salesforce零基础学习(一百三十)Report 学习进阶篇
本篇参考:
https://help.salesforce.com/s/articleView?id=sf.reports_summary_functions_about.htm&type=5
https://www.youtube.com/watch?v=bjgZTgYe_84
在Salesforce Admin篇(二) Report中,我们讲过report的一些基础知识,实际工作中往往有些场景比这些复杂很多,接下来根据实际工作中的部分场景进行知识扩展。本篇主要讲解3个内容: PARENTGROUPVAL and PREVGROUPVAL & Power Of 1.
引言: 在salesforce的report中,官方封装了很多的函数,基于不同的函数来进行不同的场景处理。有一些我们比较熟悉的类似formula的函数IF等,用起来很方便,除此以外还有两个特殊的函数:PARENTGROUPVAL and PREVGROUPVAL,使用 PARENTGROUPVAL 计算相对于一个父分组的值,使用 PREVGROUPVAL 计算相对于同级分组的值。接下来对这两者进行展开。
一. PARENTGROUPVAL
此函数返回指定父分组的值。父 "分组是指包含公式的分组之上的任何层级。
针对Summary Report以及Join Report,我们使用这个函数包含两个参数:PARENTGROUPVAL(summary_field, grouping_level)
针对Matrix Report,我们使用这个函数包含三个参数:PARENTGROUPVAL(summary_field, parent_row_grouping, parent_column_grouping)
我们对这三个参数进行一下解释:
- summary_field:汇总的字段的值。举个例子: 第一个参数使用TOTAL_PRICE:SUM代表我们返回指定父分组的值,分组的值基于 TOTAL_PRICE字段进行SUM汇总。再举一个例子: 第一个参数使用RowCount,这个是report的字段,代表对指定分组进行计数操作,返回的结果将是某个指定分组的数据的数量。
- parent_row_grouping:针对Summary Report以及Join Report,第二个参数即row_grouping。row_grouping可以有两个值: GRAND_SUMMARY以及分组字段的API NAME。 其中GRAND_SUMMARY代表着整体数量,即Report下方的Grand Total选项勾选的数量效果。指定分组字段的API Name代表着某个子分组的范围。
- parent_column_grouping用法和parent_row_grouping用法相同并且参数值也相同。
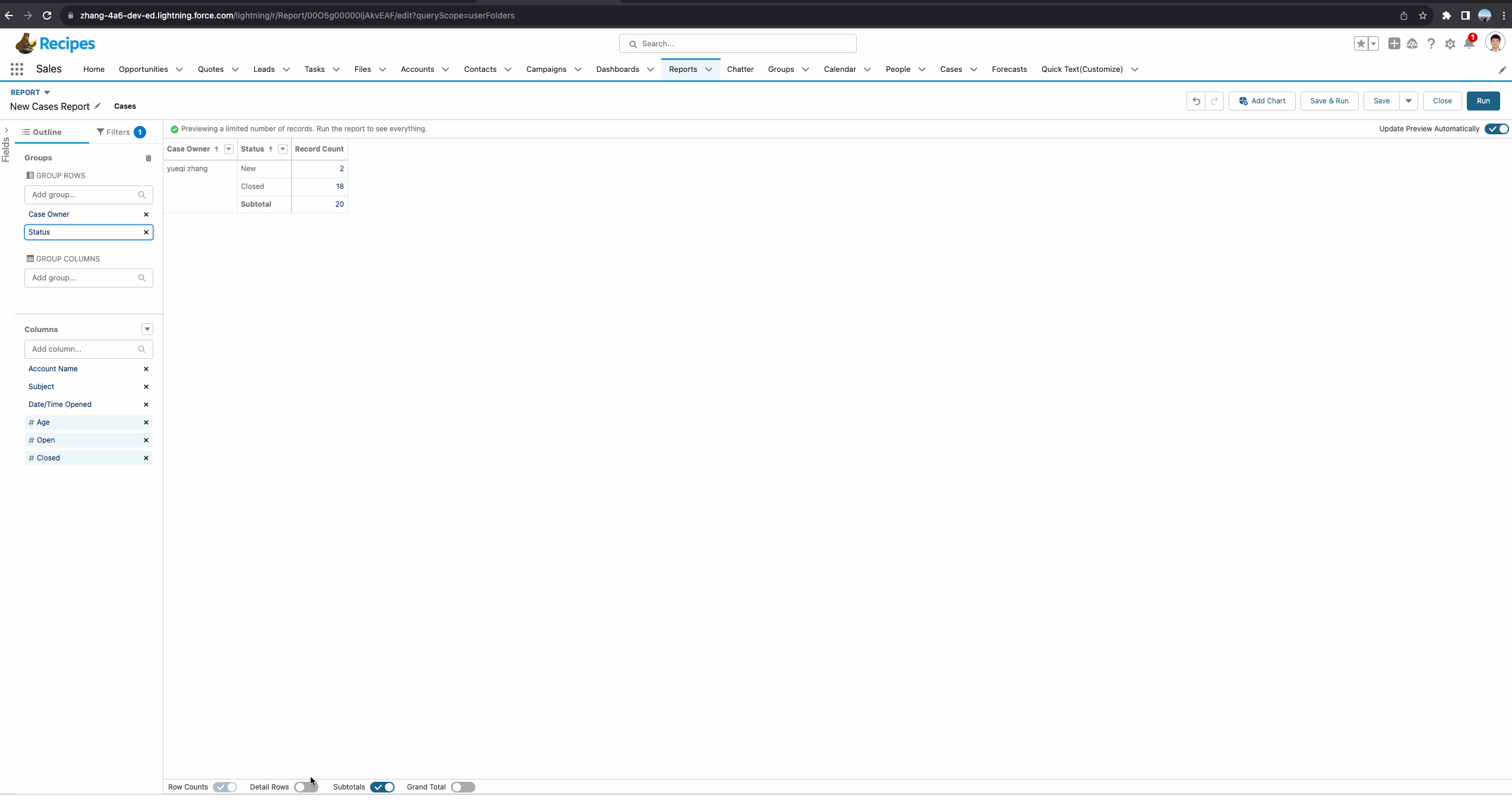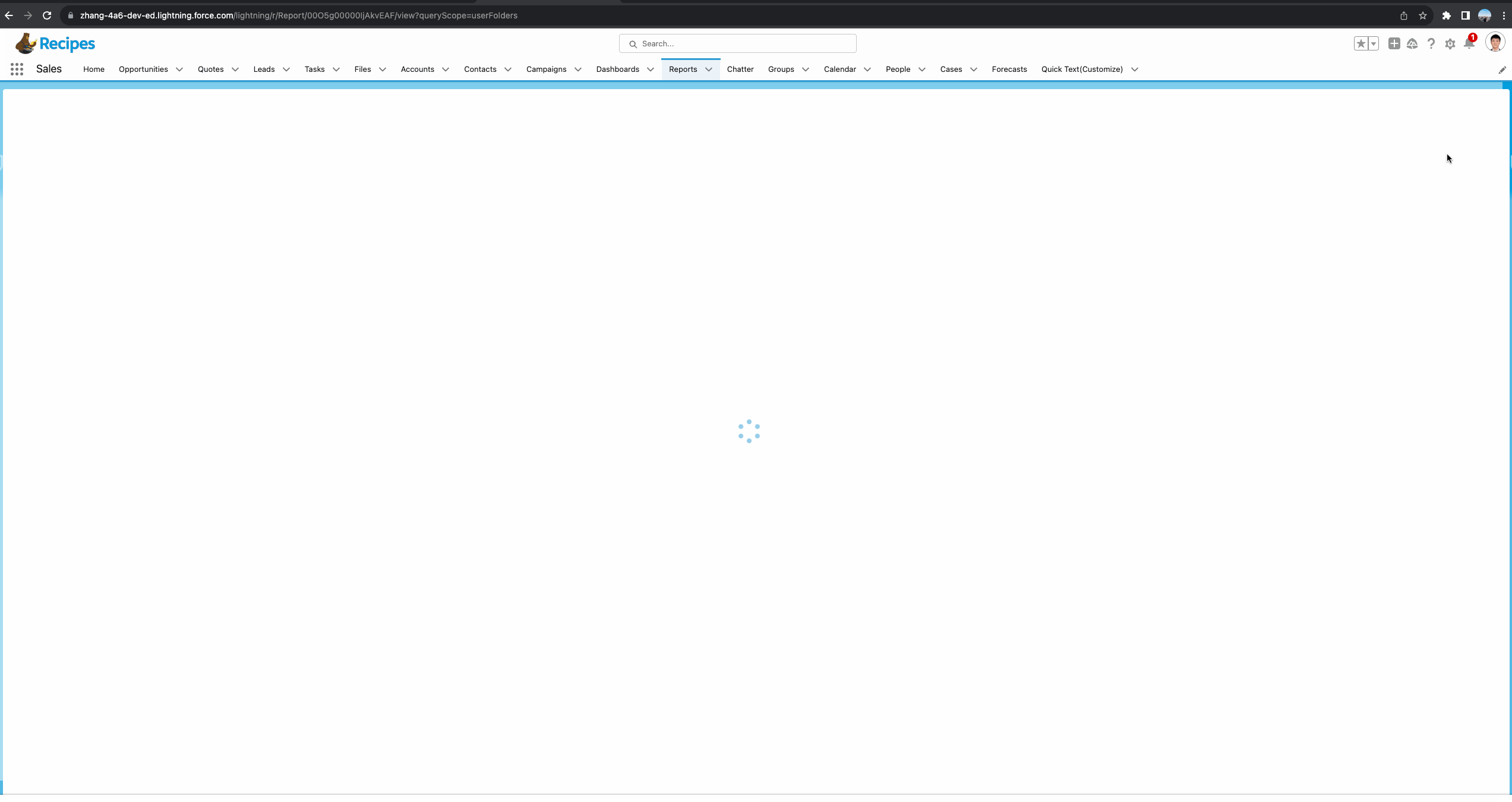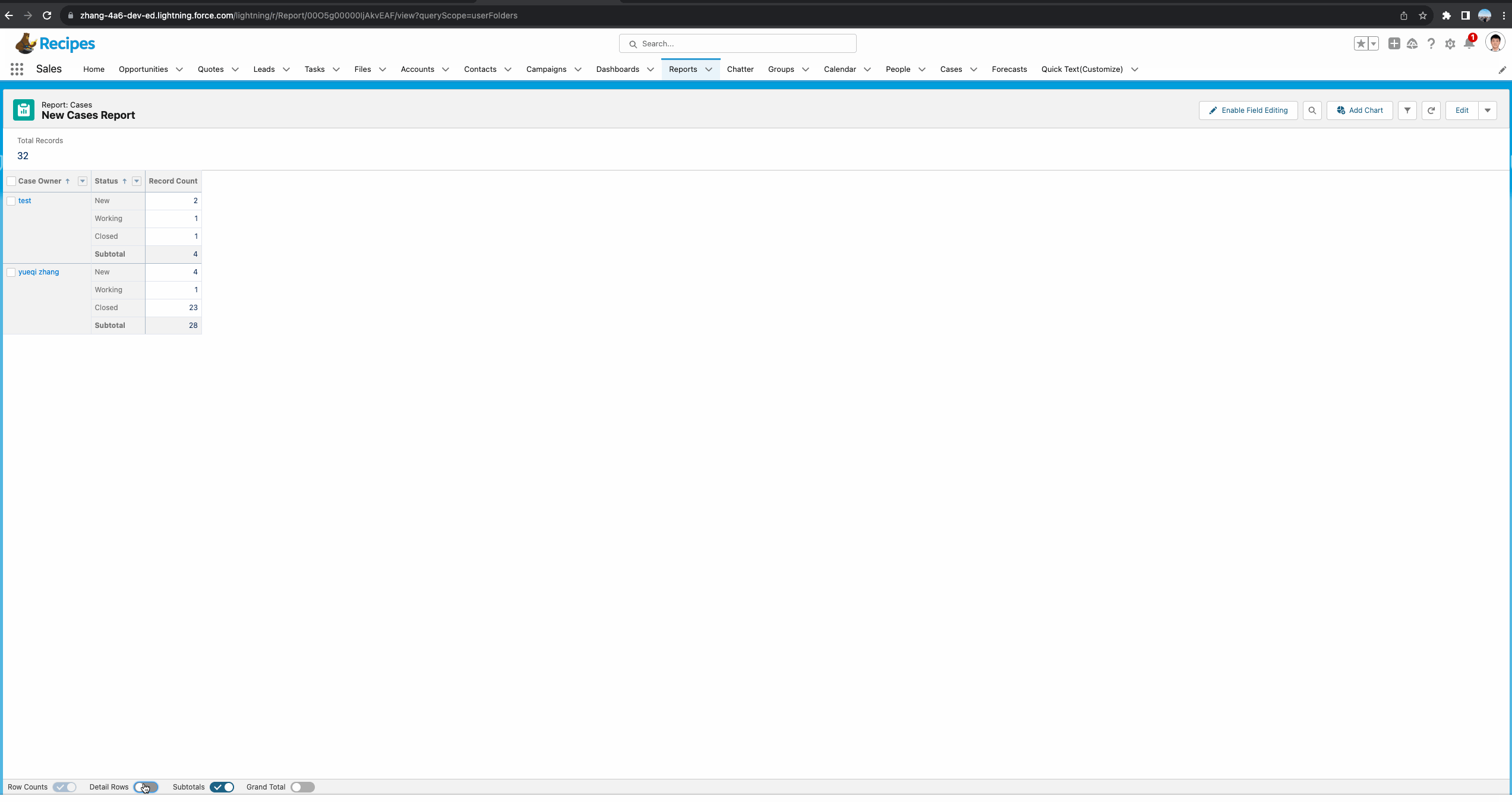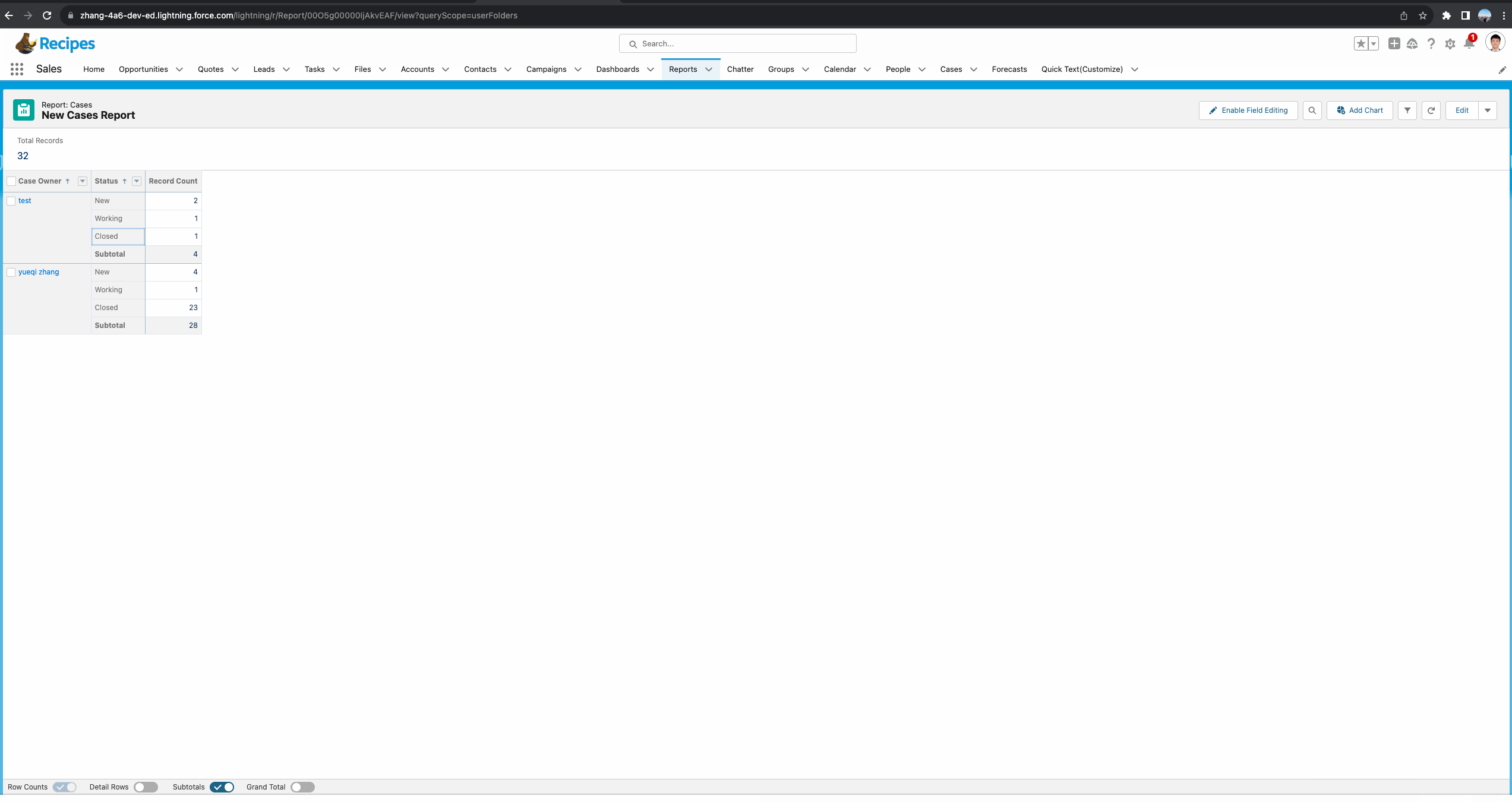
其实这样说起来很绕,并且很难去理解,我们不妨以一个例子进行更好的理解。我们的原始需求是制作一个Case Report,Case Report基于Case Owner以及Case Status进行分组查看每个owner每个组的数量。这个需求很简单,我们可以基于两种方式实现,一个是summary report设置两层分组,一个是matrix report。
基于Summary Report的demo: 两个user,每个user都各拥有一部分数据。
基于Matrix Report的Demo。
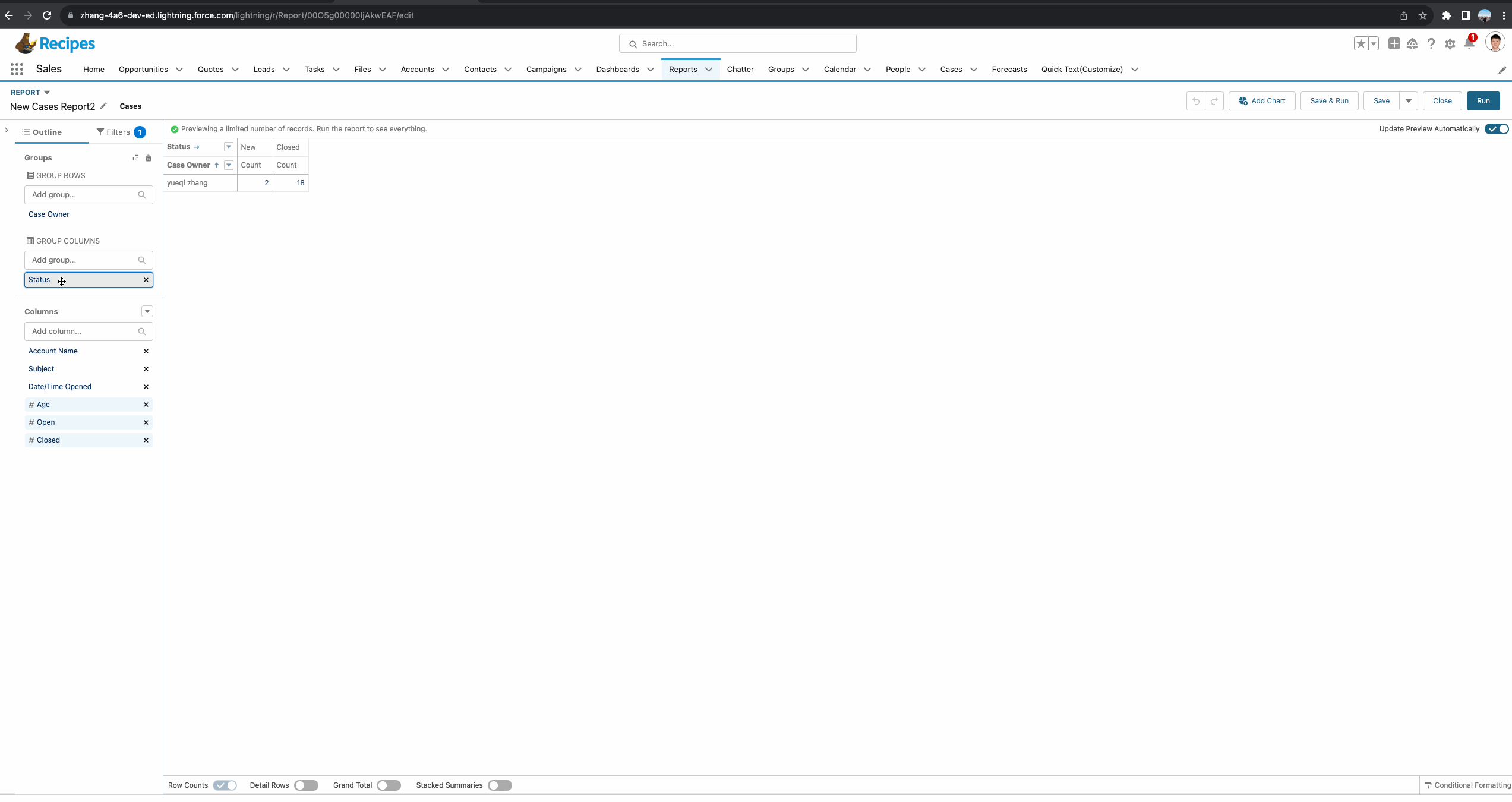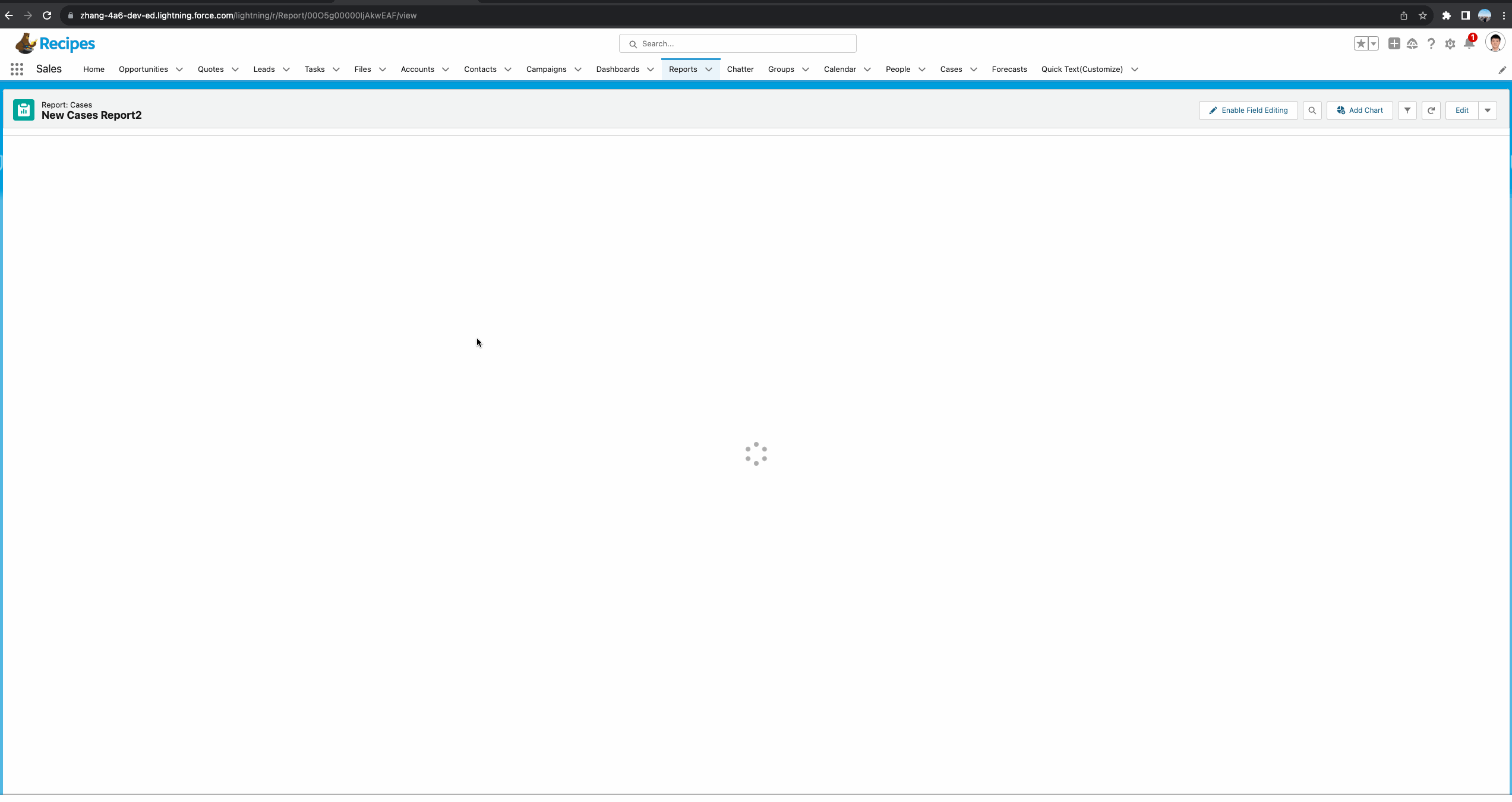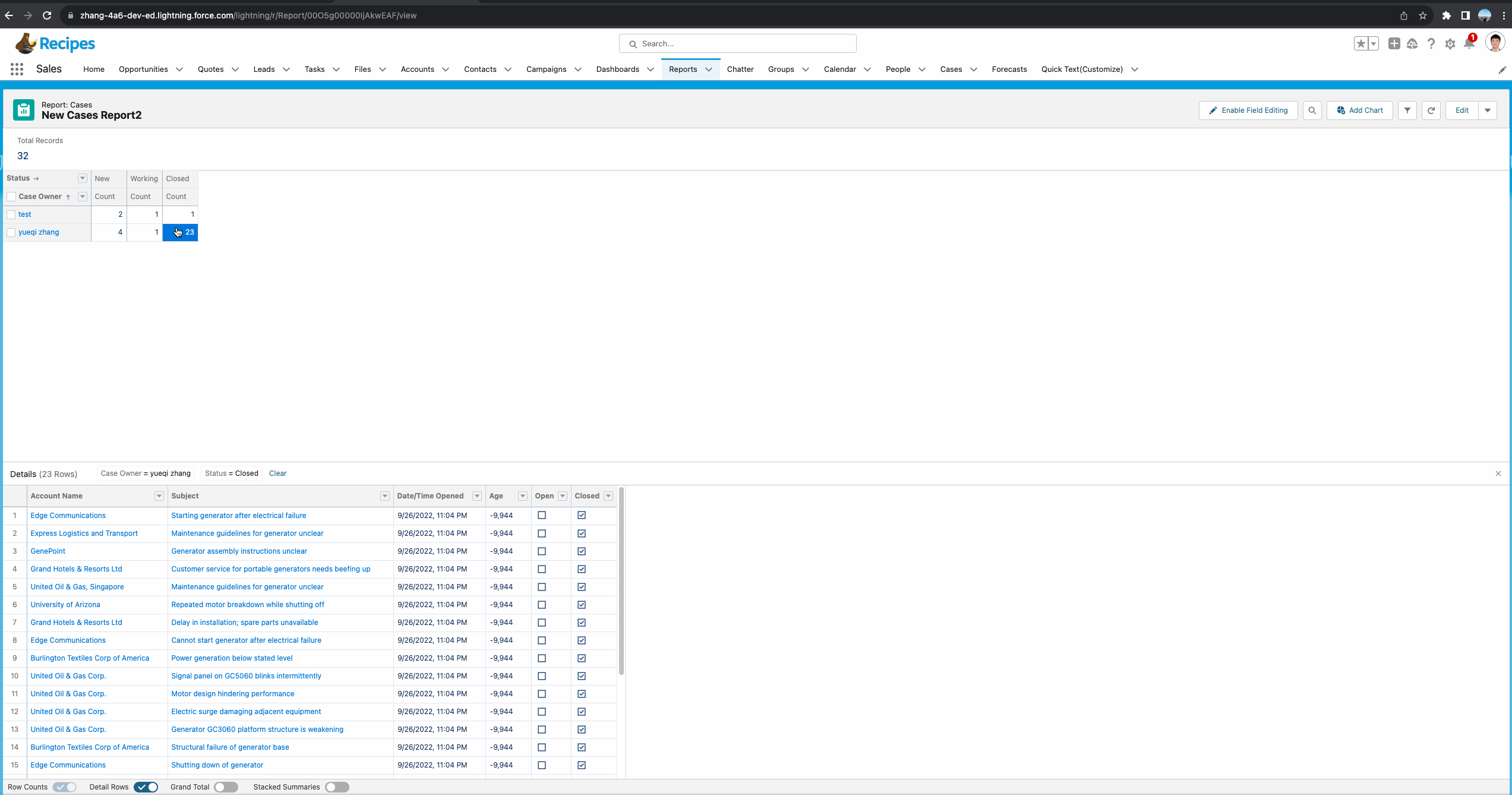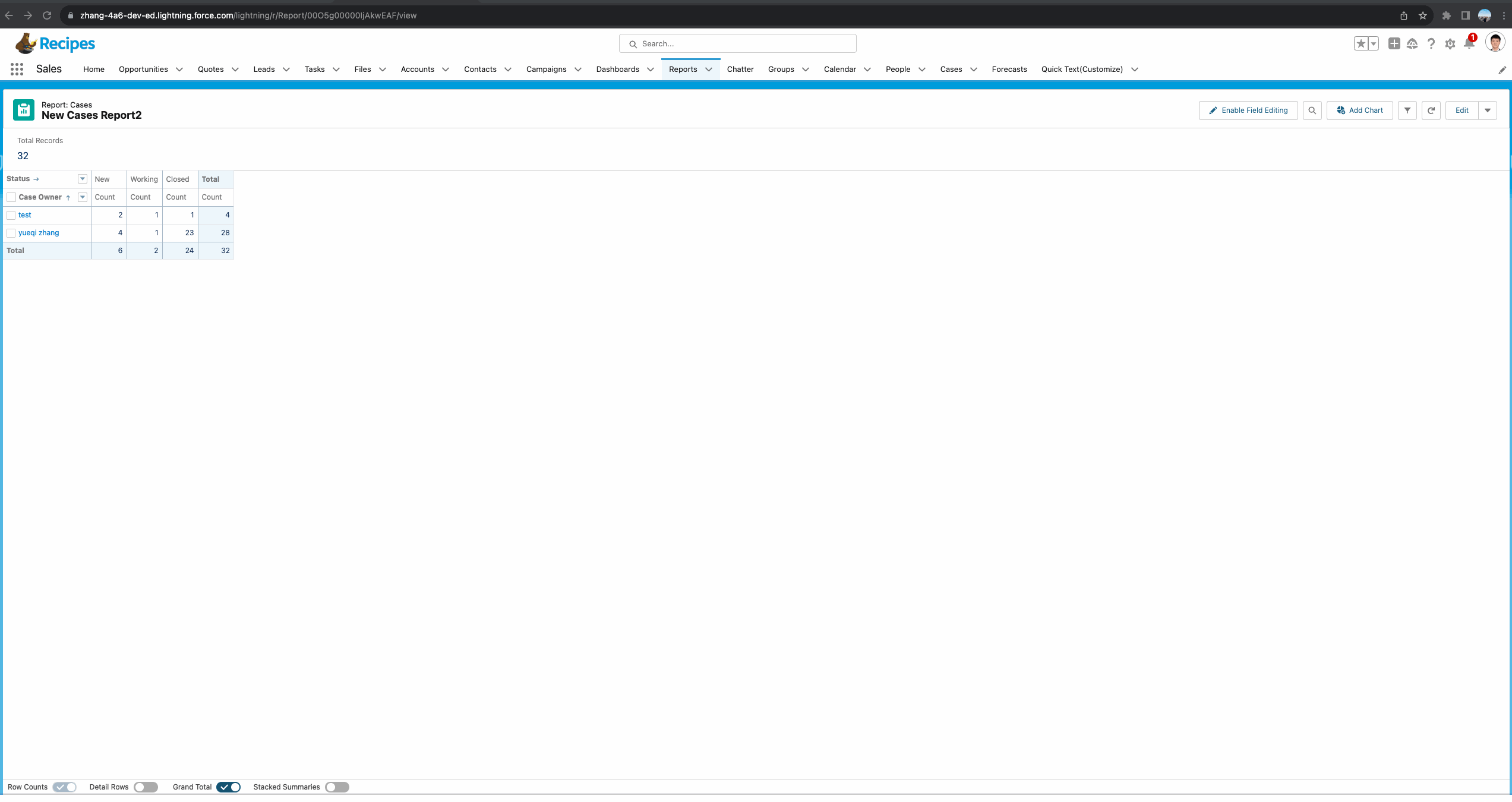
现在需求进行了变更,显示每个阶段的数量固然很好,但是每个owner所处理的case数量不同,直接看每个阶段的数量参考意义不大,更希望看到每个阶段所占每个人所拥有的总数的百分比。我们对这两个report进行一下优化从而满足需求。
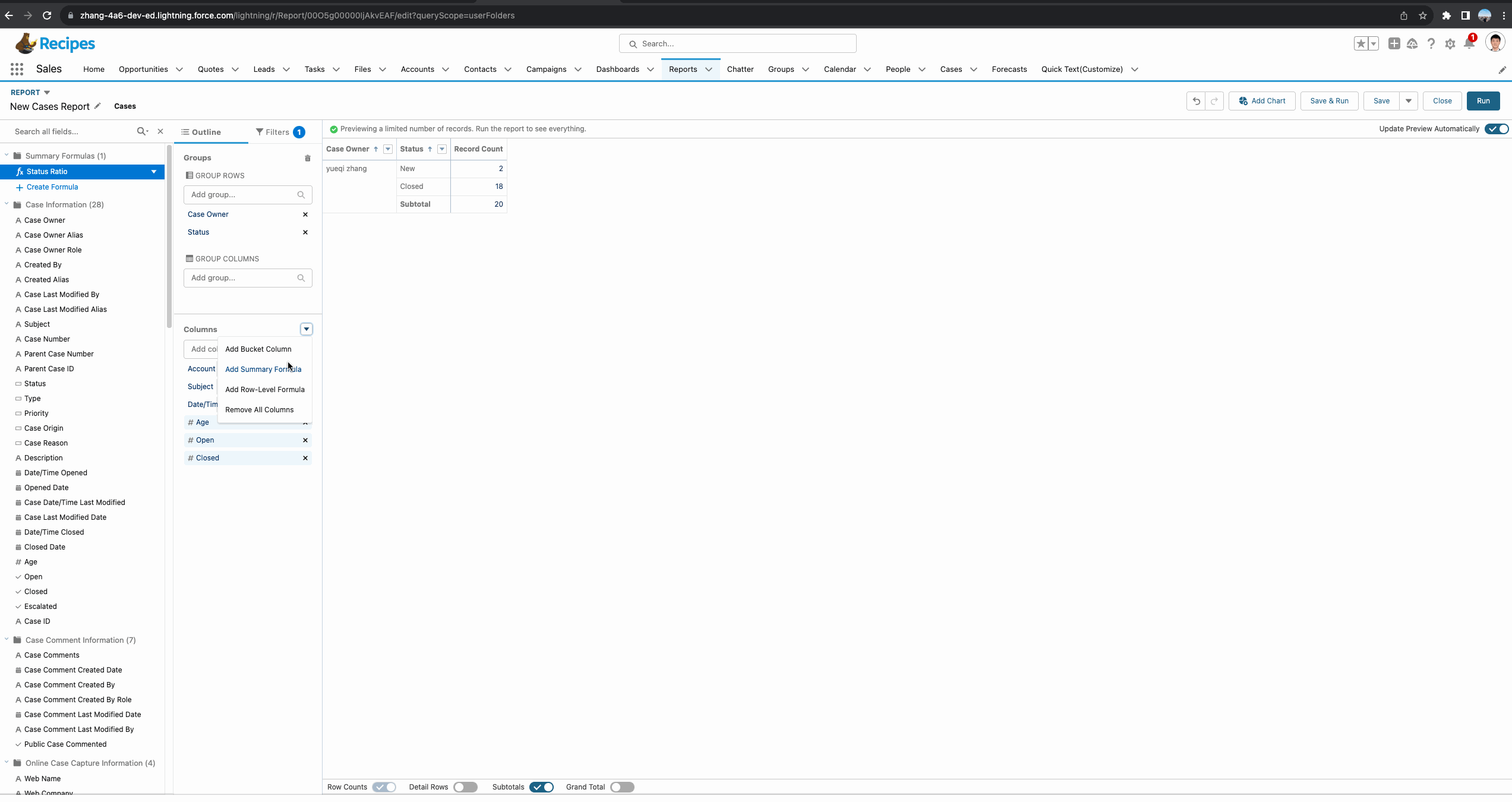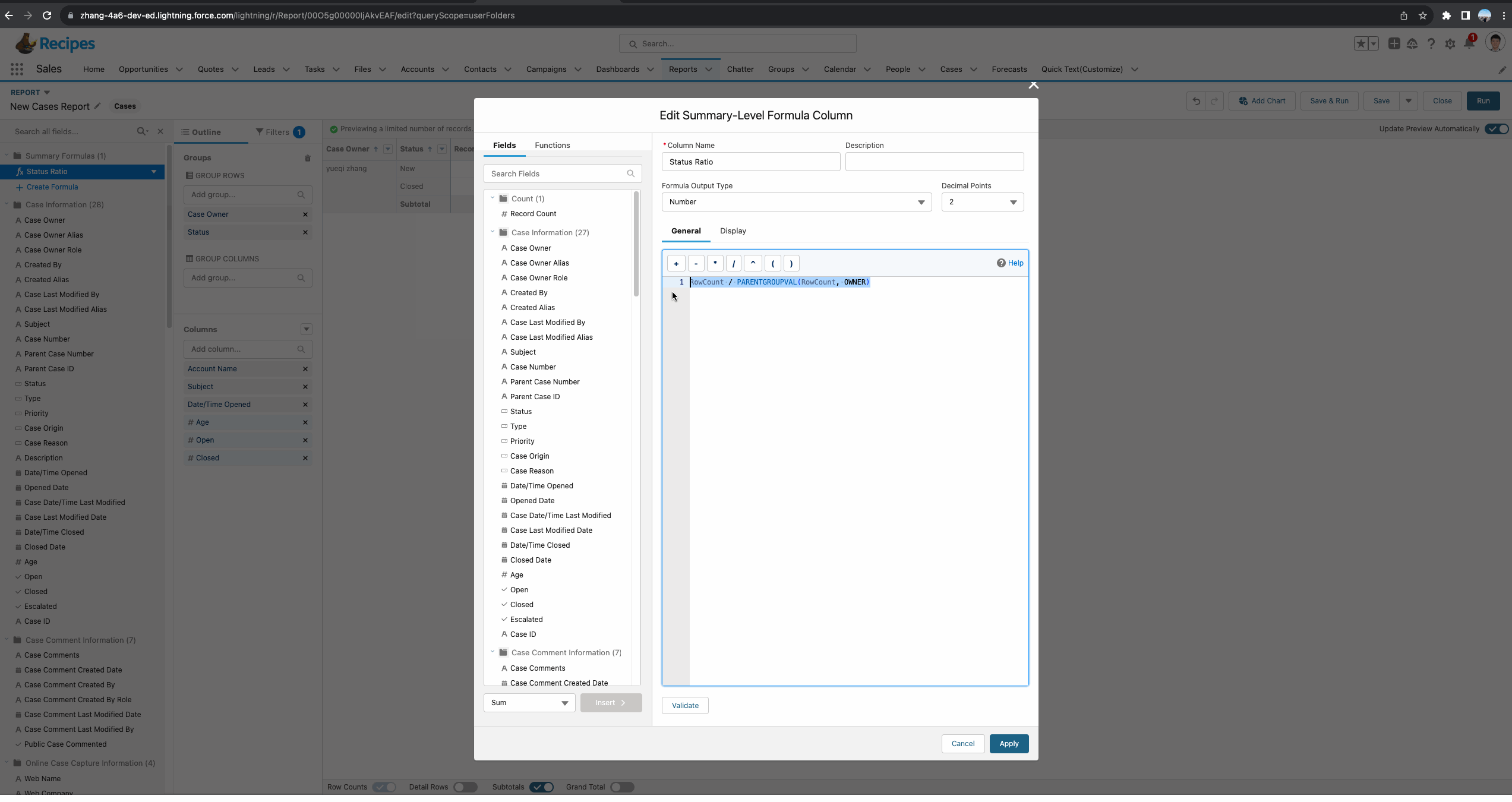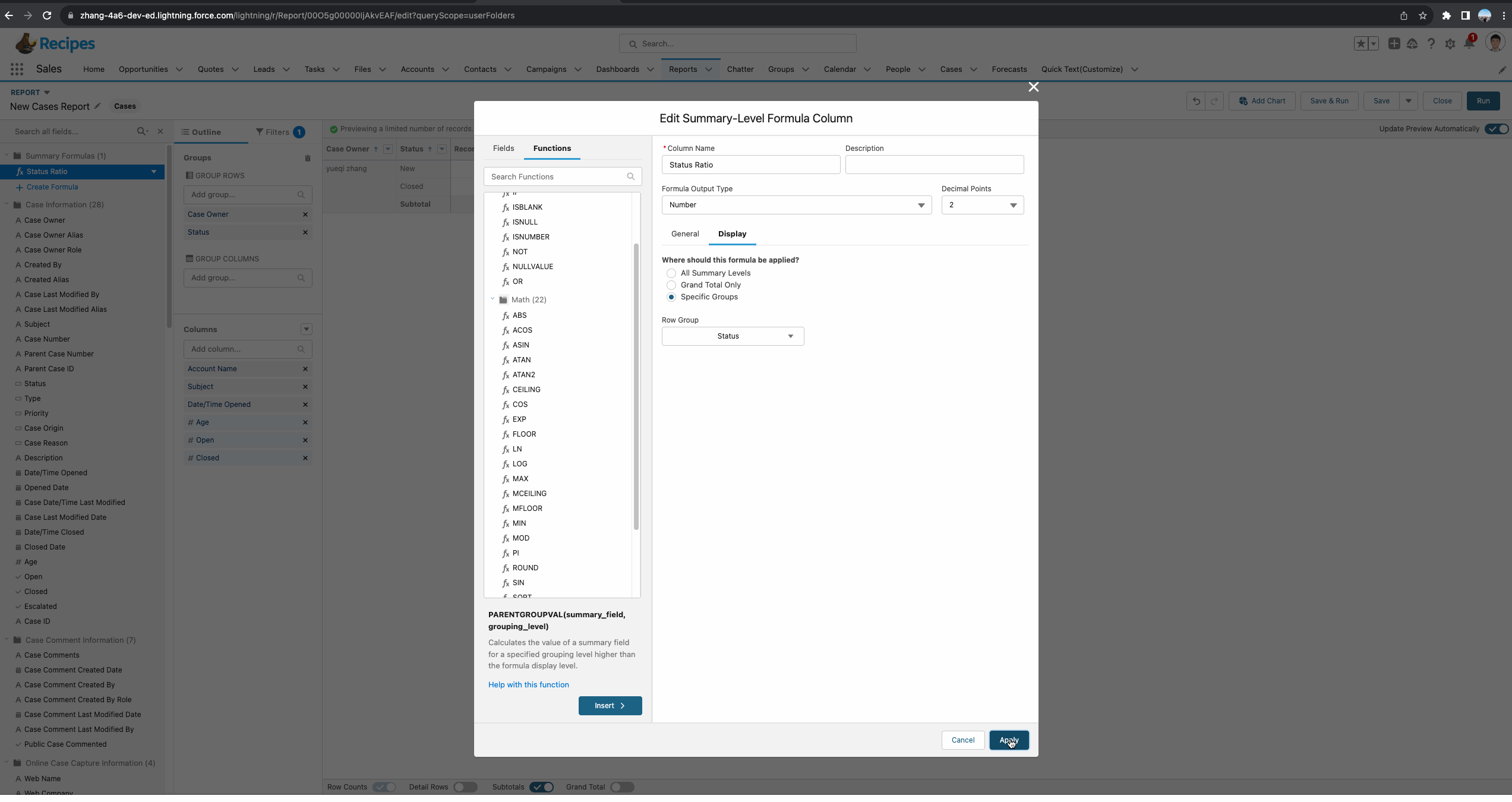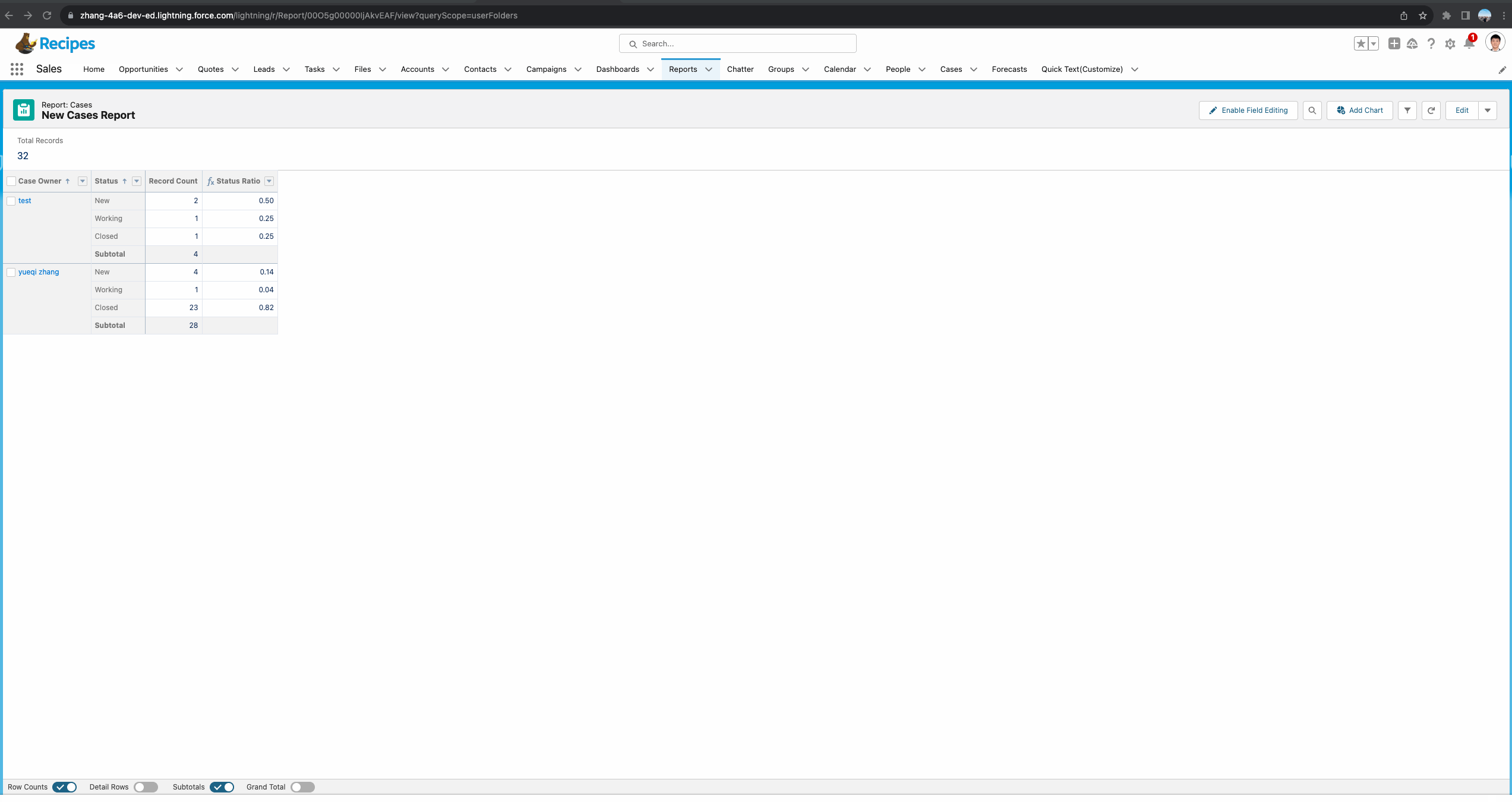
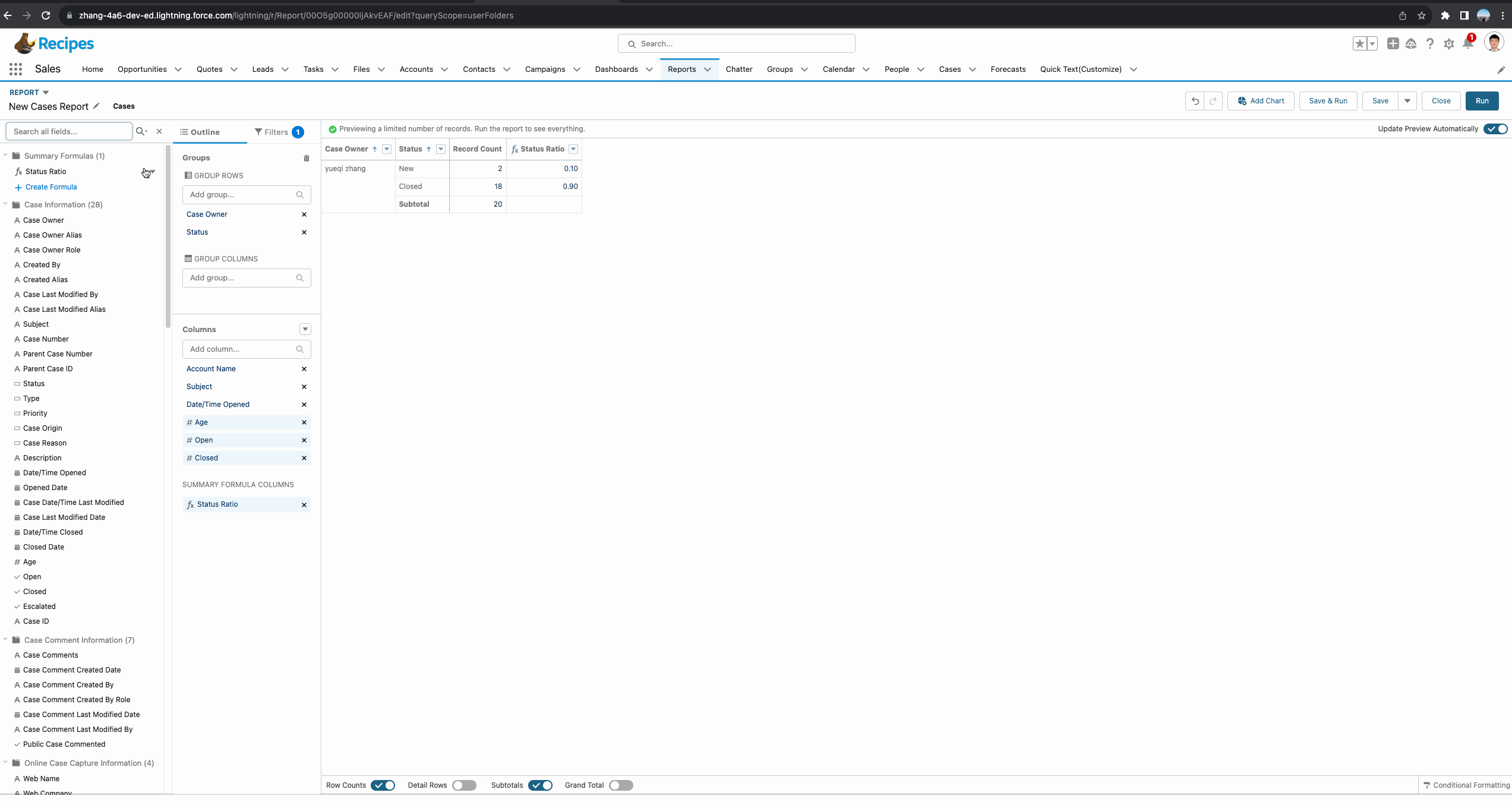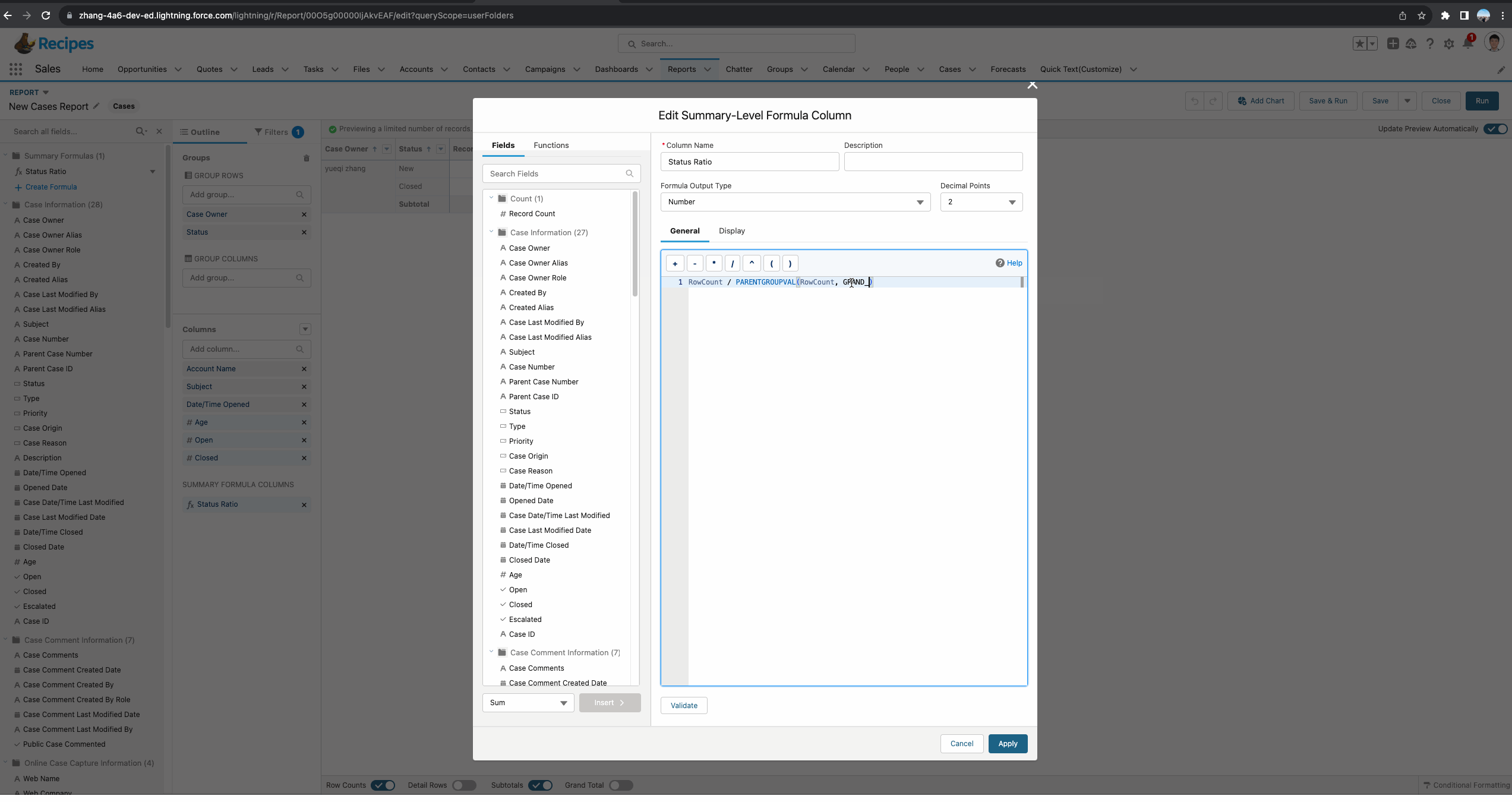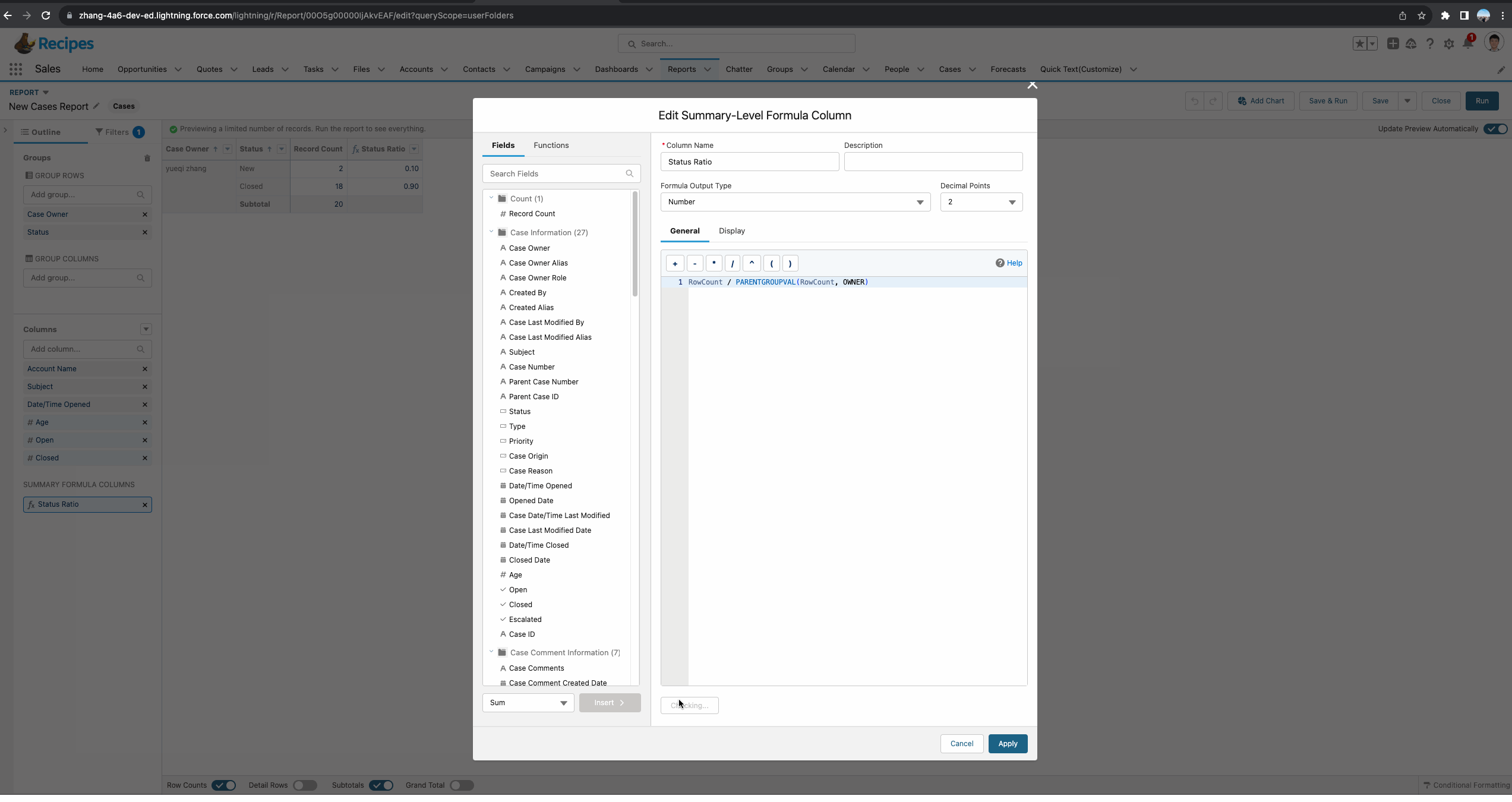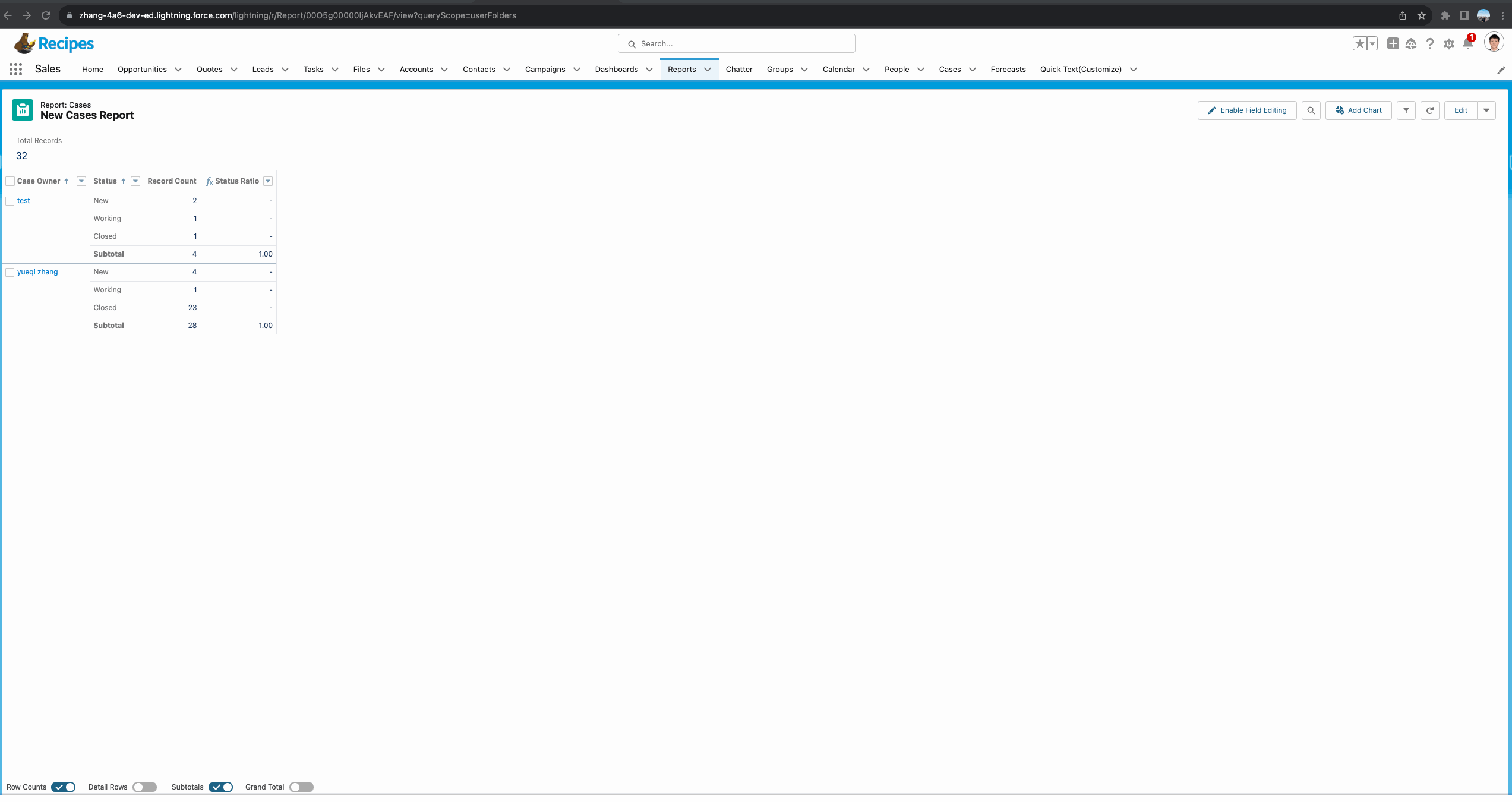
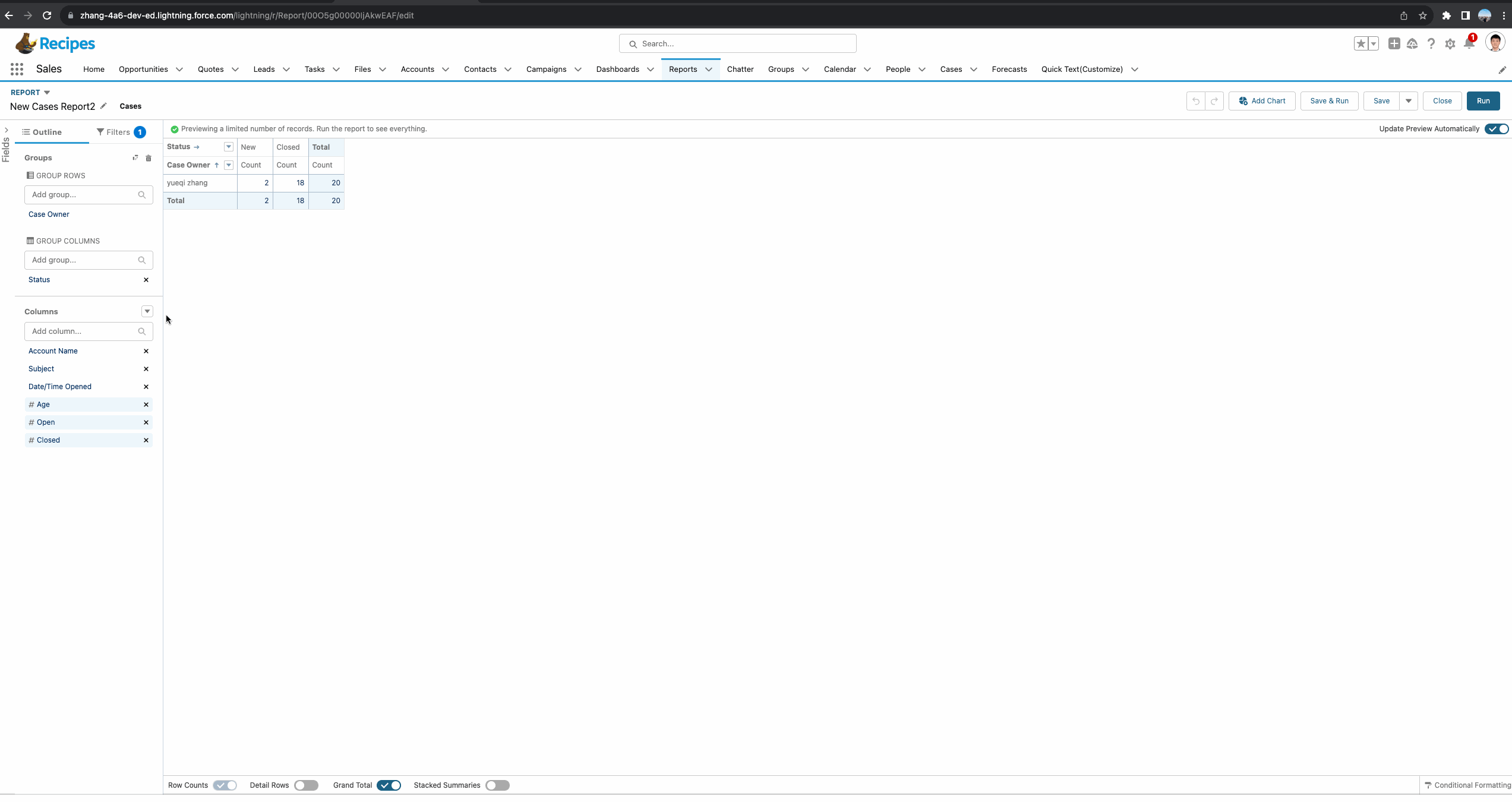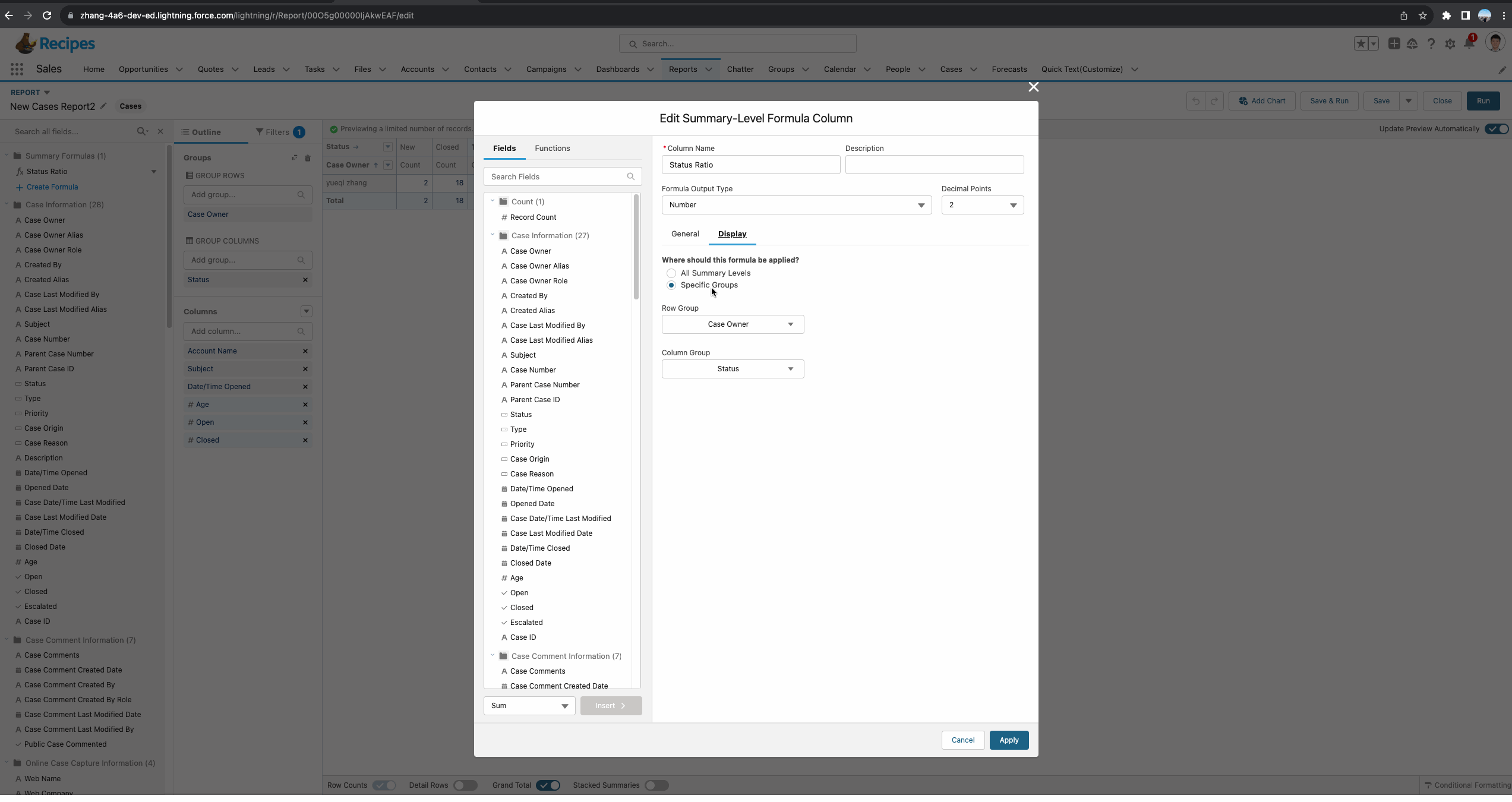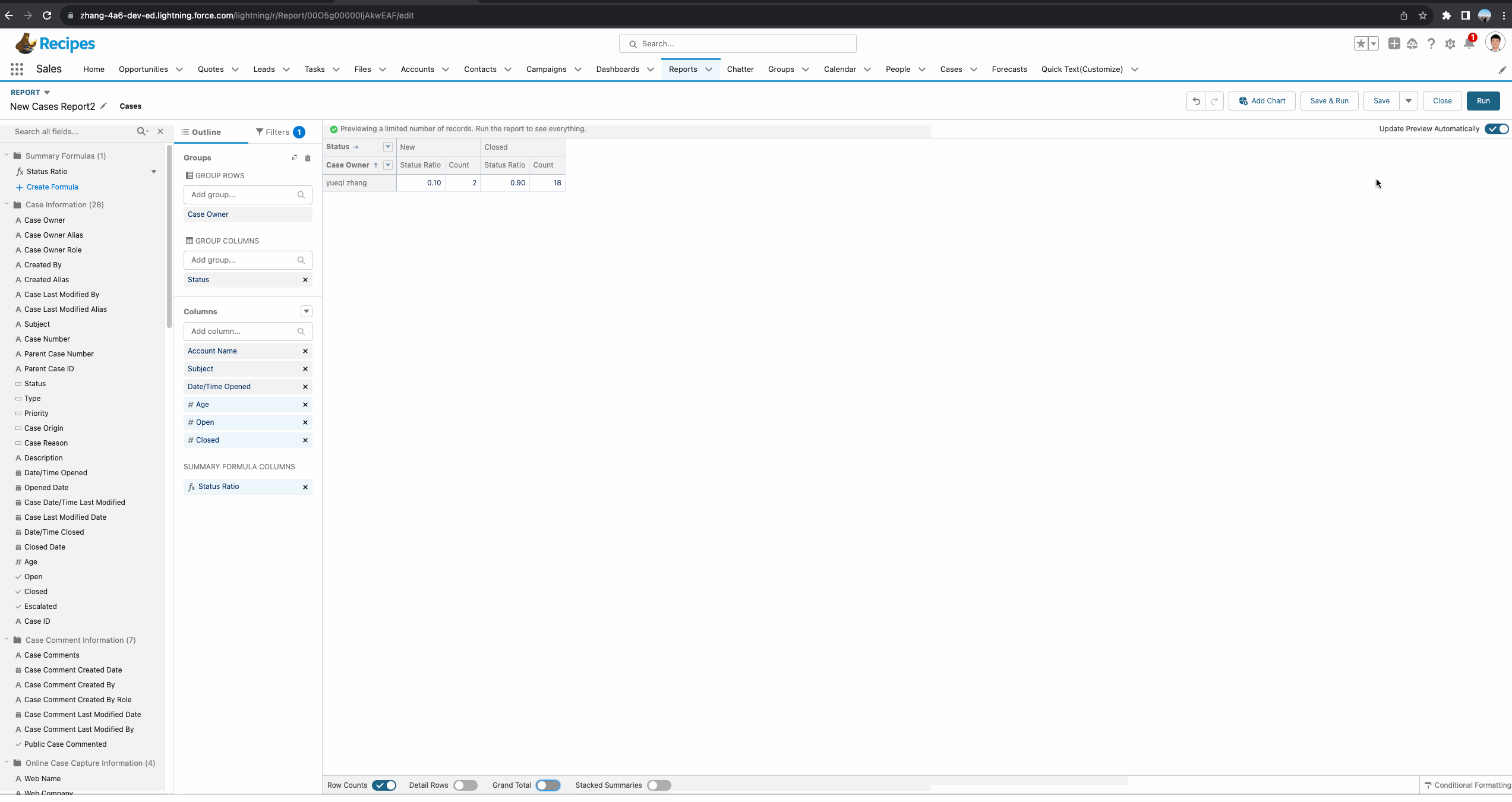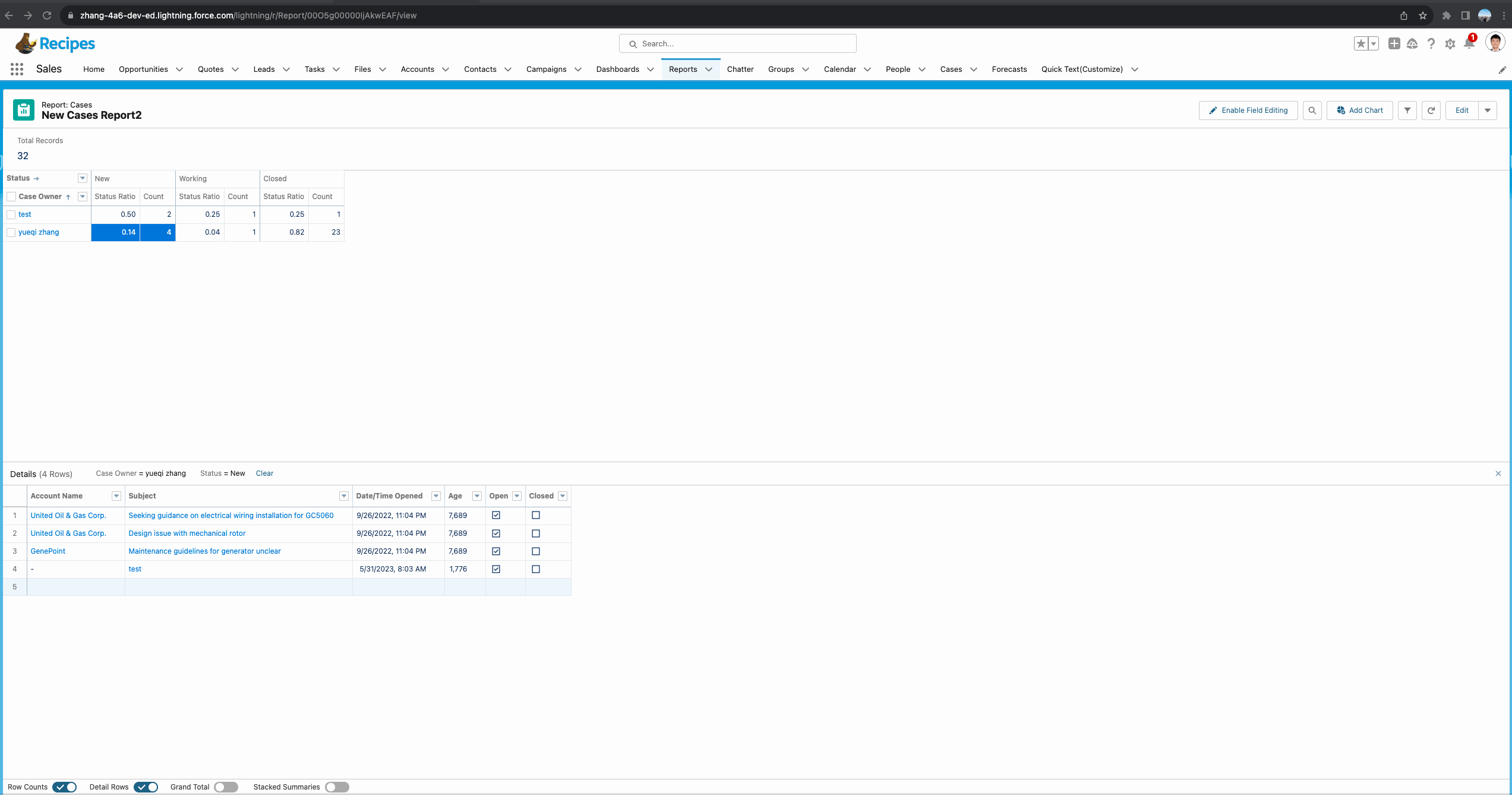
针对Summary Report,正确操作举例如下图gif所示。接下来我们对这个report进行详细的剖析。首先我们需要创建一个summary formula。基于需求,我们需要了解每个Status所占每个owner的总比,所以函数使用的是 PARENTGROUPVAL(RowCount, OWNER),其中OWNER代表的是我们report中的主group:Owner,即获取基于Owner级别的总数量。
还有一个重要的内容是Display,代表当前的formula显示在哪里。针对Summary Report主要有以下几个值:
- All Summary Levels:所有的group字段,当前的demo相当于显示在Owner以及Status的subtotal中。
- Grand Total Only:显示在Grand Total级别,通常这种函数为金额或者数量多一些,比如当前记录总数或者当前report的总金额等。
- Specific Groups:显示在指定的group的subtotal,当前demo选择了此种方式,并且字段选择了Status,代表只会显示在Status的subtotal位置。
接下来展示几个错误的示范
1. 函数中选错基于某个字段分组。我们可以看到下方gif中,函数选择基于Status分组永远是100%,基于GRAND_SUMMARY分组则把两个user的总数都作为计算,这个是不正确的,我们在使用此函数时,首先需要确定计数范围。
2. 显示错误的位置。我们可以看到此函数仅支持summary函数,如果放在grand total以及All Summary Level则报错,放在不正确的字段的subtotal则展示的结果不符合我们的需求的预期。
这两个点在实际工作中使用此函数一定要重点思考。
基于matrix report正确操作如下:这个demo中,我们看到函数有三个参数,其中第二个参数很好理解,我们使用了Case Owner进行分组。第三个参数我们选择了GRAND_SUMMARY,因为当前column只有一个分组,所以使用这种也代表获取当前这个owner的total。
二. PREVGROUPVAL
使用 PREVGROUPVAL 计算相对于同级分组的值,他用来获取分组的前一刻的值。我们直接以一个demo进行展开,这样理解会更方便。
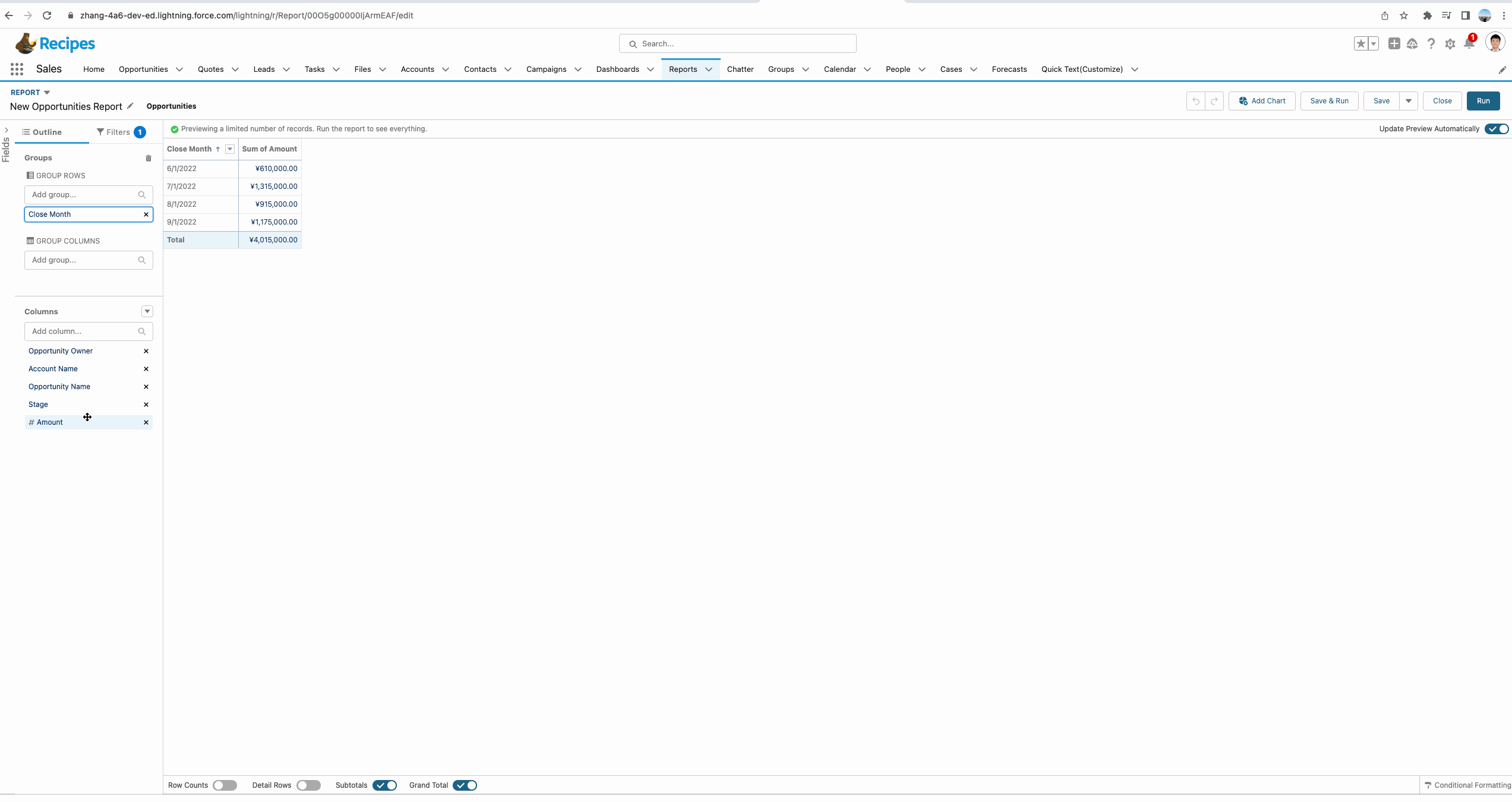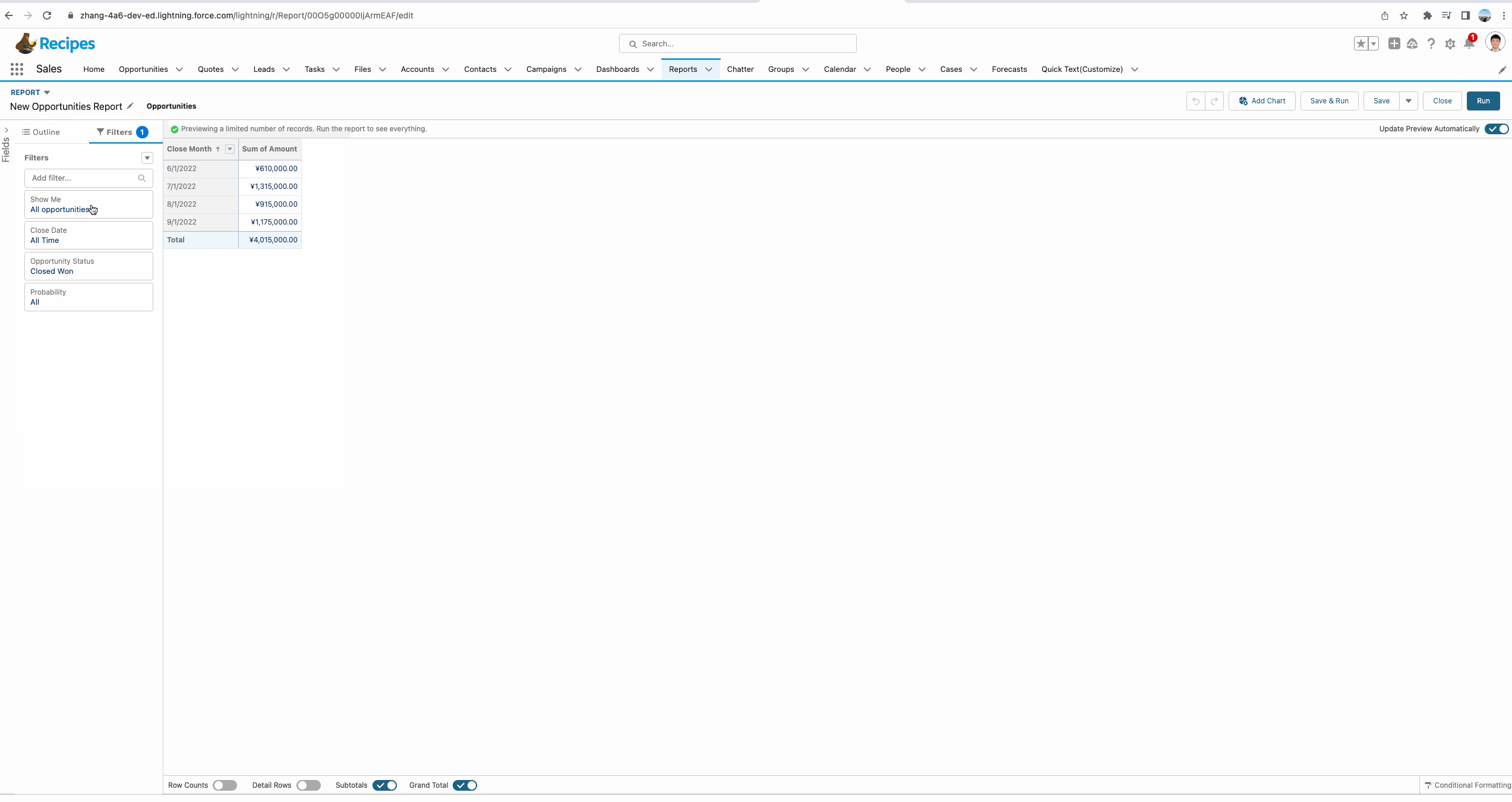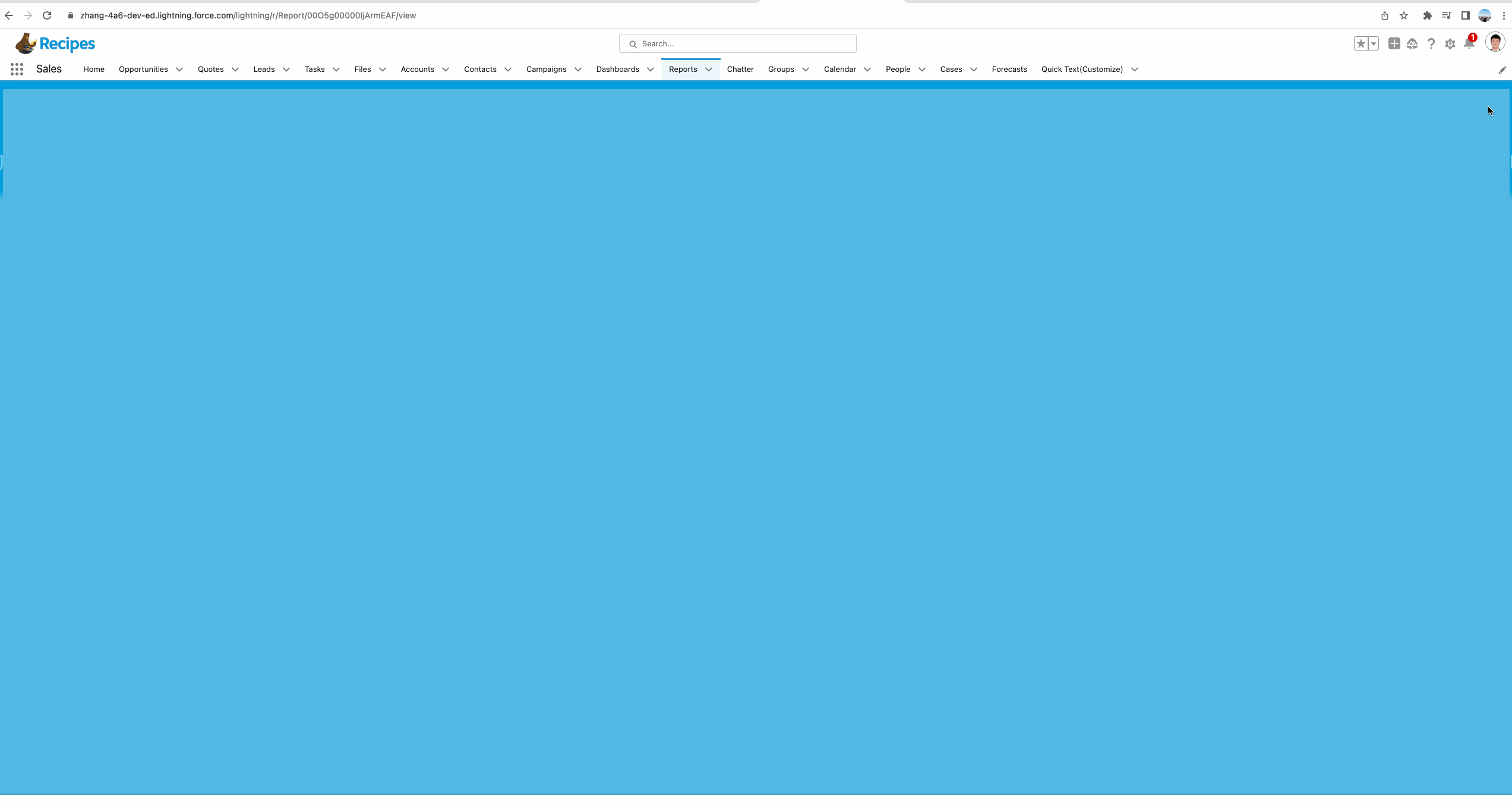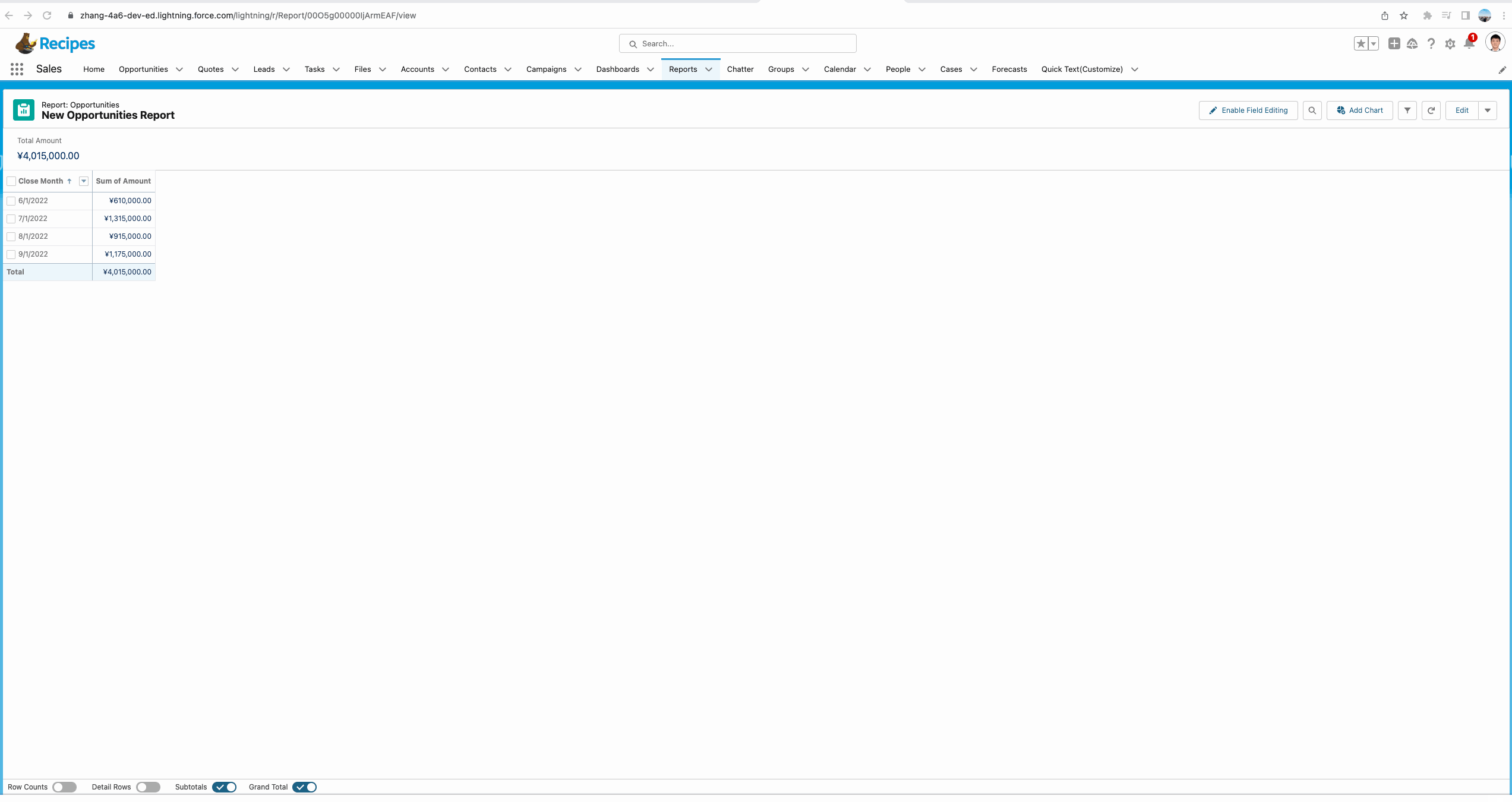
我们想要了解一下第二条记录和前一条记录的差值,即每个月的amount的变化,是增长的,还是减少的。这种情况我们便可以使用PREVGROUPVAL函数。
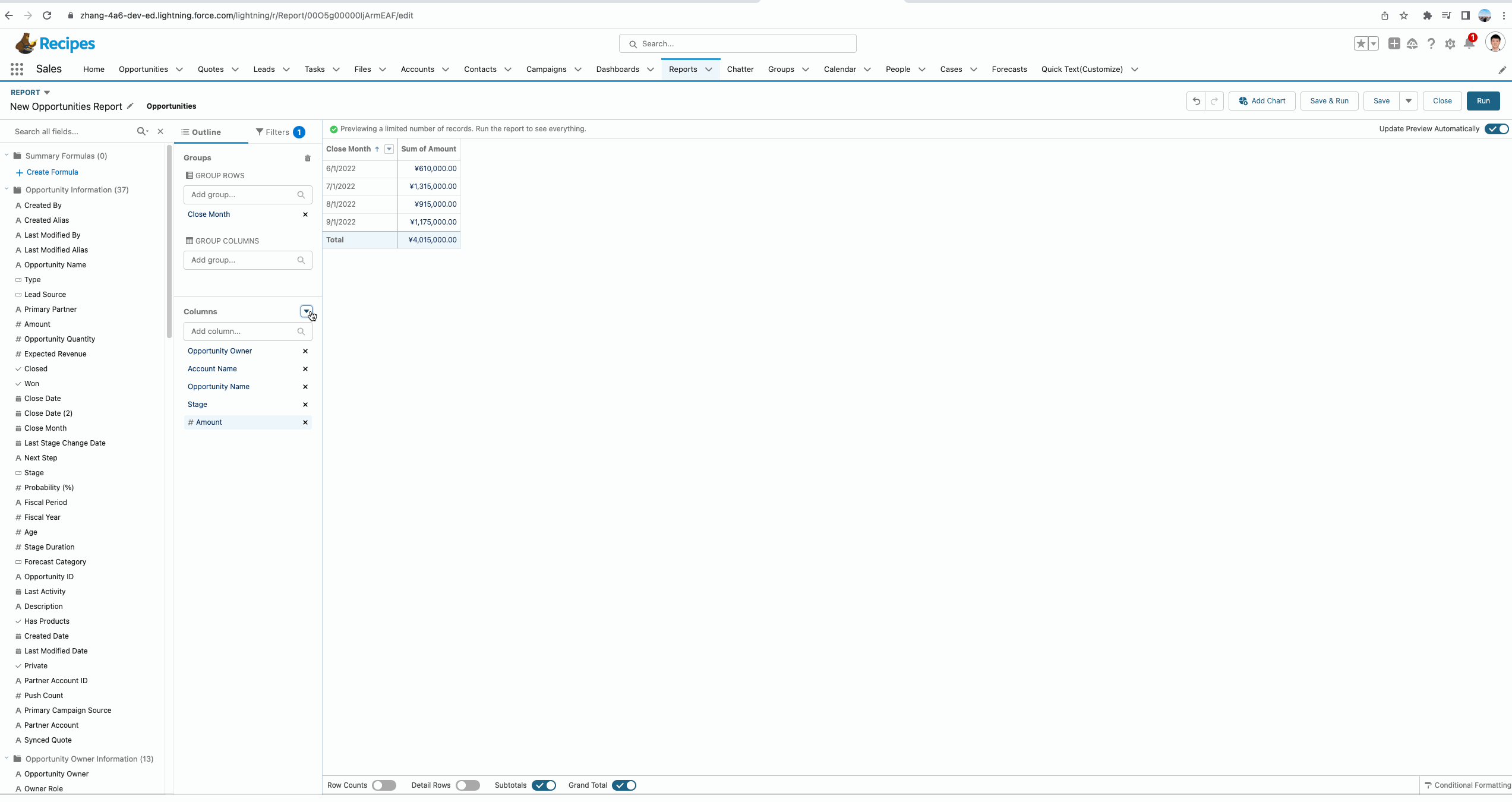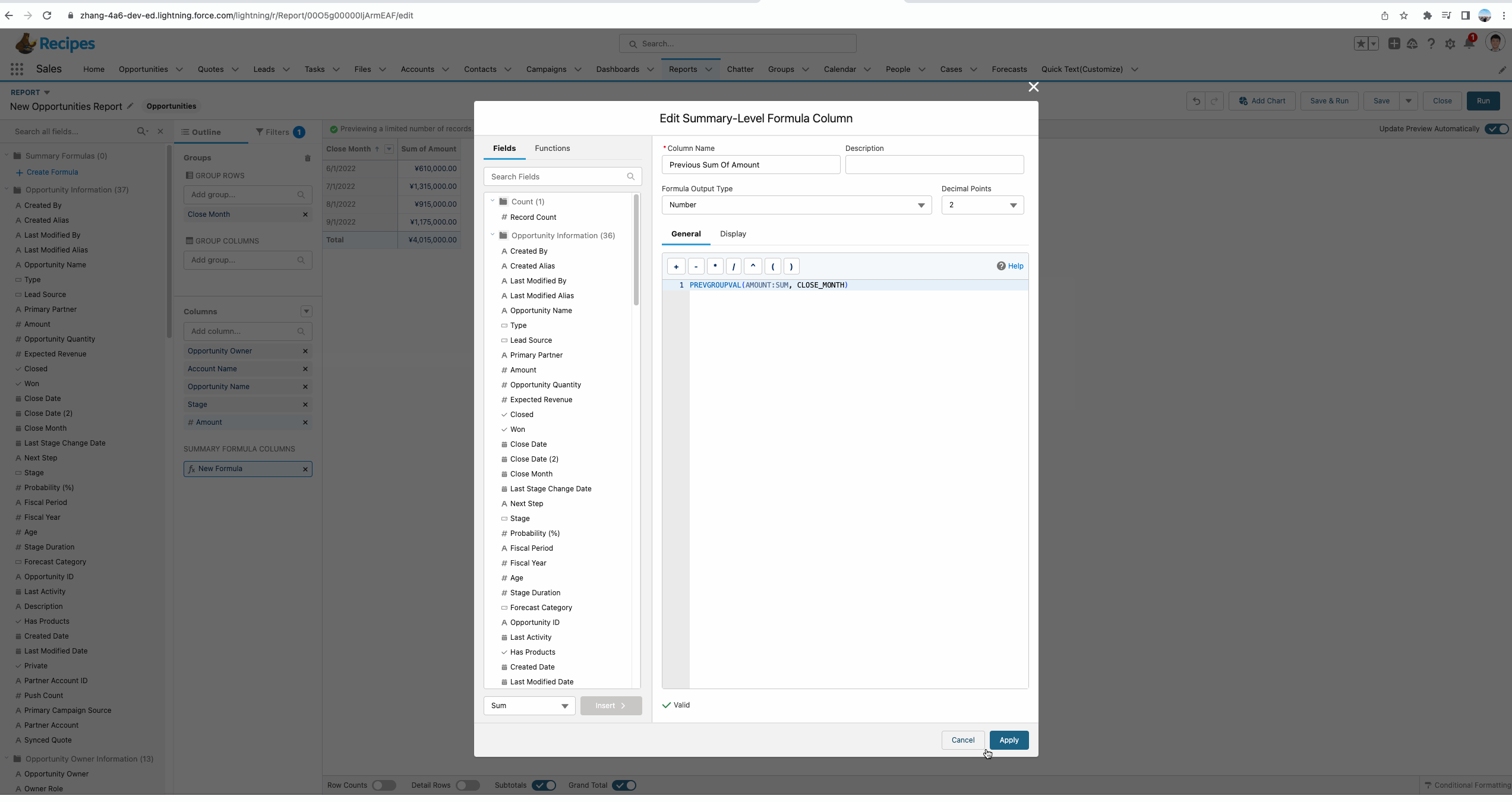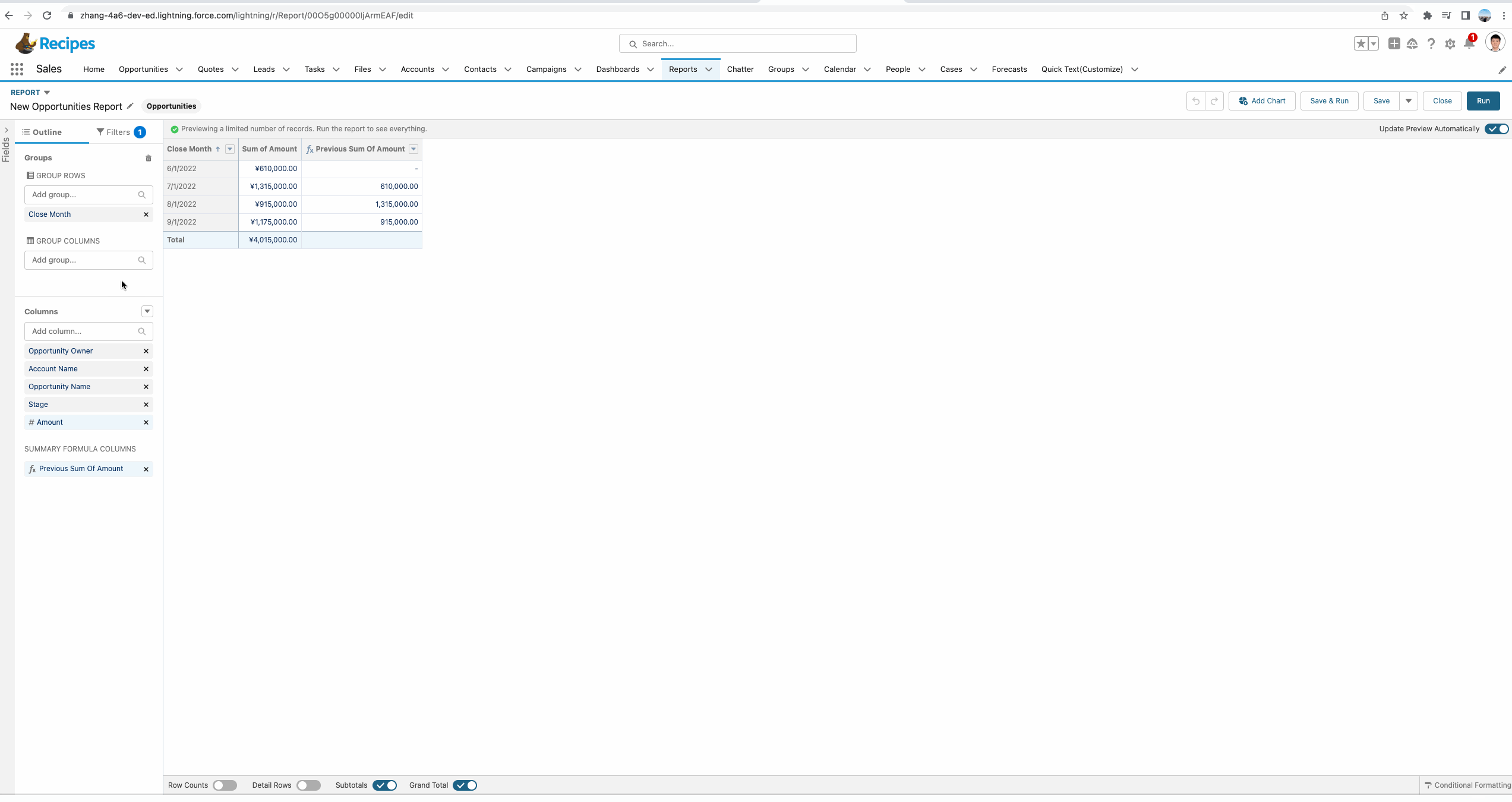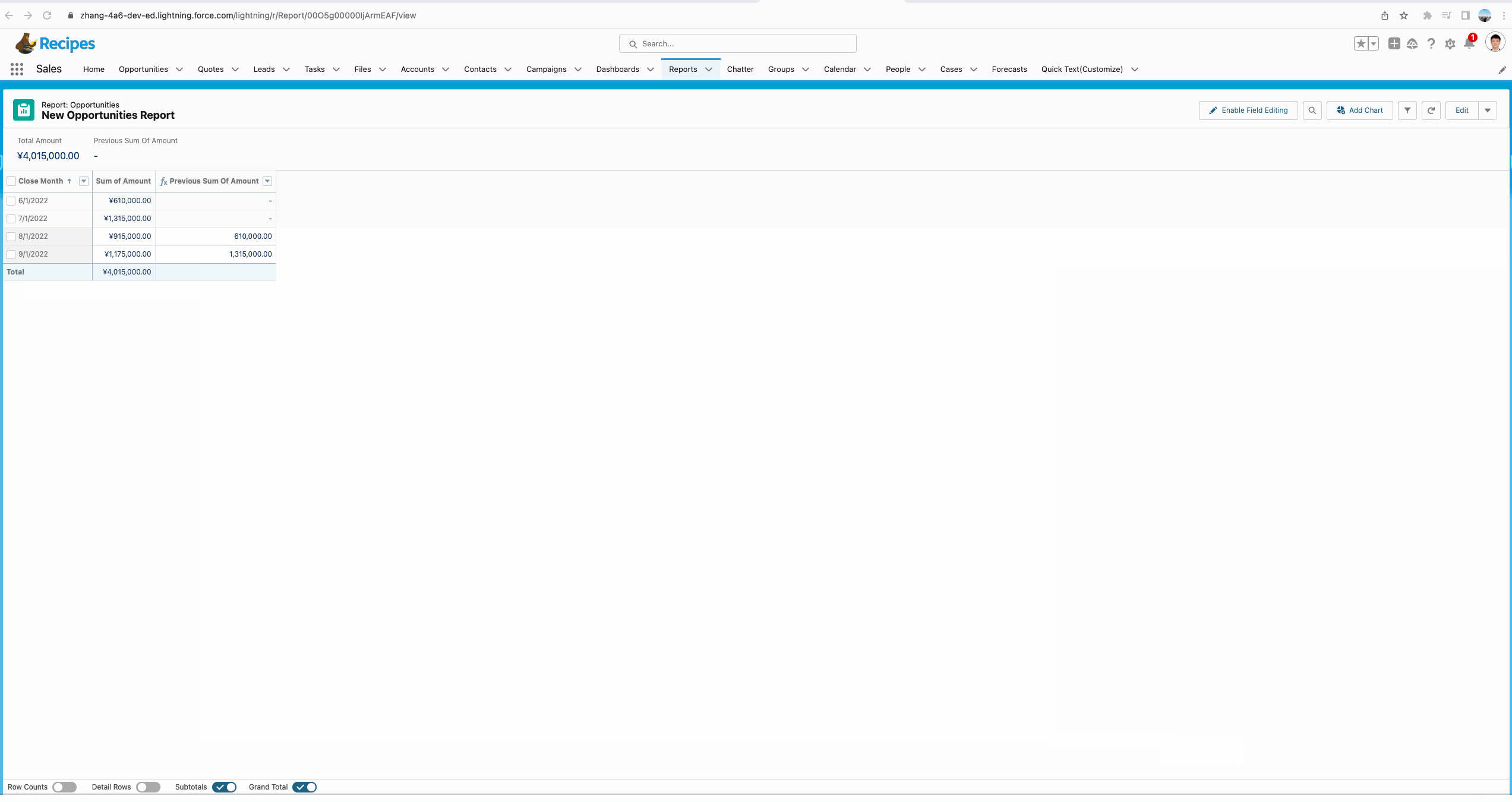
从下方的gif中我们可以看到使用PREVGROUPVAL的效果,这个函数拥有三个参数:
- summary_field:记录哪个汇总字段,demo中我们使用的是 Amount:Sum即获取Amount的汇总数据。
- grouping_level:记录基于哪个字段进行分组来获取summary_field。
- increment:记录增量,默认是1,即获取前一条数据的值,如果隔条获取,可以设置为2, demo中有一个简单的UI效果。
我们对UI进行简单修改,即可了解每个月相对上个月是增长还是下降了,仅需简单的计算以及颜色渲染,便可直观显示。 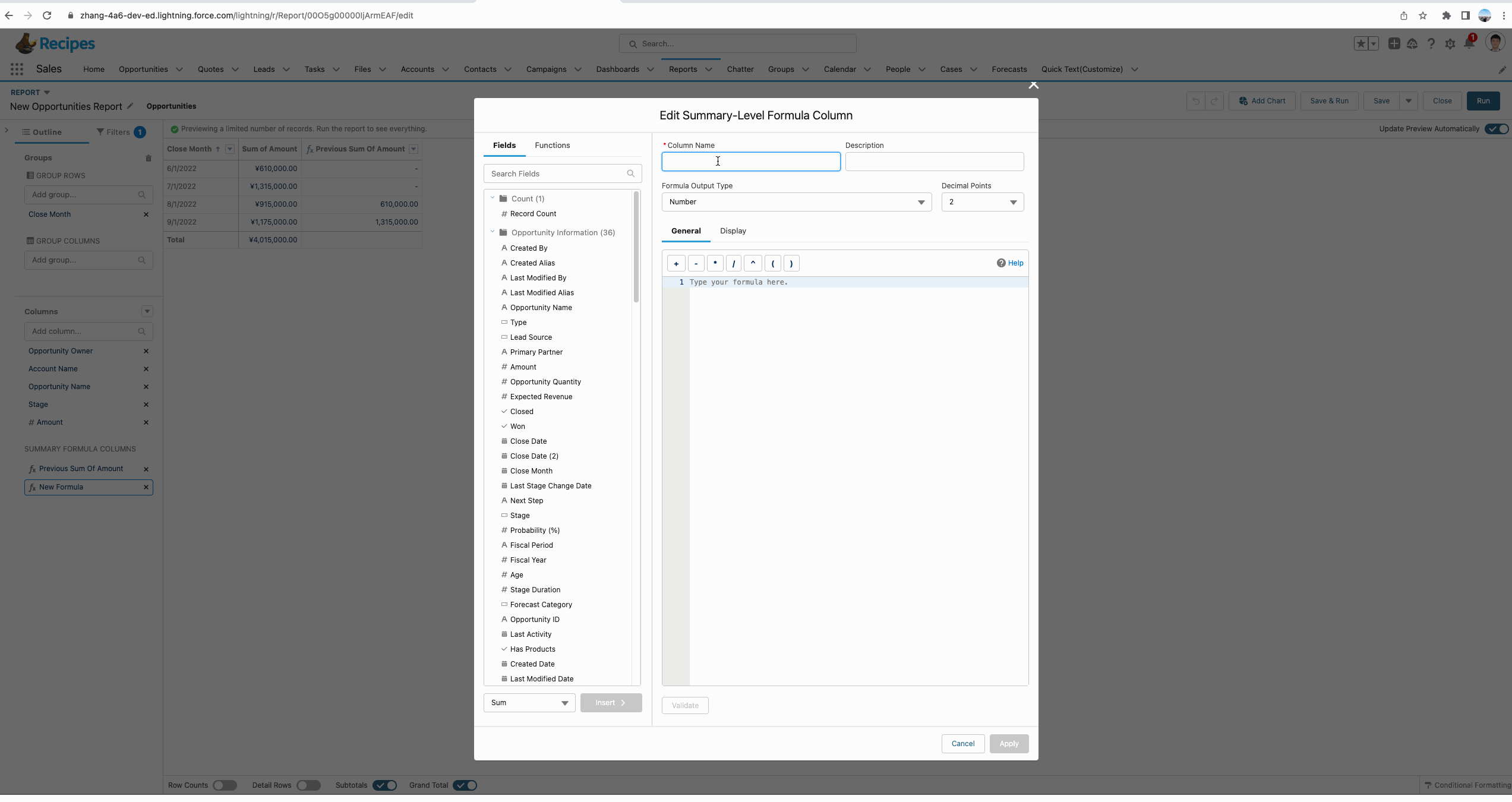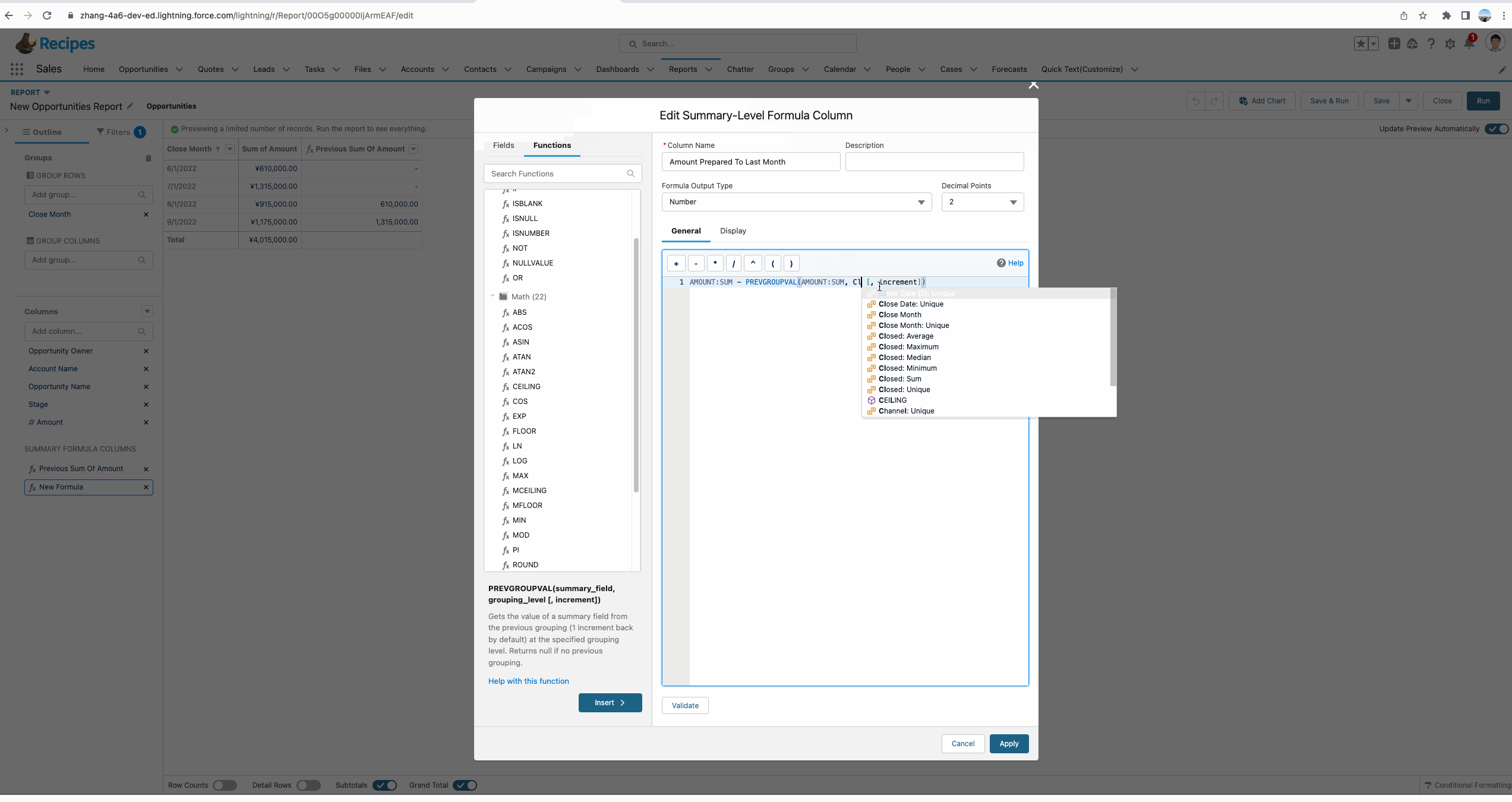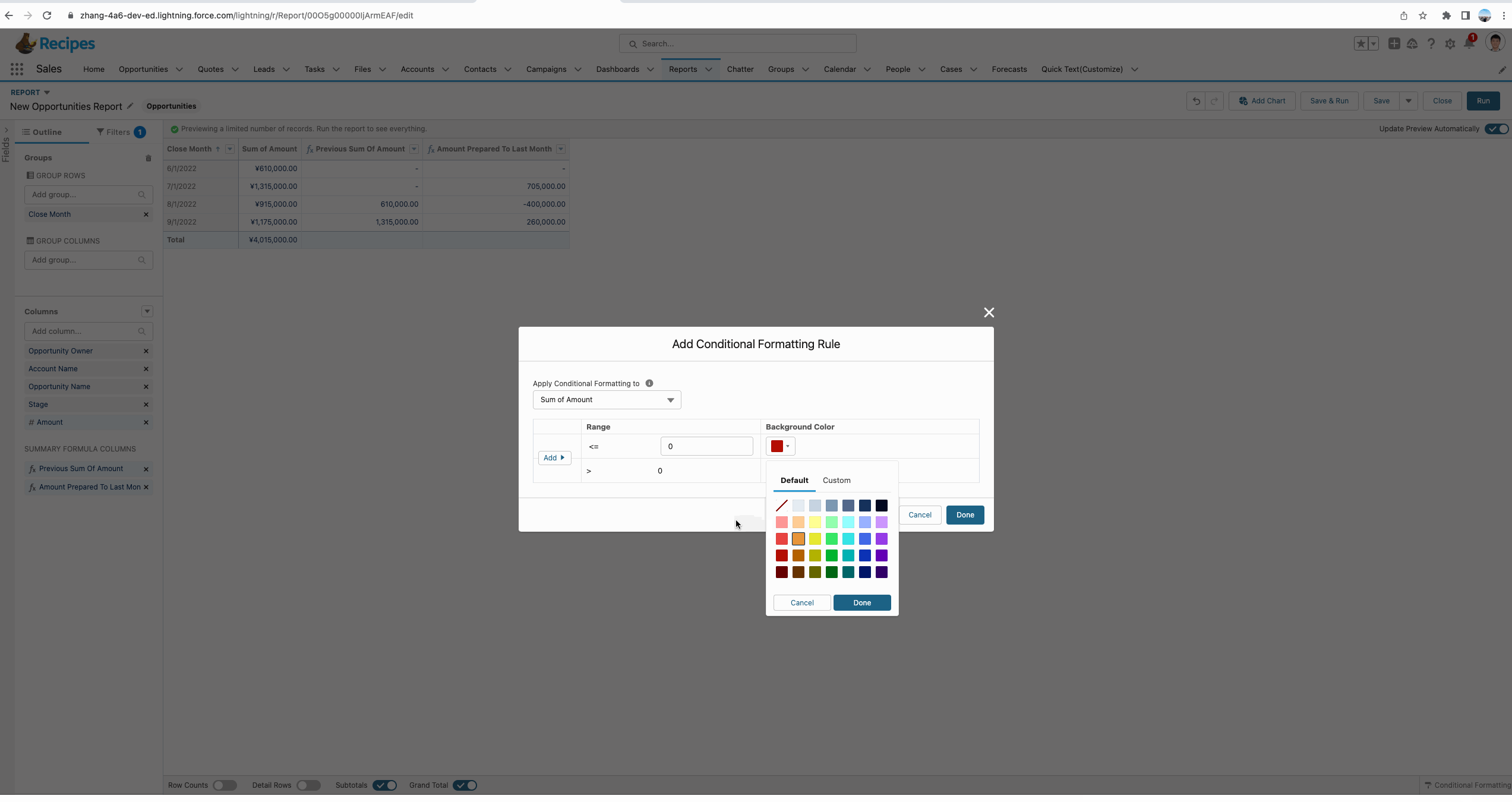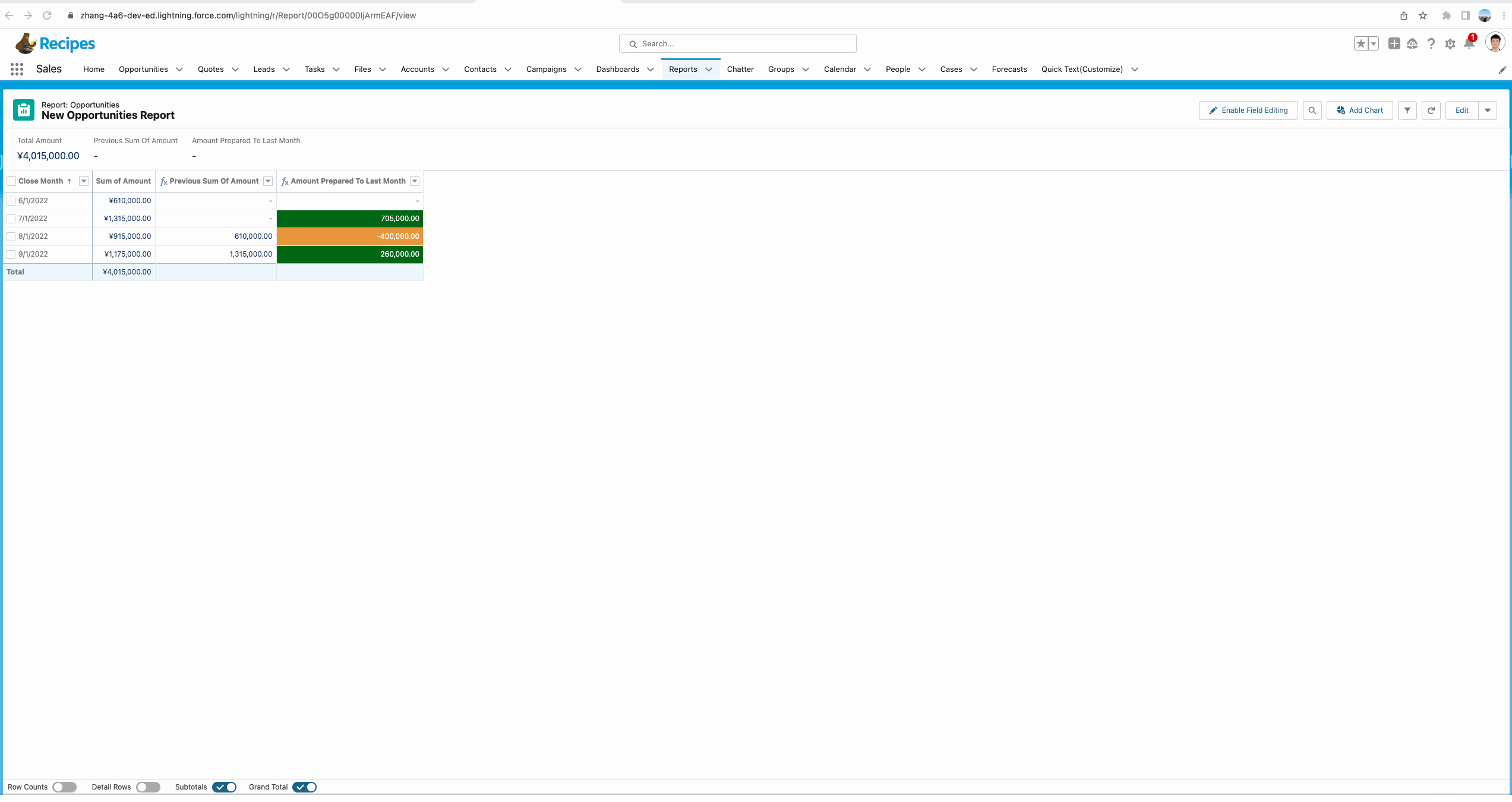
三. Power Of 1
我们以一个简单的demo来引出Power Of 1.
下方的gif中我们可以看到,针对Opportunity Report,我们可以在 Account Name列使用Unique,从而获取Account Name去重以后的数量,这个很方便也很好用。然而如果我们基于Account Name去进行Group以后,这个字段将不再支持 Unique去查看总共有多少个Unique Account,标准的report的record count也指向的是Opportunity有多少条数据,所以这时我们仅需要简单的在Account表中创建一个formula字段,并且将value设置一个hard code等于1即可。这种方式适用于针对关联列表或者字表查询,想要在字表查询到父表唯一的数量(Opportunity report查询Account去重以后的数量),可以使用Power Of 1。
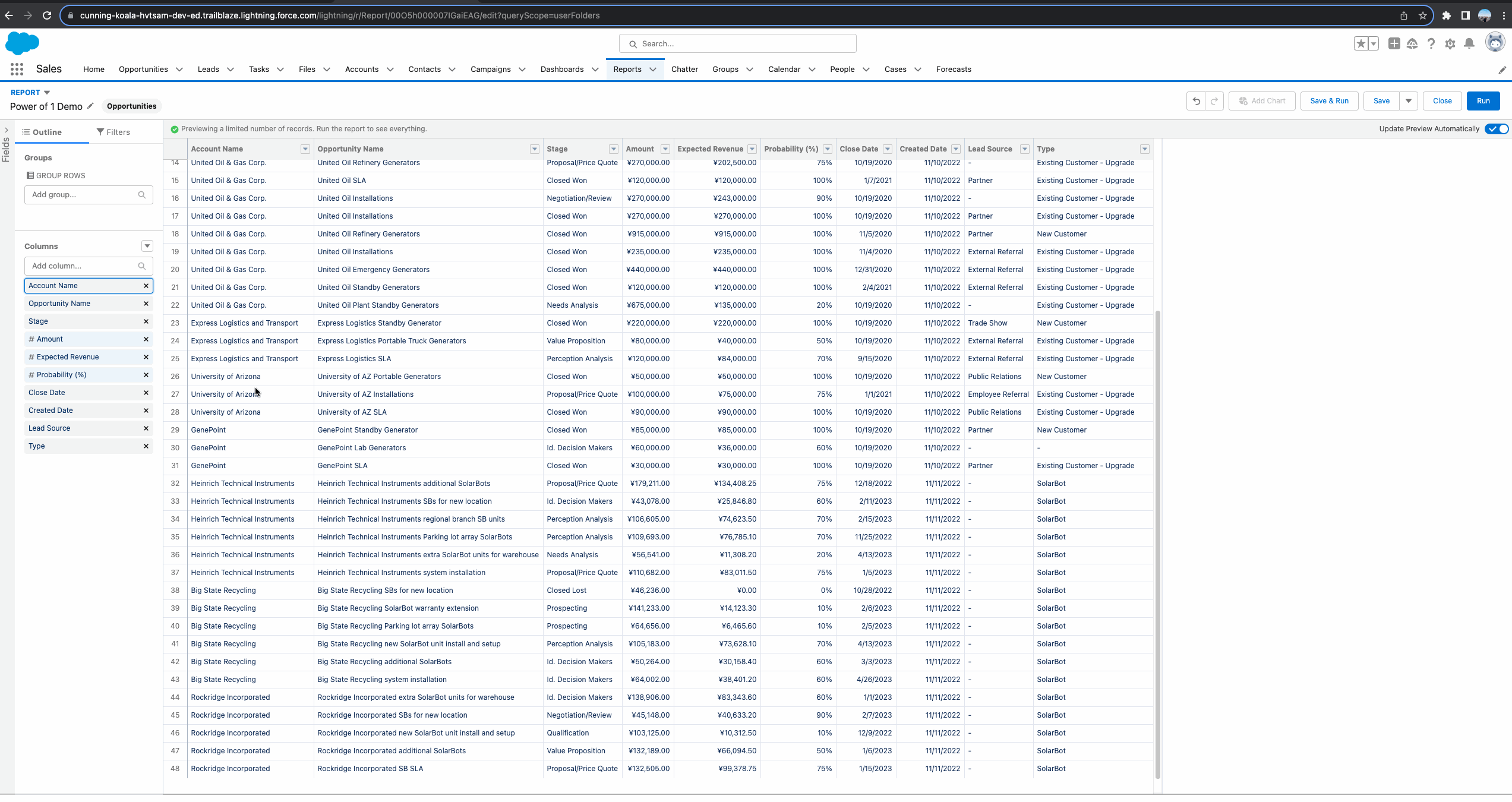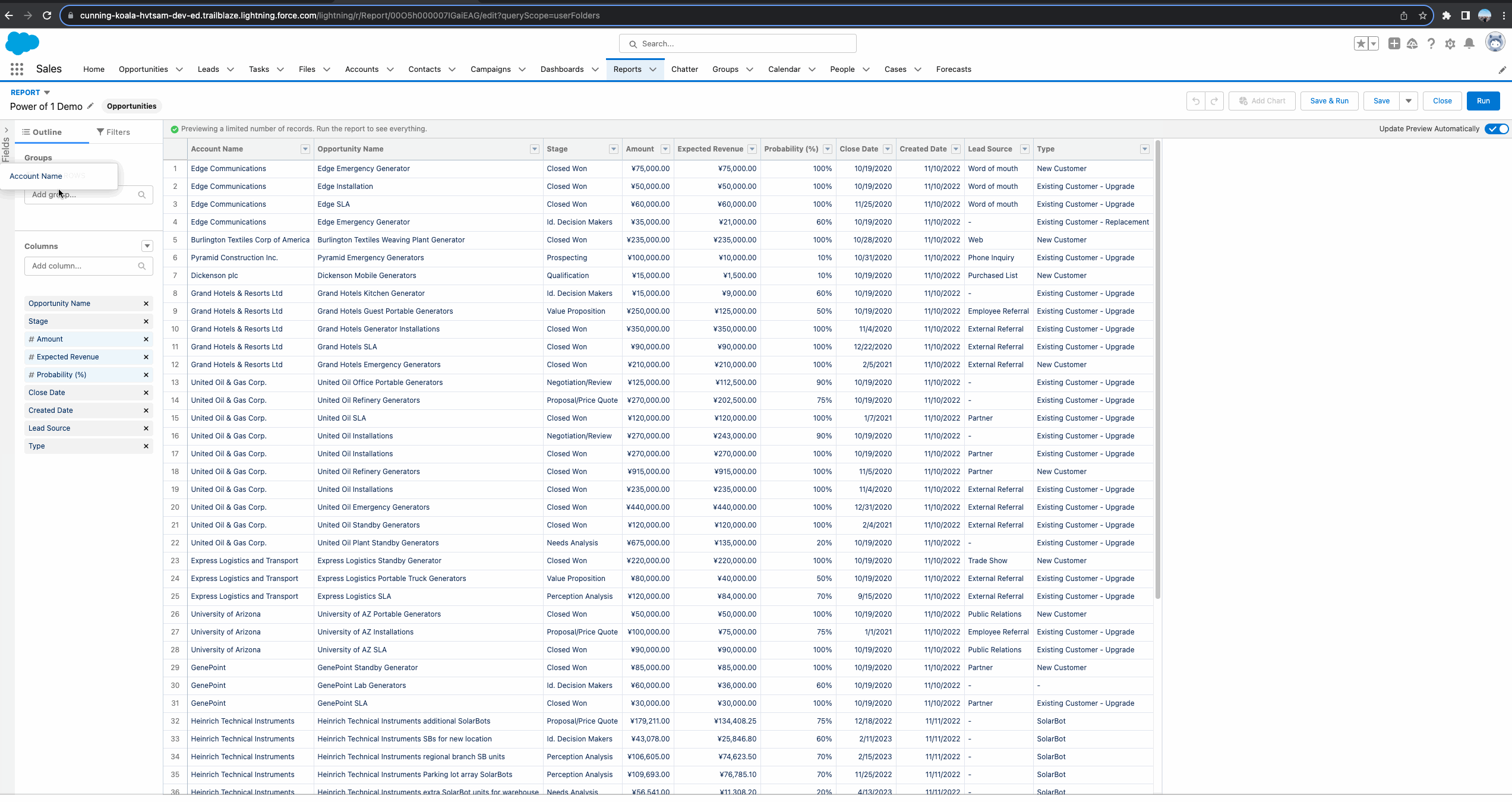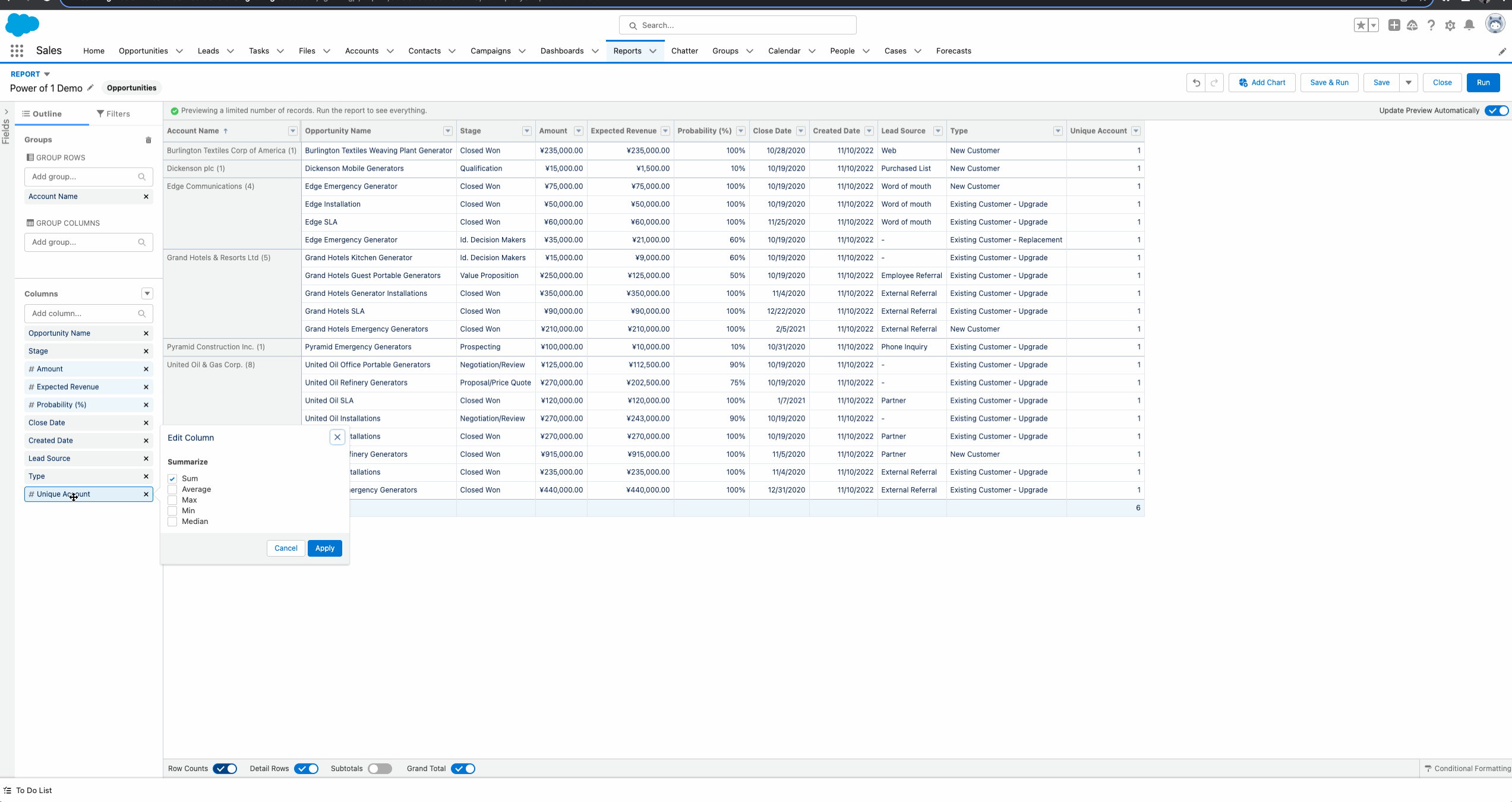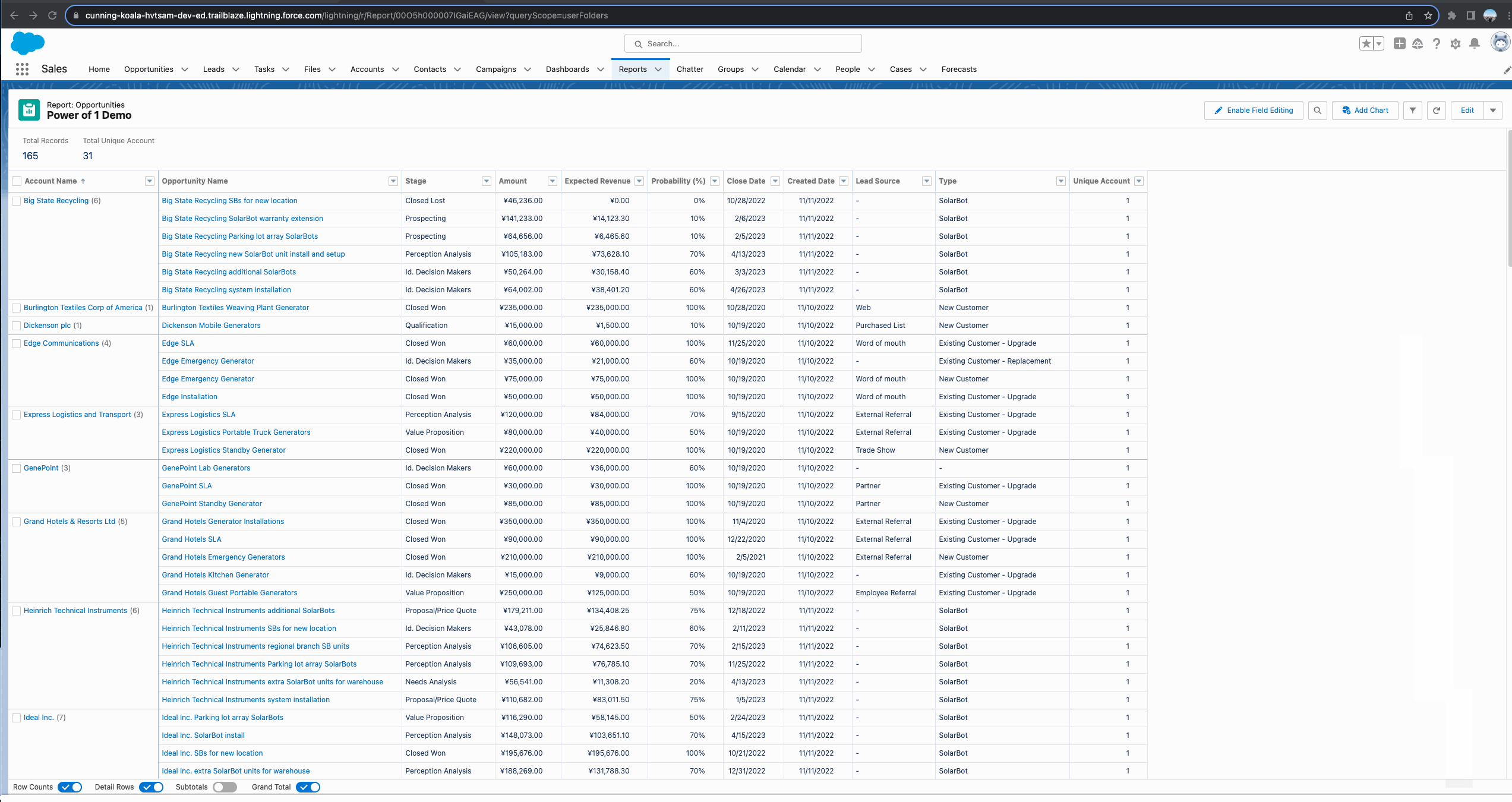
当然, Power Of 1 所能做的远不止如此。以这个功能做一下引申,我们有时候的需求需要比较相同字段级别的不同阶段的转换率。举个例子,Opportunity有不同的Stage,我们有时需要计算 某个Stage在某几个Stage中所占的比例。这种需求可以使用Power Of 1进行快速实现。这里我们模拟一个需求: 我们的Opportunity Stage有Prospecting,Needs Analysis, Negotiation/Review, Closed Won。
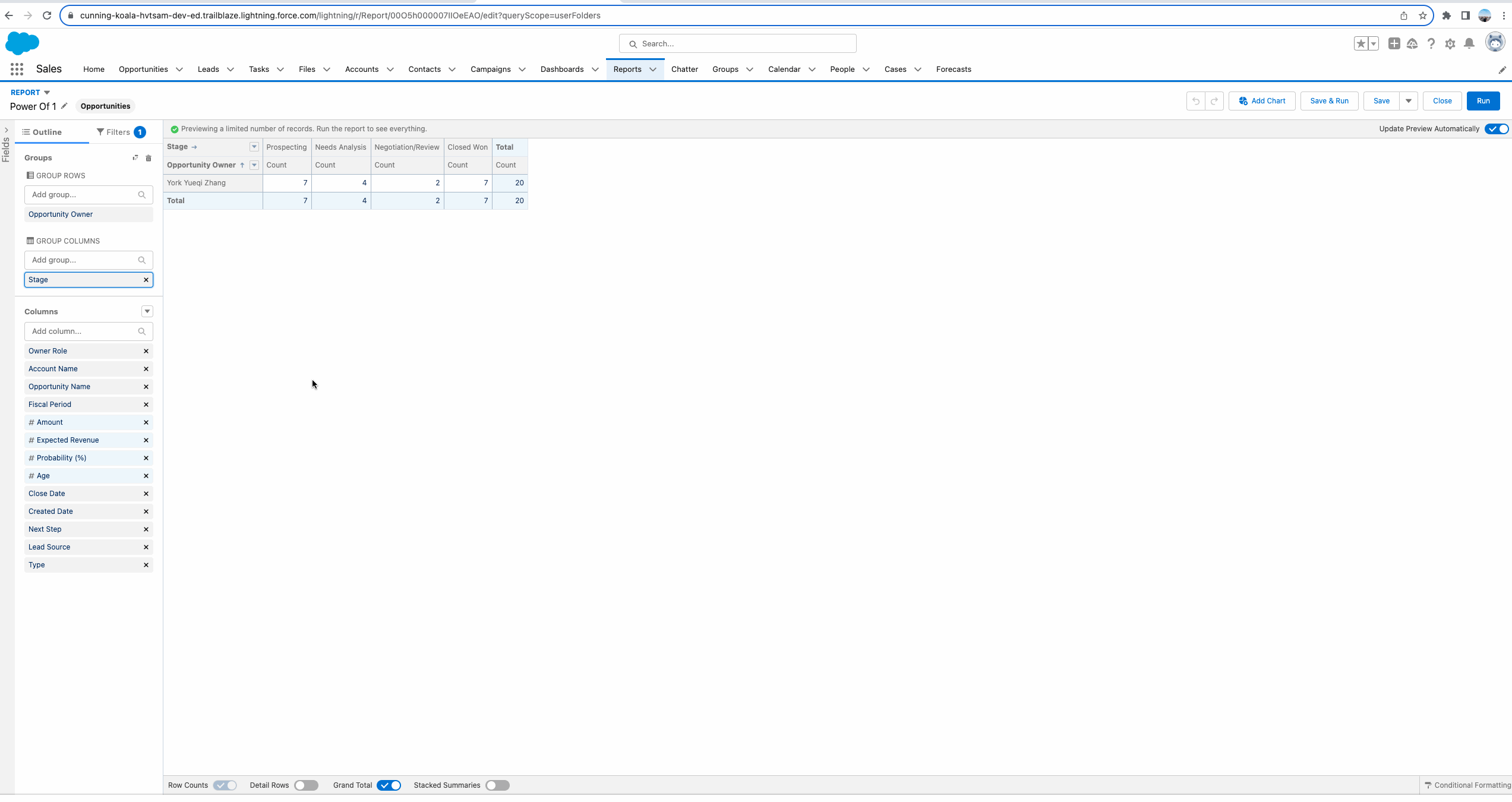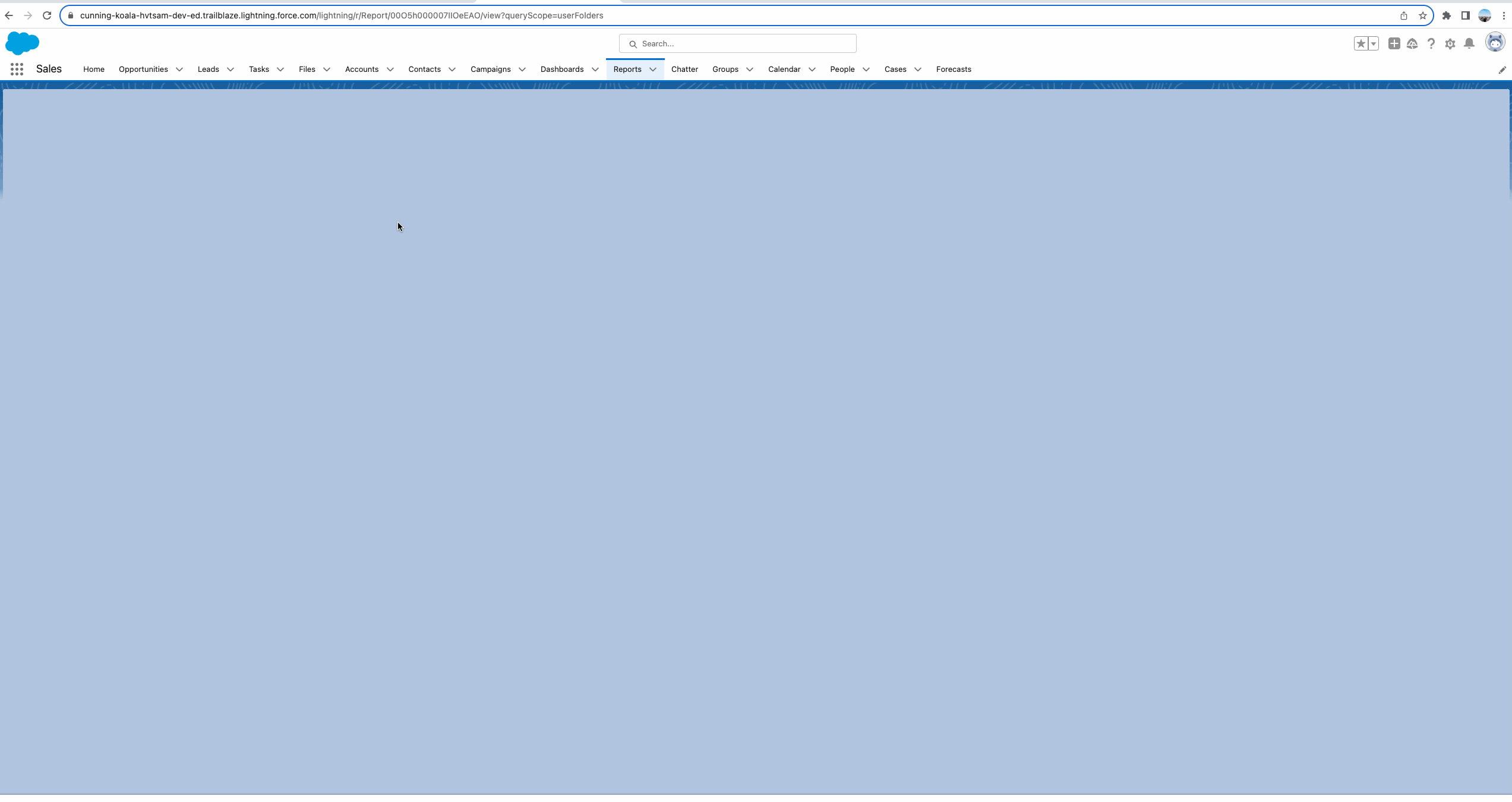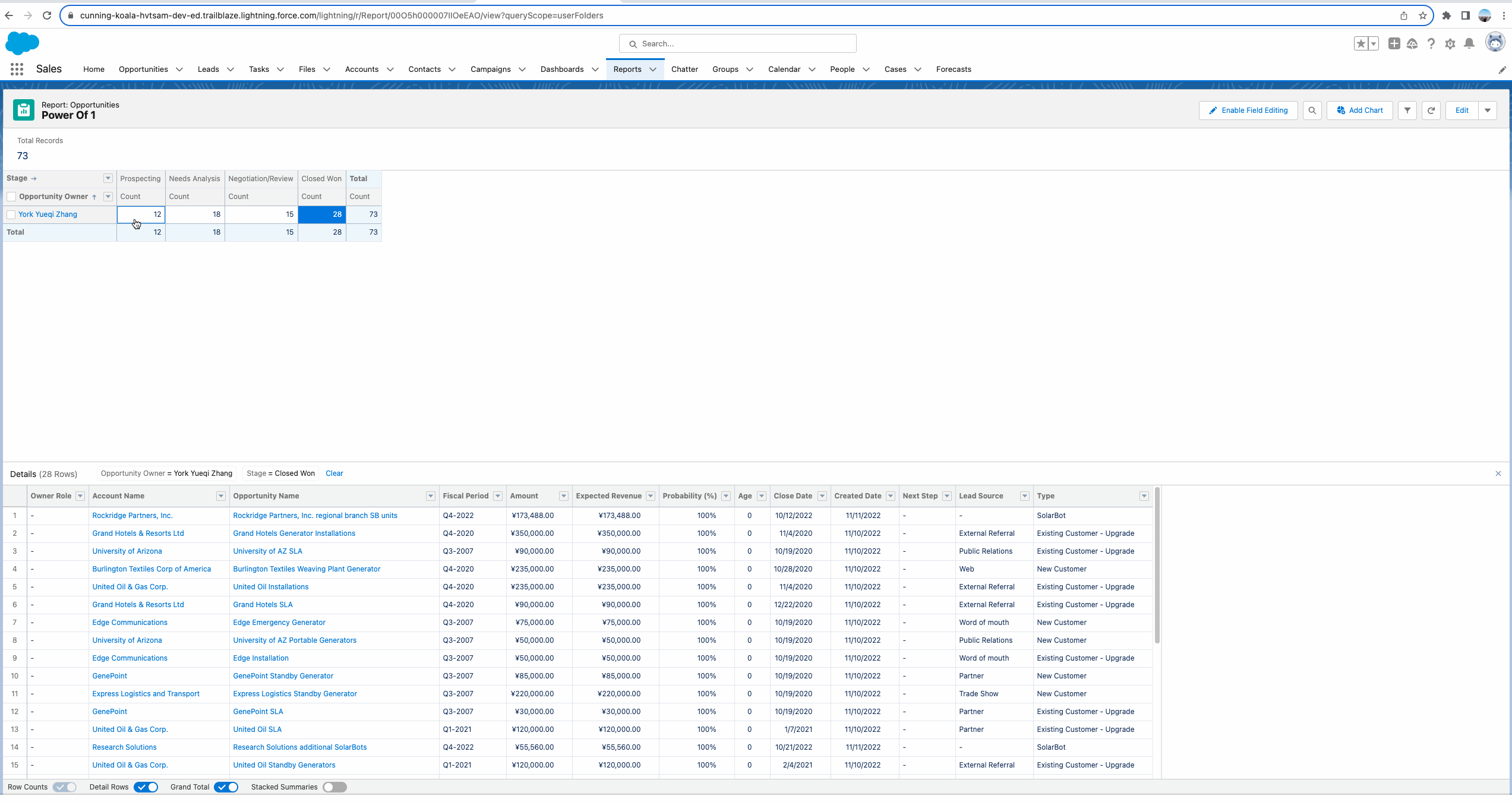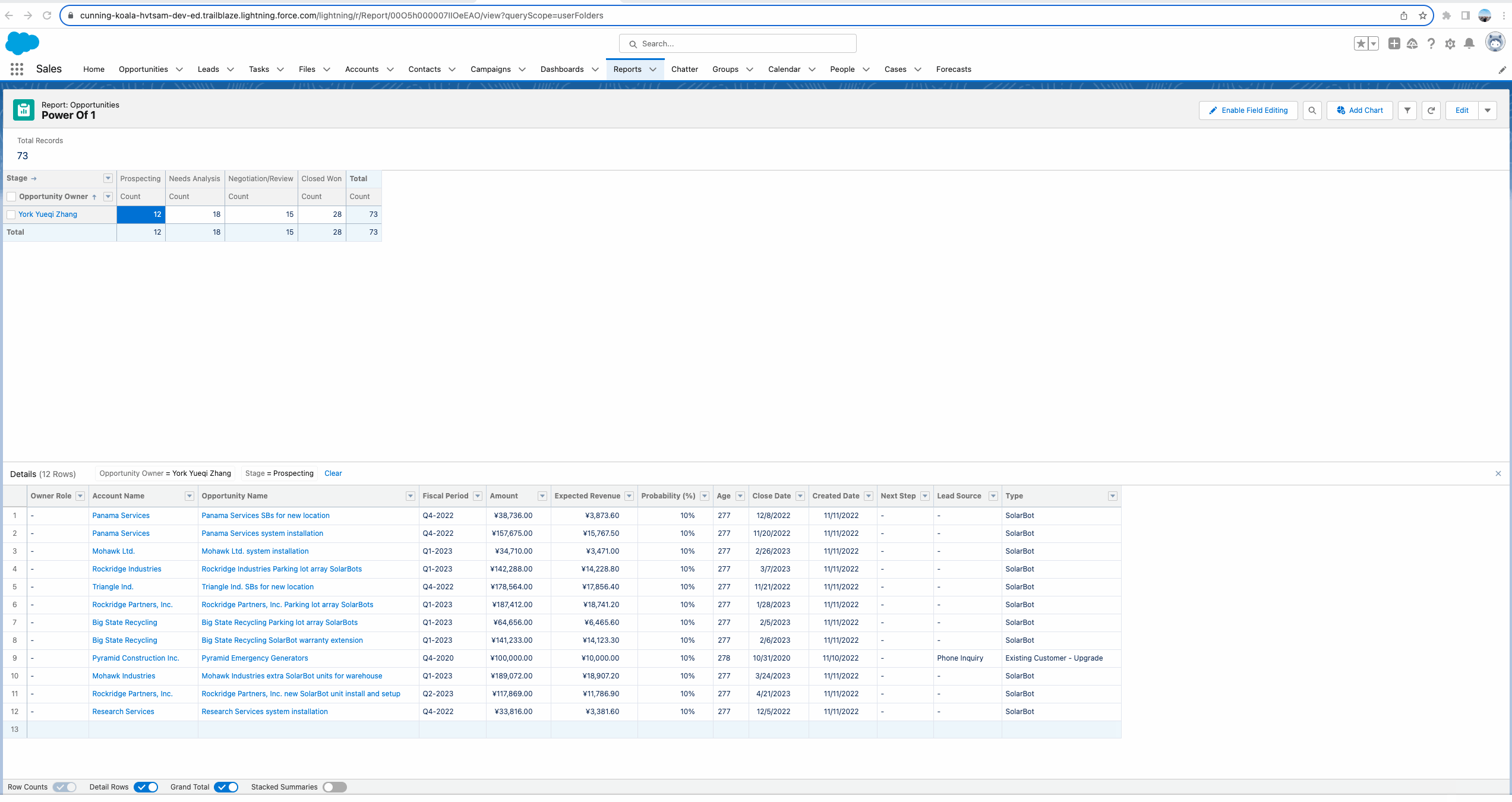
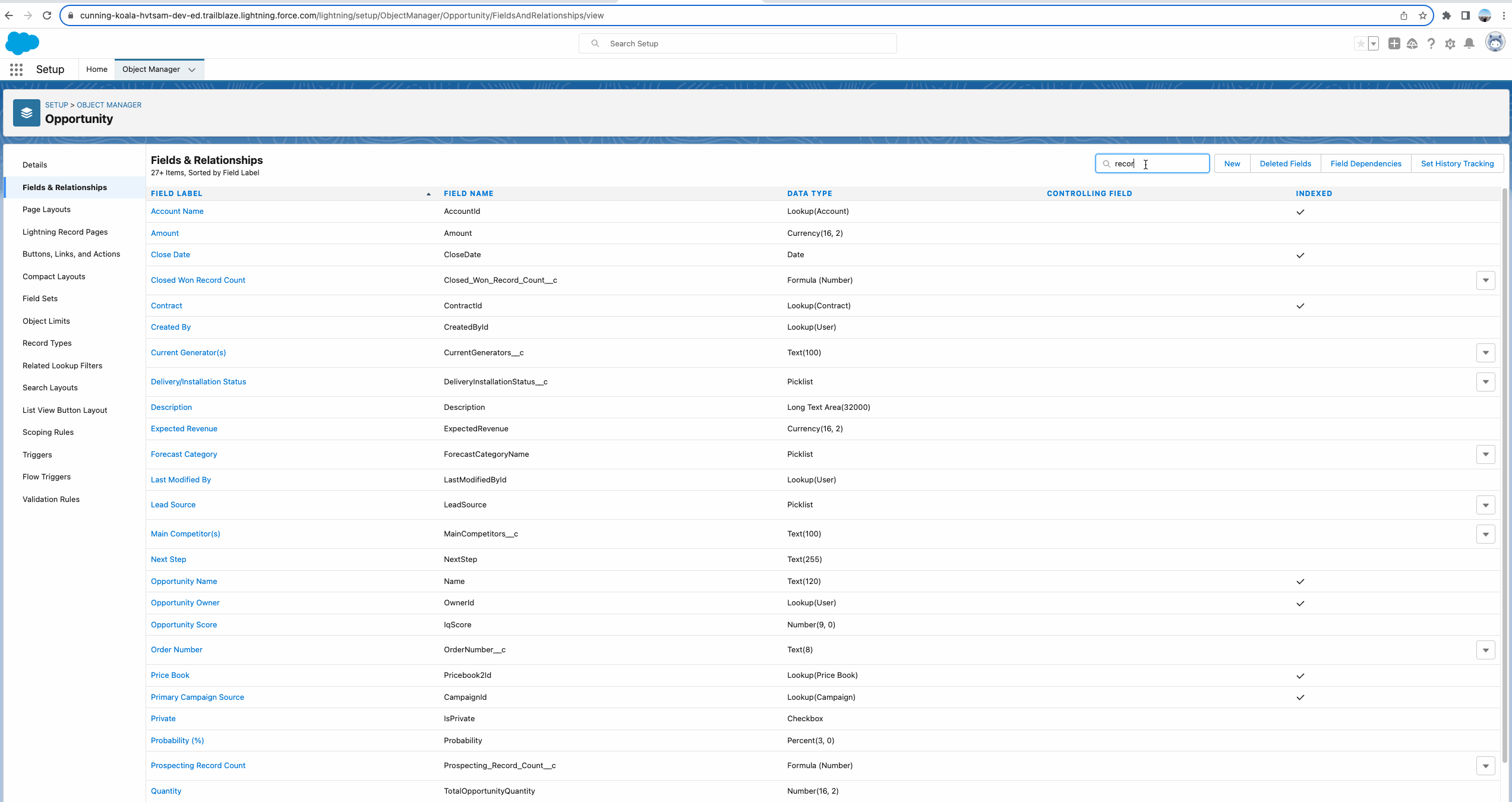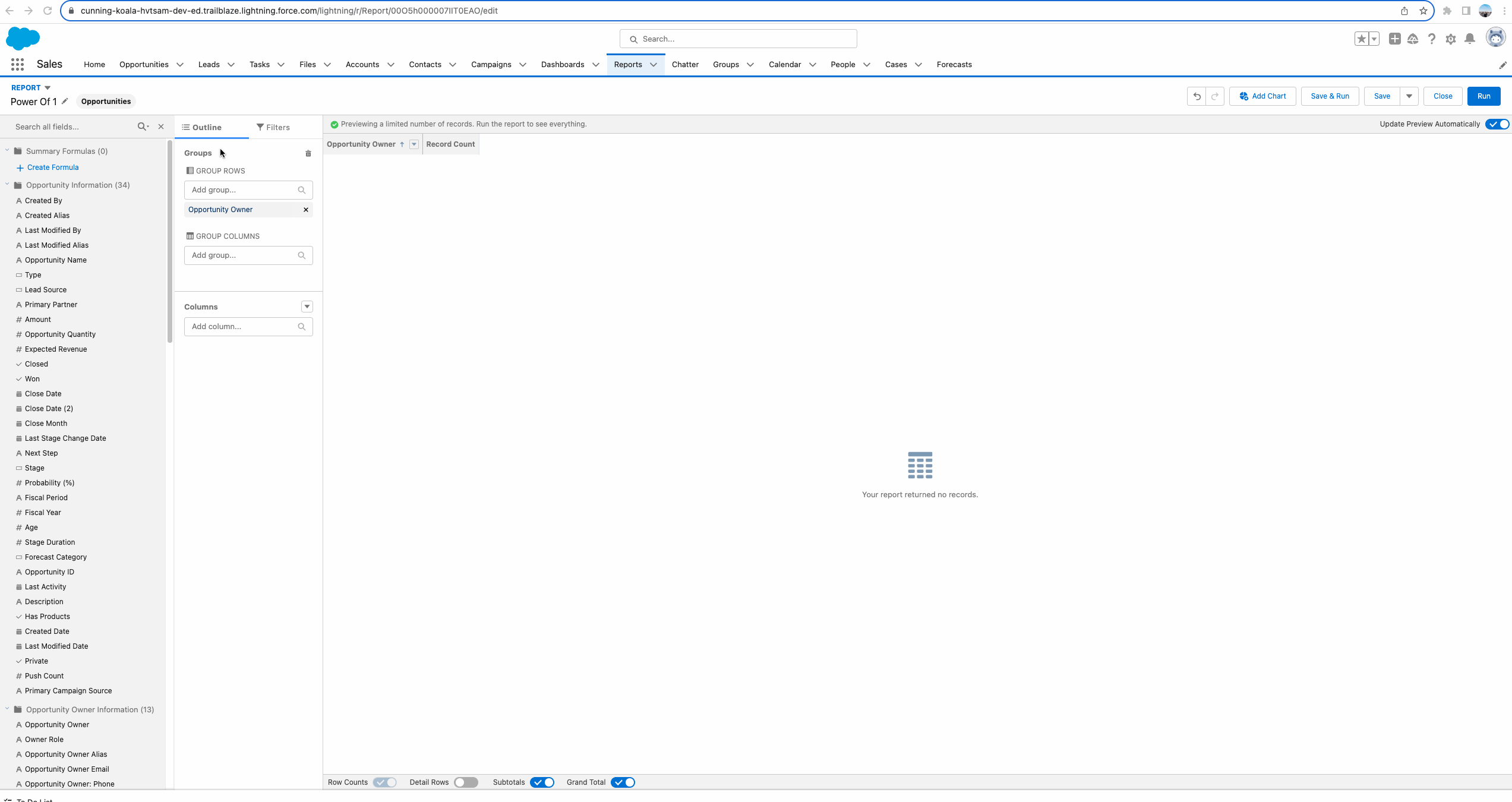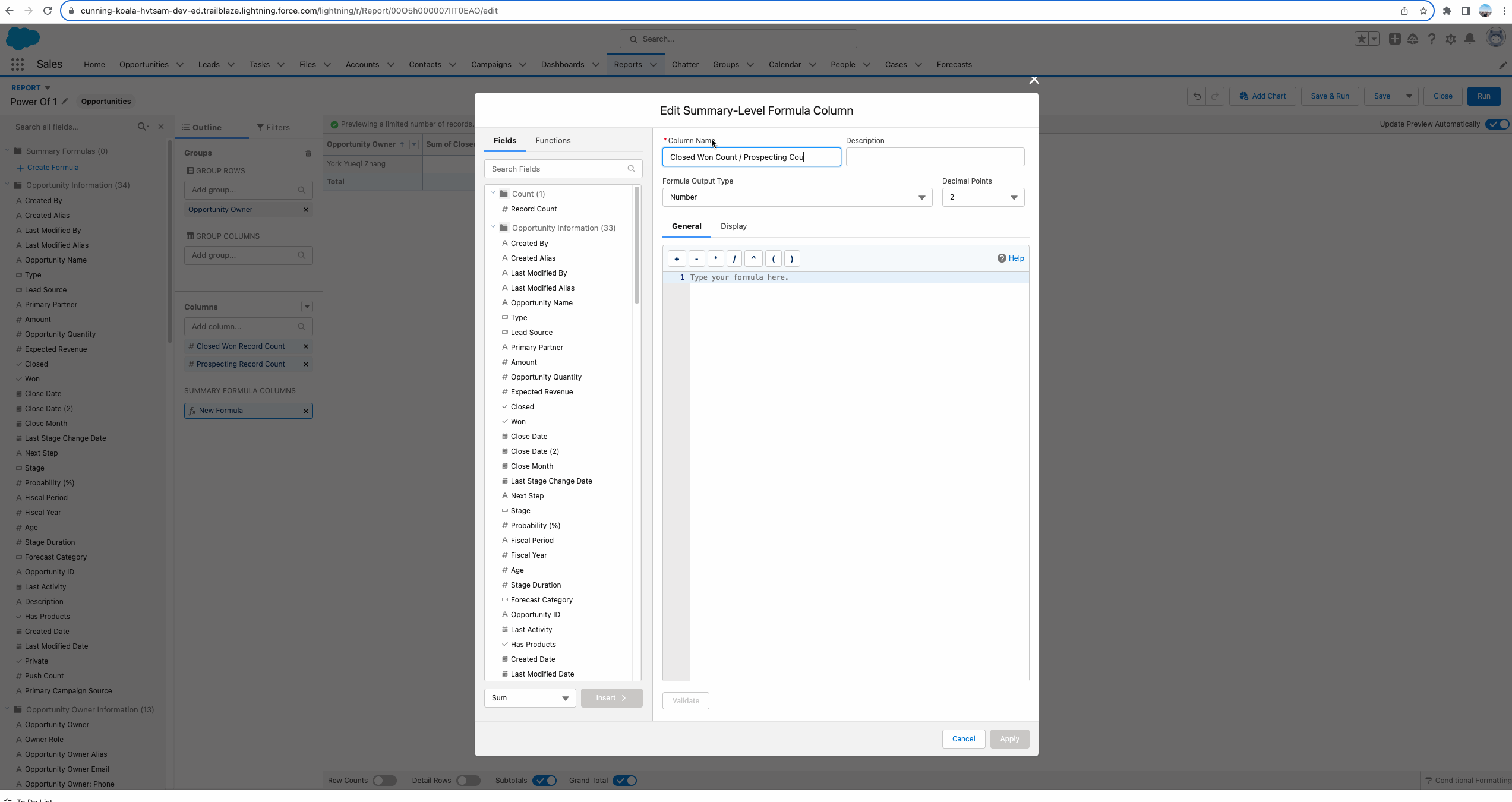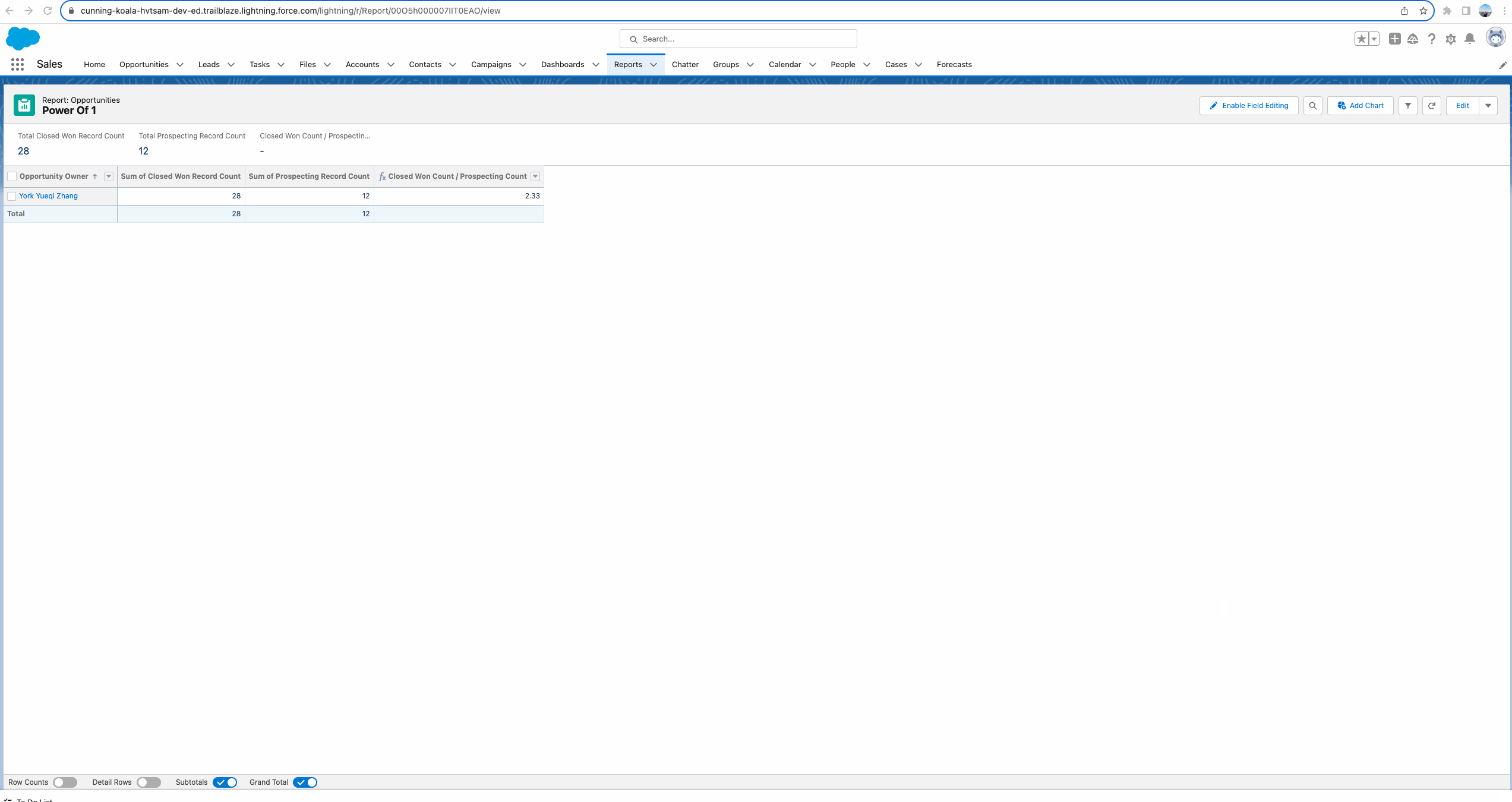
我们需要计算Closed Won的数量针对每个其他阶段的比率。即 Closed Won Record Count / Prospecting => 28 / 12; Closed Won Record Count / Needs Analysis => 28 / 18; Closed Won Record Count / Negotiation/Review =>15 28 / 。那么如何实现这种需求呢? 可以使用Power Of 1的神奇之处。我们以Closed Won Record Count / Prospecting为例。
根据下方的gif我们可以看出来,新建两个formula字段,如果当前的Stage为指定的值,设置为1,否则设置为0. 之后在report中只需要创建一个 report formula字段即可实现需求。
总结:篇中主要介绍了一下Report的两个函数以及Power Of 1简单用法,更多好玩的用法等待你的发掘,本篇仅抛砖引玉。篇中有错误地方欢迎指出,有不懂欢迎留言。
salesforce零基础学习(一百三十)Report 学习进阶篇的更多相关文章
- Python学习日记(三十六) Mysql数据库篇 四
MySQL作业分析 五张表的增删改查: 完成所有表的关系创建 创建教师表(tid为这张表教师ID,tname为这张表教师的姓名) create table teacherTable( tid int ...
- Python学习日记(三十四) Mysql数据库篇 二
外键(Foreign Key) 如果今天有一张表上面有很多职务的信息 我们可以通过使用外键的方式去将两张表产生关联 这样的好处能够节省空间,比方说你今天的职务名称很长,在一张表中就要重复的去写这个职务 ...
- Python学习日记(三十八) Mysql数据库篇 六
Mysql视图 假设执行100条SQL语句时,里面都存在一条相同的语句,那我们可以把这条语句单独拿出来变成一个'临时表',也就是视图可以用来查询. 创建视图: CREATE VIEW passtvie ...
- Python学习日记(三十九) Mysql数据库篇 七
Mysql函数 高级函数 1.BIN(N) 返回N的二进制编码 ); 执行结果: 2.BINARY(str) 将字符串str转换为二进制字符串 select BINARY('ASCII'); 执行结果 ...
- Python学习日记(三十五) Mysql数据库篇 三
使用Navicate 创建一个连接去使用Mysql的数据库,连接名可以取任意字符但是要有意义 新增一个数据库 填写新数据库名,设置它的字符集和排序规则 新建一个表 增加表中的信息 点击保存再去输入表名 ...
- 【转】零基础写Java知乎爬虫之进阶篇
转自:脚本之家 说到爬虫,使用Java本身自带的URLConnection可以实现一些基本的抓取页面的功能,但是对于一些比较高级的功能,比如重定向的处理,HTML标记的去除,仅仅使用URLConnec ...
- Membership三步曲之进阶篇 - 深入剖析Provider Model
Membership 三步曲之进阶篇 - 深入剖析Provider Model 本文的目标是让每一个人都知道Provider Model 是什么,并且能灵活的在自己的项目中使用它. Membershi ...
- salesforce零基础学习(一百二十四)Postman 使用
本篇参考: Salesforce 集成篇零基础学习(一)Connected App salesforce 零基础学习(三十三)通过REST方式访问外部数据以及JAVA通过rest方式访问salesfo ...
- salesforce零基础学习(一百二十八)Durable Id获取以及相关概念浅入浅出
本篇参考: salesforce 零基础开发入门学习(十一)sObject及Schema深入 https://developer.salesforce.com/docs/atlas.en-us.api ...
- salesforce零基础学习(一百二十五)零基础学习SF路径
本篇参考: https://boulder-bard-27f.notion.site/Salesforce-Learning-e990864695674f07b99a5f8955770bd4 本篇背景 ...
随机推荐
- 2020-09-14:KVM和XEN虚拟化的区别?
福哥答案2020-09-14:#福大大架构师每日一题#[答案来自此链接](https://bbs.csdn.net/topics/397671000)KVM:1.虚拟化支持:全虚拟化.2.支持架构:虚 ...
- 2022-07-18:以下go语言代码输出什么?A:Groutine;B:Main;C:Goroutine;D:GoroutineMain。 package main import ( “f
2022-07-18:以下go语言代码输出什么?A:Groutine:B:Main:C:Goroutine:D:GoroutineMain. package main import ( "f ...
- 2021-07-11:给定一个棵完全二叉树,返回这棵树的节点个数,要求时间复杂度小于O(树的节点数)。
2021-07-11:给定一个棵完全二叉树,返回这棵树的节点个数,要求时间复杂度小于O(树的节点数). 福大大 答案2021-07-11: 右树最左节点层数==左树最左节点层数,左树是满二叉树,统计左 ...
- 2021-11-04:计算右侧小于当前元素的个数。给你`一个整数数组 nums ,按要求返回一个新数组 counts 。数组 counts 有该性质: counts[i] 的值是 nums[i] 右
2021-11-04:计算右侧小于当前元素的个数.给你`一个整数数组 nums ,按要求返回一个新数组 counts .数组 counts 有该性质: counts[i] 的值是 nums[i] 右侧 ...
- jmeter如何保存变量到结果jtl文件里
将变量保存到结果jtl文件里,可以方便的在generate报告时,自行取用jtl中的变量进行展示,实现过程如下: 1.打开jmeter/bin目录下的jmeter.properties文件,将变量名加 ...
- IntelliJ IDEA 最新激活码:2023、2022及以下版本通用(亲测有效)
分享一下 IntelliJ IDEA 2023.1 最新激活注册码,破解教程如下,可免费永久激活,亲测有效,下面是详细文档哦~ 申明:本教程 IntelliJ IDEA 破解补丁.激活码均收集于网络, ...
- 【Python】如何在FastAPI中使用UUID标记日志,以跟踪一个请求的完整生命周期
为什么要使用uuid标记日志? 在分布式系统中,一个请求可能会经过多个服务,每个服务都会生成自己的日志.如果我们只使用普通的日志记录,那么很难将这些日志串联在一起,以至难以跟踪一个请求的完整生命周期. ...
- 拒绝conda, 用virtualenv构建多版本的python开发环境
本文章转载自公众号 "生信码农笔记(ID:bio-coder)",已获得原作者授权. 1. 不喜欢用 conda 特别不喜欢 bioconda, miniconda, Anacon ...
- 通过redis学网络(2)-redis网络模型
本系列主要是为了对redis的网络模型和集群原理进行学习,我会用golang实现一个reactor网络模型,并实现对redis协议的解析. 系列源码已经上传github https://github. ...
- xpoc漏洞使用与编写 浅尝
下载地址 https://github.com/chaitin/xpoc/releases 目前最新版本是 0.0.4 可能是我还是不太习惯yaml这种结构的,感觉就很反人类,所以我以前一般都还是po ...