。简单想象一下业务接入Tablestore的过程,首先可能是通过《表格存储Tablestore权威指南》中找到类似自己业务场景的解决方案,了解这一方案的实现方式,直接对照这一方案进行实现,然后接入业务数据进行测试和验证,最终上线业务。或者是在了解了一些场景案例后,开始分析自己的业务需求,设计业务表结构,然后编码实现,最终测试验证并上线。
总之,可能会经历这样的几个过程:了解Tablestore(场景案例和文档)、业务需求分析、表结构和查询方案设计、编码实现、测试上线。
这个过程也分两种情况:
- 业务场景可以直接套用Tablestore提供某种模型,比如Timeline、Timestream、Grid这些模型。这时候不需要进行特别的表结构设计,直接套用模型即可,开发时也使用特定模型的SDK接口。
- 业务场景无法套用模型,此时需要根据业务需求和场景进行表结构和查询方案设计。这个过程因场景而异,有些场景比较简单,不用特别设计,比如简单的KeyValue模式进行存取。有些场景会比较复杂,比如数据规模很大,且查询方式多样,这时候需要一些特别的设计。
Tablestore提供有专门的钉钉技术交流群(群号11789671),在业务接入的任何阶段,有任何问题都欢迎咨询。
表设计
数据散列
怎么看待散列问题
分布式数据系统中,大部分都会提到数据散列这个问题,散列的目的是让数据分布更均匀,避免热点。假设数据分布不均匀,会出现以下问题:
- 数据写入和读取能力受限于单个分区的能力,或者是单机能力,存在明显瓶颈。
- 在某些数据处理场景下,热点或者数据分布不均会导致明显的长尾效应,拖慢整体速度。
- 某个数据系统或者模块往往仅仅是整个业务链路上的一环,热点会拖慢整个上下游的速度。
通常来讲,分布式数据库系统中,理想的数据和负载情况是:数据均匀分布,水平方式切分为很多分区,分布在不同机器上,读写压力也水平分散,每个请求的压力仅覆盖局部的一小部分,而不是整体。这种模式下完全水平扩展,业务压力增加,只需要增加机器资源即可。
在业务设计上,应当尽量避免会导致数据热点的设计,在未来负载可支撑的情况下兼顾业务需求。有时业务需求会与数据均匀相矛盾,比如要按照时间全局有序的查询整个表最近写入的数据,那就与数据写入分散的原则有一些冲突。如果要让新写入的数据都集中在一起,系统就存在扩展瓶颈,那么在当前以及未来能否支撑这样的负载,未来系统的最大的写入TPS可能是多少,这些就是业务架构师需要考虑的问题。如果这种模式无法支持未来的负载,就意味着必须更改设计,否则是为当下或者将来埋坑。
另一方面辩证的来看,如果业务需求很低,比如对于Tablestore的tps/qps都在1000以下,整体数据在10GB下,且未来也不会有大的增长,那么热点问题也不是一个需要花太多精力考虑的问题,这样的负载单分区完全可以支撑。实际上,单分区也可以达到几万行/s的写入,但是架构设计上不要依赖单分区能力,尽量控制在很安全的水平内。
一类常见热点
一个常见的热点例子,比如下表。这个表中主键有两列,分别是Timestamp和MachineIp,这是一个简单的监控场景的例子,每次存储某个机器某个时间的一些指标值。
| Timestamp(主键列1,分区键) | MachineIp(主键列2) | Metrics(属性列) |
|---|---|---|
| 1563617365001 | 10.10.10.1 | {"cpu":10.0, "net_in": 10.0} |
| 1563617365002 | 10.10.10.2 | {"cpu":11.0, "net_in": 20.0} |
| 1563617365003 | 10.10.10.3 | {"cpu":12.0, "net_in": 30.0} |
这个表设计有很明显的热点问题,每次数据写入都是在表的末尾追加数据,而数据是按照分区键的范围进行分区的,也就是每次数据写入都会写入最后一个分区,而无法把写入负载平衡到多台机器上。这种情况下,单分区的写入能力就是整个表的写入能力上限,更重要的是,一旦发生热点,无法通过分片分裂来平衡负载,因为写入压力总是在写尾部。
一种较分散的方式
针对上面的问题,一个可以让写入更分散的方式是把MachineIp放到主键列的第一列,Timestamp放到第二列。
这样就把写入压力按照Machine这个级别进行了分散,即写入的是每个Machine的尾部,大部分情况下也足够分散了。
有一种局部热点情况,假设10.10.0.0/16这个网段的机器写入量很大,而Tablestore是按照分区键的一个范围进行分区,刚好这些机器又都分在一个分区内,会不会产生热点呢?如果写入压力超过或接近单分区的上限,确实是一个热点,但是Tablestore具备自动负载均衡的能力,会自动将这个分区进行切分(Split),使得压力平均到两个分区上,如果仍不够会继续进行切分。
类似MachineIp这种分区键是很常见的一种分区方式,即把某个业务上比较分散的Key放到第一列,比如UserId,DeviceId、OrderId等等。这种模式只要这个Key本身比较分散,一般无太大问题。
更分散的方式: 拼接MD5
上面的例子中,也可以通过拼接MD5的方式将ip本身的顺序打散,这种方式也较为常用。比如对ip计算md5,然后在
ip前面拼接md5的前4位,如下图:
| MachineIp(主键列1,分区键) | Timestamp(主键列2) | Metrics(属性列) |
|---|---|---|
| 7552_10.10.10.2 | 1563617365000 | {"cpu":10.0, "net_in": 10.0} |
| 7552_10.10.10.2 | 1563617365001 | {"cpu":10.0, "net_in": 10.0} |
| 8d9c_10.10.10.3 | 1563617365003 | {"cpu":10.0, "net_in": 10.0} |
| 8d9c_10.10.10.3 | 1563617365004 | {"cpu":10.0, "net_in": 10.0} |
| e5a3_10.10.10.1 | 1563617365000 | {"cpu":10.0, "net_in": 10.0} |
这种方式可以避免某个ip段的热点,同时在结构上具备一定的模式,即以16进制字符串开头,这样有利于系统进行预分区。
解决顺序性的问题
回到最初的例子中,很多用户以Timestamp作为第一个主键列,是希望数据全局按照时间排序,这样可以按照时间范围进行查询,但是这种方式导致了尾部热点,给系统能力扩展带来了瓶颈。
那么怎么解决对顺序性的要求呢?
- 方法一:业务设计上避免对全局顺序性的要求,改为局部顺序性,比如上面的例子,在某个MachineIp下,数据仍是按照Timestamp有序的。即先通过一个字段来打散数据,再按照某种顺序查询。
- 方法二:业务上采用分桶的方式,分散写入压力,在读取时从每个桶查询再合并。比如采用16个桶,每次写入时把时间对16取模,余数放到第一个主键列(0到15),时间放到第二个主键列。在读取时,从每个桶读取后合并即可。这种方式可以把压力分散到不同的桶上,能有多么分散取决于有多少个桶。在读取时需要对所有桶进行读取,可以采用并行读取的方式进行加速。
- 方法三:表上仍然采用均匀的方式写入数据,给表建立一个多元索引,通过多元索引进行Timestamp等字段的有序查询。多元索引在数据分布上本身会进行一次散列,分成多个分片,查询时自动从多个分片合并数据。
其余主键设计问题
- 主键的第一个字段为分片键,分片键首先考虑散列问题,上一节已经讲过。
- 同一个分区键(分区键为第一列主键列)下数据不宜过多,比如10GB内(无硬性限制),因为相同分区键的行无法再进行分裂。这里相同分片键,指定的是对于第一列主键列的某个确定的值。对应上文的例子,即某个机器下的数据尽量不要超过10GB。
- 主键列的长度限制为1KB,尽可能使用较短的主键,有利于加快查询速度。
- 主键列是有先后顺序的,根据查询需求设计主键列的顺序。如果要按照不同的几种主键列顺序进行范围查询,考虑使用全局二级索引。如果有各种条件组合查询需求,考虑使用多元索引。
属性列
- Tablestore支持宽行,即一行可以非常宽,比如几十万个属性列。但是很宽的行,如果一次性读取,可能会读不出(超时),需要指定列或者分页读取某些列。因此,原则上不太建议非常宽的行(万列以上),可能会使某些功能受限。
- 属性列有2MB的限制,如果要保存的数据超过这一限制,需要把数据拆分成多列保存。、
索引选择
Tablestore存储引擎的整体架构类似于Google的BigTable,在开源领域的实现有HBase等。其存储引擎的数据模型为宽行模型,这个模型可以支撑海量的数据,但在数据查询方面依赖主键,对主键做精确查询和范围查询效率很高,但其他查询方式则效率很低,甚至要扫描全表。
为了增加数据查询的能力,Tablestore在存储引擎之外增加了索引引擎,支持全局二级索引和多元索引,其中多元索引支持多条件组合查询、模糊查询、地理空间查询,以及全文索引等。
关于索引引擎的原理和如何选择,我有另外一篇文章专门来进行解读,读者可进行参考:《海量结构化数据存储技术揭秘:Tablestore存储和索引引擎详解》。
进一步设计
如果你在为接入Tablestore而进行业务设计,那么看了本文也许会更加清晰,也许会更加迷糊。或者还有些功能需求不是很清晰,比如怎么与大数据分析产品结合,怎么使用数据通道等,或者是希望进行进一步的技术探讨,或者是实现层面想知道如何进行编码。或者是实际使用中遇到什么问题。那么,我们有一个钉钉交流群,群号是11789671,欢迎来一起探讨。
亿级消息系统的核心存储:Tablestore发布Timeline 2.0模型
2.0时代到来
此次推出的Timeline模型2.0版,没有直接基于1.X版本直接改造。而是在兼容原有模型架构之上,定义、封装了新的使用接口。重新打造升级新的模型,增加了如下功能:
- 增加了Timeline Meta的管理能力;
- 基于多元索引功能,增加了Meta、Timeline的全文检索、多维组合查询能力;
- 支持SequenceId两种设置方式:自增列、手动设置;
- 支持多列的Timeline Identifier设置,提供Timeline的分组管理能力;
- 兼容Timeline 1.X模型,提供的TimelineMessageForV1样例可直接读、写1.X版本消息,用户也可仿照实现。
架构解析
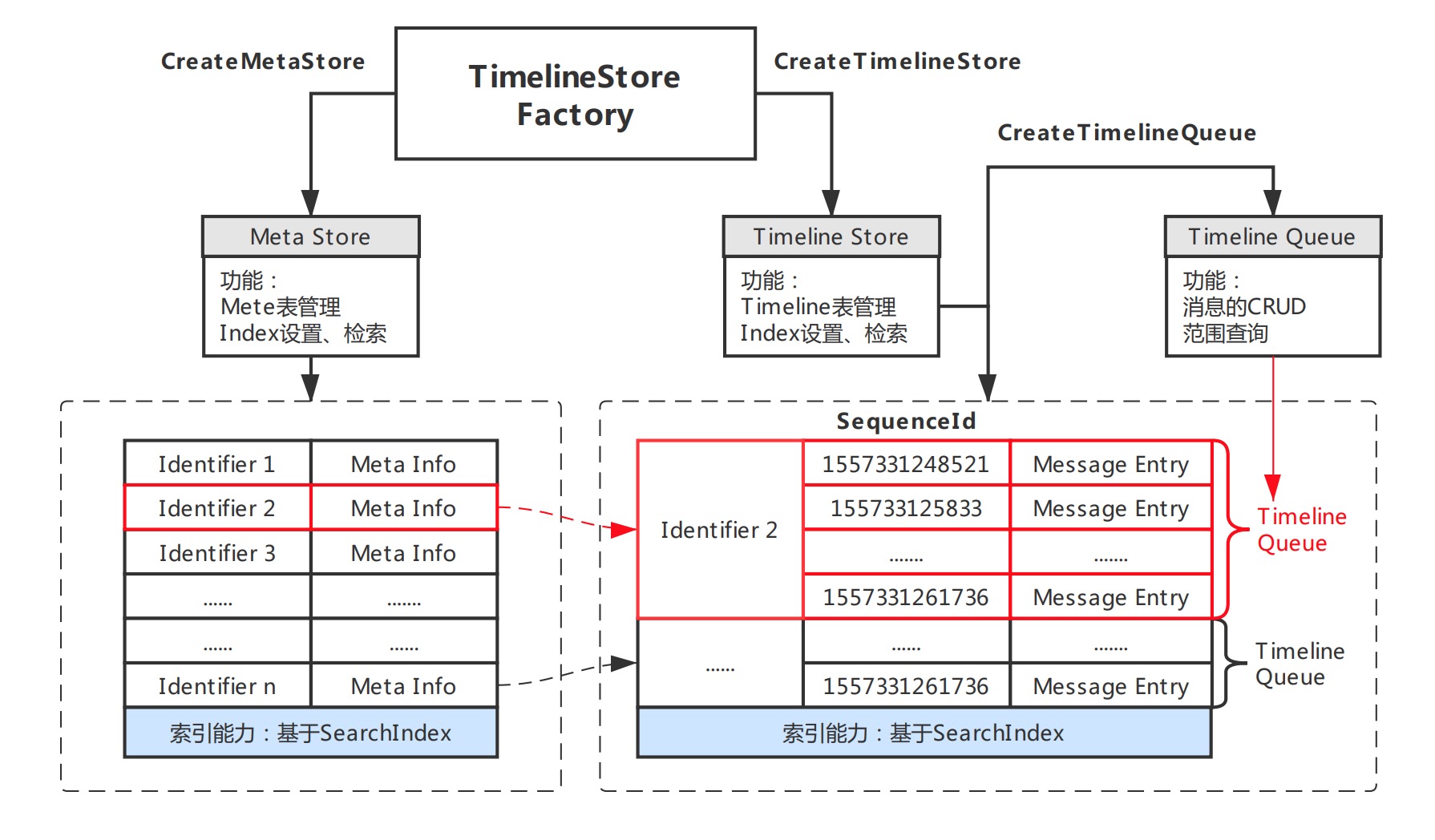
Timeline做为表格存储直接支持的一种数据模型,以『简单』为设计目标,其存核心模块构成比较清晰明了。Timeline尽量提升用户的使用自由度,让用户能够根据自身场景需求选择更为合适的实现方案。模型的模块架构如上图,主要包括如下重要部分:
- Store:存储库,类似数据库的表的概念,模型包含两类Store分别为Meta Store、Timeline Store。
- Identifier:用于区分Timeline的唯一标识,用以标识单行Meta,以及相应的Timeline Queue。
- Meta:用于描述Timeline的元数据,元数据描述采用free-schema结构,可自由包含任意列。
- Queue:Queue为单Identifier对应的所有消息队列,一个Timeline下Message按照Queue单元存储。
- SequenceId:Queue中消息体的序列号,需保证递增、唯一,模型支持自增列、自定义两种实现模式。
- Message:Timeline内传递的消息体,是一个free-schema的结构,可自由包含任意列。
- Index:基于SearchIndex实现的索引,针对不同Store分为Meta Index和Message Index两类,可对Meta或Message内的任意列自定义索引,提供灵活的多条件组合查询和搜索。
性能优势
Timeline 模型是基于Tablestore抽象、封装出的一类场景数据模型,因而具有Tablestore自身的所有优点。同时结合场景设计的接口,让用户更直观、清晰的实现业务逻辑,总结如下:
- 支撑海量数据存储:分布式架构,高可扩展,支持10PB级的消息。
- 低存储成本:表格存储提供低成本的存储方式,按量付费、资源包、预留Cu。
- 数据生命周期管理:不同类型(表级别)消息数据,可自定义不同生命周期。
- 极高的写入吞吐:具备极高的写入吞吐能力,可应对00M TPS的消息写入。
- 低延迟的读:查询消息延迟低,毫秒量级。
- 接口设计:可读性高,接口功能全面、清晰。
Maven地址
Timeline Lib
<dependency>
<groupId>com.aliyun.openservices.tablestore</groupId>
<artifactId>Timeline</artifactId>
<version>2.0.0</version>
</dependency>TableStore Java SDK
Timeline模型在TableStore Java SDK >= 4.12.1作为基本数据模型直接提供,表格存储老用户可升级SDK直接使用
<dependency>
<groupId>com.aliyun.openservices</groupId>
<artifactId>tablestore</artifactId>
<version>4.12.1</version>
</dependency>入手指南
初始化
初始化Factory
用户将SyncClient作为参数,初始化StoreFactory,通过工厂创建Meta数据、Timeline数据的管理Store。错误重试的实现依赖SyncClient的重试策略,用户通过设置SyncClient实现重试。如有特殊需求,可自定义策略(只需实现RetryStrategy接口)。
/**
* 重试策略设置
* Code: configuration.setRetryStrategy(new DefaultRetryStrategy());
* */
ClientConfiguration configuration = new ClientConfiguration();
SyncClient client = new SyncClient(
"http://instanceName.cn-shanghai.ots.aliyuncs.com",
"accessKeyId",
"accessKeySecret",
"instanceName", configuration);
TimelineStoreFactory factory = new TimelineStoreFactoryImpl(client);初始化MetaStore
构建meta表的Schema(包含Identifier、MetaIndex等参数),通过Store工厂创建并获取Meta的管理Store;配置参数包含:Meta表名、索引,表名、主键字段、索引名、索引类型等参数。
TimelineIdentifierSchema idSchema = new TimelineIdentifierSchema.Builder()
.addStringField("timeline_id").build();
IndexSchema metaIndex = new IndexSchema();
metaIndex.addFieldSchema( //配置索引字段、类型
new FieldSchema("group_name", FieldType.TEXT).setIndex(true).setAnalyzer(FieldSchema.Analyzer.MaxWord)
new FieldSchema("create_time", FieldType.Long).setIndex(true)
);
TimelineMetaSchema metaSchema = new TimelineMetaSchema("groupMeta", idSchema)
.withIndex("metaIndex", metaIndex); //设置索引
TimelineMetaStore timelineMetaStore = serviceFactory.createMetaStore(metaSchema);初始化TimelineStore
构建timeline表的Schema配置,包含Identifier、TimelineIndex等参数,通过Store工厂创建并获取Timeline的管理Store;配置参数包含:Timeline表名、索引,表名、主键字段、索引名、索引类型等参数。
消息的批量写入,基于Tablestore的DefaultTableStoreWriter提升并发,用户可以根据自己需求设置线程池数目。
TimelineIdentifierSchema idSchema = new TimelineIdentifierSchema.Builder()
.addStringField("timeline_id").build();
IndexSchema timelineIndex = new IndexSchema();
timelineIndex.setFieldSchemas(Arrays.asList(//配置索引的字段、类型
new FieldSchema("text", FieldType.TEXT).setIndex(true).setAnalyzer(FieldSchema.Analyzer.MaxWord),
new FieldSchema("receivers", FieldType.KEYWORD).setIndex(true).setIsArray(true)
));
TimelineSchema timelineSchema = new TimelineSchema("timeline", idSchema)
.autoGenerateSeqId() //SequenceId 设置为自增列方式
.setCallbackExecuteThreads(5) //设置Writer初始线程数为5
.withIndex("metaIndex", timelineIndex); //设置索引
TimelineStore timelineStore = serviceFactory.createTimelineStore(timelineSchema);Meta管理
Meta管理提供了增、删、改、单行读、多条件组合查询等接口。其中多条件组合查询功能基于多元索引,只有设置了IndexSchema的MetaStore才支持组合查询功能。索引类型支持LONG、DOUBLE、BOOLEAN、KEYWORD、GEO_POINT等类型,属性包含Index、Store和Array,其含义与多元索引相同。
TimelineIdentifer是区分Timeline的唯一标识,重复的Identifier会被覆盖。
/**
* 接口使用参数
* */
TimelineIdentifier identifier = new TimelineIdentifier.Builder()
.addField("timeline_id", "group")
.build();
TimelineMeta meta = new TimelineMeta(identifier)
.setField("filedName", "fieldValue");
/**
* 创建Meta表(如果设置索引则会创建索引)
* */
timelineMetaStore.prepareTables();
/**
* 插入Meta数据
* */
timelineMetaStore.insert(meta);
/**
* 根据id读取单行Meta数据
* */
timelineMetaStore.read(identifier);
/**
* 更新Meta数据
* */
meta.setField("fieldName", "newValue");
timelineMetaStore.update(meta);
/**
* 根据id删除单行Meta数据
* */
timelineMetaStore.delete(identifier);
/**
* 通过SearchParameter参数检索
* */
SearchParameter parameter = new SearchParameter(
field("fieldName").equals("fieldValue")
);
timelineMetaStore.search(parameter);
/**
* 通过SearchQuery参数检索(SearchQuery是SDK原生类型,支持所有多元索引检索条件)
* */
TermQuery query = new TermQuery();
query.setFieldName("fieldName");
query.setTerm(ColumnValue.fromString("fieldValue"));
SearchQuery searchQuery = new SearchQuery().setQuery(query);
timelineMetaStore.search(searchQuery);
/**
* 删除Meta表(如果存在索引,同时删除索引)
* */
timelineMetaStore.dropAllTables();Timeline管理
Timeline管理提供了消息模糊查询、多条件组合查询接口。消息的全文检索依托多元索引,用户只需将相应字段索引类型设置为TEXT,即可通过Search接口实现消息的全文检索。Timeline管理包含消息表的创建、检索、删除等。
/**
* 接口使用参数
* */
SearchParameter searchParameter = new SearchParameter(
field("text").equals("fieldValue")
);
TermQuery query = new TermQuery();
query.setFieldName("text");
query.setTerm(ColumnValue.fromString("fieldValue"));
SearchQuery searchQuery = new SearchQuery().setQuery(query).setLimit(10);
/**
* 创建Meta表(如果设置索引则会创建索引)
* */
timelineStore.prepareTables();
/**
* 通过SearchParameter参数检索
* */
timelineStore.search(searchParameter);
/**
* 通过SearchQuery参数检索(SearchQuery是SDK原生类型,支持所有多元索引检索条件)
* */
timelineStore.search(searchQuery);
/**
* 将Writer队列中未发的请求主动触发,同步等待直到所有消息完成存储
* */
timelineStore.flush();
/**
* 关闭Writer与Writer中的线程池
* */
timelineStore.close();
/**
* 删除Timeline表(如果存在索引,同时删除索引)
* */
timelineStore.dropAllTables();Queue管理
Queue是单个消息队列的抽象概念,对应一个Store下单个Identifier的所有消息。通过Queue实例管理相应Identifer的消息队列,支持基本的增、删、改、单行查、范围查等接口。
/**
* 接口使用参数
* */
TimelineIdentifier identifier = new TimelineIdentifier.Builder()
.addField("timeline_id", "group")
.build();
long sequenceId = 1557133858994L;
TimelineMessage message = new TimelineMessage().setField("text", "Timeline is fine.");
ScanParameter scanParameter = new ScanParameter().scanBackward(Long.MAX_VALUE, 0);
TimelineCallback callback = new TimelineCallback() {
@Override
public void onCompleted(TimelineIdentifier i, TimelineMessage m, TimelineEntry t) {
// do something when succeed.
}
@Override
public void onFailed(TimelineIdentifier i, TimelineMessage m, Exception e) {
// do something when failed.
}
};
/**
* 单个Identifier对应的消息队列
* */
timelineQueue = timelineStore.createTimelineQueue(identifier);
/**
* 存储消息
* */
//同步
timelineQueue.store(message);
timelineQueue.store(sequenceId, message);
//异步,支持callback
timelineQueue.storeAsync(message, callback);
timelineQueue.storeAsync(sequenceId, message, callback);
//异步批量
timelineQueue.batchStore(message);
timelineQueue.batchStore(sequenceId, message);
//异步批量,支持callback
timelineQueue.batchStore(message, callback);
timelineQueue.batchStore(sequenceId, message, callback);
/**
* 单行读取、获取最新一行、获取最新SequenceId
* */
timelineQueue.get(sequenceId);
timelineQueue.getLatestTimelineEntry();
timelineQueue.getLatestSequenceId();
/**
* 根据SequenceId更新消息
* */
message.setField("text", "newValue");
timelineQueue.update(sequenceId, message);
timelineQueue.updateAsync(sequenceId, message, callback);
/**
* 根据SequenceId删除消息
* */
timelineQueue.delete(sequenceId);
/**
* 根据范围参数、Filter获取批量消息
* */
timelineQueue.scan(scanParameter);专家服务
表格存储有一批精通Timeline领域的技术专家,在打造IM、Feed流场景方面有着独到的见解。如果您:
- 渴望寻觅Timeline领域高手过招;
- 调研Timeline场景解决方案;
- 准备入门Timeline场景;
- 对表格存储(Tablestore)产品感兴趣;
阿里云-数据库-表格存储Tablestore的更多相关文章
- 阿里云AliYun表格存储(Table Store)相关案例
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- 【IT名人堂】何云飞:阿里云数据库的架构演进之路
[IT名人堂]何云飞:阿里云数据库的架构演进之路 原文转载自:IT168 如果说淘宝革了零售的命,那么DT革了企业IT消费的命.在阿里巴巴看来,DT时代,企业IT消费的模式变成了“云服务+数据”, ...
- 从运维的角度分析使用阿里云数据库RDS的必要性--你不应该在阿里云上使用自建的MySQL/SQL Server/Oracle/PostgreSQL数据库
开宗明义,你不应该在阿里云上使用自建的MySQL or SQL Server数据库,对了,还有Oracle or PostgreSQL数据库. 云数据库 RDS(Relational Database ...
- 云栖神侠传—阿里云数据库专家德歌告诉你PostgreSQL的那些事
什么是云栖神侠传: 云栖社区(http://yq.aliyun.com/?utm_source=yqdg),是阿里云面向开发者群体的开放型社区.在云栖社区中,活跃着许多阿里技术大牛,他们在自己的技术领 ...
- 阿里云数据库MySQL版快速上手!
MySQL是全球最受欢迎的开源数据库,其在各Web应用中均有广泛部署.阿里云数据库MySQL版基于Alibaba的MySQL源码分支,经过双11高并发.大数据量的考验,拥有优良的性能和吞吐量.除此之外 ...
- 重新定义数据库的时刻,阿里云数据库专家带你了解POLARDB
摘要:POLARDB是阿里云ApsaraDB数据库团队研发的基于云计算架构的下一代关系型数据库,其最大的特色是计算节点与存储节点分离,借助优秀的RDMA网络以及最新的块存储技术.POLARDB不但满足 ...
- 赋能时空云计算,阿里云数据库时空引擎Ganos上线
随着移动互联网.位置感知技术.对地观测技术的快速发展,时空信息已从传统GIS行业渗透到大众应用及各行各业.从静态POI(兴趣点)到APP位置信息,从导航电子地图到车辆行驶轨迹,从卫星影像到三维城市建模 ...
- 阿里云数据库再获学术顶会认可,一文全览VLDB最新亮点
一年一度的数据库领域顶级会议VLDB 2019于当地时间8月26日-8月30日在洛杉矶圆满落幕.在本届大会上,阿里云数据库产品团队浓墨登场,不仅有多篇论文入选Research Track和Indust ...
- 再不懂时序就 OUT 啦!,DBengine 排名第一时序数据库,阿里云数据库 InfluxDB 正式商业化!
云数据库 InfluxDB® 版介绍 阿里云数据库 InfluxDB® 版已于近日正式启动商业化 . 云数据库 InfluxDB® 是基于当前最流行的开源数据库 InfluxDB 提供的在线数据库服务 ...
- Future Maker | 领跑亚太 进击的阿里云数据库
7月31日,阿里云马来西亚峰会在吉隆坡召开,阿里巴巴集团副总裁.阿里云智能数据库事业部总裁李飞飞在演讲中表示:“作为亚太地区第一的云服务提供商,阿里云数据库已为多家马来西亚知名企业提供技术支持,助力企 ...
随机推荐
- 今日一学,5道大厂的Java基础面试题
前言 各种框架眼花缭乱,各种逻辑需求,CRUD.久而久之,写的1000行代码中都是if else,@autowired等等,等出去面试的时候,基础题不断,而且还是不常用,或者说不在意的,往往这些就容易 ...
- 2.6 使用dd命令安装Linux系统
面对大批量服务器的安装,人们往往热衷于选择"无人值守安装"的方式,而此方式需要对服务器进行过多的配置,并不适合初学者. 无人值守安装(Kickstart),又称全自动安装,其工作原 ...
- Codeforces 2023/2024 A-H
题面 A B C D E F G H 难度:红 橙 黄 绿 蓝 紫 黑 黑 题解 A 题目大意: 输入 \(a\),\(b\),解不等式 \(b - 2x \le a - x (0 \le x \le ...
- String,StringBuffer、StringBuilder的区别
1.可变性 String:是不可变的.其内部是fianl修饰的,每次变更都会创建一个新的对象. StringBuffer.StringBuilder是可变的,字符串的变更是不会创建新对象的. 2.线程 ...
- RAG 系统高效检索提升秘籍:如何精准选择 BGE 智源、GTE 阿里与 Jina 等的嵌入与精排模型的完美搭配
RAG 系统高效检索提升秘籍:如何精准选择 BGE 智源.GTE 阿里与 Jina 等的嵌入与精排模型的完美搭配 Text Embedding 榜单:MTEB.C-MTEB <MTEB: Mas ...
- 2、oracle数据库基本概念
基本概念 一.数据库启动.监听启动.判断数据库是否可以连接的过程.感知实例的存在 虚拟机ip地址:192.168.56.12 这里需要修改一个地方:就是把本地主机Host-Only的ip地址修改为:1 ...
- bootstrap模态框modal和select2合用时input无法获取焦点
场景:bootstrap模态框modal和select2合用时input无法获取焦点,导致输入法一直闪动,不能输入中文 解决办法: 1.把页面中的 tabindex="-1" 删掉 ...
- vue2-路由Router
Vue 中的路由用于实现单页应用(SPA)中的页面导航.它允许你在不刷新整个页面的情况下,根据不同的 URL 路径显示不同的组件,提供了类似于多页面应用的用户体验.例如,在一个电商应用中,可以通过 ...
- mysql5.7之密码重置
一.windows下更改mysql数据库密码在windows下找到my.ini文件,例如:C:\ProgramData\MySQL\MySQL Server 5.7,打开该文件夹下的my.ini文件, ...
- docker构建supervisor镜像
1 介绍 记录使用docker 构建包含 supervior 的镜像, supervisor: 是一个管理和监控进程的程序,可以方便的通过配置文件来管理我们的任务脚本 将supervisor构建到系统 ...