hadoop 3.x 服役 | 退役数据节点
在服役前要配置好新增主机的环境变量,ssh等信息,个人环境介绍
hadoop002(namenode),hadoop003(resourcemanager),hadoop004(secondarynamenode),准备新增hadoop005
一.服役数据节点
1.在namenode节点主机下的${HADOOP_HOME}/etc/hadoop/下创建dfs.hosts文件添加你要新增的主机名
hadoop002
hadoop003
hadoop004
hadoop005
2.打开hfds-site,xml,添加以下配置
<property>
<name>dfs.hosts</name>
<value>/opt/module/hadoop-3.1./etc/hadoop/dfs.hosts</value>
<description>Names a file that contains a list of hosts that are
permitted to connect to the namenode. The full pathname of the file
must be specified. If the value is empty, all hosts are
permitted.</description>
</property>
3.刷新namenode与yarn
hdfs dfsadmin -refreshNodes
yarn rmadmin -refreshNodes
此时在页面查看hadoop005状态,发现是dead
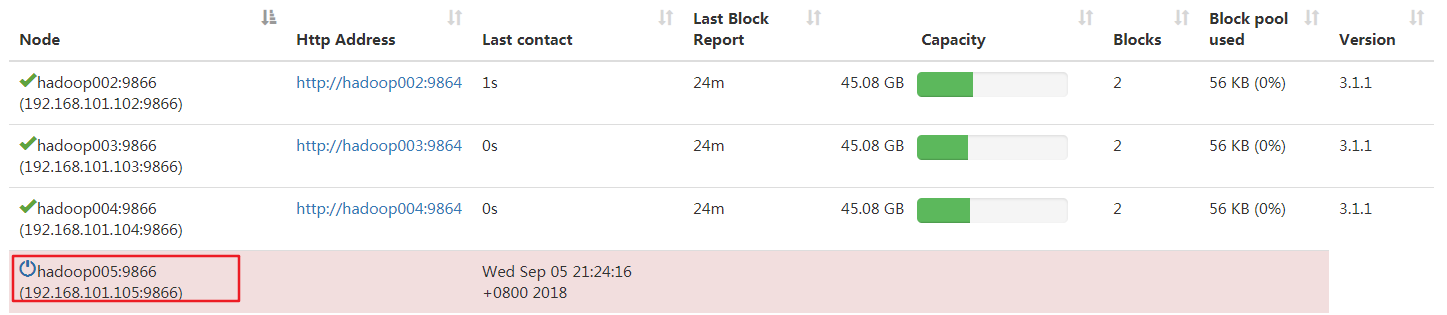
4.在hadoop005上启动datanode与nodemanager
hdfs --daemon start datanode
yarn --daemon start nodemanager
再次查看状态
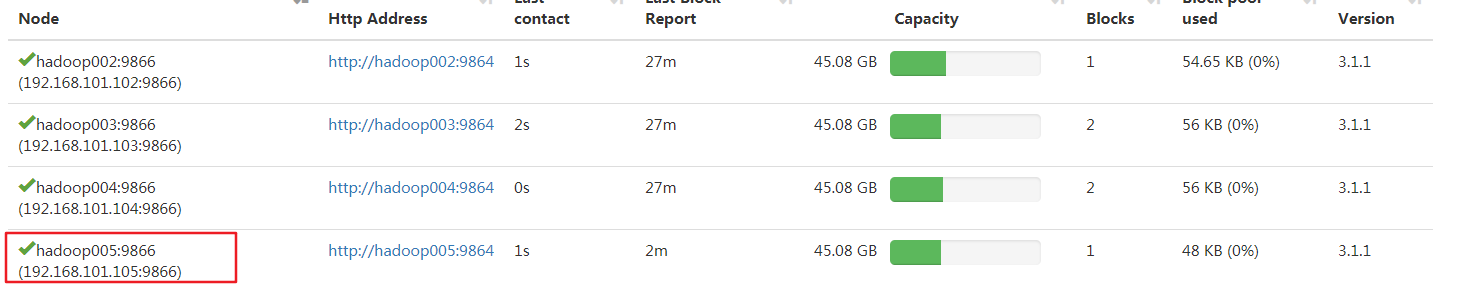
到这基本完成,但还需要在workers文件中添加主机名,以便下次执行start-dfs命令时能够直接启动新增的hadoop005节点
hadoop002
hadoop003
hadoop004
hadoop005
如果需要平衡数据的话,在执行下start-balancer.sh即可(记得修改分发脚本)
二.退役旧节点
1.在namenode节点主机下的${HADOOP_HOME}/etc/hadoop/下创建dfs.hosts.exclude文件添加你要退役的主机名
hadoop005
2.打开hfds-site,xml,添加以下配置
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-3.1./etc/hadoop/dfs.hosts.exclude</value>
<description>Names a file that contains a list of hosts that are
not permitted to connect to the namenode. The full pathname of the
file must be specified. If the value is empty, no hosts are
excluded.</description>
</property>
3.刷新namenode与yarn
hdfs dfsadmin -refreshNodes
yarn rmadmin -refreshNodes
此时在页面查看hadoop005状态,发现正在退役

继续等待,直到had005变成退役状态
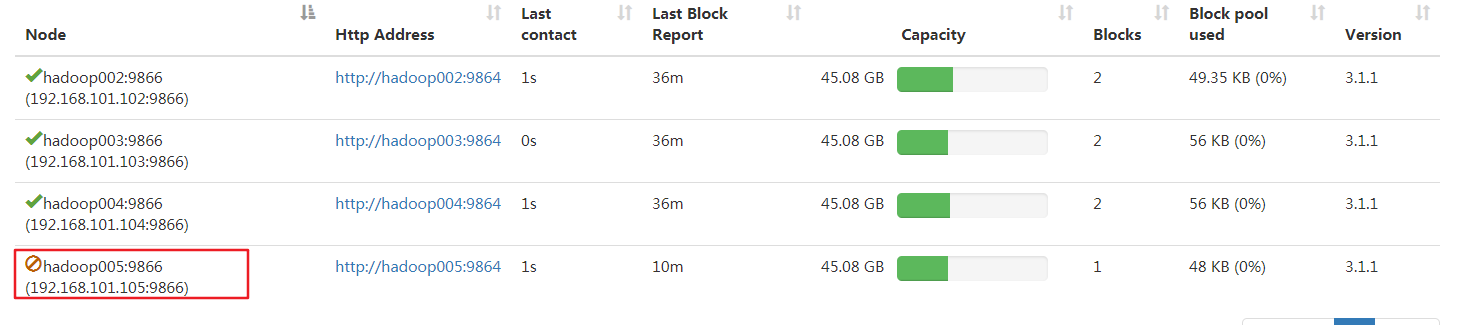
4.在hadoop005上停止namenode与nodemanager
hdfs --daemon stop datanode
yarn --daemon stop nodemanager
5.从dfs.hosts中删除hadoop005
6.再次刷新namenode与yarn后查看页面

7.从workers文件中删除hadoop005,这样执行start-dfs时就不会启动hadoop005上的datanode了
8.数据平衡start-balancer.sh
9.修改分发脚本
hadoop 3.x 服役 | 退役数据节点的更多相关文章
- Hadoop集群动态服役新的数据节点&&退役数据节点
备注:新添的机器为hadoop05,现有hadoop01.hadoop02.hadoop03.hadoop04 环境准备: 1.先克隆一台和集群中一样的机器 2.修改机器ip和主机名称 3.删除原来的 ...
- hadoop新增新数据节点和退役数据节点
新增数据节点 0. 需求随着公司业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点.1. 环境准备 (1)在hadoop03主机上再克 ...
- Hadoop源码分析之数据节点的握手,注册,上报数据块和心跳
转自:http://www.it165.net/admin/html/201402/2382.html 在上一篇文章Hadoop源码分析之DataNode的启动与停止中分析了DataNode节点的启动 ...
- Hadoop 添加删除数据节点(datanode)
前提条件: 添加机器安装jdk等,最好把环境都搞成一样,示例可做相应改动 实现目的: 在hadoop集群中添加一个新增数据节点. 1. 创建目录和用户 mkdir -p /app/hadoop gr ...
- hdfs 名称节点和数据节点
名字节点(NameNode )是HDFS主从结构中主节点上运行的主要进程,它指导主从结构中的从节点,数据节点(DataNode)执行底层的I/O任务. 名字节点是HDFS的书记员,维护着整个文件系统的 ...
- CentOS上安装Hadoop2.7,添加数据节点,运行wordcount
安装hadoop的步骤比较繁琐,但是并不难. 在CentOS上安装Hadoop2.7 1. 安装 CentOS,注:图形界面并无必要 2. 在CentOS里设置静态IP,手工编辑如下4个文件 /etc ...
- Hadoop 集群安装(从节点安装配置)
1.Java环境配置 view plain copy sudo mv /tmp/java /opt/ jdk安装完配置环境变量,编辑/etc/profile: view plain copy sudo ...
- Hadoop概念学习系列之Hadoop集群动态增加新节点或删除已有某节点及复制策略导向 (四十三)
不多说,直接上干货! hadoop-2.6.0动态添加新节点 https://blog.csdn.net/baidu_25820069/article/details/52225216 Hadoop集 ...
- HDFS中数据节点数据块存储示例
数据块在数据节点上是按照如下方式存储的. 首先是一个存储的根目录/Hadoop/data/dfs/dn,如下图所示: 接着进入current目录,如下图所示: 再进入后续的BP-433072574-1 ...
随机推荐
- iOS开发之CocoaPods(objective-c第三方库管理工具)
介绍: iOS开发中,大多数情况下,我们都须要集成一些第三方依赖库.对于一个稍大的项目,用到的第三方依赖库的数量也很可观.CocoaPods是objective-c第三方库管理工具,方便第三方库的管理 ...
- UVA 294 294 - Divisors (数论)
UVA 294 - Divisors 题目链接 题意:求一个区间内,因子最多的数字. 思路:因为区间保证最多1W个数字,因子能够遍历区间.然后利用事先筛出的素数求出质因子,之后因子个数为全部(质因子的 ...
- 百度2019校招Web前端工程师笔试卷(9月14日)
8月27日晚,在实习公司加班.当时正在调试页面,偶然打开百度首页console,发现彩蛋,于是投了简历. 9月14日晚,七点-九点,在公司笔试. 笔试题型(有出入): 一.单选20道 1.难度不难,考 ...
- 使用javascript实现图片上下切换效果并且实现顺序循环播放
<!doctype html><html lang="en"><head> <meta charset="UTF-8" ...
- [React Intl] Use Webpack to Conditionally Include an Intl Polyfill for Older Browsers
Some browsers, such as Safari < 10 & IE < 11, do not support the JavaScript Internationali ...
- 为什么我要选择erlang+go进行server架构(2)
原创文章,转载请注明出处:server非业余研究http://blog.csdn.net/erlib 作者Sunface 为什么我要选择Erlang呢? 一.erlang特别适合中小团队创业: erl ...
- TF卡电压 SD卡引脚
//////////////////////////////////////////////////////////////////////////////////////////////////// ...
- Docker搭建ES
Centos7安装ES 和 Docker搭建ES 文版权归博客园和作者吴双本人共同所有 转载和爬虫请注明原文地址 www.cnblogs.com/tdws 一.linux centos7.x安装ES ...
- 使用maven进行测试设置断点调试的方法
在Maven中配置测试插件surefire来进行单元测试,默认情况下,surefire会执行文件名以Test开头或结尾的测试用例,或者是以TestCase结尾的测试用例. ...
- nginx 代理服务器
目前现状:只有1个机器能上网(web),其他机器不能方法:能上网的做一个代理web服务器中转,其他机器连接它即可。采用nginxNginx配置如下:server{ resolver 8. ...