分布式结构化存储系统-Kudu简介
分布式结构化存储系统-Kudu简介
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
Hadoop生态系统发展到现在,存储层主要由HDFS和HBase两个系统把持着,一直没有太大突破。在追求高吞吐的批处理场景下,我们选用HDFS;在追求低延迟,有随机读写需求的场景下,我们选用HBase。那么是否存在一种系统,能结合两个系统的优点,同时支持高吞吐率和低延迟呢?Kudu的出现正式为了解决这以难题。
一.Kudu基本特点
Kudu是Cloudera开源的列式存储引擎,专门为了对快速变化的数据进行快速分析,填补了以往Hadoop存储层的空缺。Kudu具有以下几个特点:
(1)C++语言开发;
(2)可以高效处理类OLAP负载;
(3)可以与MapReduce,Spark以及Hadoop生态系统中其他组件进行友好集成;
(4)可与Imapla集成,替代目前Impala常用的HDFS+Parquet组合;
(5)灵活的一致性模型;
(6)顺序写和随机写并存的场景下,仍能达到良好的性能;
(7)高可用,使用Raft协议保证数据高可靠存储;
(8)结构化数据模型; Kudu的出现,有望解决目前Hadoop生态系统难以解决的一大类问题,比如:
(1)流式实时计算结果的实时更新和查询;
(2)时间序列相关应用,具体要求有:
1)查询海量历史数据;
2)查询个体数据,并要求快速返回;
(3)预测模型中,周期性更新模型,并根据历史数据快速做出决策。
二.Kudu数据模型与架构
kudu是一个强类型的纯列式存储数据库。类似于HBase,Kudu的表是由很多数据子集构成的,表被水平拆分成多个Tablet(类似于HBase的Region),这些Tablet被散布到不同机器上,以实现分布式的存储存储和读写。
Kudu有两种类型的组件:Master Server和Tablet Server。Kudu Master与HBase Master类似,主要功能包括:
(1)负责管理元数据,这些元数据包括Tablet的描述信息及位置信息;
(2)管理Tablet Server,监听Tablet Server的健康状态,一旦发生故障便触发容错;对于副本书过低的Tablet,启动复制任务来提高其副本数。
Master的所有信息都在cache中,因此速度非常快,每次查询都是毫秒级别。Kudu支持多Master,但只有一个Active Master,其余知识作为灾备,不提供服务,一旦Active Master出现故障,其他Master将采用Raft一致性协议重新选举产生新的Active Master。
Table Server用于存储实际的Tablet数据,通常每个Tablet有3个副本存放在不同的Tabale Server。同一个Table的副本分为leader和follower两种类别:每个Tablet只能有一个leader副本,这个副本为用户提供修改操作,然后将修改结果同步给follower;而follower只提供读服务,不提供修改服务;Tablet副本之间使用Raft协议来实现高可用,当leader所在的节点发生故障时,follower会重新选举leader。
三.Kudu与HBase对比
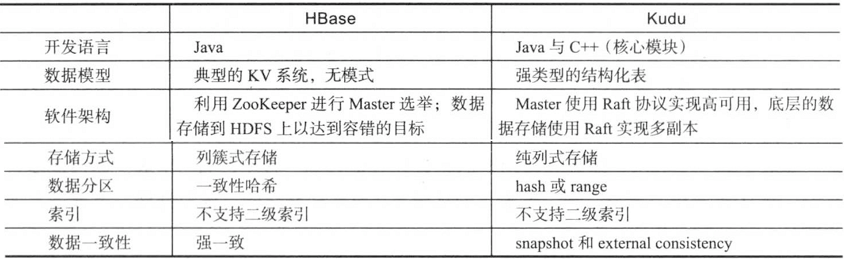
如上图所示,软件架构,存储方式等方面对比了HBase和Kudu。 总结起来,HBase是一个强一致性的KV系统,其扩展性和伸缩性是其最大的有点,通常用于海量数据更新和随机读取的场景;而kudu则是一个实现来多种一致性协议的结构化存储引擎,它通常与Impala结合使用,可用实时OLAP分析(流式导入实时分析)的场景。
分布式结构化存储系统-Kudu简介的更多相关文章
- 分布式结构化存储系统-HBase基本架构
分布式结构化存储系统-HBase基本架构 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在大数据领域中,除了直接以文件形式保存数据外,还有大量结构化和半结构化的数据,这类数据通常需 ...
- 分布式结构化存储系统-HBase应用案例
分布式结构化存储系统-HBase应用案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 为了让读者更进一步了解HBase在实际生成环境中的应用方法,在董西成的书里介绍两个经典的HB ...
- 分布式结构化存储系统-HBase访问方式
分布式结构化存储系统-HBase访问方式 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. HBase提供了多种访问方式,包括HBase shell,HBase API,数据收集组件( ...
- [翻译] Cassandra 分布式结构化存储系统
Cassandra 分布式结构化存储系统 摘要 Cassandra 是一个分布式存储系统,用于管理分布在许多商品服务器上的大量结构化数据,同时提供无单点故障(no single point of fa ...
- Solr系列四:Solr(solrj 、索引API 、 结构化数据导入)
一.SolrJ介绍 1. SolrJ是什么? Solr提供的用于JAVA应用中访问solr服务API的客户端jar.在我们的应用中引入solrj: <dependency> <gro ...
- Hadoop生态新增列式存储系统Kudu
Hadoop生态系统发展到现在,存储层主要由HDFS和HBase两个系统把持着,一直没有太大突破.在追求高吞吐的批处理场景下,我们选用HDFS,在追求低延迟,有随机读写需求的场景下,我们选用H ...
- Bigtable:一个分布式的结构化数据存储系统
Bigtable:一个分布式的结构化数据存储系统 摘要 Bigtable是一个管理结构化数据的分布式存储系统,它被设计用来处理海量数据:分布在数千台通用服务器上的PB级的数据.Google的很多项目将 ...
- Bigtable:结构化数据的分布式存储系统
Bigtable最初是谷歌设计用来存储大规模结构化数据的分布式系统,其可以在数以千计的商用服务器上存储高达PB级别的数据量.开源社区根据Bigtable的设计思路开发了HBase.其优势在于提供了高效 ...
- 分布式存储系统Kudu与HBase的简要分析与对比
本文来自网易云社区 作者:闽涛 背景 Cloudera在2016年发布了新型的分布式存储系统——kudu,kudu目前也是apache下面的开源项目.Hadoop生态圈中的技术繁多,HDFS作为底层数 ...
随机推荐
- oracle sequnece 介绍以及 监控
###sequnece 介绍 http://www.dba-oracle.com/t_rac_tuning_sequence_order_parameter.htm order by 可能会影响性能, ...
- 如何自己构建一套EasyNVR这样的无插件流媒体服务器实现摄像机硬盘录像机的网页可视化直播
EasyNVR流媒体解决方案 EasyNVR能够通过简单的网络摄像机通道配置,将传统监控行业里面的高清网络摄像机IP Camera.NVR等具有RTSP协议输出的设备接入到EasyNVR,EasyNV ...
- LeetCode_405. Convert a Number to Hexadecimal
405. Convert a Number to Hexadecimal Easy Given an integer, write an algorithm to convert it to hexa ...
- docker基本排错
遇到了一个很奇葩的问题,docker运行一个容器后,执行docker ps -a可以查看到该容器处于运行状态,但是无法进入该容器. 试着使用docker stop ID和docker kill -s ...
- php_mvc实现步骤十
shop34-19-商品添加 功能:添加商品表单 Index.php?p=back&c=Goods&a=add Controller-Action: 新建商品控制器类 Applicat ...
- pdflatex 插入eps图片
1. 将eps图片转成pdf或者将pdf图片转成eps,也就是说一张图片有pdf.eps两种格式.方法一: \includegraphics{pic} %不要扩展名.这样pdflatex自动调相应的p ...
- PHP设计模式 - 抽象工厂模式
有些情况下我们需要根据不同的选择逻辑提供不同的构造工厂,而对于多个工厂而言需要一个统一的抽象工厂: <?php class System{} class Soft{} class MacSyst ...
- Linux下Python安装PyMySQL成功,但无法导入的问题
今天使用 Nginx 部署 Django应用.安装python库都显示成功安装. 尝试启动 uwsgi 服务,竟然报错 Traceback (most recent call last): File ...
- STM32F030-UART1_DMA使用提示
STM32F030-UART1_DMA使用提示 前言: 今天把STM32F030C8T6的串口DMA学习了一下,为了加快各位研发人员的开发进度,避免浪费大量的时间在硬件平台上,写出个人代码调试的经验. ...
- 【Centos】Centos7.5取消自动锁屏功能
目录 00. 目录 01. 问题描述 02. 问题分析 03. 解决办法 04. 附录 00. 目录 @ 参考博客:[Centos]Centos7.5取消自动锁屏功能 01. 问题描述 Centos7 ...