Linux awk+uniq+sort 统计文件中某字符串出现次数并排序
https://blog.csdn.net/qq_28766327/article/details/78069989
在服务器开发中,我们经常会写入大量的日志文件。有时候我们需要对这些日志文件进行统计。Linux中我们可以利用以下命令简单高效的实现这一功能。
需要用到的命令简介
- cat命令
cat命令主要有三大功能
1.一次显示整个文件 cat filename
2.创建一个文件 cat > fileName
3.将几个文件合并为一个文件 cat file1 file2 > file
参数:
-n 或 –number 由 1 开始对所有输出的行数编号
-b 或 –number-nonblank 和 -n 相似,只不过对于空白行不编号
-s 或 –squeeze-blank 当遇到有连续两行以上的空白行,就代换为一行的空白行
-v 或 –show-nonprinting - | 管道
管道的作用是将左边命令的输出作为右边命令的输入 awk 命令
awk 是行处理器,优点是处理庞大文件时不会出现内存溢出或处理缓慢的问题,通常用来格式化文本信息。awk依次对每一行进行处理,然后输出。
命令形式 awk [-F|-f|-v] ‘BEGIN{} //{command1; command2} END{}’ file
[-F|-f|-v] 大参数,-F指定分隔符,-f调用脚本,-v定义变量 var=value
’ ’ 引用代码块
BEGIN 初始化代码块,在对每一行进行处理之前,初始化代码,主要是引用全局变量,设置FS分隔符
// 匹配代码块,可以使字符串或正则表达式
{} 命令代码块,包含一条或多条命令
;多条命令使用分号分隔
END 结尾代码块,对每一行进行处理后再执行的代码块,主要进行最终计算或输出
由于篇幅限制,可自行查找更详细的信息。这里awk命令的作用是从文件中每一行取出我们需要的字符串sort 命令
sort将文件的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
-b:忽略每行前面开始出的空格字符;
-c:检查文件是否已经按照顺序排序;
-d:排序时,处理英文字母、数字及空格字符外,忽略其他的字符;
-f:排序时,将小写字母视为大写字母;
-i:排序时,除了040至176之间的ASCII字符外,忽略其他的字符;
-m:将几个排序号的文件进行合并;
-M:将前面3个字母依照月份的缩写进行排序;
-n:依照数值的大小排序;
-o<输出文件>:将排序后的结果存入制定的文件;
-r:以相反的顺序来排序;
-t<分隔字符>:指定排序时所用的栏位分隔字符;- uniq 命令
uniq 命令用于报告或忽略文件中的重复行,一般与sort命令结合使用
-c或——count:在每列旁边显示该行重复出现的次数;
-d或–repeated:仅显示重复出现的行列;
-f<栏位>或–skip-fields=<栏位>:忽略比较指定的栏位;
-s<字符位置>或–skip-chars=<字符位置>:忽略比较指定的字符;
-u或——unique:仅显示出一次的行列;
-w<字符位置>或–check-chars=<字符位置>:指定要比较的字符。 - > 命令
> 是定向输出到文件,如果文件不存在,就创建文件。如果文件存在,就将其清空
另外 >>是将输出内容追加到目标文件中。其他同>
现在我们开始
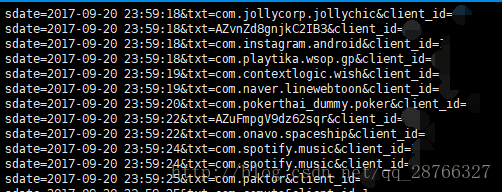
1 读入文件
cat test.log.2017-09-20 - 1
执行结果
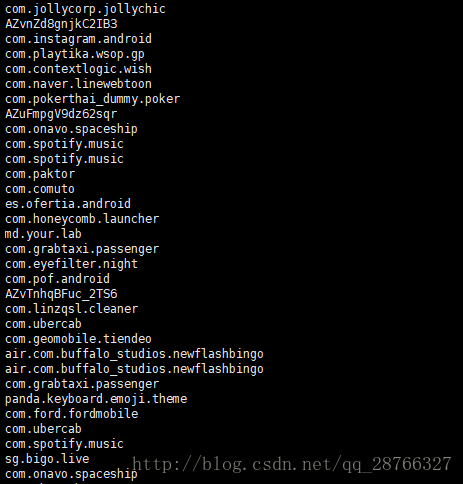
2 从每一行取出我们需要的字符串
cat check_info.log.2017-09-20 | awk -F '(txt=|&client)' '{print $2}'- 1
awk 命令中 -F 指定每一行的分隔符 在这里 ‘(txt=|&client)’是分隔符,它是一个正则表达式。意义是,用’txt=’或’&client’ 作为分隔符
举例来说下面这行
sdate=2017-09-20 23:59:32&txt=com.ford.fordmobile&client_id=x- 1
会被分割成
sdate=2017-09-20 23:59:32&
com.ford.fordmobile
_id=x- 1
- 2
- 3
三部分
其中第二部分”com.ford.fordmobile”是我所需要的字段
而’{print $2}’的意思是将每行得到的第二个值打印出来,$0代表获取的所有值
执行效果如下
3 对行进行排序
先排序是因为去重与统计的 ‘unip’命令只能处理相邻行
cat check_info.log.2017-09-20 | awk -F '(txt=|&client)' '{print $2}'|sort- 1
执行结果 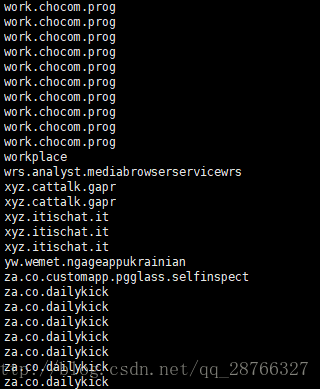
可以看到相同行已经被排在了一起
4 统计数量与去重
cat check_info.log.2017-09-20 | awk -F '(txt=|&client)' '{print $2}'| sort | uniq -c- 1
uniq -c 中的-c 代表在每列旁边显示该行重复出现的次数
执行结果
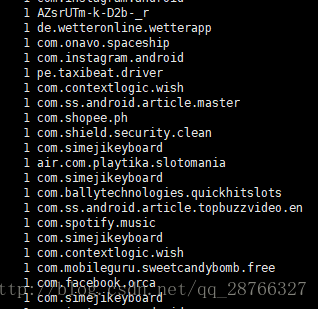
5 按重复次数排序
cat check_info.log.2017-09-20 | awk -F '(txt=|&client)' '{print $2}'| sort | uniq -c | sort -nr- 1
sort 的 -n:依照数值的大小排序;-r 按照相反顺序排列
执行结果
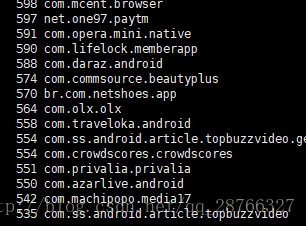
6 将结果输出到文件中
cat check_info.log.2017-09-20 | awk -F '(txt=|&client)' '{print $2}'| sort | uniq -c | sort -nr > testfile- 1
可以看到我们当前目录已有testfile 目录
用vim 打开可以看到
Linux awk+uniq+sort 统计文件中某字符串出现次数并排序的更多相关文章
- linux命令统计文件中某个字符串出现的次数
1.使用grep linux grep命令在我的随笔linux分类里有过简单的介绍,这里就只简单的介绍下使用grep命令统计某个文件这某个字符串出现的次数,首先介绍grep命令的几个参数,详细参数请自 ...
- 使用 awk 过滤文本或文件中的字符串
当我们在 Unix/Linux 下使用特定的命令从字符串或文件中读取或编辑文本时,我们经常需要过滤输出以得到感兴趣的部分.这时正则表达式就派上用场了. 什么是正则表达式? 正则表达式可以定义为代表若干 ...
- awk统计文件中某关键词出现次数
1.统计文件test.txt中第2列不同值出现的次数 awk '{sum[$2]+=1}END{for(i in sum)print i"\t"sum[i]}' test.txt ...
- linux中统计文件中一个字符串出现的次数
要统计一个字符串出现的次数,这里现提供自己常用两种方法: 1. 使用vim统计 用vim打开目标文件,在命令模式下,输入 :%s/objStr//gn 2. 使用grep: grep -o objSt ...
- Java 中统计文件中出现单词的次数练习
统计英文article.txt文件中出现hello这个单词的次数 这个是article.txt文件内容 { hello The Royal Navy is trying hello to play h ...
- Linux统计文件中单词出现的次数
grep -E "\b[[:alpha:]]+\b" /etc/fstab -o | sort | uniq -c 或 awk '{for(i=1;i<NF;i++){c ...
- linux 下批量在多文件中替换字符串
sed -i "s/原字符串/新字符串/g" `grep 原字符串 -rl 所在目录` 注意:`` 符号在shell里面正式的名称叫做backquote , 一般叫做命令替换其作用 ...
- sort +awk+uniq 统计文件中出现次数最多的前10个单词
实例cat logt.log|sort -s -t '-' -k1n |awk '{print $1;}'|uniq -c|sort -k1nr|head -100 统计文件中出现次数最多的前10个单 ...
- Linux命令行批量替换多文件中的字符串【转】
Linux命令行批量替换多文件中的字符串[转自百度文库] 一种是Mahuinan法,一种是Sumly法,一种是30T法分别如下: 一.Mahuinan法: 用sed命令可以批量替换多个文件中的字符串. ...
随机推荐
- 解决idea中maven默认jdk为1.5的问题 : IntelliJ IDEA 源值1.5已过时,将在未来所有版本中删除
解决idea中maven默认jdk为1.5的问题 最近运行总是报警告: IntelliJ IDEA 源值1.5已过时,将在未来所有版本中删除 发现是jdk版本问题, 即使自己修改structure中的 ...
- Luogu5348 密码解锁
题面 题解 记\(N = \dfrac nm\) 这道题目就是要求\(a_m = \sum_{i=1}^N \mu(i)\mu(im)\) 因为\(\mu(ij) = \mu(i)\mu(j)[\gc ...
- LCT 总结
刚开始学lct花了一晚上研究模板,调出来就感觉不怎么难打了. 对板子的浅显理解: lct维护树形联通块,通过splay维护实链,可以把需要的路径变换到一颗splay上维护. splay中的关系只依赖实 ...
- Out of range value for column 'huid' at row
遇到一个MySQL小问题 Data truncation: Out of range value for column 'huid' at row 1 在数据库某表中字段 “huid” 为 ...
- ubuntu之路——day3(本来打算做pytorch的练习 但是想到前段时间的数据预处理的可视化分析 就先总结一下)
首先依托于一个场景来进行可视化分析 直接选了天池大数据竞赛的新人赛的一个活跃题目 用的方式也是最常用的数据预处理方式 [新人赛]快来一起挖掘幸福感!https://tianchi.aliyun.com ...
- Tomcat启动过程中找不到JAVA_HOME JRE_HOME的解决方法
转自:http://blog.sina.com.cn/s/blog_61c006ea0100l1u6.html 原文: 在XP上明明已经安装了JDK1.5并设置好了JAVA_HOME,可偏偏Tomca ...
- python中list和dict
字典(Dictionary)是一种映射结构的数据类型,由无序的“键-值对”组成.字典的键必须是不可改变的类型,如:字符串,数字,tuple:值可以为任何python数据类型. 1.新建字典 1 2 3 ...
- taocrypt
taocrypt MySQL Bugs: #25189: mysqld: coding.cpp:243: void TaoCrypt::Base64Decoder::Decode(): Asserti ...
- 前端通用下载文件方法(兼容IE)
之前在网上看到一个博主写的前端通用的下载文件的方法,个人觉得很实用,所以mark一下,方便以后查阅 源文地址(源文还有上传/下载excel文件方法) 因为项目要求要兼容IE浏览器,所以完善了一下之前博 ...
- PHP实现执行定时任务
首先用命令检查服务是否在运行 systemctl status crond.service 如果服务器上没有装有crontab ,则可以执行 yum install vixie-cron yum in ...