[转帖]Linux下逻辑地址、线性地址、物理地址详细总结
Linux下逻辑地址、线性地址、物理地址详细总结
https://www.cnblogs.com/alantu2018/p/9002441.html 总结的挺好的 现在应该是段页式管理 使用MMU和TLB 实现 线性地址 逻辑地址 和物理地址的映射.
|
|
二、线性地址转物理地址
前面说了Linux中逻辑地址等于线性地址,那么线性地址怎么对应到物理地址呢?这个大家都知道,那就是通过分页机制,具体的说,就是通过页表查找来对应物理地址。
分页是CPU提供的一种机制,Linux只是根据这种机制的规则,利用它实现了内存管理。
分页的基本原理是把线性地址分成固定长度的单元,称为页(page)。页内部连续的线性地址映射到连续的物理地址中。X86每页为4KB(为简化分析,我们不考虑扩展分页的情况)。为了能转换成物理地址,我们需要给CPU提供当前任务的线性地址转物理地址的查找表,即页表(page table),页表存放在内存中。
在保护模式下,控制寄存器CR0的最高位PG位控制着分页管理机制是否生效,如果PG=1,分页机制生效,需通过页表查找才能把线性地址转换物理地址。如果PG=0,则分页机制无效,线性地址就直接作为物理地址。
为了实现每个任务的平坦的虚拟内存和相互隔离,每个任务都有自己的页目录表和页表。
为了节约页表占用的内存空间,x86将线性地址通过页目录表和页表两级查找转换成物理地址。
32位的线性地址被分成3个部分:
最高10位 Directory 页目录表偏移量,中间10位 Table是页表偏移量,最低12位Offset是物理页内的字节偏移量。
页目录表的大小为4KB(刚好是一个页的大小),包含1024项,每个项4字节(32位),表项里存储的内容就是页表的物理地址(因为物理页地址4k字节对齐,物理地址低12位总是0,所以表项里的最低12字节记录了一些其他信息,这里做简化分析)。如果页目录表中的页表尚未分配,则物理地址填0。
页表的大小也是4k,同样包含1024项,每个项4字节,内容为最终物理页的物理内存起始地址。
每个活动的任务,必须要先分配给它一个页目录表,并把页目录表的物理地址存入cr3寄存器。页表可以提前分配好,也可以在用到的时候再分配。
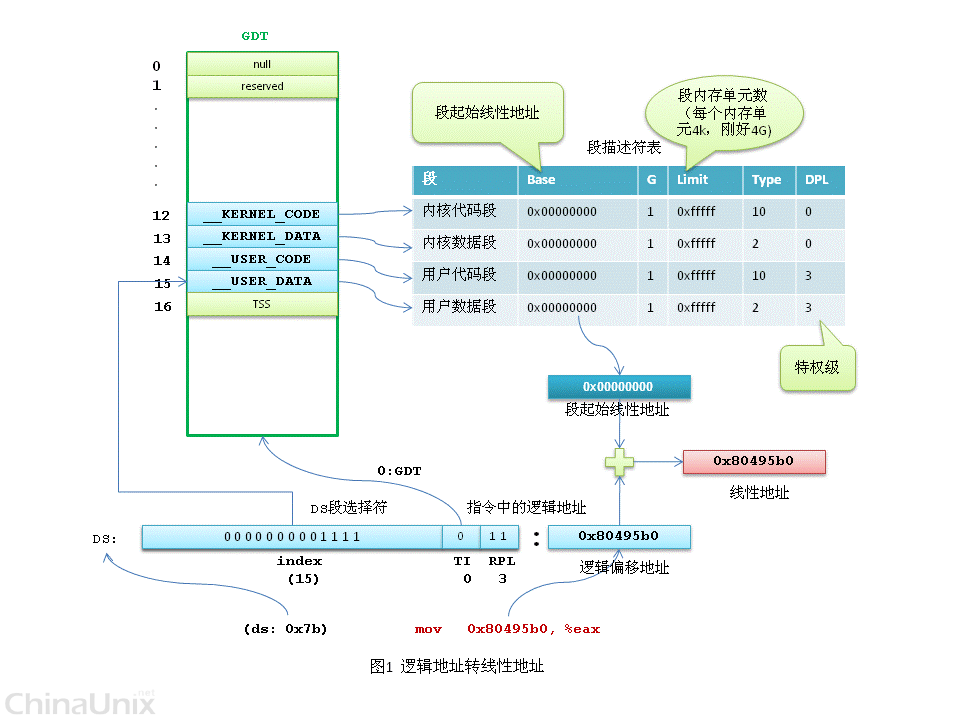
还是以 mov 0x80495b0, %eax 中的地址为例分析一下线性地址转物理地址的过程。
前面说到Linux中逻辑地址等于线性地址,那么我们要转换的线性地址就是0x80495b0。转换的过程是由CPU自动完成的,Linux所要做的就是准备好转换所需的页目录表和页表(假设已经准备好,给页目录表和页表分配物理内存的过程很复杂,后文再分析)。
内核先将当前任务的页目录表的物理地址填入cr3寄存器。
线性地址 0x80495b0 转换成二进制后是 0000 1000 0000 0100 1001 0101 1011 0000,最高10位0000 1000 00的十进制是32,CPU查看页目录表第32项,里面存放的是页表的物理地址。线性地址中间10位00 0100 1001 的十进制是73,页表的第73项存储的是最终物理页的物理起始地址。物理页基地址加上线性地址中最低12位的偏移量,CPU就找到了线性地址最终对应的物理内存单元。
我们知道Linux中用户进程线性地址能寻址的范围是0 - 3G,那么是不是需要提前先把这3G虚拟内存的页表都建立好呢?一般情况下,物理内存是远远小于3G的,加上同时有很多进程都在运行,根本无法给每个进程提前建立3G的线性地址页表。Linux利用CPU的一个机制解决了这个问题。进程创建后我们可以给页目录表的表项值都填0,CPU在查找页表时,如果表项的内容为0,则会引发一个缺页异常,进程暂停执行,Linux内核这时候可以通过一系列复杂的算法给分配一个物理页,并把物理页的地址填入表项中,进程再恢复执行。当然进程在这个过程中是被蒙蔽的,它自己的感觉还是正常访问到了物理内存。
怎样防止进程访问不属于自己的线性地址(如内核空间)或无效的地址呢?内核里记录着每个进程能访问的线性地址范围(进程的vm_area_struct 线性区链表和红黑树里存放着),在引发缺页异常的时候,如果内核检查到引发缺页的线性地址不在进程的线性地址范围内,就发出SIGSEGV信号,进程结束,我们将看到程序员最讨厌看到的Segmentation fault。
我理解的逻辑地址、线性地址、物理地址和虚拟地址
本贴涉及的硬件平台是X86,如果是其它平台,嘻嘻,不保证能一一对号入座,但是举一反三,我想是完全可行的。
一、概念
物理地址(physical address)
用于内存芯片级的单元寻址,与处理器和CPU连接的地址总线相对应。
——这个概念应该是这几个概念中最好理解的一个,但是值得一提的是,虽然可以直接把物理地址理解成插在机器上那根内存本身,把内存看成一个从0字节一直到最大空量逐字节的编号的大数组,然后把这个数组叫做物理地址,但是事实上,这只是一个硬件提供给软件的抽像,内存的寻址方式并不是这样。所以,说它是“与地址总线相对应”,是更贴切一些,不过抛开对物理内存寻址方式的考虑,直接把物理地址与物理的内存一一对应,也是可以接受的。也许错误的理解更利于形而上的抽像。
虚拟内存(virtual memory)
这是对整个内存(不要与机器上插那条对上号)的抽像描述。它是相对于物理内存来讲的,可以直接理解成“不直实的”,“假的”内存,例如,一个0x08000000内存地址,它并不对就物理地址上那个大数组中0x08000000 - 1那个地址元素;
之所以是这样,是因为现代操作系统都提供了一种内存管理的抽像,即虚拟内存(virtual memory)。进程使用虚拟内存中的地址,由操作系统协助相关硬件,把它“转换”成真正的物理地址。这个“转换”,是所有问题讨论的关键。
有了这样的抽像,一个程序,就可以使用比真实物理地址大得多的地址空间。(拆东墙,补西墙,银行也是这样子做的),甚至多个进程可以使用相同的地址。不奇怪,因为转换后的物理地址并非相同的。
——可以把连接后的程序反编译看一下,发现连接器已经为程序分配了一个地址,例如,要调用某个函数A,代码不是call A,而是call 0x0811111111 ,也就是说,函数A的地址已经被定下来了。没有这样的“转换”,没有虚拟地址的概念,这样做是根本行不通的。
打住了,这个问题再说下去,就收不住了。
逻辑地址(logical address)
Intel为了兼容,将远古时代的段式内存管理方式保留了下来。逻辑地址指的是机器语言指令中,用来指定一个操作数或者是一条指令的地址。以上例,我们说的连接器为A分配的0x08111111这个地址就是逻辑地址。
——不过不好意思,这样说,好像又违背了Intel中段式管理中,对逻辑地址要求,“一个逻辑地址,是由一个段标识符加上一个指定段内相对地址的偏移量,表示为 [段标识符:段内偏移量],也就是说,上例中那个0x08111111,应该表示为[A的代码段标识符: 0x08111111],这样,才完整一些”
线性地址(linear address)或也叫虚拟地址(virtual address)
跟逻辑地址类似,它也是一个不真实的地址,如果逻辑地址是对应的硬件平台段式管理转换前地址的话,那么线性地址则对应了硬件页式内存的转换前地址。
-------------------------------------------------------------
CPU将一个虚拟内存空间中的地址转换为物理地址,需要进行两步:首先将给定一个逻辑地址(其实是段内偏移量,这个一定要理解!!!),CPU要利用其段式内存管理单元,先将为个逻辑地址转换成一个线程地址,再利用其页式内存管理单元,转换为最终物理地址。
这样做两次转换,的确是非常麻烦而且没有必要的,因为直接可以把线性地址抽像给进程。之所以这样冗余,Intel完全是为了兼容而已。
2、CPU段式内存管理,逻辑地址如何转换为线性地址
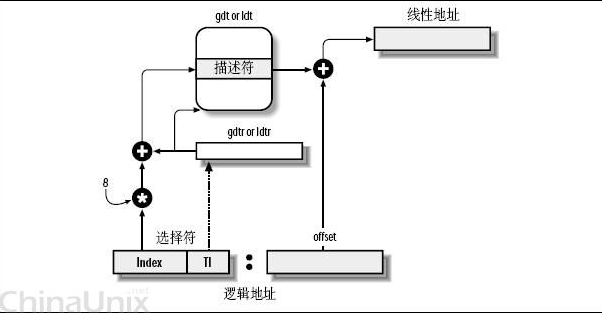
一个逻辑地址由两部份组成,段标识符: 段内偏移量。段标识符是由一个16位长的字段组成,称为段选择符。其中前13位是一个索引号。后面3位包含一些硬件细节,如图:
最后两位涉及权限检查,本贴中不包含。
索引号,或者直接理解成数组下标——那它总要对应一个数组吧,它又是什么东东的索引呢?这个东东就是“段描述符(segment descriptor)”,呵呵,段描述符具体地址描述了一个段(对于“段”这个字眼的理解,我是把它想像成,拿了一把刀,把虚拟内存,砍成若干的截——段)。这样,很多个段描述符,就组了一个数组,叫“段描述符表”,这样,可以通过段标识符的前13位,直接在段描述符表中找到一个具体的段描述符,这个描述符就描述了一个段,我刚才对段的抽像不太准确,因为看看描述符里面究竟有什么东东——也就是它究竟是如何描述的,就理解段究竟有什么东东了,每一个段描述符由8个字节组成,如下图: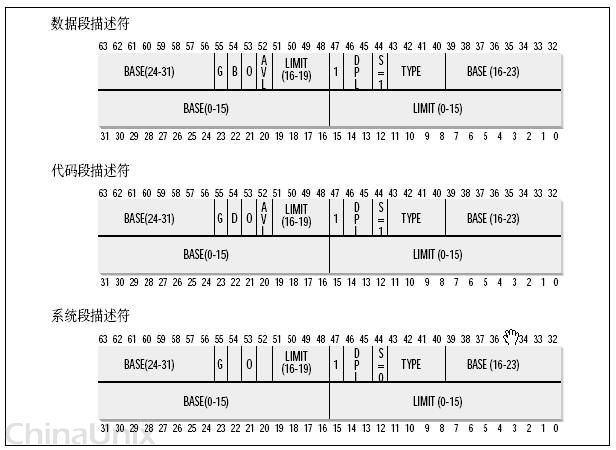
这些东东很复杂,虽然可以利用一个数据结构来定义它,不过,我这里只关心一样,就是Base字段,它描述了一个段的开始位置的线性地址。
Intel设计的本意是,一些全局的段描述符,就放在“全局段描述符表(GDT)”中,一些局部的,例如每个进程自己的,就放在所谓的“局部段描述符表(LDT)”中。那究竟什么时候该用GDT,什么时候该用LDT呢?这是由段选择符中的T1字段表示的,=0,表示用GDT,=1表示用LDT。
GDT在内存中的地址和大小存放在CPU的gdtr控制寄存器中,而LDT则在ldtr寄存器中。
好多概念,像绕口令一样。这张图看起来要直观些: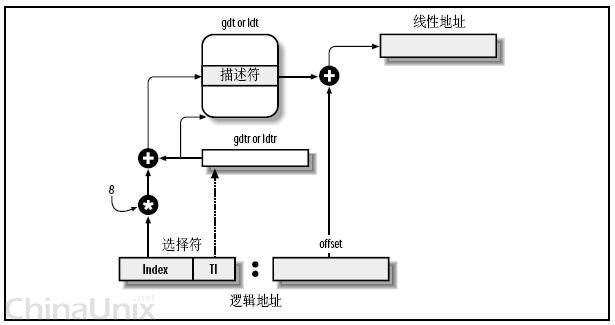
首先,给定一个完整的逻辑地址[段选择符:段内偏移地址],
1、看段选择符的T1=0还是1,知道当前要转换是GDT中的段,还是LDT中的段,再根据相应寄存器,得到其地址和大小。我们就有了一个数组了。
2、拿出段选择符中前13位,可以在这个数组中,查找到对应的段描述符,这样,它了Base,即基地址就知道了。
3、把Base + offset,就是要转换的线性地址了。
还是挺简单的,对于软件来讲,原则上就需要把硬件转换所需的信息准备好,就可以让硬件来完成这个转换了。OK,来看看Linux怎么做的。
3、Linux的段式管理
Intel要求两次转换,这样虽说是兼容了,但是却是很冗余,呵呵,没办法,硬件要求这样做了,软件就只能照办,怎么着也得形式主义一样。
另一方面,其它某些硬件平台,没有二次转换的概念,Linux也需要提供一个高层抽像,来提供一个统一的界面。所以,Linux的段式管理,事实上只是“哄骗”了一下硬件而已。
按照Intel的本意,全局的用GDT,每个进程自己的用LDT——不过Linux则对所有的进程都使用了相同的段来对指令和数据寻址。即用户数据段,用户代码段,对应的,内核中的是内核数据段和内核代码段。这样做没有什么奇怪的,本来就是走形式嘛,像我们写年终总结一样。
include/asm-i386/segment.h
- #define GDT_ENTRY_DEFAULT_USER_CS 14
- #define __USER_CS (GDT_ENTRY_DEFAULT_USER_CS * 8 + 3)
- #define GDT_ENTRY_DEFAULT_USER_DS 15
- #define __USER_DS (GDT_ENTRY_DEFAULT_USER_DS * 8 + 3)
- #define GDT_ENTRY_KERNEL_BASE 12
- #define GDT_ENTRY_KERNEL_CS (GDT_ENTRY_KERNEL_BASE + 0)
- #define __KERNEL_CS (GDT_ENTRY_KERNEL_CS * 8)
- #define GDT_ENTRY_KERNEL_DS (GDT_ENTRY_KERNEL_BASE + 1)
- #define __KERNEL_DS (GDT_ENTRY_KERNEL_DS * 8)
复制代码
把其中的宏替换成数值,则为:
- #define __USER_CS 115 [00000000 1110 0 11]
- #define __USER_DS 123 [00000000 1111 0 11]
- #define __KERNEL_CS 96 [00000000 1100 0 00]
- #define __KERNEL_DS 104 [00000000 1101 0 00]
复制代码
方括号后是这四个段选择符的16位二制表示,它们的索引号和T1字段值也可以算出来了
- __USER_CS index= 14 T1=0
- __USER_DS index= 15 T1=0
- __KERNEL_CS index= 12 T1=0
- __KERNEL_DS index= 13 T1=0
复制代码
T1均为0,则表示都使用了GDT,再来看初始化GDT的内容中相应的12-15项(arch/i386/head.S):
- .quad 0x00cf9a000000ffff /* 0x60 kernel 4GB code at 0x00000000 */
- .quad 0x00cf92000000ffff /* 0x68 kernel 4GB data at 0x00000000 */
- .quad 0x00cffa000000ffff /* 0x73 user 4GB code at 0x00000000 */
- .quad 0x00cff2000000ffff /* 0x7b user 4GB data at 0x00000000 */
复制代码
按照前面段描述符表中的描述,可以把它们展开,发现其16-31位全为0,即四个段的基地址全为0。
这样,给定一个段内偏移地址,按照前面转换公式,0 + 段内偏移,转换为线性地址,可以得出重要的结论,“在Linux下,逻辑地址与线性地址总是一致(是一致,不是有些人说的相同)的,即逻辑地址的偏移量字段的值与线性地址的值总是相同的。!!!”
忽略了太多的细节,例如段的权限检查。呵呵。
Linux中,绝大部份进程并不例用LDT,除非使用Wine ,仿真Windows程序的时候。
4.CPU的页式内存管理
CPU的页式内存管理单元,负责把一个线性地址,最终翻译为一个物理地址。从管理和效率的角度出发,线性地址被分为以固定长度为单位的组,称为页(page),例如一个32位的机器,线性地址最大可为4G,可以用4KB为一个页来划分,这页,整个线性地址就被划分为一个tatol_page[2^20]的大数组,共有2的20个次方个页。这个大数组我们称之为页目录。目录中的每一个目录项,就是一个地址——对应的页的地址。
另一类“页”,我们称之为物理页,或者是页框、页桢的。是分页单元把所有的物理内存也划分为固定长度的管理单位,它的长度一般与内存页是一一对应的。
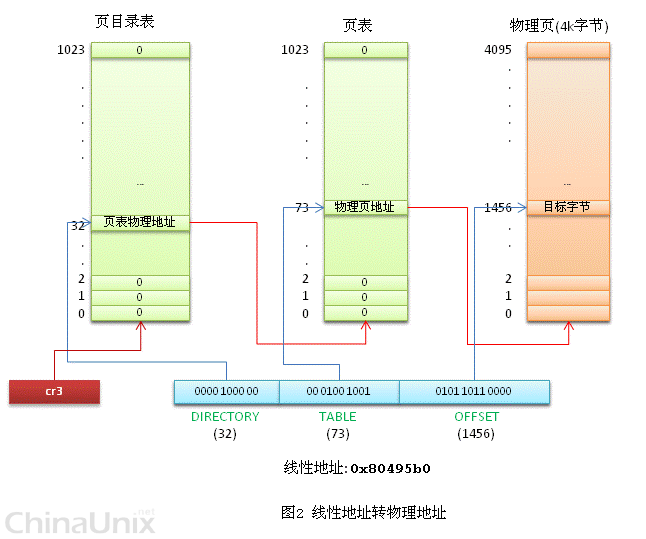
这里注意到,这个total_page数组有2^20个成员,每个成员是一个地址(32位机,一个地址也就是4字节),那么要单单要表示这么一个数组,就要占去4MB的内存空间。为了节省空间,引入了一个二级管理模式的机器来组织分页单元。文字描述太累,看图直观一些: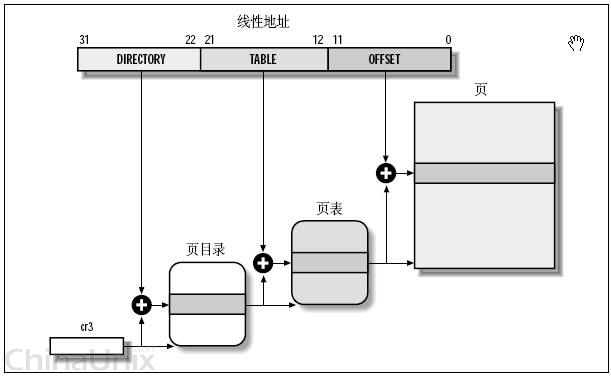
如上图,
1、分页单元中,页目录是唯一的,它的地址放在CPU的cr3寄存器中,是进行地址转换的开始点。万里长征就从此长始了。
2、每一个活动的进程,因为都有其独立的对应的虚似内存(页目录也是唯一的),那么它也对应了一个独立的页目录地址。——运行一个进程,需要将它的页目录地址放到cr3寄存器中,将别个的保存下来。
3、每一个32位的线性地址被划分为三部份,面目录索引(10位):页表索引(10位):偏移(12位)
依据以下步骤进行转换:
1、从cr3中取出进程的页目录地址(操作系统负责在调度进程的时候,把这个地址装入对应寄存器);
2、根据线性地址前十位,在数组中,找到对应的索引项,因为引入了二级管理模式,页目录中的项,不再是页的地址,而是一个页表的地址。(又引入了一个数组),页的地址被放到页表中去了。
3、根据线性地址的中间十位,在页表(也是数组)中找到页的起始地址;
4、将页的起始地址与线性地址中最后12位相加,得到最终我们想要的葫芦;
这个转换过程,应该说还是非常简单地。全部由硬件完成,虽然多了一道手续,但是节约了大量的内存,还是值得的。那么再简单地验证一下:
1、这样的二级模式是否仍能够表示4G的地址;
页目录共有:2^10项,也就是说有这么多个页表
每个目表对应了:2^10页;
每个页中可寻址:2^12个字节。
还是2^32 = 4GB
2、这样的二级模式是否真的节约了空间;
也就是算一下页目录项和页表项共占空间 (2^10 * 4 + 2 ^10 *4) = 8KB。哎,……怎么说呢!!!
红色错误,标注一下,后文贴中有此讨论。。。。。。
按<深入理解计算机系统>中的解释,二级模式空间的节约是从两个方面实现的:
A、如果一级页表中的一个页表条目为空,那么那所指的二级页表就根本不会存在。这表现出一种巨大的潜在节约,因为对于一个典型的程序,4GB虚拟地址空间的大部份都会是未分配的;
B、只有一级页表才需要总是在主存中。虚拟存储器系统可以在需要时创建,并页面调入或调出二级页表,这就减少了主存的压力。只有最经常使用的二级页表才需要缓存在主存中。——不过Linux并没有完全享受这种福利,它的页表目录和与已分配页面相关的页表都是常驻内存的。
值得一提的是,虽然页目录和页表中的项,都是4个字节,32位,但是它们都只用高20位,低12位屏蔽为0——把页表的低12屏蔽为0,是很好理解的,因为这样,它刚好和一个页面大小对应起来,大家都成整数增加。计算起来就方便多了。但是,为什么同时也要把页目录低12位屏蔽掉呢?因为按同样的道理,只要屏蔽其低10位就可以了,不过我想,因为12>10,这样,可以让页目录和页表使用相同的数据结构,方便。
本贴只介绍一般性转换的原理,扩展分页、页的保护机制、PAE模式的分页这些麻烦点的东东就不啰嗦了……可以参考其它专业书籍。
5.Linux的页式内存管理
原理上来讲,Linux只需要为每个进程分配好所需数据结构,放到内存中,然后在调度进程的时候,切换寄存器cr3,剩下的就交给硬件来完成了(呵呵,事实上要复杂得多,不过偶只分析最基本的流程)。
前面说了i386的二级页管理架构,不过有些CPU,还有三级,甚至四级架构,Linux为了在更高层次提供抽像,为每个CPU提供统一的界面。提供了一个四层页管理架构,来兼容这些二级、三级、四级管理架构的CPU。这四级分别为:
页全局目录PGD(对应刚才的页目录)
页上级目录PUD(新引进的)
页中间目录PMD(也就新引进的)
页表PT(对应刚才的页表)。
整个转换依据硬件转换原理,只是多了二次数组的索引罢了,如下图: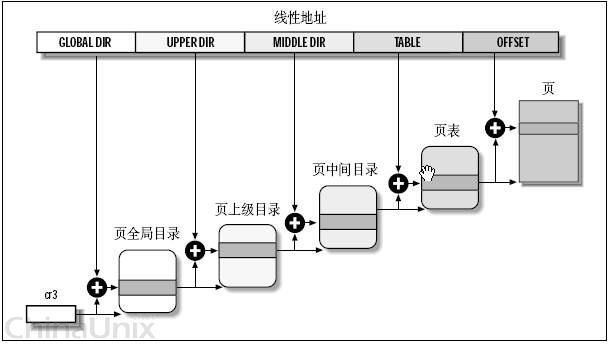
那么,对于使用二级管理架构32位的硬件,现在又是四级转换了,它们怎么能够协调地工作起来呢?嗯,来看这种情况下,怎么来划分线性地址吧!
从硬件的角度,32位地址被分成了三部份——也就是说,不管理软件怎么做,最终落实到硬件,也只认识这三位老大。
从软件的角度,由于多引入了两部份,,也就是说,共有五部份。——要让二层架构的硬件认识五部份也很容易,在地址划分的时候,将页上级目录和页中间目录的长度设置为0就可以了。
这样,操作系统见到的是五部份,硬件还是按它死板的三部份划分,也不会出错,也就是说大家共建了和谐计算机系统。
这样,虽说是多此一举,但是考虑到64位地址,使用四层转换架构的CPU,我们就不再把中间两个设为0了,这样,软件与硬件再次和谐——抽像就是强大呀!!!
例如,一个逻辑地址已经被转换成了线性地址,0x08147258,换成二制进,也就是:
0000100000 0101000111 001001011000
内核对这个地址进行划分
PGD = 0000100000
PUD = 0
PMD = 0
PT = 0101000111
offset = 001001011000
现在来理解Linux针对硬件的花招,因为硬件根本看不到所谓PUD,PMD,所以,本质上要求PGD索引,直接就对应了PT的地址。而不是再到PUD和PMD中去查数组(虽然它们两个在线性地址中,长度为0,2^0 =1,也就是说,它们都是有一个数组元素的数组),那么,内核如何合理安排地址呢?
从软件的角度上来讲,因为它的项只有一个,32位,刚好可以存放与PGD中长度一样的地址指针。那么所谓先到PUD,到到PMD中做映射转换,就变成了保持原值不变,一一转手就可以了。这样,就实现了“逻辑上指向一个PUD,再指向一个PDM,但在物理上是直接指向相应的PT的这个抽像,因为硬件根本不知道有PUD、PMD这个东西”。
然后交给硬件,硬件对这个地址进行划分,看到的是:
页目录 = 0000100000
PT = 0101000111
offset = 001001011000
嗯,先根据0000100000(32),在页目录数组中索引,找到其元素中的地址,取其高20位,找到页表的地址,页表的地址是由内核动态分配的,接着,再加一个offset,就是最终的物理地址了。
linux内存管理---虚拟地址、逻辑地址、线性地址、物理地址的区别(一)
分析linux内存管理机制,离不了上述几个概念,在介绍上述几个概念之前,先从《深入理解linux内核》这本书中摘抄几段关于上述名词的解释:
一、《深入理解linux内核》的解释
逻辑地址(Logical Address)
包含在机器语言指令中用来指定一个操作数或一条指令的地址(有点深奥)。这种寻址方式在80x86著名的分段结构中表现得尤为具体,它促使windows程序员把程序分成若干段。每个逻辑地址都由一个段和偏移量组成,偏移量指明了从段开始的地方到实际地址之间的距离。
线性地址(linear address)(也称虚拟地址 virtual address)
是一个32位无符号整数,可以用来表示高达4GB的地址,线性地址通常用十六进制数字表示,值的范围从0x00000000到0xffffffff。
物理地址(physical address)
用于内存芯片级内存单元寻址。它们与从微处理器的地址引脚按发送到内存总线上的电信号相对应。物理地址由32位或36位无符号整数表示。(其实这个最好理解,就是实实在在的地址)
(PS:在下面的解释就可以看到,有时也将逻辑地址看做虚拟地址,但是《深入理解linux内核》中将线性地址看做虚拟地址)
首先说一句话:linux关于内存寻址可以分为几个阶段,首先由分段机制,然后有分页机制。
分页机制在段机制之后进行,以完成线性—物理地址的转换过程。段机制把逻辑地址转换为线性址页机制进一步把该线性地址再转换为物理地址
下面是我从网上查找资料了解到的,同时添加了自己的理解
二、第二种解释
逻辑地址(Logical Address)
是指由程序产生的与段相关的偏移地址部分。例如,你在进行C语言指针编程中,可以读取指针变量本身值(&操作),实际上这个值就是逻辑地址,它是相对于你当前进程数据段的地址,不和绝对物理地址相干。只有在Intel实模式下,逻辑地址才和物理地址相等(因为实模式没有分段或分页机制,Cpu不进行自动地址转换);逻辑也就是在Intel保护模式下程序执行代码段限长内的偏移地址(假定代码段、数据段如果完全一样)。应用程序员仅需与逻辑地址打交道,而分段和分页机制对您来说是完全透明的,仅由系统编程人员涉及。应用程序员虽然自己可以直接操作内存,那也只能在操作系统给你分配的内存段操作。(也就是说,咱们应用程序中看到的地址都是逻辑地址。)
如果是程序员,那么逻辑地址对你来说应该是轻而易举就可以理解的。我们在写C代码的时候经常说我们定义的结构体首地址的偏移量,函数的入口偏移量,数组首地址等等。当我们在考究这些概念的时候,其实是相对于你这个程序而言的。并不是对于整个操作系统而言的。也就是说,逻辑地址是相对于你所编译运行的具体的程序(或者叫进程吧,事实上在运行时就是当作一个进程来执行的)而言。你的编译好的程序的入口地址可以看作是首地址,而逻辑地址我们通常可以认为是在这个程序中,编译器为我们分配好的相对于这个首地址的偏移,或者说以这个首地址为起点的一个相对的地址值。(PS:这么来看,逻辑地址就是一个段内偏移量,但是这么说违背了逻辑地址的定义,在intel段是管理中,一个逻辑地址,是由一个段标识符加上一个指定段内相对地址的偏移量,表示为 [段标识符:段内偏移量])
当我们双击一个可执行程序时,就是给操作系统提供了这个程序运行的入口地址。之后shell把可执行文件的地址传入内核。进入内核后,会fork一个新的进程出来,新的进程首先分配相应的内存区域。这里会碰到一个著名的概念叫做Copy On Write,即写时复制技术。这里不详细讲述,总之新的进程在fork出来之后,新的进程也就获得了整个的PCB结构,继而会调用exec函数转而去将磁盘中的代码加载到内存区域中。这时候,进程的PCB就被加入到可执行进程的队列中,当CPU调度到这个进程的时候就真正的执行了。
我们大可以把程序运行的入口地址理解为逻辑地址的起始地址,也就是说,一个程序的开始的地址。以及以后用到的程序的相关数据或者代码相对于这个起始地址的位置(这是由编译器事先安排好的),就构成了我们所说的逻辑地址。逻辑地址就是相对于一个具体的程序(事实上是一个进程,即程序真正被运行时的相对地址)而言的。这么理解在细节上有一定的偏差,只要领会即可。
逻辑地址产生的历史背景:
追根求源,Intel的8位机8080CPU,数据总线(DB)为8位,地址总线(AB)为16位。那么这个16位地址信息也是要通过8位数据总线来传送,也是要在数据通道中的暂存器,以及在CPU中的寄存器和内存中存放的,但由于AB正好是DB的整数倍,故不会产生矛盾!
但当上升到16位机后,Intel8086/8088CPU的设计由于当年IC集成技术和外封装及引脚技术的限制,不能超过40个引脚。但又感觉到8位机原来的地址寻址能力2^16=64KB太少了,但直接增加到16的整数倍即令AB=32位又是达不到的。故而只能把AB暂时增加4条成为20条。则
2^20=1MB的寻址能力已经增加了16倍。但此举却造成了AB的20位和DB的16位之间的矛盾,20位地址信息既无法在DB上传送,又无法在16位的CPU寄存器和内存单元中存放。于是应运而生就产生了CPU段结构的原理。Intel为了兼容,将远古时代的段式内存管理方式保留了下来,也就存在了逻辑地址
线性地址(Linear Address)
是逻辑地址到物理地址变换之间的中间层。程序代码会产生逻辑地址,或者说是段中的偏移地址,加上相应段的基地址就生成了一个线性地址。如果启用了分页机制,那么线性地址可以再经变换以产生一个物理地址。若没有启用分页机制,那么线性地址直接就是物理地址。Intel
80386的线性地址空间容量为4G(2的32次方即32根地址总线寻址)。
我们知道每台计算机有一个CPU(我们从单CPU来说吧。多CPU的情况应该是雷同的),最终所有的指令操作或者数据等等的运算都得由这个CPU来进行,而与CPU相关的寄存器就是暂存一些相关信息的存储记忆设备。因此,从CPU的角度出发的话,我们可以将计算机的相关设备或者部件简单分为两类:一是数据或指令存储记忆设备(如寄存器,内存等等),一种是数据或指令通路(如地址线,数据线等等)。线性地址的本质就是“CPU所看到的地址”。如果我们追根溯源,就会发现线性地址的就是伴随着Intel的X86体系结构的发展而产生的。当32位CPU出现的时候,它的可寻址范围达到4GB,而相对于内存大小来说,这是一个相当巨大的数字,我们也一般不会用到这么大的内存。那么这个时候CPU可见的4GB空间和内存的实际容量产生了差距。而线性地址就是用于描述CPU可见的这4GB空间。我们知道在多进程操作系统中,每个进程拥有独立的地址空间,拥有独立的资源。但对于某一个特定的时刻,只有一个进程运行于CPU之上。此时,CPU看到的就是这个进程所占用的4GB空间,就是这个线性地址。而CPU所做的操作,也是针对这个线性空间而言的。之所以叫线性空间,大概是因为人们觉得这样一个连续的空间排列成一线更加容易理解吧。其实就是CPU的可寻址范围。
物理地址(Physical Address)
是指出现在CPU外部地址总线上的寻址物理内存的地址信号,是地址变换的最终结果地址。如果启用了分页机制,那么线性地址会使用页目录和页表中的项变换成物理地址。如果没有启用分页机制,那么线性地址就直接成为物理地址了。
三、第三种解释
虚拟内存(Virtual Memory)
是指计算机呈现出要比实际拥有的内存大得多的内存量。因此它允许程序员编制并运行比实际系统拥有的内存大得多的程序。这使得许多大型项目也能够在具有有限内存资源的系统上实现。一个很恰当的比喻是:你不需要很长的轨道就可以让一列火车从上海开到北京。你只需要足够长的铁轨(比如说3公里)就可以完成这个任务。采取的方法是把后面的铁轨立刻铺到火车的前面,只要你的操作足够快并能满足要求,列车就能象在一条完整的轨道上运行。这也就是虚拟内存管理需要完成的任务。在Linux
0.11内核中,给每个程序(进程)都划分了总容量为64MB的虚拟内存空间。因此程序的逻辑地址范围是0x0000000到0x4000000。
有时我们也把逻辑地址称为虚拟地址。因为与虚拟内存空间的概念类似,逻辑地址也是与实际物理内存容量无关的。(这一点和上面的解释有一点区别,往下的解释就按照这个继续)
逻辑地址与物理地址的“差距”是0xC0000000,是由于虚拟地址->线性地址->物理地址映射正好差这个值。这个值是由操作系统指定的。
虚拟地址到物理地址的转化方法是与体系结构相关的。一般来说有分段、分页两种方式。以现在的x86 cpu为例,分段分页都是支持的。MemoryMangement Unit负责从逻辑地址到物理地址的转化。逻辑地址是段标识+段内偏移量的形式,MMU通过查询段表,可以把逻辑地址转化为线性地址。如果cpu没有开启分页功能,那么线性地址就是物理地址;如果cpu开启了分页功能,MMU还需要查询页表来将线性地址转化为物理地址:
逻辑地址 ----(段表)---> 线性地址 — (页表)—> 物理地址
不同的逻辑地址可以映射到同一个线性地址上;不同的线性地址也可以映射到同一个物理地址上;所以是多对一的关系。另外,同一个线性地址,在发生换页以后,也可能被重新装载到另外一个物理地址上。所以这种多对一的映射关系也会随时间发生变化。
四、第四种解释
程序(进程)的虚拟地址和逻辑地址
逻辑地址(logicaladdress)指程序产生的段内偏移地址。应用程序只与逻辑地址打交道,分段分页对应用程序来说是透明的。也就是说C语言中的&,汇编语言中的符号地址,C中嵌入式汇编的”m”对应的都是逻辑地址。
逻辑地址是Intel为了兼容,将远古时代的段式内存管理方式保留了下来。逻辑地址指的是机器语言指令中,用来指定一个操作数或者是一条指令的地址。以上例,我们说的连接器为A分配的0x08111111这个地址就是逻辑地址。不过不好意思,这样说,好像又违背了Intel中段式管理中,对逻辑地址要求,“一个逻辑地址,是由一个段标识符加上一个指定段内相对地址的偏移量,表示为[段标识符:段内偏移量],也就是说,上例中那个0x08111111,应该表示为[A的代码段标识符: 0x08111111],这样,才完整一些”
线性地址(linear address)或也叫虚拟地址(virtual address):跟逻辑地址类似,它也是一个不真实的地址,如果逻辑地址是对应的硬件平台段式管理转换前地址的话,那么线性地址则对应了硬件页式内存的转换前地址。
实际物理内存地址
物理地址(physicaladdress)是CPU外部地址总线上的寻址信号,是地址变换的最终结果,一个物理地址始终对应实际内存中的一个存储单元。对80386保护模式来说,如果开启分页机制,线性地址经过页变换产生物理地址。如果没有开启分页机制,线性地址直接对应物理地址。页目录表项、页表项对应都是物理地址。
是指出现在CPU外部地址总线上的寻址物理内存的地址信号,是地址变换的最终结果地址。如果启用了分页机制,那么线性地址会使用页目录和页表中的项变换成物理地址。如果没有启用分页机制,那么线性地址就直接成为物理地址了。
物理地址用于内存芯片级的单元寻址,与处理器和CPU连接的地址总线相对应。这个概念应该是这几个概念中最好理解的一个,但是值得一提的是,虽然可以直接把物理地址理解成插在机器上那根内存本身,把内存看成一个从0字节一直到最大空量逐字节的编号的大数组,然后把这个数组叫做物理地址,但是事实上,这只是一个硬件提供给软件的抽像,内存的寻址方式并不是这样。所以,说它是“与地址总线相对应”,是更贴切一些,不过抛开对物理内存寻址方式的考虑,直接把物理地址与物理的内存一一对应,也是可以接受的。也许错误的理解更利于形而上的抽像。
Linux0.11的内核数据段,内核代码段基地址都是0,所以对内核来说,逻辑地址就是线性地址。又因为1个页目录表和4个页表完全映射16M物理内存,所以线性地址也就是物理地址。故对linux0.11内核来说,逻辑地址,线性地址,物理地址重合。
========================================================
虚拟地址是对整个内存(不要与机器上插那条对上号)的抽像描述。它是相对于物理内存来讲的,可以直接理解成“不真实的”,“假的”内存,例如,一个0x08000000内存地址,它并不对就物理地址上那个大数组中0x08000000 - 1那个地址元素;之所以是这样,是因为现代操作系统都提供了一种内存管理的抽像,即虚拟内存(virtual memory)。进程使用虚拟内存中的地址,由操作系统协助相关硬件,把它“转换”成真正的物理地址。这个“转换”,是所有问题讨论的关键。有了这样的抽像,一个程序,就可以使用比真实物理地址大得多的地址空间。(拆东墙,补西墙,银行也是这样子做的),甚至多个进程可以使用相同的地址。不奇怪,因为转换后的物理地址并非相同的。可以把连接后的程序反编译看一下,发现连接器已经为程序分配了一个地址,例如,要调用某个函数A,代码不是call A,而是call 0x0811111111 ,也就是说,函数A的地址已经被定下来了。没有这样的“转换”,没有虚拟地址的概念,这样做是根本行不通的。打住了,这个问题再说下去,就收不住了。
五、总结
CPU将一个虚拟内存空间中的地址转换为物理地址,需要进行两步:首先将给定一个逻辑地址(其实是段内偏移量,这个一定要理解!!!),CPU要利用其段式内存管理单元,先将为个逻辑地址转换成一个线程地址,再利用其页式内存管理单元,转换为最终物理地址。
线性地址:是CPU所能寻址的空间或者范围。
物理地址:是机器中实际的内存地址。换言之,是机器中的内存容量范围。
逻辑地址:是对程序而言的。一般以Seg:Offset来表示。(程序员自己看到的地址)
因此,若要确实比较三者的话,应有以下关系:线性地址大于等于物理地址(PS:但二者的地址空间是一样的),而逻辑地址大于线性地址。逻辑地址通过段表变换成线性地址,此时如果并未开启分页机制的情况下,逻辑地址直接转换成CPU所能寻址的空间。若已开启则通过页表完成线性地址到物理地址的变换。
因此,三者最准确的关系是:逻辑地址通过线性地址完成物理地址的映射,线性地址在三者之中完全是充当"桥"的作用。
不管哪种解释,都差不多,只不过把虚拟地址归属于剩下三种的哪一个的问题
[转帖]Linux下逻辑地址、线性地址、物理地址详细总结的更多相关文章
- Linux下逻辑地址-线性地址-物理地址图解(转)
一.逻辑地址转线性地址 机器语言指令中出现的内存地址,都是逻辑地址,需要转换成线性地址,再经过MMU(CPU中的内存管理单元)转换成物理地址才能够被访问到. 我们写个最简单的hello world程序 ...
- Linux下逻辑地址、线性地址、物理地址详细总结
Linux下逻辑地址.线性地址.物理地址详细总结 一.逻辑地址转线性地址 机器语言指令中出现的内存地址,都是逻辑地址,需要转换成线性地址,再经过MMU(CPU中的内存管理单元)转换成物理地址 ...
- CentOS/Linux下设置IP地址
CentOS/Linux下设置IP地址 1:临时修改:1.1:修改IP地址# ifconfig eth0 192.168.100.100 1.2:修改网关地址# route add default g ...
- 嵌入式 Linux下修改MAC地址
Linux下修改MAC地址 方法一: 1.关闭网卡设备ifconfig eth0 down2.修改MAC地址ifconfig eth0 hw ether MAC地址3.重启网卡ifconfig eth ...
- 获取Linux下的IP地址 java代码
/** * 获取Linux下的IP地址 * * @return IP地址 * @throws SocketException */ public static String getLinuxLocal ...
- linux下修改IP地址的方法
linux下修改IP地址的方法 1.网卡的命名规则 在centos7中,en表示着:ethernet以太网,即现在所用的局域网,enX(X常见有以下3种类型) 2.IP地址的临时修改(重启后失效) 查 ...
- linux配置网卡IP地址命令详细介绍及一些常用网络配置命令
linux配置网卡IP地址命令详细介绍及一些常用网络配置命令2010-- 个评论 收藏 我要投稿 Linux命令行下配置IP地址不像图形界面下那么方 便,完全需要我们手动配置,下面就给大家介绍几种配置 ...
- Linux下函数调用堆栈帧的详细解释【转】
转自:http://blog.chinaunix.net/uid-30339363-id-5116170.html 原文地址:Linux下函数调用堆栈帧的详细解释 作者:cssjtuer http:/ ...
- linux下mysql-5.5.15安装详细步骤
linux下mysql-5.5.15安装详细步骤 注:该文档中用到的目录路径以及一些实际的值都是作为例子来用,具体的目录路径以各自安装时的环境为准 mysql运行时需要一个启动目录.一个安装目录和一个 ...
随机推荐
- C#/Java 常用轮子 (子文章)(持续更新)
-----> 总文章 入口 C# 框架/类库名称 介绍 Topshelf windows服务框架 Quartz 定时任务框架 NVelocity MVC视图引擎 NPOI 文档读写 Signal ...
- 怎么用switchhost
第一步:打开exe, 第二部:在 My hosts 里面直接添加路径 106.75.131.183 npm.kuaizitech.cn 第三部 :打开my hosts 保护好眼睛,早睡早起,多运动,k ...
- NAT端口映射综合详解
- thymeleaf错误解决办法
Caused by: org.attoparser.ParseException: Exception evaluating SpringEL expression: "username&q ...
- Java对象为啥要实现Serializable接口
Serializable接口概述 Serializable是java.io包中定义的.用于实现Java类的序列化操作而提供的一个语义级别的接口.Serializable序列化接口没有任何方法或者字段, ...
- APP:目录
ylbtech-APP:目录 1.返回顶部 2.返回顶部 3.返回顶部 4.返回顶部 5.返回顶部 6.返回顶部 7.返回顶部 8.返回顶部 9.返回顶部 ...
- idea 报错javax/xml/bind/DatatypeConverter
idea 报错javax/xml/bind/DatatypeConverter java.lang.NoClassDefFoundError: javax/xml/bind/DatatypeCon ...
- flutter 日志工具类
class LogUtils { //dart.vm.product 环境标识位 Release为true debug 为false static const bool isRelease = con ...
- Java 有双引号的字符串处理
public class Test{ public static void main(String[] args){ String str1 = "\"name\"&qu ...
- 异常检测-基于孤立森林算法Isolation-based Anomaly Detection-3-例子
参考:https://scikit-learn.org/stable/auto_examples/ensemble/plot_isolation_forest.html#sphx-glr-auto-e ...