猫狗识别——PyTorch
猫狗识别
数据集下载:
网盘链接:https://pan.baidu.com/s/1SlNAPf3NbgPyf93XluM7Fg
提取密码:hpn4
1. 要导入的包
import os
import time
import numpy as np import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torch.utils import data
from torchvision import transforms as T
from PIL import Image
import
2. 模型配置
###################################
# SETTINGS
################################### class Config(object): batch_size = 32
max_epoch = 30
num_workers = 2
lr = 0.001
lr_decay = 0.95
weight_decay = 0.0001 train_data_root = '/home/dong/Documents/DATASET/train'
test_data_root = '/home/dong/Documents/DATASET/test' load_dict_path = None opt = Config()
SETTINGS
3. 选择DEVICE
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
4. 数据集
###################################
# DATASETS
################################### class DogCatDataset(data.Dataset): def __init__(self, root, transforms=None, train=True, test=False): super(DogCatDataset, self).__init__() imgs = [os.path.join(root, img) for img in os.listdir(root)] np.random.seed(10000)
np.random.permutation(imgs) len_imgs = len(imgs) self.test = test # -----------------------------------------------------------------------------------------
# 因为在猫狗数据集中,只有训练集和测试集,但是我们还需要验证集,因此从原始训练集中分离出30%的数据
# 用作验证集。
# ------------------------------------------------------------------------------------------
if self.test:
self.imgs = imgs
elif train:
self.imgs = imgs[: int(0.7*len_imgs)]
else:
self.imgs = imgs[int(0.7*len_imgs): ] if transforms is None: normalize = T.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) if self.test or not train:
self.transforms = T.Compose([
T.Scale(224),
T.CenterCrop(224),
T.ToTensor(),
normalize
])
else:
self.transforms = T.Compose([
T.Scale(246),
T.RandomCrop(224),
T.RandomHorizontalFlip(),
T.ToTensor(),
normalize
]) def __getitem__(self, index): # 当前要获取图像的路径
img_path = self.imgs[index] if self.test:
img_label = int(img_path.split('.')[-2].split('/')[-1])
else:
img_label = 1 if 'dog' in img_path.split('/')[-1] else 0 img_data = Image.open(img_path)
img_data = self.transforms(img_data) return img_data, img_label def __len__(self):
return len(self.imgs) train_dataset = DogCatDataset(root=opt.train_data_root, train=True) # train=True, test=False -> 训练集
val_dataset = DogCatDataset(root=opt.train_data_root, train=False) # train=False, test=False -> 验证集
test_dataset = DogCatDataset(root=opt.test_data_root, test=True) # test=True -> 测试集 train_dataloader = DataLoader(dataset=train_dataset,
shuffle=True,
batch_size=opt.batch_size,
num_workers = opt.num_workers)
val_dataloader = DataLoader(dataset=val_dataset,
shuffle=False,
batch_size=opt.batch_size,
num_workers = opt.num_workers)
test_dataloader = DataLoader(dataset=test_dataset,
shuffle=False,
batch_size=opt.batch_size,
num_workers = opt.num_workers)
DATASETS
5. 检查数据集的 shape
# ------------------------------------------------
# CHECKING THE DATASETS
# ------------------------------------------------
print("Training set:")
for images, labels in train_dataloader:
print('Image Batch Dimensions:', images.size())
print('Label Batch Dimensions:', labels.size())
break print("Validation set:")
for images, labels in val_dataloader:
print('Image Batch Dimensions:', images.size())
print('Label Batch Dimensions:', labels.size())
break print("Testing set:")
for images, labels in test_dataloader:
print('Image Batch Dimensions:', images.size())
print('Label Batch Dimensions:', labels.size())
break
eg:
Training set:
Image Batch Dimensions: torch.Size([32, 3, 224, 224])
Label Batch Dimensions: torch.Size([32])
Validation set:
Image Batch Dimensions: torch.Size([32, 3, 224, 224])
Label Batch Dimensions: torch.Size([32])
Testing set:
Image Batch Dimensions: torch.Size([32, 3, 224, 224])
Label Batch Dimensions: torch.Size([32])
6. 模型定义
###################################################
# MODEL
################################################### class AlexNet(nn.Module): def __init__(self, num_classes=2): # num_classes代表数据集的类别数 super(AlexNet, self).__init__() self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=(3, 3), stride=2), nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True), nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True), nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2)
) self.avgpool = nn.AdaptiveAvgPool2d((6, 6)) self.classifers = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True), nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
) def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = x.view(x.size(0), 256*6*6)
logits = self.classifers(x)
probas = F.softmax(logits, dim=1)
return logits, probas # 记载模型
def load(self, model_path):
self.load_state_dict(torch.load(model_path)) # 保存模型
def save(self, model_name):
# 状态字典的保存格式:文件名 + 日期时间 .pth
prefix = 'checkpoints/' + model_name + '_'
name = time.strftime(prefix + '%m%d_%H:%M:%S.pth')
torch.save(self.state_dict, name) model = AlexNet()
model = model.to(device)
Model
7. 定义优化器
##############################################
# Optimizer
############################################## # optimizer = torch.optim.Adam(model.parameters(), lr=opt.lr, weight_decay=opt.weight_decay) optimizer = torch.optim.SGD(model.parameters(), lr=opt.lr, momentum=0.8)
Optimizer
8. 计算准确率
# -------------------------------------------
# 计算准确率
# -------------------------------------------
def compute_acc(model, dataloader, device): correct_pred, num_examples = 0, 0 # correct_pred 统计正确预测的样本数,num_examples 统计样本总数
for i, (features, targets) in enumerate(dataloader): features = features.to(device)
targets = targets.to(device) logits, probas = model(features)
_, predicted_labels = torch.max(probas, 1) num_examples += targets.size(0)
assert predicted_labels.size() == targets.size()
correct_pred += (predicted_labels == targets).sum() return correct_pred.float() / num_examples * 100
compute_acc
9. 训练 and 验证
##############################################
# TRAINING and VALIDATION
############################################## cost_list = []
train_acc_list, val_acc_list = [], [] start_time = time.time() for epoch in range(opt.max_epoch): model.train()
for batch_idx, (features, targets) in enumerate(train_dataloader): features = features.to(device)
targets = targets.to(device) optimizer.zero_grad() logits, probas = model(features)
# print(targets.size(), logits.size(), probas.size())
cost = F.cross_entropy(logits, targets)
# cost = torch.nn.CrossEntropyLoss(logits, targets) cost.backward() optimizer.step() cost_list.append(cost.item()) if not batch_idx % 50:
print('Epoch: %03d/%03d | Batch %03d/%03d | Cost: %.4f'
%(epoch+1, opt.max_epoch, batch_idx, len(train_dataloader), cost)) model.eval()
with torch.set_grad_enabled(False): # save memory during inference train_acc = compute_acc(model, train_dataloader, device=device)
val_acc = compute_acc(model, val_dataloader, device=device) print('Epoch: %03d/%03d | Training ACC: %.4f%% | Validation ACC: %.4f%%'
%(epoch+1, opt.max_epoch, train_acc, val_acc)) train_acc_list.append(train_acc)
val_acc_list.append(val_acc) print('Time Elapsed: %.2f min' % ((time.time() - start_time)/60)) print('Total Time Elapsed: %.2f min' % ((time.time() - start_time)/60))
Training and Validation
eg:
Epoch: 001/030 | Batch 000/547 | Cost: 0.6945
Epoch: 001/030 | Batch 050/547 | Cost: 0.6920
Epoch: 001/030 | Batch 100/547 | Cost: 0.6942
Epoch: 001/030 | Batch 150/547 | Cost: 0.6926
Epoch: 001/030 | Batch 200/547 | Cost: 0.6926
Epoch: 001/030 | Batch 250/547 | Cost: 0.6946
Epoch: 001/030 | Batch 300/547 | Cost: 0.6920
Epoch: 001/030 | Batch 350/547 | Cost: 0.6951
Epoch: 001/030 | Batch 400/547 | Cost: 0.6943
Epoch: 001/030 | Batch 450/547 | Cost: 0.6946
Epoch: 001/030 | Batch 500/547 | Cost: 0.6932
Epoch: 001/030 | Training ACC: 51.7657% | Validation ACC: 50.8933%
Time Elapsed: 2.98 min
Epoch: 002/030 | Batch 000/547 | Cost: 0.6926
Epoch: 002/030 | Batch 050/547 | Cost: 0.6931
Epoch: 002/030 | Batch 100/547 | Cost: 0.6915
Epoch: 002/030 | Batch 150/547 | Cost: 0.6913
Epoch: 002/030 | Batch 200/547 | Cost: 0.6908
Epoch: 002/030 | Batch 250/547 | Cost: 0.6964
Epoch: 002/030 | Batch 300/547 | Cost: 0.6939
Epoch: 002/030 | Batch 350/547 | Cost: 0.6914
Epoch: 002/030 | Batch 400/547 | Cost: 0.6941
Epoch: 002/030 | Batch 450/547 | Cost: 0.6937
Epoch: 002/030 | Batch 500/547 | Cost: 0.6948
Epoch: 002/030 | Training ACC: 53.0400% | Validation ACC: 52.2933%
Time Elapsed: 6.00 min
...
Epoch: 030/030 | Batch 000/547 | Cost: 0.1297
Epoch: 030/030 | Batch 050/547 | Cost: 0.2972
Epoch: 030/030 | Batch 100/547 | Cost: 0.2468
Epoch: 030/030 | Batch 150/547 | Cost: 0.1685
Epoch: 030/030 | Batch 200/547 | Cost: 0.3452
Epoch: 030/030 | Batch 250/547 | Cost: 0.3029
Epoch: 030/030 | Batch 300/547 | Cost: 0.2975
Epoch: 030/030 | Batch 350/547 | Cost: 0.2125
Epoch: 030/030 | Batch 400/547 | Cost: 0.2317
Epoch: 030/030 | Batch 450/547 | Cost: 0.2464
Epoch: 030/030 | Batch 500/547 | Cost: 0.2487
Epoch: 030/030 | Training ACC: 89.5314% | Validation ACC: 88.6400%
Time Elapsed: 92.85 min
Total Time Elapsed: 92.85 min
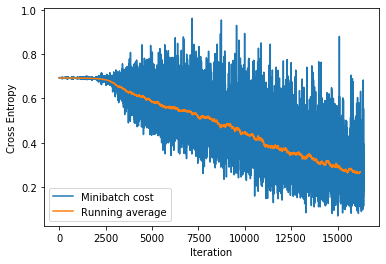
10. 可视化 Loss
plt.plot(cost_list, label='Minibatch cost')
plt.plot(np.convolve(cost_list,
np.ones(200,)/200, mode='valid'),
label='Running average')
plt.ylabel('Cross Entropy')
plt.xlabel('Iteration')
plt.legend()
plt.show()
visualize loss
eg:
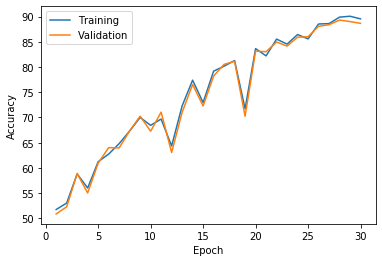
11. 可视化 准确率
plt.plot(np.arange(1, opt.max_epoch+1), train_acc_list, label='Training')
plt.plot(np.arange(1, opt.max_epoch+1), val_acc_list, label='Validation') plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
eg:
猫狗识别——PyTorch的更多相关文章
- pytorch实现kaggle猫狗识别
参考:https://blog.csdn.net/weixin_37813036/article/details/90718310 kaggle是一个为开发商和数据科学家提供举办机器学习竞赛.托管数据 ...
- 猫狗识别-CNN与VGG实现
本次项目首先使用CNN卷积神经网络模型进行训练,最终训练效果不太理想,出现了过拟合的情况.准确率达到0.72,loss达到0.54.使用预训练的VGG模型后,在测试集上准确率达到0.91,取得了不错的 ...
- 深度学习原理与框架-猫狗图像识别-卷积神经网络(代码) 1.cv2.resize(图片压缩) 2..get_shape()[1:4].num_elements(获得最后三维度之和) 3.saver.save(训练参数的保存) 4.tf.train.import_meta_graph(加载模型结构) 5.saver.restore(训练参数载入)
1.cv2.resize(image, (image_size, image_size), 0, 0, cv2.INTER_LINEAR) 参数说明:image表示输入图片,image_size表示变 ...
- keras猫狗图像识别
这里,我们介绍的是一个猫狗图像识别的一个任务.数据可以从kaggle网站上下载.其中包含了25000张毛和狗的图像(每个类别各12500张).在小样本中进行尝试 我们下面先尝试在一个小数据上进行训练, ...
- 使用pytorch完成kaggle猫狗图像识别
kaggle是一个为开发商和数据科学家提供举办机器学习竞赛.托管数据库.编写和分享代码的平台,在这上面有非常多的好项目.好资源可供机器学习.深度学习爱好者学习之用.碰巧最近入门了一门非常的深度学习框架 ...
- 【猫狗数据集】pytorch训练猫狗数据集之创建数据集
猫狗数据集的分为训练集25000张,在训练集中猫和狗的图像是混在一起的,pytorch读取数据集有两种方式,第一种方式是将不同类别的图片放于其对应的类文件夹中,另一种是实现读取数据集类,该类继承tor ...
- Kaggle系列1:手把手教你用tensorflow建立卷积神经网络实现猫狗图像分类
去年研一的时候想做kaggle上的一道题目:猫狗分类,但是苦于对卷积神经网络一直没有很好的认识,现在把这篇文章的内容补上去.(部分代码参考网上的,我改变了卷积神经网络的网络结构,其实主要部分我加了一层 ...
- paddlepaddle实现猫狗分类
目录 1.预备工作 1.1 数据集准备 1.2 数据预处理 2.训练 2.1 模型 2.2 定义训练 2.3 训练 3.预测 4.参考文献 声明:这是我的个人学习笔记,大佬可以点评,指导,不喜勿喷.实 ...
- Java中如何分析一个案列---猫狗案例为例
猫狗案例: 具体事务: 猫.狗 共性: 姓名.年龄.吃饭 分析:从具体到抽象 猫: 姓名.年龄--->成员变量 吃饭 ---> 成员方法 构造方法:无参.有参 狗: 姓名.年龄 ...
随机推荐
- java 反射基本认识
java 反射基本认识 最近重新复习java反射的知识,有了新的理解. class类? 在面向对象中,万事万物皆对象.类也是个对象,是java.lang.class类的实例对象. public cla ...
- day05 作业
猜年龄 ''' 输入姑娘的年龄后,进行以下判断: 1. 如果姑娘小于18岁,打印"不接受未成年" 2. 如果姑娘大于18岁小于25岁,打印"心动表白" 3. 如 ...
- 基于Arduino和python的串口通信和上位机控制
引言 经常的时候我们要实现两个代码之间的通信,比如说两个不同不同人写的代码要对接,例如将python指令控制Arduino控件的开关,此处使用串口通信是非常方便的,下面笔者将结合自己踩过的坑来讲述下自 ...
- jq序 选择器
1.库和框架 库:小而精 直接操作DOM css() jquerry封装js的那些操作: 事件,属性, ajax(交互的技术),DOM,选择器 框架:大而全 事件,DOM,属性操作,ajax,&qu ...
- DNS解析过程--笔试答题版
在运维笔试的时候,回答DNS解析的过程,不能写一大堆,一是不美观,二是浪费时间,应该怎么写呢?我觉得这样写比较好. 1.客户端:chche----hosts 2.DNS服务器:cache---递归-- ...
- 201871010126 王亚涛 《面向对象程序设计 Java》 第十五周学习总结
内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 https://www.cnblogs.com/nwnu-daizh/p/11 ...
- day16_7.18 常用模块
一.collections collections模块中提供了除了dict,list,str等数据类型之外的其他数据类型:Counter.deque.defaultdict.namedtuple和Or ...
- zzPony.ai 的基础架构挑战与实践
本次分享将从以下几个方面介绍: Pony.ai 基础架构做什么 车载系统 仿真平台 数据基础架构 其他基础架构 1. Pony.ai 基础架构 首先给大家介绍一下 Pony.ai 的基础架构团队做什么 ...
- KDE 上 任务栏 图标位置更改
任务栏上图标是不能直接拖拽的. 右键点任务栏,选[Panel Options -> Panel Settins]之后,就可以拖拽了. 完成之后,按X就行了.
- tuned linux 性能调优工具
tuned 是redhat 提供的一套系统调优工具,使用简单,同时也提供了比较全的分类. 参考资料 https://github.com/redhat-performance/tuned