神经网络之卷积篇:详解残差网络(ResNets)(Residual Networks (ResNets))
详解残差网络
ResNets是由残差块(Residual block)构建的,首先解释一下什么是残差块。
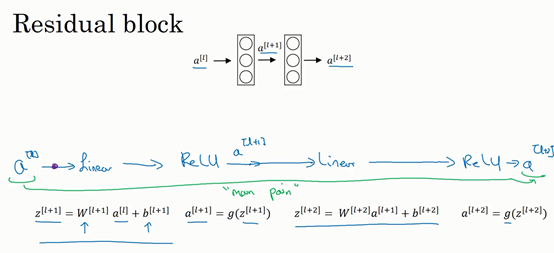
这是一个两层神经网络,在\(L\)层进行激活,得到\(a^{\left\lbrack l + 1 \right\rbrack}\),再次进行激活,两层之后得到\(a^{\left\lbrack l + 2 \right\rbrack}\)。计算过程是从\(a^{[l]}\)开始,首先进行线性激活,根据这个公式:\(z^{\left\lbrack l + 1 \right\rbrack} = W^{\left\lbrack l + 1 \right\rbrack}a^{[l]} + b^{\left\lbrack l + 1 \right\rbrack}\),通过\(a^{[l]}\)算出\(z^{\left\lbrack l + 1 \right\rbrack}\),即\(a^{[l]}\)乘以权重矩阵,再加上偏差因子。然后通过ReLU非线性激活函数得到\(a^{\left\lbrack l + 1 \right\rbrack}\),\(a^{\left\lbrack l + 1 \right\rbrack} =g(z^{\left\lbrack l + 1 \right\rbrack})\)计算得出。接着再次进行线性激活,依据等式\(z^{\left\lbrack l + 2 \right\rbrack} = W^{\left\lbrack 2 + 1 \right\rbrack}a^{\left\lbrack l + 1 \right\rbrack} + b^{\left\lbrack l + 2 \right\rbrack}\),最后根据这个等式再次进行ReLu非线性激活,即\(a^{\left\lbrack l + 2 \right\rbrack} = g(z^{\left\lbrack l + 2 \right\rbrack})\),这里的\(g\)是指ReLU非线性函数,得到的结果就是\(a^{\left\lbrack l + 2 \right\rbrack}\)。换句话说,信息流从\(a^{\left\lbrack l \right\rbrack}\)到\(a^{\left\lbrack l + 2 \right\rbrack}\)需要经过以上所有步骤,即这组网络层的主路径。
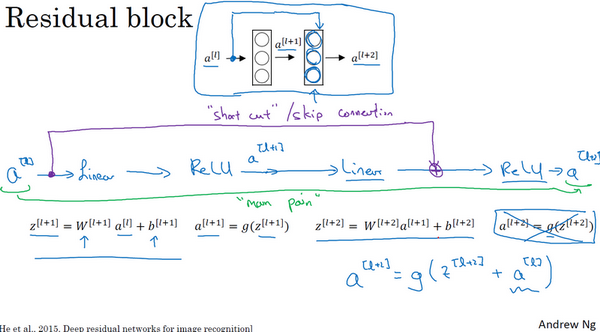
在残差网络中有一点变化,将\(a^{[l]}\)直接向后,拷贝到神经网络的深层,在ReLU非线性激活函数前加上\(a^{[l]}\),这是一条捷径。\(a^{[l]}\)的信息直接到达神经网络的深层,不再沿着主路径传递,这就意味着最后这个等式(\(a^{\left\lbrack l + 2 \right\rbrack} = g(z^{\left\lbrack l + 2 \right\rbrack})\))去掉了,取而代之的是另一个ReLU非线性函数,仍然对\(z^{\left\lbrack l + 2 \right\rbrack}\)进行\(g\)函数处理,但这次要加上\(a^{[l]}\),即:\(\ a^{\left\lbrack l + 2 \right\rbrack} = g\left(z^{\left\lbrack l + 2 \right\rbrack} + a^{[l]}\right)\),也就是加上的这个\(a^{[l]}\)产生了一个残差块。
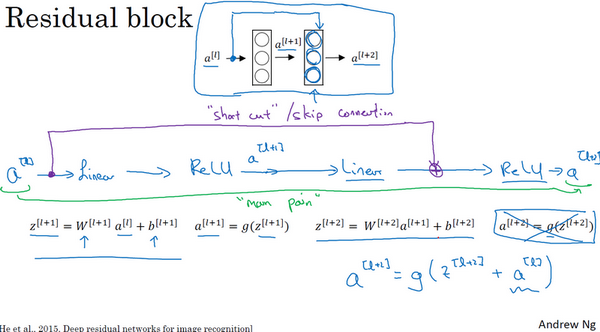
在上面这个图中,也可以画一条捷径,直达第二层。实际上这条捷径是在进行ReLU非线性激活函数之前加上的,而这里的每一个节点都执行了线性函数和ReLU激活函数。所以\(a^{[l]}\)插入的时机是在线性激活之后,ReLU激活之前。除了捷径,还会听到另一个术语“跳跃连接”,就是指\(a^{[l]}\)跳过一层或者好几层,从而将信息传递到神经网络的更深层。
ResNet的发明者是何凯明(Kaiming He)、张翔宇(Xiangyu Zhang)、任少卿(Shaoqing Ren)和孙剑(Jiangxi Sun),他们发现使用残差块能够训练更深的神经网络。所以构建一个ResNet网络就是通过将很多这样的残差块堆积在一起,形成一个很深神经网络,来看看这个网络。

这并不是一个残差网络,而是一个普通网络(Plain network),这个术语来自ResNet论文。
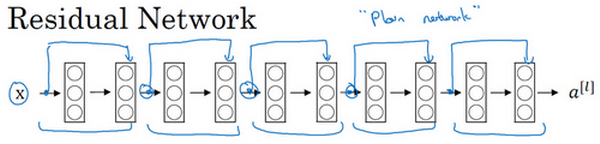
把它变成ResNet的方法是加上所有跳跃连接,每两层增加一个捷径,构成一个残差块。如图所示,5个残差块连接在一起构成一个残差网络。
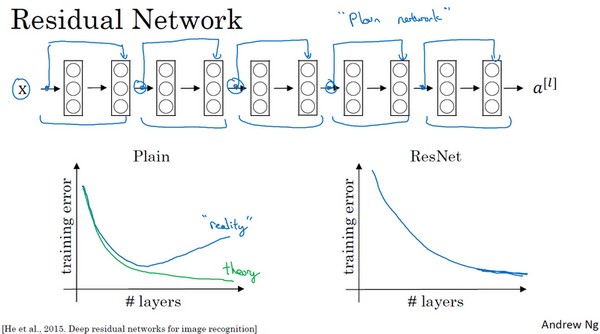
如果使用标准优化算法训练一个普通网络,比如说梯度下降法,或者其它热门的优化算法。如果没有残差,没有这些捷径或者跳跃连接,凭经验会发现随着网络深度的加深,训练错误会先减少,然后增多。而理论上,随着网络深度的加深,应该训练得越来越好才对。也就是说,理论上网络深度越深越好。但实际上,如果没有残差网络,对于一个普通网络来说,深度越深意味着用优化算法越难训练。实际上,随着网络深度的加深,训练错误会越来越多。
但有了ResNets就不一样了,即使网络再深,训练的表现却不错,比如说训练误差减少,就算是训练深达100层的网络也不例外。有人甚至在1000多层的神经网络中做过实验,尽管目前还没有看到太多实际应用。但是对\(x\)的激活,或者这些中间的激活能够到达网络的更深层。这种方式确实有助于解决梯度消失和梯度爆炸问题,让在训练更深网络的同时,又能保证良好的性能。也许从另外一个角度来看,随着网络越来深,网络连接会变得臃肿,但是ResNet确实在训练深度网络方面非常有效。
神经网络之卷积篇:详解残差网络(ResNets)(Residual Networks (ResNets))的更多相关文章
- 残差网络(Residual Networks, ResNets)
1. 什么是残差(residual)? “残差在数理统计中是指实际观察值与估计值(拟合值)之间的差.”“如果回归模型正确的话, 我们可以将残差看作误差的观测值.” 更准确地,假设我们想要找一个 $x$ ...
- 基于双向BiLstm神经网络的中文分词详解及源码
基于双向BiLstm神经网络的中文分词详解及源码 基于双向BiLstm神经网络的中文分词详解及源码 1 标注序列 2 训练网络 3 Viterbi算法求解最优路径 4 keras代码讲解 最后 源代码 ...
- Dual Path Networks(DPN)——一种结合了ResNet和DenseNet优势的新型卷积网络结构。深度残差网络通过残差旁支通路再利用特征,但残差通道不善于探索新特征。密集连接网络通过密集连接通路探索新特征,但有高冗余度。
如何评价Dual Path Networks(DPN)? 论文链接:https://arxiv.org/pdf/1707.01629v1.pdf在ImagNet-1k数据集上,浅DPN超过了最好的Re ...
- PHP函数篇详解十进制、二进制、八进制和十六进制转换函数说明
PHP函数篇详解十进制.二进制.八进制和十六进制转换函数说明 作者: 字体:[增加 减小] 类型:转载 中文字符编码研究系列第一期,PHP函数篇详解十进制.二进制.八进制和十六进制互相转换函数说明 ...
- 走向DBA[MSSQL篇] 详解游标
原文:走向DBA[MSSQL篇] 详解游标 前篇回顾:上一篇虫子介绍了一些不常用的数据过滤方式,本篇详细介绍下游标. 概念 简单点说游标的作用就是存储一个结果集,并根据语法将这个结果集的数据逐条处理. ...
- Scala进阶之路-Scala函数篇详解
Scala进阶之路-Scala函数篇详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.传值调用和传名调用 /* @author :yinzhengjie Blog:http: ...
- 深度残差网(deep residual networks)的训练过程
这里介绍一种深度残差网(deep residual networks)的训练过程: 1.通过下面的地址下载基于python的训练代码: https://github.com/dnlcrl/deep-r ...
- 详解ResNet 网络,如何让网络变得更“深”了
摘要:残差网络(ResNet)的提出是为了解决深度神经网络的"退化"(优化)问题.ResNet 通过设计残差块结构,调整模型结构,让更深的模型能够有效训练更训练. 本文分享自华为云 ...
- 一文详解 WebSocket 网络协议
WebSocket 协议运行在TCP协议之上,与Http协议同属于应用层网络数据传输协议.WebSocket相比于Http协议最大的特点是:允许服务端主动向客户端推送数据(从而解决Http 1.1协议 ...
- Oracle10g数据泵impdp参数详解--摘自网络
Oracle10g数据泵impdp参数详解 2011-6-30 12:29:05 导入命令Impdp • ATTACH 连接到现有作业, 例如 ATTACH [=作业名]. • C ...
随机推荐
- 【JavaScript】Jquery事件绑定问题
我们所知道的选择器方式,其中有一种方式是属性选择器: <div style="display: flex; justify-content: space-between;"& ...
- 带有最小间隔时间的队列读取实现 —— 最小等待时间的队列 —— Python编程(续)
接前文: 带有最小间隔时间的队列读取实现 -- 最小等待时间的队列 -- Python编程 由于上次的设计多少有些简单,这里对此丰富一下. ============================== ...
- 如果一个windows主机上插两个蓝牙适配器会如何???——由于 Windows 无法加载这个设备所需的驱动程序,导致这个设备工作异常。 (代码 31)——windows主机蓝牙适配器驱动错误排查
事情是这样的,在某鱼上挂了一个蓝牙适配器,是自己多年前买的,给自己的老电脑用的,那一台老电脑主板上没有自带蓝牙,于是就在某东上买了一个蓝牙适配器: 但是这几年新买的电脑都自带蓝牙,于是准备把这个适配器 ...
- ffpyplayer源码编译报错:ffpyplayer/tools.pyx:182:28: Cannot assign type 'void (*)(void *, int, const char *, va_list) except * nogil' to 'void (*)(void *, int, const char *, va_list) noexcept nogil'
编译ffpyplayer报错,具体错误如标题. 报错信息: ffpyplayer/tools.pyx:182:28: Cannot assign type 'void (*)(void *, int, ...
- 从baselines库的common/vec_env/vec_normalize.py模块看方差的近似计算方法
在baselines库的common/vec_env/vec_normalize.py中计算方差的调用方法为: RunningMeanStd 同时该计算函数的解释也一并给出了: https://en. ...
- 如何更改Python项目中的 模块搜索第一路径
内容承接上文: Python语言中当前工作目录(Current Working Directory, cwd)与模块搜索第一路径都是指什么??? 上文中已经解释了当前工作目录cwd与模块搜索路径的区别 ...
- 再探 游戏 《 2048 》 —— AI方法—— 缘起、缘灭(5) —— 第一个用于解决2048游戏的Reinforcement learning方法——《Temporal Difference Learning of N-Tuple Networks for the Game 2048》
<2048>游戏在线试玩地址: https://play2048.co/ 如何解决<2048>游戏源于外网的一个讨论帖子,而这个帖子则是讨论如何解决该游戏的最早开始,可谓是&q ...
- git 如何在本地批量删除匹配名称分支
背景 有时间创建了一大堆的dev/*分支,远程合并完就删除了,但本地还留下一大堆,自己又忘记删除了.一个个删除太麻烦.后面发现居然有批量删除的方法 备注:这里是window下powershell的命令 ...
- java多线程之自定义线程池
1.背景 线程池.....大家常用.... 自己搞一个,顺便练习一下多线程编程 2.自定义线程代码 2.1.拒绝策略接口 @FunctionalInterface public interface M ...
- SearXNG与LLM强强联合:打造用户隐私保护的智能搜索解答流程,隐私无忧,搜索无忧
SearXNG与LLM强强联合:打造用户隐私保护的智能搜索解答流程,隐私无忧,搜索无忧 SearXNG 是一个免费的互联网元搜索引擎,整合了各种搜索服务的结果.用户不会被跟踪,也不会被分析. gith ...