SQL Server数据库性能优化
开篇:
最近遇到了很多性能问题,一直没来的及总结,今天正好周末抽时间总结下:
对于稍微大点的公司或者说用户多一些的公司,说白了就是数据量较大的公司,在查询数据时往往会遇到很多瓶颈。这时就需要性能优化。 性能优化分为代码优化和数据库优化,常见的代码优化有分页查询,with(nolock)使用无锁模式。 数据库优化主要是创建索引。
一个苦逼的事情是我们的老系统没有使用分页查询,而是通过查询出所有的数据然后利用前台控件进行的分页。(PS:一个合格的架构师需要不断学习前沿技术,而不是固步自封,设计出垃圾架构)。所以系统经常提示连接数据库超时。。。 所以要解决这个问题我们只能从数据库优化下手。
因为此文要围绕索引展开,所以在开始之前先了解几个概念,及什么是索引? 什么是聚集索引,什么是非聚集索引?什么是主键? 建立非聚集索引时,索引键列和包含性列分别指的什么?
什么是索引?举个例子你就明白了,索引就相当于字典目录,根据目录查找你想要找的文字。如果没有目录的话,你就得一页一页的翻,看哪个文字是自己想要的。所以我们要建立索引。
什么是聚集索引,什么是非聚集索引?一张表里面可以有多个非聚集索引,但只能有一个聚集索引。数据会按照聚集索引进行物理排序,聚集索引和数据是绑定在一起的。而非聚集索引是数据和索引位置分开的,索引上有个指针指向数据。还是拿字典举例,聚集索引就相当于你通过拼音查找,他是有顺序的,A,B,C...是依次排列的,你可以通过拼音直接找到文字位置。而非聚集索引就相当于通过偏旁查找,你先要找到偏旁,然后根据偏旁查找文字,最后才知道在哪一页。 搞不懂的话,可以看下这个 。
什么是主键? 主键主要是确定资料的唯一性。设置主键的字段(可多个字段一起做主键)。例如人事资料中有一个身份证号的字段。这个就可设为主键(因为身份证号不会重复).但姓名就不可以,因为姓名可以重复,另外设置了主键有利于提高数据的检索速度.也保证数据准确性。 主键和索引没有什么必然联系,主键是确定唯一性的,索引是排序用的。
建立非聚集索引时,索引键列和包含性列分别指的什么? 首先声明下,建立非聚集索引的前提是有where查询条件或者order by时建立才有意义。 索引键列一般选取的就是根据where要查询的字段。包含性列是要查询的字段。包含性列是对查询条件的一种性能补充。 可能说的不是很明白,详细可以参考:https://www.cnblogs.com/sc0791/p/3720249.html
正文:
首先先创建Grade和Member两个数据库表并插入数据来进行模拟,创建数据库脚本如下:
create table Grade(
ID int primary key identity,
MathGrade int null,
ChineseGrade int null,
EnglishGrade int null,
MemberID int null,
CreateTime DateTime
) create table Member(
ID int primary key identity,
MemberName nvarchar(20)
) --在Grade里面循环插入数据
Declare @I int
Set @I=0
Begin Tran
InsertData:
Insert into Grade values(@I,@I+10,@I+20,@I+30,GETDATE())
Set @I=@I+1
if @I<100000
Goto InsertData
Commit Tran --在Member里面循环插入数据
Declare @I int
Set @I=0
Begin Tran
InsertData:
Insert into Member values('姓名'+Convert(nvarchar(20), @I))
Set @I=@I+1
if @I<100000
Goto InsertData
Commit Tran
OK,Grade表和Member表都创建好了,并都插入了10W条数据。Grade表中的MemberID和Member表ID是一一对应关系。下面开始测试性能。

执行代码:
declare @begin_date datetime
declare @end_date datetime
select @begin_date = getdate() select g.ID,g.MathGrade,m.MemberName,g.CreateTime from Grade g
left join Member m
on g.MemberID=m.ID
order by g.CreateTime select @end_date = getdate()
select datediff(ms,@begin_date,@end_date) as '用时/毫秒'
OK,下面开始优化,少于1930毫秒则证明优化成功~
选择 工具->数据库引擎优化顾问
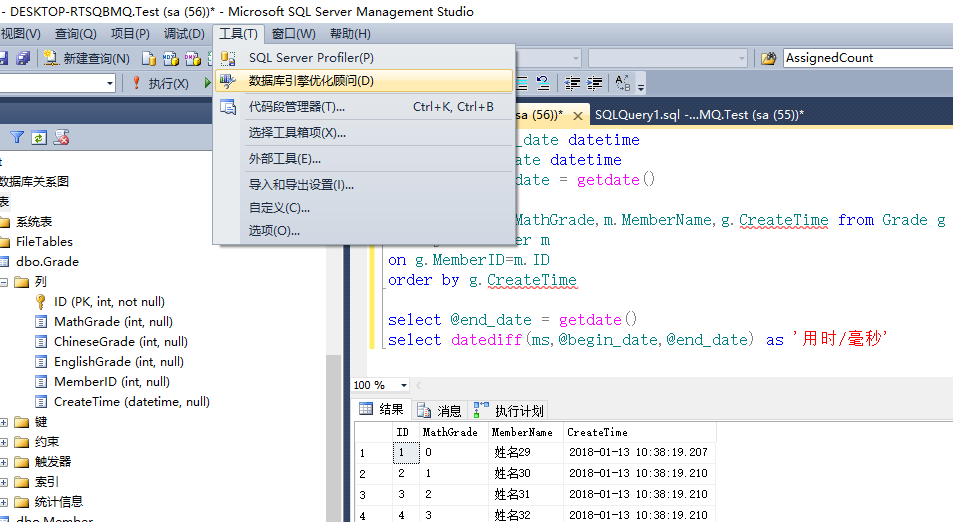
或者右键空白处选择 在数据库引擎优化顾问中分析查询
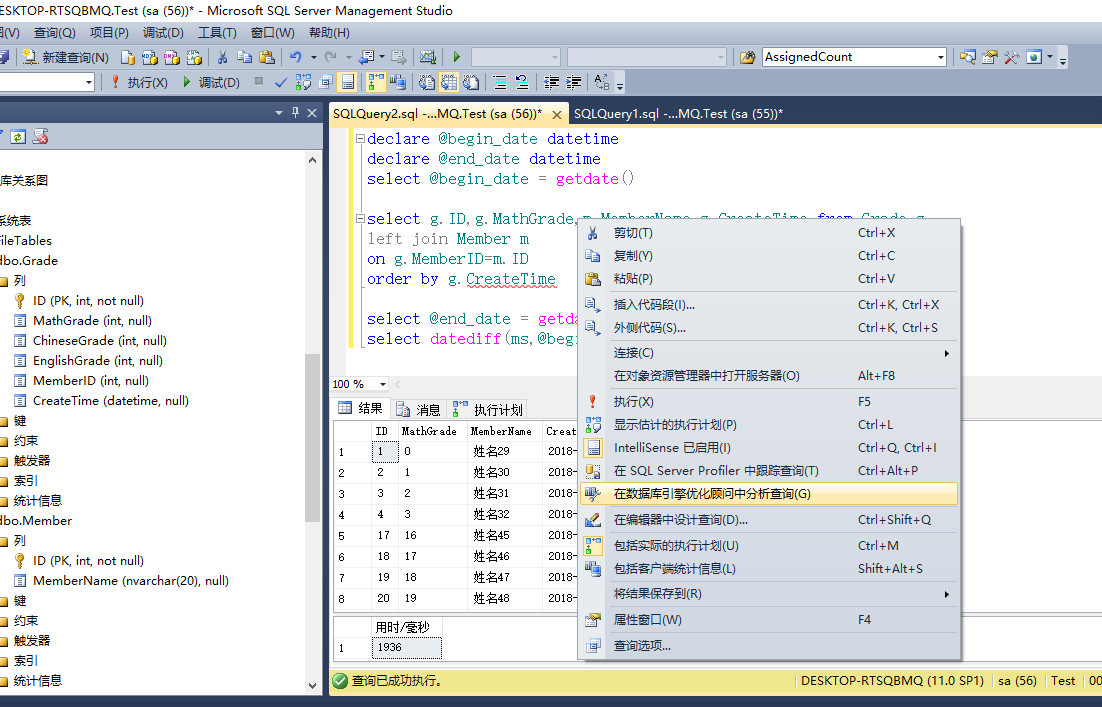 、
、
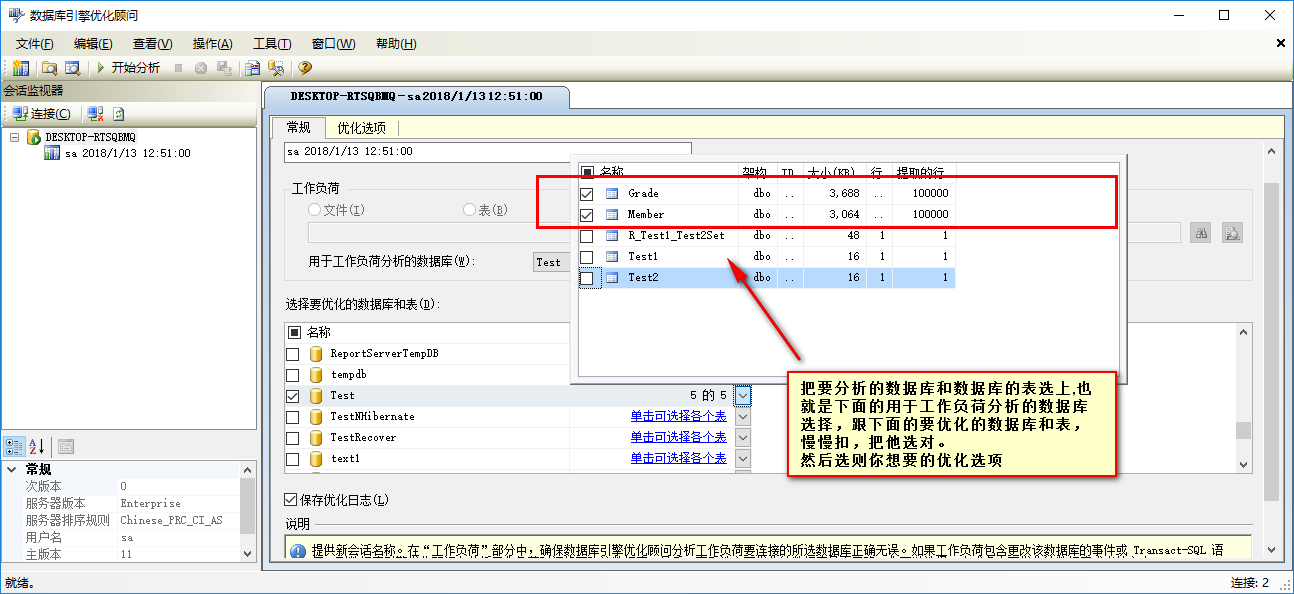

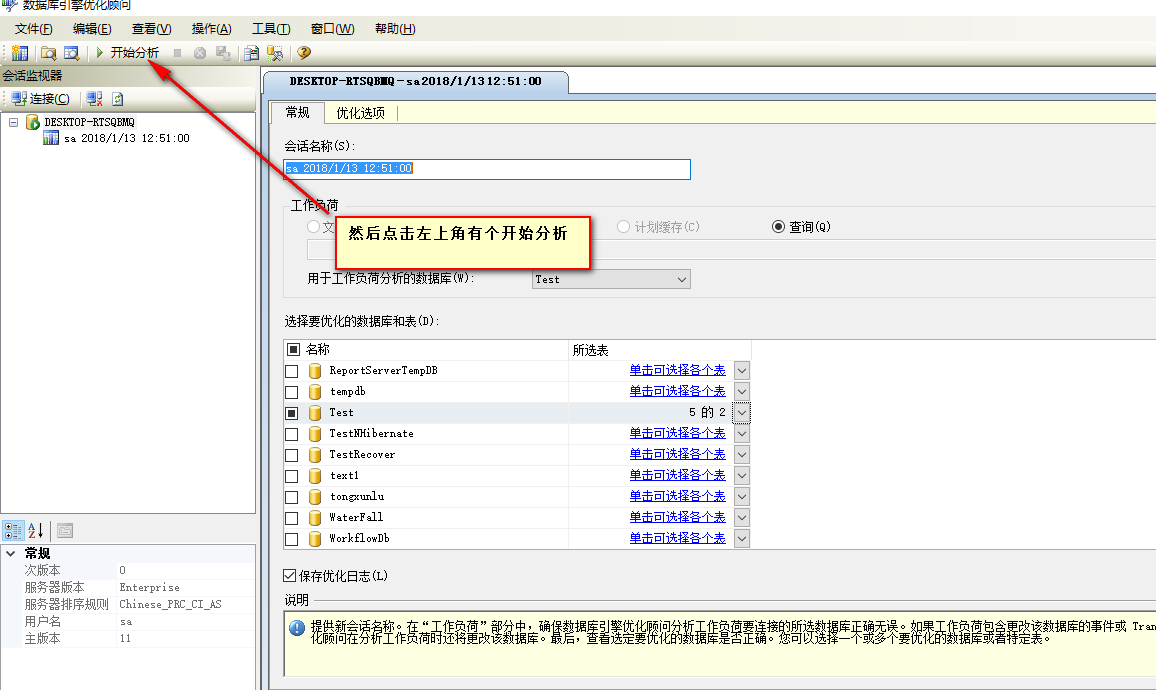

应用后再次执行,如下图:
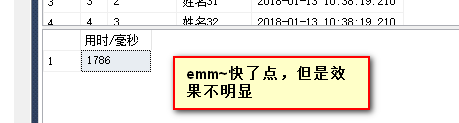
先不用管它,先看下上面执行了什么,如下图:
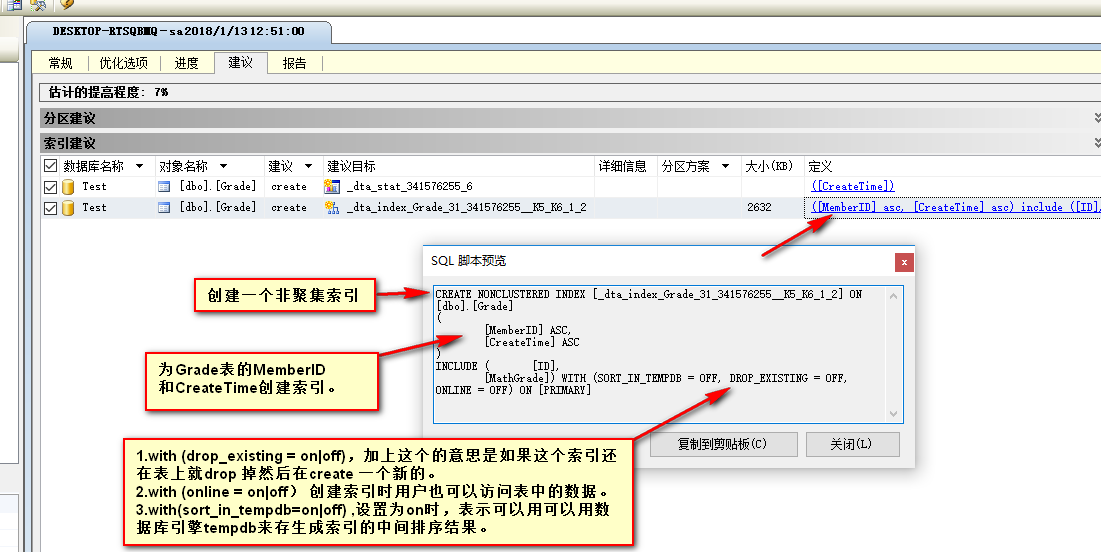
从上面可以看到,它把我们的查询条件都包含进了非聚集索引里面。 emmm~下面看下有没有命中索引:

SQL Server有几种方式查找数据记录:
[Table Scan]表扫描(最慢),这种情况是没索引的前提下。
[Clustered Index Scan]聚集索引扫描(较慢) ,这种情况是只有主键索引的前提下。
[Index Scan]索引扫描(普通),这种情况是有主键索引,并且要搜索的数据建立了非聚集索引的前提下。
[Index Seek]索引查找(较快),这种情况是where条件里面没有根据主键进行过滤时,把过滤的字段加在索引键列上,其余加在包含列上的前提下。
[Clustered Index Seek]聚集索引查找(最快)。这种情况是根据主键进行where过滤的前提下。
这块具体实例我就不演示了,想看的话参考:https://www.cnblogs.com/taiyonghai/p/5594826.html
----休息一下!!!
来,继续!!!上面主要是通过工具生成优化脚本,我们还可以通过图形化工具自己定义,同时还可以写脚本创建。
如下图:(图形化工具创建两张图完美解释)
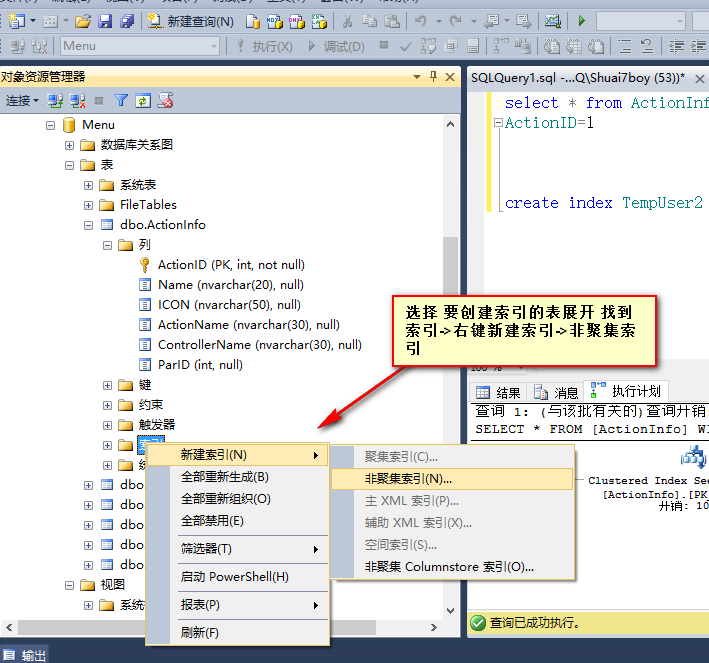

脚本创建如下:
CREATE [索引类型] INDEX 索引名称
ON 表名(列名)
WITH FILLFACTOR = 填充因子值0~100
GO
索引类型有:
-- 聚集索引(Clustered)
-- 非聚集索引(NonClustered)
填充因子解释:http://blog.csdn.net/silentmuh/article/details/50403228
创建聚集索引时,因为有时要创建包含性列,比较特殊,所以举个例子:
create NonClustered index SuoYiin_Name on ActionInfo(ControllerName,ParID) include
(ActionID) WITH FILLFACTOR = 80
--这样就给ActionInfo表中的ControllerName和ParID创建了一个包含ActionID的非聚集索引
好啦,数据库优化就这么多啦,细节比较多,但是学会的话还是感觉挺简单的,快去动手试试吧~
SQL Server数据库性能优化的更多相关文章
- SQL Server数据库性能优化之SQL语句篇【转】
SQL Server数据库性能优化之SQL语句篇http://www.blogjava.net/allen-zhe/archive/2010/07/23/326927.html 近期项目需要, 做了一 ...
- Sql Server数据库性能优化之索引
最近在做SQL Server数据库性能优化,因此复习下一索引.视图.存储过程等知识点.本篇为索引篇,知识整理来源于互联网. 索引加快检索表中数据的方法,它对数据表中一个或者多个列的值进行结构排序,是数 ...
- SQL Server数据库性能优化之索引篇【转】
http://www.blogjava.net/allen-zhe/archive/2010/07/23/326966.html 性能优化之索引篇 近期项目需要, 做了一段时间的SQL Server性 ...
- SQL Server数据库性能优化技巧
查询速度慢的原因很多,常见如下几种: 1.没有索引或者没有用到索引: 2.I/O吞吐量小,形成了瓶颈效应: 3.内存不足: 4.网络速度慢: 5.查询出的数据量过大: 6.锁或者死锁: 7.返回了不必 ...
- SQL Server数据库性能优化(二)之 索引优化
参考文献 http://isky000.com/database/mysql-performance-tuning-index 原文作者是做mysql 优化的 但是我觉得 在索引方面 ...
- SQL Server数据库性能优化(一)之 优化SQL 语句
最近工作上基本没什么需求(好吧 不是最近是好久了,所以随便看看基础的东西来填补自己的空白) 原文出自:http://www.blogjava.net/allen-zhe/archive/2010/07 ...
- 转载——SQL Server数据库性能优化之SQL语句篇
转载自:http://www.blogjava.net/allen-zhe/archive/2010/07/23/326927.html 1. 按需索取字段,跟“SELECT *”说拜拜 字段的提取一 ...
- SQL SERVER数据库性能优化之SQL语句篇
(引用自重明鸟的博客,方便学习和查看) 1. 按需索取字段,跟“SELECT *”说拜拜 字段的提取一定要按照“用多少提多少”的原则,避免使用“SELECT *”这样的操作.做了这样一个实验,表tbl ...
- SQL Server 数据库性能优化
分析比较执行时间计划读取情况 1. 查看执行时间和cpu set statistics time on select * from Bus_DevHistoryData set statistics ...
随机推荐
- 在MyEclipse中使用debug模式
转:http://blog.csdn.net/competerh_programing/article/details/6773371 1, 首先在一个java文件中设断点,然后运行,当程序走到断点 ...
- Qt5 webview加载本地网页
文件结构 qtchart.pro QT += core gui webkitwidgets greaterThan(QT_MAJOR_VERSION, 4): QT += widgets TARGET ...
- 多态&接口
多态 多态定义:允许一个父类变量引用子类的对象:允许一个接口类型引用实现类对象. 多态的调用:使用父类的变量指向子类的对象:所调用的属性和方法只限定父类中定义的属性和方法,不能调用子类中特有的属性和方 ...
- 2017/01/20 学习笔记 关于修改和重打jar包
背景 客户提供了jar包,但发现db表中缺少一个字段,db追加以后需要修改jar包中的source. 操作 如何修改jar包中的source并重新打一个新的jar包,做了如下操作. ① 开包 解压j ...
- Swift 字典 Dictionary基本用法
import UIKit /* 字典的介绍 1.字典允许按照某个键访问元素 2.字典是由两部分组成, 一个键(key)集合, 一个是值(value)集合 3.键集合是不能有重复的元素, 值集合可以有重 ...
- Github 团队协作基本流程与命令操作 图解git工作流程
# 先 fork 项目到自己 github # 1. 从自己仓库克隆到本地(clone 的是项目指定的默认分支,比如 master) git clone git@github.com:me/em.gi ...
- 再谈json
接上一篇,省市三级联动的例子中,引入了1个QQ网站上的js文件.这个js中构造了一个地址对象,页面上我们所有的操作都跟这个对象关联.今天讨论这种对象怎么构造的问题. 前面写过一篇:浅谈Json数据格式 ...
- 修改XtraMessageBox的内容字体大小
修改XtraMessageBox的内容字体大小 public static DialogResult Show(UserLookAndFeel lookAndFeel, IWin32Window ow ...
- mysql进阶练习
一 . MySQL进阶练习 /*==========================创建班级表=============================*/ CREATE TABLE class ( ...
- 3.2、Ansible单命令测试
0.Ansible的group支持all.通配符(*).IP地址 1.查看Ansible的版本 $ ansbile --version [root@test ~]# ansible --versi ...