小白学习Spark系列六:Spark调参优化
前几节介绍了下常用的函数和常踩的坑以及如何打包程序,现在来说下如何调参优化。当我们开发完一个项目,测试完成后,就要提交到服务器上运行,但运行不稳定,老是抛出如下异常,这就很纳闷了呀,明明测试上没问题,咋一到线上就出bug了呢!别急,我们来看下这bug到底怎么回事~
一、错误分析
1、参数设置及异常信息
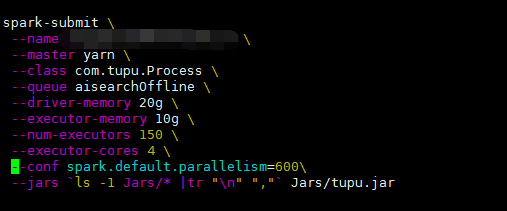
18/10/08 16:23:51 WARN TransportChannelHandler: Exception in connection from /10.200.2.95:40888
java.io.IOException: Connection reset by peer
at sun.nio.ch.FileDispatcherImpl.read0(Native Method)
at sun.nio.ch.SocketDispatcher.read(SocketDispatcher.java:39)
at sun.nio.ch.IOUtil.readIntoNativeBuffer(IOUtil.java:223)
at sun.nio.ch.IOUtil.read(IOUtil.java:192)
at sun.nio.ch.SocketChannelImpl.read(SocketChannelImpl.java:380)
at io.netty.buffer.PooledUnsafeDirectByteBuf.setBytes(PooledUnsafeDirectByteBuf.java:221)
at io.netty.buffer.AbstractByteBuf.writeBytes(AbstractByteBuf.java:899)
at io.netty.channel.socket.nio.NioSocketChannel.doReadBytes(NioSocketChannel.java:275)
at io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:119)
at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:652)
at io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:575)
at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:489)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:451)
at io.netty.util.concurrent.SingleThreadEventExecutor$2.run(SingleThreadEventExecutor.java:140)
at io.netty.util.concurrent.DefaultThreadFactory$DefaultRunnableDecorator.run(DefaultThreadFactory.java:144)
at java.lang.Thread.run(Thread.java:745)
18/10/08 16:23:51 ERROR TransportResponseHandler: Still have 1 requests outstanding when connection from /10.200.2.95:40888 is closed
2、分析原因
运行的程序其实逻辑上比较简单,只是从hive表里读取的数据量很大,差不多60+G,并且需要将某些hive表读取到dirver节点上,用来获取每个executor上某些数据的映射值,所以driver设定的资源较大。运行时抛出的异常信息,从网上查了下原因大致是服务器的并发连接数超过了其承载量,服务器会将其中一些连接Down掉,这也就是说在运行spark程序时,过多的申请资源并发执行。那应该怎样去合理设置参数才能最大化提升并发的性能呢?这些参数又分别代表什么?
二、常见参数及含义
|
常用参数 |
含义及建议 |
|
spark.executor.memory (--executor-memory) |
含义:每个执行器进程分配的内存 建议:该设置需要和下面的executor-num数一起考虑,一般设置为4G~8G如果和其他人共用队列,为防止独占资源建议memory*num <= 资源队列最大总内存*(1/2~1/3) |
|
spark.executor.num (--executor-num) |
含义:设置用来执行spark作业的执行器进程的个数 建议:一般设置为50~100个,设置太少会导致无法充分利用资源,太多又导致大部分任务分配不到充足的资源 |
|
spark.executor.cores (--executor-cores) |
含义:每个执行器进程的cpu core数量,决定了执行器进程并发执行task线程的个数,一个core同一时间只能执行一个task线程。如果core数量越多,完成自己task越快。 建议:一般设置2~4个,需要和executor-num一起考虑,num*core<=队列总core*(1/2~1/3) |
|
spark.driver.memory (--driver-memory) |
含义:设置驱动进程的内存 建议:driver一般不设置,默认的就可以,不过如果你在程序中需要使用collect算子拉取rdd到驱动节点上,那就得设置相应的内存大小(大于几十k建议使用广播变量) |
| spark.default.parallelism |
含义:设置每个stage的默认任务数量 建议:官方建议设置为 executor-num*executor-cores的2~3倍 |
| spark.storage.memoryFraction |
含义:默认Executor 60%的内存,可以用来保存持久化的RDD数据 建议:spark作业中,如果有较多rdd需要持久化,该参数可适当提高一些,保证持久化的数据存储在内存中,避免被写入磁盘影响运行速度。如果shuffle类操作较多,可调低该参数。并且如果由于频繁的垃圾回收导致运行缓慢,证明执行task的内存不够用,建议调低该参数。 |
| spark.shuffle.memoryFraction |
含义:设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例 建议:shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。结合上一个参数调整。 |
| spark.speculation |
含义:设为true时开启task预测执行机制。当出现较慢的任务时,这种机制会在另外的节点尝试执行该任务的一个副本。 建议:true,打开此选项会减少大规模集群中个别较慢的任务带来的影响。 |
| spark.storage.blockManagerTimeoutIntervalMs |
含义:内部通过超时机制追踪执行器进程是否存活的阈值。 建议:对于会引发长时间垃圾回收(GC)暂停的作业,需要把这个值调到100秒(100000)以防止失败。 |
| spark.sql.shuffle.partitions |
含义:配置join或者聚合操作shuffle数据时分区的数量,默认200 建议:同spark.default.parallelism |
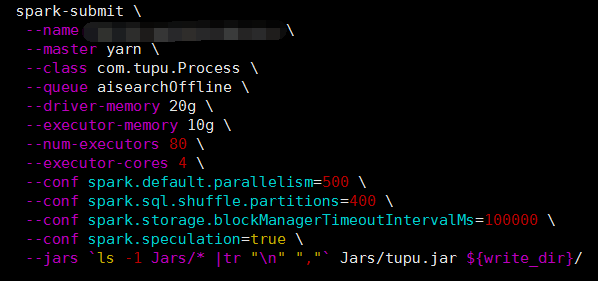
三、实践
通过适当调整以上讲到的几个参数,降低spark.default.parallelism的同时又设置了spark.sql.shuffle.partitions、spark.speculation、spark.storage.blockManagerTimeoutIntervalMs三个参数。由于项目中频繁的读取hive表数据,并进行连接操作,所以在shuffle阶段增大了partitions。对于woker倾斜,设置spark.speculation=true,把预测不乐观的节点去掉来保证程序可稳定运行,通过这几个参数的调整这样并大大减少了运行时间。
小白学习Spark系列六:Spark调参优化的更多相关文章
- Spark 模型选择和调参
Spark - ML Tuning 官方文档:https://spark.apache.org/docs/2.2.0/ml-tuning.html 这一章节主要讲述如何通过使用MLlib的工具来调试模 ...
- 贪玩ML系列之CIFAR-10调参
调参方法:网格调参 tf.layers.conv2d()中的padding参数 取值“same”,表示当filter移出边界时,给空位补0继续计算.该方法能够更多的保留图像边缘信息.当图片较小(如CI ...
- Spark系列(六)Master注册机制和状态改变机制
各组件的注册流程如下图: 注册机制源码说明: 入口:org.apache.spark.deploy.master文件下的receiveWithLogging方法中的case RegisterAppli ...
- Spark系列—01 Spark集群的安装
一.概述 关于Spark是什么.为什么学习Spark等等,在这就不说了,直接看这个:http://spark.apache.org, 我就直接说一下Spark的一些优势: 1.快 与Hadoop的Ma ...
- Spark系列—02 Spark程序牛刀小试
一.执行第一个Spark程序 1.执行程序 我们执行一下Spark自带的一个例子,利用蒙特·卡罗算法求PI: 启动Spark集群后,可以在集群的任何一台机器上执行一下命令: /home/spark/s ...
- jvm系列(六):jvm调优-从eclipse开始
jvm调优-从eclipse开始 概述 什么是jvm调优呢?jvm调优就是根据gc日志分析jvm内存分配.回收的情况来调整各区域内存比例或者gc回收的策略:更深一层就是根据dump出来的内存结构和线程 ...
- [纯小白学习OpenCV系列]官方例程00:世界观与方法论
2015-11-11 ----------------------------------------------------------------------------------- 其实,写博 ...
- jvm系列(六):jvm调优-工具篇
## jdk自带的工具### jconsole Jconsole(Java Monitoring and Management Console)是从java5开始,在JDK中自带的java监控和管理控 ...
- [纯小白学习OpenCV系列]官方例程01:Load and Display an Image
Version: OpenCV 2.4.9 IDE : VS2010 OS : Windows --------------------------------------------- ...
随机推荐
- netty心跳机制和断线重连(四)
心跳是为了保证客户端和服务端的通信可用.因为各种原因客户端和服务端不能及时响应和接收信息.比如网络断开,停电 或者是客户端/服务端 高负载. 所以每隔一段时间 客户端发送心跳包到客户端 服务端做出心 ...
- JAVA版本号微信公众账号开源项目版本号公布-jeewx1.0(捷微)
JeeWx, 敏捷微信开发,简称"捷微". 捷微是一款免费开源的微信公众账号开发平台. 平台介绍: 一.简单介绍 jeewx是一个开源,高效.敏捷的微信开发平台採用JAVA语言,它 ...
- Java中的事务
Java中的事务 学习了:https://www.cnblogs.com/chengpeng15/p/5802930.html 膜拜一下 org 分为三类:jdbc事务.jta事务.容器事务:
- MySQL优化之——为用户开通mysql权限
转载请注明出处:http://blog.csdn.net/l1028386804/article/details/46627263 为用户开通mysql权限: grant all privileges ...
- CentOS 7通过yum安装fcitx五笔输入法
CentOS 7通过yum安装fcitx五笔输入法 下面通过了亲測: 1.设置源 Posted in Linux at 三月 5th, 2015 / No Comments ? 增加EPEL源 EPE ...
- URAL 1826. Minefield(数学 递归)
题目链接:http://acm.timus.ru/problem.aspx? space=1&num=1826 1826. Minefield Time limit: 0.5 second M ...
- java中String的21种使用方法
(构造函数必须new出来) * public String (char[] vaue) 将一个字符数组变成字符串(构造函数) * public Stri ...
- PDF.NET支持最新的SQLite数据库
最近项目中用到了SQLite,之前项目中用的是PDF.NET+MySQL的组合,已经写了不少代码,如果能把写好的代码直接用在SQLite上就好了,PDF.NET支持大部分主流的数据库,这个当然可以,只 ...
- 分布式系统CAP原则与BASE思想
一.CAP原则 CAP原则又称CAP定理,指的是在一个分布式系统中, Consistency(一致性). Availability(可用性).Partition tolerance(分区容错性),三者 ...
- Gym-101915D Largest Group 最大独立集 Or 状态压缩DP
题面题意:给你N个男生,N个女生,男生与男生之间都是朋友,女生之间也是,再给你m个关系,告诉你哪些男女是朋友,最后问你最多选几个人出来,大家互相是朋友. N最多为20 题解:很显然就像二分图了,男生一 ...