R语言-回归
定义:
回归是统计学的核心,它其实是一个广义的概念,通常指那些用一个或多个预测变量来预测响应变量.既:从一堆数据中获取最优模型参数
1.线性回归
1.1简单线性回归
案例:女性预测身高和体重的关系
结论:身高和体重成正比关系
fit <- lm(weight ~ height,data = women)
summary(fit)
plot(women$height,women$weight,xlab = 'Height inches',ylab = 'Weight pounds')
abline(fit)
1.2添加多项式来提升预测精度
结论:模型的方差解释率提升到99.9%,表示二次项提高了模型的拟合度
fit2 <- lm(weight ~ height + I(height^2),data = women)
summary(fit2)
plot(women$height,women$weight,xlab = 'Height inches',ylab = 'Weight pounds')
lines(women$height,fitted(fit2))

1.3多元线性回归
案例探究:探究美国州的犯罪率和其他因素的关系,包括人口,文盲率,平均收入,天气
结论:谋杀率和人口,文盲率呈正相关,和天气,收入呈负相关
states <- as.data.frame(state.x77[,c("Murder", "Population",
"Illiteracy", "Income", "Frost")])
cor(states)
library(car)
scatterplotMatrix(states,spread = F,smoother.args = list(lty=2),main='Scatter Plot Matrix')

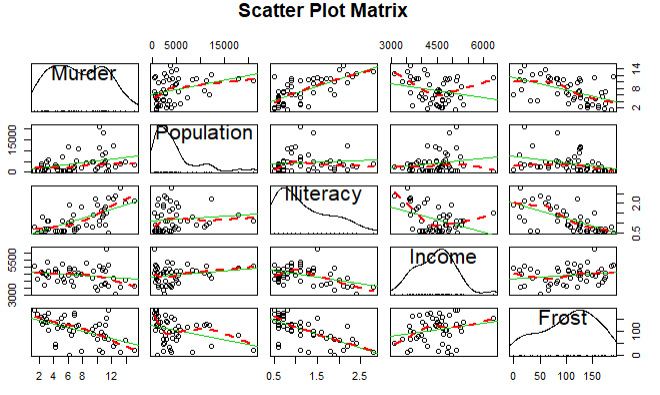
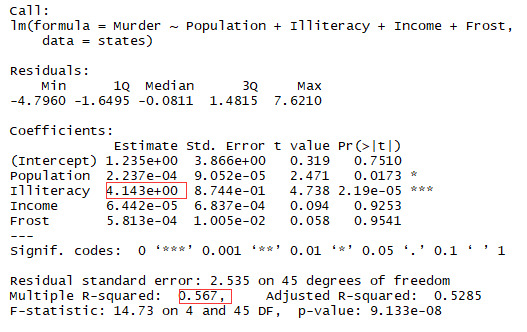
结论:文盲率的回归系数是4.14,说明在控制其他变量不变的情况下,文盲率提升1%,谋杀率就会提高4.14%
# 多元线性回归
1 fit3 <- lm(Murder~Population+Illiteracy+Income+Frost,data = states)
summary(fit3)
1.4回归诊断
结论:文盲率改变1%,谋杀率在95%的置信区间[2.38,5.9]之间变化,因为frost的置信区间包含0,所以可以认为温度的改变与谋杀率无关
confint(fit3)

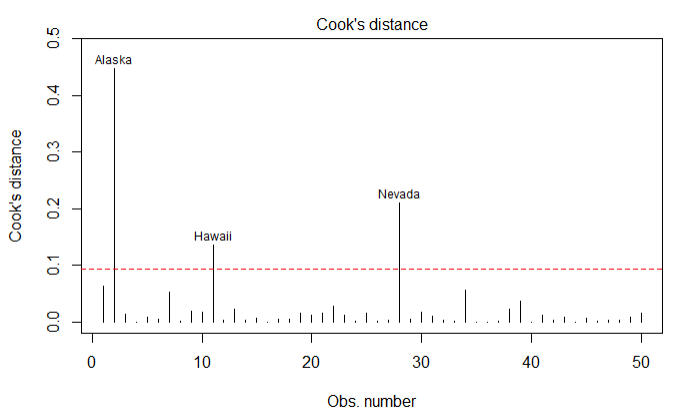
结论:除了Nevada一个点,其余的点都很好的符合了模型
par(mfrow=c(2,2))
plot(fit3)

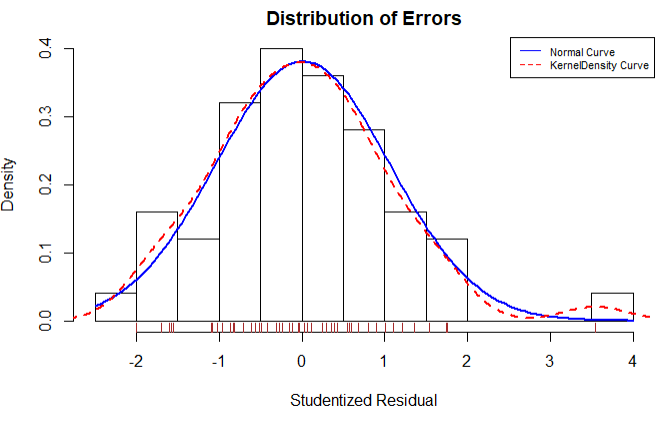
学生化残差分布图展示了除了Nevada一个离群点,其他点都很好的符合了模型
residplot <- function(fit,nbreaks=10){
z <- rstudent(fit)
hist(z,breaks = nbreaks,freq = F,xlab = 'Studentized Residual',main = 'Distribution of Errors')
rug(jitter(z),col = 'brown')
curve(dnorm(x,mean=mean(z),sd=sd(z)),add=T,col='blue',lwd=2)
lines(density(z)$x,density(z)$y,col='red',lwd=2,lty=2)
legend('topright',legend = c('Normal Curve','KernelDensity Curve'),lty = 1:2,col = c('blue','red'),cex = .7)
}
residplot(fit3)
1.5 异常观测值
1.5.1 离群点:指的是模型预测观测效果
此处可以看到Nevada是数据集中的离群点
library(car)
outlierTest(fit3)

1.5.2 高杠杆值点:与其他观测变量有关的离群点
可以通过以下的帽子图进行观测,,一般来说若帽子值的均值大于帽子均值的2倍或者3倍,就是高杠杆点
hat.plot <- function(fit){
p <- length(coefficients(fit3))
n <- length(fitted(fit3))
plot(hatvalues(fit3),main = 'Index Plot of Hat Values')
abline(h=c(2,3)*p/n,col='red',lty=2)
identify(1:n,hatvalues(fit3),names(hatvalues(fit3)))
}
hat.plot(fit3)

1.5.3强影响点:对模型参数影响有比例失调的点
使用cook's D值大于4/(n-k-1)表示是强影响点
cutoff <- 4/(nrow(states)-length(fit3$coefficients)-2)
plot(fit3,which=4,cook.levels=cutoff)
abline(h=cutoff,lty=2,col='red')
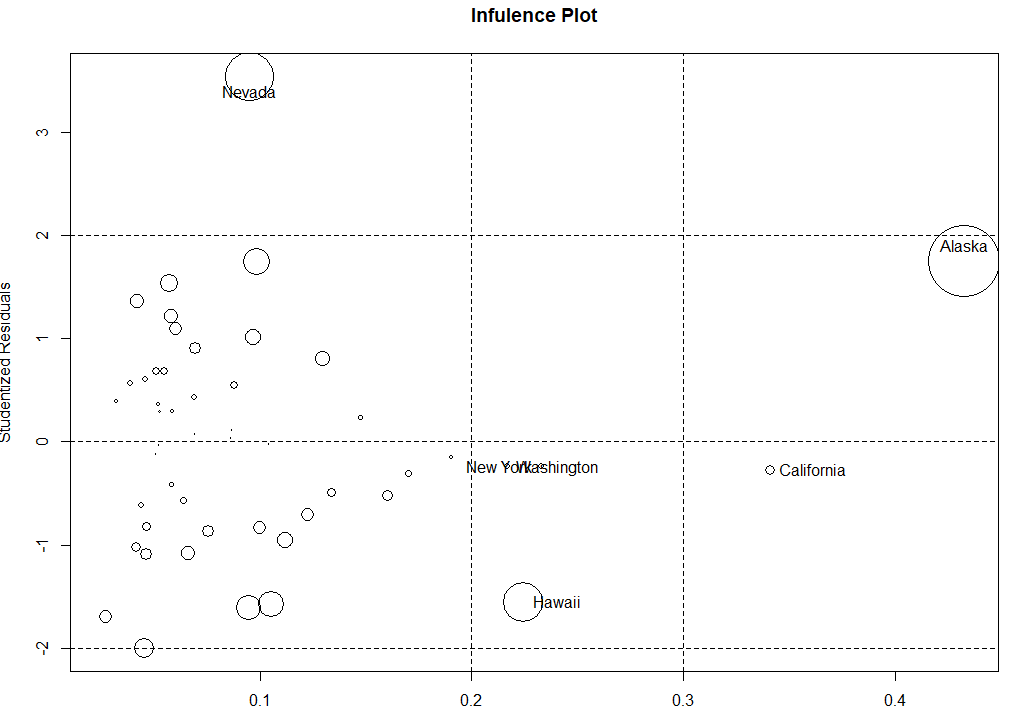
1.5.4还可以通过气泡图来展示哪些是离群点,强影响点和高杠杆值点
influencePlot(fit3,id.method='identify',main='Infulence Plot',sub='Circle size is proportional to cook distance')
1.6选择最佳的模型
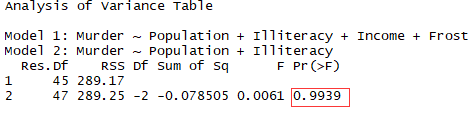
1.6.1使用anova比较
结论:由于检验不显著,不需要吧Income和Forst加入到变量中
fit5 <- lm(Murder ~ Population+Illiteracy,data = states)
anova(fit3,fit5)
1.6.2使用AIC比较
结论:同上
fit5 <- lm(Murder ~ Population+Illiteracy,data = states)
AIC(fit3,fit5)

1.6.3变量选择
结论:开始时模型包含4个变量,在每一步中,AIC列提供了一个删除变量后的AIC值第一次删除AIC从97.75下降到95.75,第二次从93.76,再删除变量会增加AIC所以回归停止
library(MASS)
stepAIC(fit3,direction = 'backward')

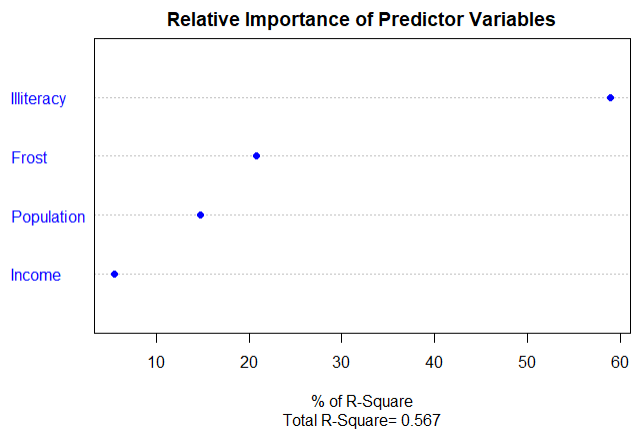
1.6.4使用自定义韩式计算相对权重
结论:可以看到每个预测变量对模型方差的解释程度和影响权重
relweights <- function(fit,...){
R <- cor(fit$model)
nvar <- ncol(R)
rxx <- R[2:nvar,2:nvar]
rxy <- R[2:nvar,1]
svd <- eigen(rxx)
evec <- svd$vectors
ev <- svd$values
delta <- diag(sqrt(ev))
lambda <- evec %*% delta %*% t(evec)
lambdasq <- lambda ^ 2
beta <- solve(lambda) %*% rxy
rsquare <- colSums(beta ^ 2)
rawwgt <- lambdasq %*% beta ^ 2
import <- (rawwgt / rsquare) * 100
import <- as.data.frame(import)
row.names(import) <- names(fit$model[2:nvar])
names(import) <- 'Weights'
import <- import[order(import),1,drop=F]
dotchart(import$Weights,labels = row.names(import),xlab = '% of R-Square',pch=19,
main = 'Relative Importance of Predictor Variables',
sub=paste('Total R-Square=',round(rsquare,digits = 3)),...)
return(import)
# 调用
24 relweights(fit3,col='blue')

R语言-回归的更多相关文章
- 用R语言的quantreg包进行分位数回归
什么是分位数回归 分位数回归(Quantile Regression)是计量经济学的研究前沿方向之一,它利用解释变量的多个分位数(例如四分位.十分位.百分位等)来得到被解释变量的条件分布的相应的分位数 ...
- 如何在R语言中使用Logistic回归模型
在日常学习或工作中经常会使用线性回归模型对某一事物进行预测,例如预测房价.身高.GDP.学生成绩等,发现这些被预测的变量都属于连续型变量.然而有些情况下,被预测变量可能是二元变量,即成功或失败.流失或 ...
- R语言实战(四)回归
本文对应<R语言实战>第8章:回归 回归是一个广义的概念,通指那些用一个或多个预测变量(也称自变量或解释变量)来预测响应变量(也称因变量.效标变量或结果变量)的方法.通常,回归分析可以用来 ...
- R语言︱XGBoost极端梯度上升以及forecastxgb(预测)+xgboost(回归)双案例解读
XGBoost不仅仅可以用来做分类还可以做时间序列方面的预测,而且已经有人做的很好,可以见最后的案例. 应用一:XGBoost用来做预测 ------------------------------- ...
- logistic逻辑回归公式推导及R语言实现
Logistic逻辑回归 Logistic逻辑回归模型 线性回归模型简单,对于一些线性可分的场景还是简单易用的.Logistic逻辑回归也可以看成线性回归的变种,虽然名字带回归二字但实际上他主要用来二 ...
- 【数据分析】线性回归与逻辑回归(R语言实现)
文章来源:公众号-智能化IT系统. 回归模型有多种,一般在数据分析中用的比较常用的有线性回归和逻辑回归.其描述的是一组因变量和自变量之间的关系,通过特定的方程来模拟.这么做的目的也是为了预测,但有时也 ...
- 分类-回归树模型(CART)在R语言中的实现
分类-回归树模型(CART)在R语言中的实现 CART模型 ,即Classification And Regression Trees.它和一般回归分析类似,是用来对变量进行解释和预测的工具,也是数据 ...
- R 再也不用愁变量太多跑回归太麻烦!R语言循环常用方法总结
在高维数据分析过程中,为了筛选出与目标结局相关的变量,通常会用到回归分析,但是因为自变量较多,往往要进行多次回归.这就是统计编程语言发挥作用的时候了 有些大神们认为超过3次的复制粘贴就可以考虑使用循环 ...
- 【机器学习与R语言】6-线性回归
目录 1.理解回归 1)简单线性回归 2)普通最小二乘估计 3)相关系数 4)多元线性回归 2.线性回归应用示例 1)收集数据 2)探索和准备数据 3)训练数据 4)评估模型 5)提高模型性能 1.理 ...
随机推荐
- 紫书 例题 9-2 UVa 437 ( DAG的动态规划)
很明显可以根据放不放建边,然后最一遍最长路即是答案 DAG上的动态规划就是根据题目中的二元关系来建一个 DAG,然后跑一遍最长路和最短路就是答案,可以用记忆化搜索的方式来实现 细节:(1)注意初始化数 ...
- 洛谷—— P2580 于是他错误的点名开始了
https://www.luogu.org/problem/show?pid=2580 题目背景 XS中学化学竞赛组教练是一个酷爱炉石的人. 他会一边搓炉石一边点名以至于有一天他连续点到了某个同学两次 ...
- C#获得文件夹下文件名
String path = @"X:\xxx\xxx"; //第一种方法 var files = Directory.GetFiles(path, "*.txt" ...
- Reuse Is About People and Education, Not Just Architecture
 Reuse Is About People and Education, Not Just Architecture Jeremy Meyer you MigHT AdopT THE AppRoA ...
- jquery源码12 offset() : 位置和尺寸的方法
// Back Compat <1.8 extension point jQuery.fx.step = {}; if ( jQuery.expr && jQuery.expr. ...
- 34.Intellij IDEA 安装lombok及使用详解
转自:https://blog.csdn.net/qinxuefly/article/details/79159018 项目中经常使用bean,entity等类,绝大部分数据类类中都需要get.set ...
- | 插件下载陈磊SQL MD5 加密
简介:SQL MD5 加密 下述是 SQL Server 中 MD5加密 16位和32位的 ,)) ,ModifiedOn=null ; ,)) ,ModifiedOn=null ;
- chkconfig---检查设置系统服务
chkconfig命令 chkconfig命令检查.设置系统的各种服务.这是Red Hat公司遵循GPL规则所开发的程序,它可查询操作系统在每一个执行等级中会执行哪些系统服务,其中包括各类常驻服务 ...
- watch---周期性的方式执行给定的指令
watch命令以周期性的方式执行给定的指令,指令输出以全屏方式显示. 选项 -n:指定指令执行的间隔时间(秒): -d:高亮显示指令输出信息不同之处: -t:不显示标题.
- JavaScript学习总结(8)——JS实用技巧总结
后退 前进 <!--<input type="button" value="后退" onClick="history.go(-1)&quo ...