百度Tera数据库介绍——类似cassandra,levelDB
转自:https://my.oschina.net/u/2982571/blog/775452
设计背景
百度的链接处理系统每天处理万亿级的超链数据,在过去,这是一系列Mapreduce的批量过程,对时效性收录很不友好。在新一代搜索引擎架构设计中,我们采用流式、增量处理替代了之前的批量、全量处理。链接从被发现到存入链接库再到被调度程序选出,变成一个全实时的过程。在这个实时处理过程中,无论链接的入库还是选取,都需要对链接库进行修改,存储系统需要支持千万甚至上亿QPS的随机读写。旧的存储系统无论在单机性能,还是在扩展性方面,都无法满足,所以我们设计了Tera。
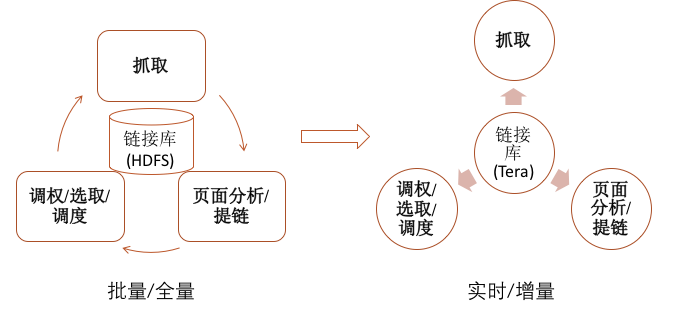
链接存储的需求
1. 数据按序存储
支持主域、站点和前缀等多维度统计、读取。
2. 自动负载均衡
分区可以动态调整,在一个分区数据量变大或者访问频率过高时,可以自动切分,小的分区也可以自动合并。
3. 记录包含时间戳和多个版本
对于链接历史抓取状态等记录,需要保留多个版本,对于策略回灌等场景,需要根据时间戳判断,避免旧的数据覆盖新的。
4. 强一致性
写入成功,立即可被所有的用户看到。
5. 支持列存储
在用户只访问固定的少数几列时,能使用更小的IO,提供更高的性能(相对于访问全记录),要求底层存储将这部分列在物理上单独存储。
设计目标
功能目标
1. 全局有序
key可以是任意字符串(二进制串),不限长度,比较逻辑可由用户定义,按Key的范围分区,分区内由单机维护有序,分区间由Master维护有序。
2. 多版本
每个字段(单元格)都可以保留指定多个版本,系统自动回收过期版本,用户可以按时间戳存取。
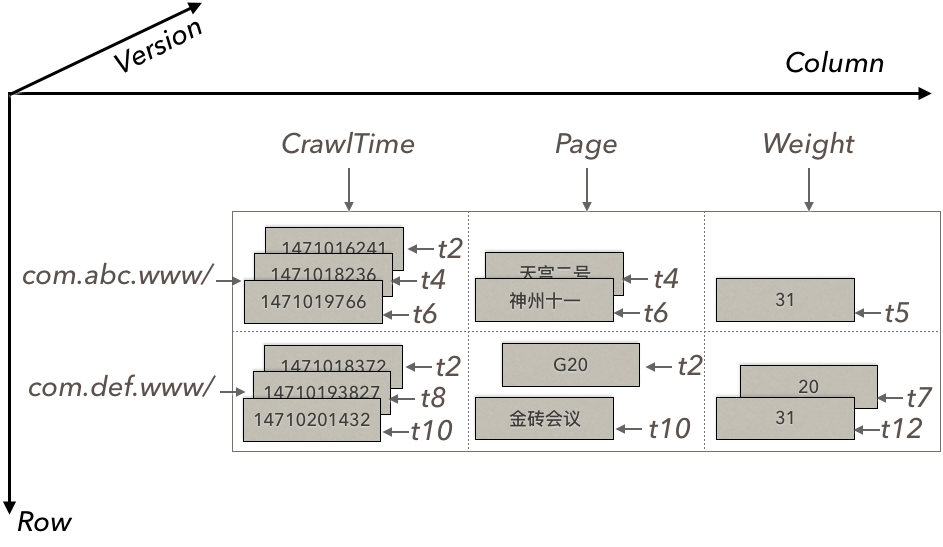
3. 自动分片
用户不需要关心分片信息,系统自动处理热点区间的分裂,数据稀疏区间的合并。
单个分区的数据量超过阈值,自动切分为多个,单个分区的读写频率增高时,自动切分。
4. 自动负载均衡和扩容
单机上保存多个分区,分区的总大小和总访问量达到阈值时,可以触发将部分分区迁移到空闲的机器。
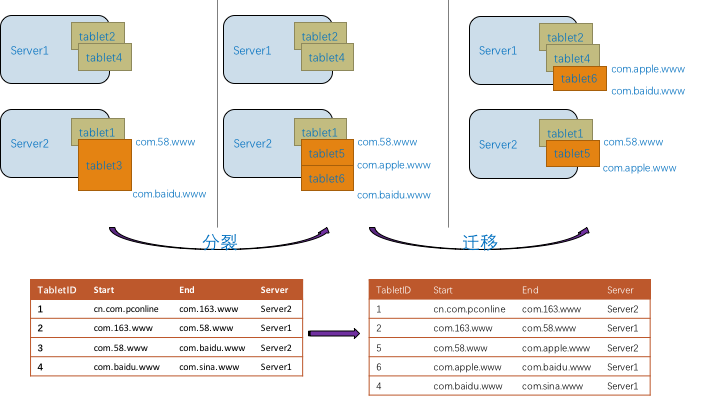
性能指标
Tera设计使用SSD+SATA磁盘混布机型。
1. 单机吞吐
顺序读写: 100MB/S
随机读1KB: 30000QPS
随机写1KB: 30000QPS
2. 延迟
延迟和吞吐需要折衷考虑,在延迟敏感性不高的场合,使用延迟换吞吐策略,延迟定位在10ms级,写操作延迟<50ms,读延迟<10ms。
对于对延迟要求高的场合,读写延迟定位在<1ms,但吞吐会有损失,初期不做优化重点。
3. 扩展性
水平扩展至万台级别机器,单机管理百级别数据分片。
| 数据量 | 系统吞吐 | |
|---|---|---|
| 站点信息服务 | 10TB | 百亿次/天 |
| 用户行为分析 | 1PB | 百亿次/天 |
| 超链存储 | 10PB | 万亿次/天 |
| 页面存储 | 100PB | 万亿次/天 |
设计思路
数据存储
1. 数据持久性
为保证数据安全性,要使用三副本存储,但维护副本的一致性与副本丢失恢复需要处理大量细节,基于一个分布式的文件系统构建,可以显著降低开发代价,所以我们选择了使用DFS(如BFS)。
系统的所有数据(用户数据和系统元数据)都存储在DFS上,通过DFS+WriteAheadLog保证数据的持久性,每次写入,保证在DFS上三副本落地后,才返回成功。
2. 强一致性
数据会按key分区存储在DFS上,分区信息由Master统一管理,Master保证每个分区同一时间只由一个数据节点提供读写服务,保证一致性。
3. 延迟换吞吐
每次写操作落地一次导致的性能问题可以通过批量落地实现,比如每10ms数据落地一次,在数据落地前写操作不返回,代价是增加了5ms的平均响应时间。
4. 存储接口封装
Tera不会以某一种DFS作为唯一选择,而是通过底层存储接口的封装,使其可搭建在其他分布式存储之上,方便用户根据个性化需求灵活地部署Tera。
希望了解更多?请点击 https://github.com/baidu/tera
百度Tera数据库介绍——类似cassandra,levelDB的更多相关文章
- 数据库介绍(MySQL安装 体系结构、基本管理)
第1章 数据库介绍及mysql安装 1.1 数据库简介 数据库,简而言之可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的数据运行新增.截取.更新.删除等操作. 所谓“数据库”系以一定方式 ...
- MongoDB:数据库介绍与基础操作
二.部署在本地服务器 在上次的学习过程中,我们主要进行了MongoDB运行环境的搭建和可视化工具的安装.此次我们将学习MongoDB有关的基本概念和在adminmongo上的基本操作.该文档中的数据库 ...
- 【转】数据库介绍(MySQL安装 体系结构、基本管理)
[转]数据库介绍(MySQL安装 体系结构.基本管理) 第1章 数据库介绍及mysql安装 1.1 数据库简介 数据库,简而言之可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的数据运行新 ...
- Redis数据库介绍
引言 redis是一个开源的.使用C语言编写的.支持网络交互的.可基于内存也可持久化的Key-Value数据库. redis数据结构 redis是一种高级的key:value存储系统,其中value支 ...
- 数据库介绍以及MySQL数据库的使用
一 数据库介绍 1.1 数据库定义 数据库就是存储数据的仓库 本质上就是一套cs结构的TCP程序 客户端连接到服务器 向服务器发送指令 完成数据的操作 1.2 常见数据库 关系型数据库 就是 ...
- mariadb_1 数据库介绍及基本操作
数据库介绍 1.什么是数据库? 简单的说,数据库就是一个存放数据的仓库,这个仓库是按照一定的数据结构(数据结构是指数据的组织形式或数据之间的联系)来组织,存储的,我们可以通过数据库提供的多种方法来管理 ...
- 华为云数据库GaussDB(for Cassandra)揭秘第二期:内存异常增长的排查经历
摘要:华为云数据库GaussDB(for Cassandra) 是一款基于计算存储分离架构,兼容Cassandra生态的云原生NoSQL数据库:它依靠共享存储池实现了强一致,保证数据的安全可靠. 本文 ...
- Mysql 数据库介绍
数据库介绍 数据库(Database)是按照数据结构来组织.存储和管理数据的仓库,每个数据库都有一个或多个不同的API接口用于创建,访问,管理,搜索和复制所保存的数据. 我们也可以将数据存储在文件中, ...
- INFORMATION_SCHEMA数据库介绍
删除mysql数据库某一张主键表的所有外键关系 SELECT CONCAT('alter table ', TABLE_NAME , ' drop foreign key ', constraint_ ...
随机推荐
- 面向对象的JavaScript系列一,创建对象
1.最简单的创建对象方法 var person = new Object(); person.name = "sam wu"; person.age = 25; person.jo ...
- 泰信---->20131025~20131101(周计划安排)
学习java相关知识计划安排: [前期复习阶段] (一)熟悉java相关语言基础. (二)搭建一个纯web项目工程,实现增加,删除,修改,查询以及分页...功能. (三)熟悉jboss的使用和相关配置 ...
- bootstrap-datepicker 日期格式设置
[参考文档]http://bootstrap-datepicker.readthedocs.org/en/latest/ datepicker插件默认是时间格式为mm/dd/yyyy,如何更改时间的格 ...
- iOS - UITouch
前言 NS_CLASS_AVAILABLE_IOS(2_0) @interface UITouch : NSObject @available(iOS 2.0, *) public class UIT ...
- iOS - UIWebView
前言 NS_CLASS_AVAILABLE_IOS(2_0) __TVOS_PROHIBITED @interface UIWebView : UIView <NSCoding, UIScrol ...
- web设计经验<一> 提升移动设备响应式设计的8个建议
今天看到一些关于web设计的一些建议和设计经验,拿出来分享分享. 第一篇: 提升移动设备响应式设计的8个建议 一.直观性和易用性 在使用移动设备时,对于杂乱.复杂或者不直观的设计造成的混乱不佳的用户体 ...
- 关于ASP.NET的web.config的小笔记
在ASP和MVC开发中,有一些参数是需要活动更改的,最常见的就是数据库的链接字符串<connectionStrings>节点下配置的.在今天接触的项目中,我又接触到了自定义配置参数,就是可 ...
- Python学习(3)变量类型
目录 变量赋值 多个变量赋值 标准数据类型 Python数字 Python字符串 Python列表 Python元组 Python元字典 Python数据类型转换 type数据类型查看 变量赋值 Py ...
- mysql 存储过程中limit
1.mysql的高版本(5.5),存储过程中的limit可以使用变量,如下:select * from student limit iStart,iNum; 2.mysql的低版本(5.1),存储过程 ...
- 【转载】【Oracle 11gR2】db_install.rsp详解
[原文]http://blog.csdn.net/jameshadoop/article/details/48086933 ###################################### ...