Databricks 企业版 Spark&Delta Lake 引擎助力 Lakehouse 高效访问
简介:本文介绍了Databricks企业版Delta Lake的性能优势,借助这些特性能够大幅提升Spark SQL的查询性能,加快Delta表的查询速度。
作者:
李锦桂(锦犀) 阿里云开源大数据平台开发工程师
王晓龙(筱龙) 阿里云开源大数据平台技术专家
背景介绍
Databricks是全球领先的Data+AI企业,是Apache Spark的创始公司,也是Spark的最大代码贡献者,核心围绕Spark、Delta Lake、MLFlow等开源生态打造企业级Lakehouse产品。2020年,Databricks 和阿里云联手打造了基于Apache Spark的云上全托管大数据分析&AI平台——Databricks数据洞察(DDI,Databricks DataInsight),为用户提供数据分析、数据工程、数据科学和人工智能等方面的服务,构建一体化的Lakehouse架构。

Delta Lake是Databricks从2016年开始在内部研发的一款支持事务的数据湖产品,于2019年正式开源。除了社区主导的开源版Delta Lake OSS,Databricks商业产品里也提供了企业版Spark&Detla Lake引擎,本文将介绍企业版提供的产品特性如何优化性能,助力高效访问Lakehouse。
针对小文件问题的优化解法
在Delta Lake中频繁执行merge, update, insert操作,或者在流处理场景下不断往Delta表中插入数据,会导致Delta表中产生大量的小文件。小文件数量的增加一方面会使得Spark每次串行读取的数据量变少,降低读取效率,另一方面,使得Delta表的元数据增加,元数据获取变慢,从另一个维度降低表的读取效率。
为了解决小文件问题,Databricks提供了三个优化特性,从避免小文件的产生和自动/手动合并小文件两个维度来解决Delta Lake的小文件问题。
特性1:优化Delta表的写入,避免小文件产生
在开源版Spark中,每个executor向partition中写入数据时,都会创建一个表文件进行写入,最终会导致一个partition中产生很多的小文件。Databricks对Delta表的写入过程进行了优化,对每个partition,使用一个专门的executor合并其他executor对该partition的写入,从而避免了小文件的产生。

该特性由表属性delta.autoOptimize.optimizeWrite来控制:
- 可以在创建表时指定
CREATE TABLE student (id INT, name STRING)
TBLPROPERTIES (delta.autoOptimize.optimizeWrite = true);
- 也可以修改表属性
ALTER TABLE table_name
SET TBLPROPERTIES (delta.autoOptimize.optimizeWrite = true);
该特性有两个优点:
- 通过减少被写入的表文件数量,提高写数据的吞吐量;
- 避免小文件的产生,提升查询性能。
其缺点也是显而易见的,由于使用了一个executor来合并表文件的写入,从而降低了表文件写入的并行度,此外,多引入的一层executor需要对写入的数据进行shuffle,带来额外的开销。因此,在使用该特性时,需要对场景进行评估:
- 该特性适用的场景:频繁使用MERGE,UPDATE,DELETE,INSERT INTO,CREATE TABLE AS SELECT等SQL语句的场景;
- 该特性不适用的场景:写入TB级以上数据。
特性2:自动合并小文件
在流处理场景中,比如流式数据入湖场景下,需要持续的将到达的数据插入到Delta表中,每次插入都会创建一个新的表文件用于存储新到达的数据,假设每10s触发一次,那么这样的流处理作业一天产生的表文件数量将达到8640个,且由于流处理作业通常是long-running的,运行该流处理作业100天将产生上百万个表文件。这样的Delta表,仅元数据的维护就是一个很大的挑战,查询性能更是急剧恶化。
为了解决上述问题,Databricks提供了小文件自动合并功能,在每次向Delta表中写入数据之后,会检查Delta表中的表文件数量,如果Delta表中的小文件(size < 128MB的视为小文件)数量达到阈值,则会执行一次小文件合并,将Delta表中的小文件合并为一个新的大文件。
该特性由表属性delta.autoOptimize.autoCompact控制,和特性delta.autoOptimize.optimizeWrite相同,可以在创建表时指定,也可以对已创建的表进行修改。自动合并的阈值由spark.databricks.delta.autoCompact.minNumFiles控制,默认为50,即小文件数量达到50会执行表文件合并;合并后产生的文件最大为128MB,如果需要调整合并后的目标文件大小,可以通过调整配置spark.databricks.delta.autoCompact.maxFileSize实现。
特性3:手动合并小文件
自动小文件合并会在对Delta表进行写入,且写入后表中小文件达到阈值时被触发。除了自动合并之外,Databricks还提供了Optimize命令使用户可以手动合并小文件,优化表结构,使得表文件的结构更加紧凑。在实现上Optimize使用bin-packing算法,该算法不但会合并表中的小文件,且合并后生成的表文件也更均衡(表文件大小相近)。例如,我们要对Delta表student的表文件进行优化,仅需执行如下命令即可实现:
OPTIMIZE student;
Optimize命令不但支持全表小文件的合并,还支持特定的分区的表文件的合并,例如,我们可以仅对date大于2017-01-01的分区中的小文件进行合并:
OPTIMIZE student WHERE date >= '2017-01-01'
从Databricks数据洞察产品上的试验数据看,Optimize能使查询性能达到8x以上的提升。
媲美企业级数据库的查询优化技术
Databricks在数据查询方面也做了诸多优化,包括:
特性1:Data Skipping
在数据查询系统中,有两种经典的查询优化 技术:一种是以更快的速度处理数据,另一种是通过跳过不相关的数据,减少需要扫描的数据量。Data Skipping属于后一种优化技术,通过表文件的统计信息跳过不相关的表文件,从而提升查询性能。
在向Delta表中新增表文件时,Delta Lake会在Delta表的元数据中存储该表文件中的数据前32列的统计信息,包括数据列的最大最小值,以及为null的行的数量,在查询时,Databricks会利用这些统计信息提升查询性能。例如:对于一张Delta表的x列,假设该表的一个表文件x列的最小值为5,最大值为10,如果查询条件为 where x < 3,则根据表文件的统计信息,我们可以得出结论:该表文件中一定不包含我们需要的数据,因此我们可以直接跳过该表文件,减少扫描的数据量,进而提升查询性能。
Data Skipping的实现原理和布隆过滤器类似,通过查询条件判断表文件中是否可能存在需要查询的数据,从而减少需要扫描的数据量。如果表文件不可能存在查询的数据,则可以直接跳过,如果表文件可能存在被查询的数据,则需要扫描表文件。
为了能尽可能多的跳过和查询无关的表文件,我们需要缩小表文件的min-max的差距,使得相近的数据尽可能在文件中聚集。举一个简单的例子,假设一张表包含10个表文件,对于表中的x列,它的取值为[1, 10],如果每个表文件的x列的分布均为[1, 10],则对于查询条件:where x < 3,无法跳过任何一个表文件,因此,也无法实现性能提升,而如果每个表文件的min-max均为0,即在表文件1的x列分布为[1, 1],表文件2的x列分布为[2, 2]...,则对于查询条件:where x < 3,可以跳过80%的表文件。受该思想的启发,Databricks支持使用Z-Ordering来对数据进行聚集,缩小表文件的min-max差距,提升查询性能。下面我们介绍Z-Ordering优化的原理和使用。
特性2:Z-Ordering优化
如上一节所解释的,为了能尽可能多的跳过无关的表文件,表文件中作为查询条件的列应该尽可能紧凑(即min-max的差距尽可能小)。Z-Ordering就可以实现该功能,它可以在多个维度上将关联的信息存储到同一组文件中,因此确切来说,Z-Ordering实际是一种数据布局优化算法,但结合Data Skipping,它可以显著提升查询性能。
Z-Ordering的使用非常简单,对于表events,如果经常使用列eventType和generateTime作为查询条件,那么执行命令:
OPTIMIZE events ZORDER BY (eventType, generateTime)
Delta表会使用列eventType和generateTime调整数据布局,使得表文件中eventType和generateTime尽可能紧凑。
根据我们在Databricks DataInsight上的试验,使用Z-Ordering优化能达到40倍的性能提升,具体的试验案例参考文末Databricks数据洞察的官方文档。
特性3:布隆过滤器索引
布隆过滤器也是一项非常有用的Data-skipping技术。该技术可以快速判断表文件中是否包含要查询的数据,如果不包含就及时跳过该文件,从而减少扫描的数据量,提升查询性能。
如果在表的某列上创建了布隆过滤器索引,并且使用where col = "something"作为查询条件,那么在扫描表中文件时,我们可以使用布隆过滤器索引得出两种结论:文件中肯定不包含col = "something"的行,或者文件有可能包含col = "something"的行。
- 当得出文件中肯定不包含
col = "something"的行的结论时,就可以跳过该文件,从而减少扫描的数据量,提升查询性能。 - 当得出文件中可能包含
col = "something"的行的结论时,引擎才会去处理该文件。注意,这里仅仅是判断该文件中可能包含目标数据。布隆过滤器定义了一个指标,用于描述出现判断失误的概率,即判断文件中包含需要查询的数据,而实际上该文件并不包含目标数据的概率,并称之为FPP(False Positive Probability: 假阳性概率)。
Databricks支持文件级Bloom过滤器,如果在表的某些列创建了布隆过滤器索引,那么该表的每个表文件都会关联一个 Bloom 筛选器索引文件,索引文件存储在表文件同级目录下的 _delta_index 子目录中。在读取表文文件之前,Databricks会检查索引文件,根据上面的步骤判断表文件中是否包含需要查询的数据,如果不包含则直接跳过,否则再进行处理。
布隆过滤器索引的创建和传统数据库索引的创建类似,但需要指定假阳性概率和该列可能出现的值的数量:
CREATE BLOOMFILTER INDEX ON TABLE table_name
FOR COLUMNS(col_name OPTIONS (fpp=0.1, numItems=50000000))
根据我们在Databricks DataInsight上的试验,使用布隆过滤器索引能达到3倍以上的性能提升,试验案例参考文末Databricks数据洞察的官方文档。
特性4:动态文件剪枝
动态文件剪枝(Dynamic File Pruning, DFP)和动态分区剪枝(Dynamic Partition Pruning)相似,都是在维表和事实表的Join执行阶段进行剪枝,减少扫描的数据量,提升查询效率。
下面我们以一个简单的查询为例来介绍DFP的原理:
SELECT sum(ss_quantity) FROM store_sales
JOIN item ON ss_item_sk = i_item_sk
WHERE i_item_id = 'AAAAAAAAICAAAAAA'
在该查询中,item为维表(数据量很少),store_sales为事实表(数据量非常大),where查询条件作用于维表上。如果不开启DFP,那么该查询的逻辑执行计划如下:
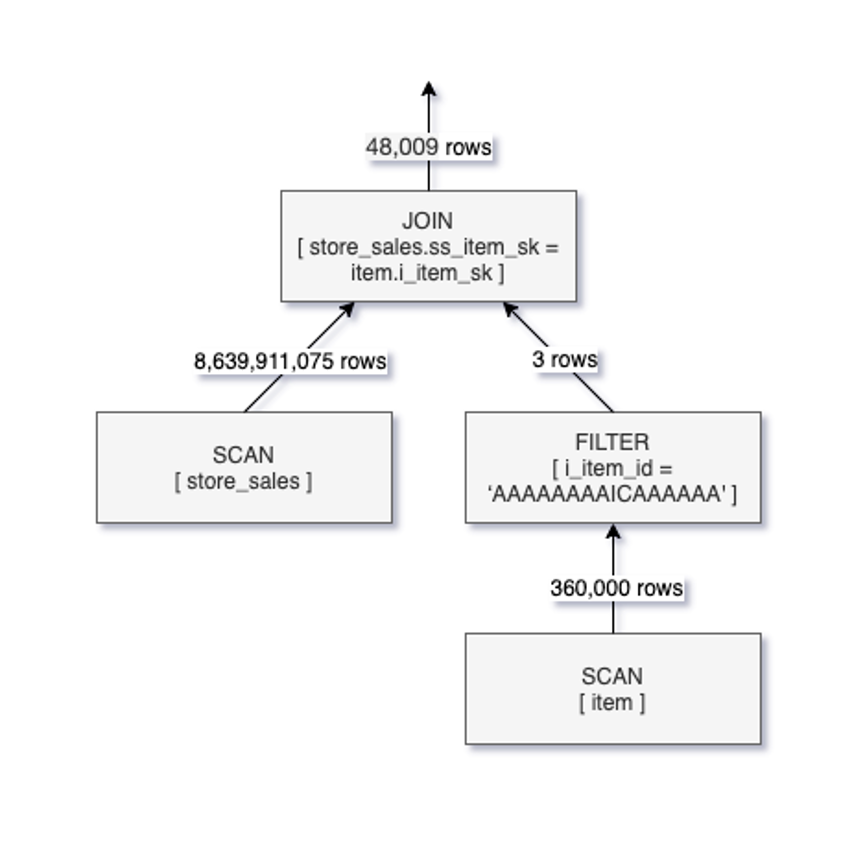
从上图可以看出,先对store_sales进行全表扫描,然后再和过滤后的item表的行进行join,虽然结果仅有4万多条数据,但却扫描了表store_sales中的80多亿条数据。针对该查询,很直观的优化是:先查询出表item中i_item_id = 'AAAAAAAAICAAAAAA'数据行,然后将这些数据行的i_item_sk值作为表store_sales的ss_item_sk的查询条件在表store_sales的SCAN阶段进行过滤,结合我们在上面介绍的Data Skipping技术,可以大幅减少表文件的扫描。这一思路正是DFP的根本原理,启动DFP后的逻辑执行计划如下图所示:

可以看到,在启用DFP之后,过滤条件被下推到SCAN操作中,仅扫描了600多万条store_sales中的数据,从结果上看,启动DFP后,该条查询实现了10倍的性能提升,此外,Databricks还针对该特性对TPC-DS测试,测试发现启用DFP后,TPC-DS的第15条查询达到了8倍的性能提升,有36条查询实现了2倍及以上的性能提升。
总结
前文概括介绍了Databricks企业版Delta Lake的性能优势,借助这些特性能够大幅提升Spark SQL的查询性能,加快Delta表的查询速度。
本文为阿里云原创内容,未经允许不得转载。
Databricks 企业版 Spark&Delta Lake 引擎助力 Lakehouse 高效访问的更多相关文章
- Apache Hudi vs Delta Lake:透明TPC-DS Lakehouse性能基准
1. 介绍 最近几周,人们对比较 Hudi.Delta 和 Iceberg 的表现越来越感兴趣. 我们认为社区应该得到更透明和可重复的分析. 我们想就如何执行和呈现这些基准.它们带来什么价值以及我们应 ...
- Delta Lake源码分析
目录 Delta Lake源码分析 Delta Lake元数据 snapshot生成 日志提交 冲突检测(并发控制) delete update merge Delta Lake源码分析 Delta ...
- Delta Lake基础操作和原理
目录 Delta Lake 特性 maven依赖 使用aws s3文件系统快速启动 基础表操作 merge操作 delta lake更改现有数据的具体过程 delta表schema 事务日志 delt ...
- 基于Azure构建PredictionIO和Spark的推荐引擎服务
基于Azure构建PredictionIO和Spark的推荐引擎服务 1. 在Azure构建Ubuntu 16.04虚拟机 假设前提条件您已有 Azure 帐号,登陆 Azure https://po ...
- Azure构建PredictionIO和Spark的推荐引擎服务
Azure构建PredictionIO和Spark的推荐引擎服务 1. 在Azure构建Ubuntu 16.04虚拟机 假设前提条件您已有 Azure 帐号,登陆 Azure https://port ...
- spark on yarn模式下配置spark-sql访问hive元数据
spark on yarn模式下配置spark-sql访问hive元数据 目的:在spark on yarn模式下,执行spark-sql访问hive的元数据.并对比一下spark-sql 和hive ...
- (十五)整合 Drools规则引擎,实现高效的业务规则
整合 Drools规则引擎,实现高效的业务规则 1.Drools引擎简介 1.1 规则语法 2.SpringBoot整合Drools 2.1 项目结构 2.2 核心依赖 2.3 配置文件 3.演示案例 ...
- 华为视频编辑服务(Video Editor Kit),助力开发者高效构建应用视频编辑能力
视频编辑服务(Video Editor Kit)是华为开放给开发者快速构建视频编辑能力的服务,提供视频导入.编辑处理.特效渲染.视频导出.媒体资源管理等一站式视频处理能力.视频编辑服务为全球开发者提供 ...
- 详细解读Spark的数据分析引擎:Spark SQL
一.spark SQL:类似于Hive,是一种数据分析引擎 什么是spark SQL? spark SQL只能处理结构化数据 底层依赖RDD,把sql语句转换成一个个RDD,运行在不同的worker上 ...
- Spark 分布式SQL引擎
SparkSQL作为分布式查询引擎:两种方式 SparkSQL作为分布式查询引擎:Thrift JDBC/ODBC服务 SparkSQL作为分布式查询引擎:Thrift JDBC/ODBC服务 Spa ...
随机推荐
- 阿里云配置http转https
参考:https://www.cnblogs.com/alexfly/p/10615986.htmlhttps://www.cnblogs.com/SemiconductorKING/p/910697 ...
- eclipse错误之Could not write metadata for "xxx"
Could not write metadata for '/test'. 这是由于删除一个项目时,没有同时在硬盘上删除该项目,而后又到硬盘文件系统中删除了该项目,才出现这问题的. 到eclipse工 ...
- 什么是XR扩展现实,XR云串流平台有哪些
什么是云XR (AR/VR/MR/SR) 虚拟现实(VR),传统的实现方式是通过计算机模拟虚拟环境,从而给人一种环境沉浸感.与传统视频相比,VR带来了前所未有的沉浸式体验. 增强现实(AR)是一种无缝 ...
- 在LabVIEW中编程运行可执行程序
以下文字来自于 https://knowledge.ni.com/KnowledgeArticleDetails?id=kA03q000000YGhVCAW&l=en-US 翻译来自于Chat ...
- StableSwarmUI:功能强大且易于使用的Stable Diffusion WebUI
StableSwarmUI是一个模块化和可定制的Stable Diffusion WebUI,最近发布了0.6.1-Beta版本.这个开源项目,托管在GitHub上:https://github.co ...
- 自动化瓦力多渠道打包python脚本
自动化瓦力多渠道打包python脚本 目录介绍 1.本库优势亮点 2.使用介绍 3.注意要点 4.效果展示 5.其他介绍 0.首先看看我录制的案例演示 如下所示,这段python代码很简单,工具十分强 ...
- Java 8 内存管理原理解析及内存故障排查实践
作者:vivo 互联网服务器团队- Zeng Zhibin 介绍Java8虚拟机的内存区域划分.内存垃圾回收工作原理解析.虚拟机内存分配配置,介绍各垃圾收集器优缺点及场景应用.实践内存故障场景排查诊 ...
- 记录--vue3问题:如何实现微信扫码授权登录?
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 一.需求 微信扫码授权,如果允许授权,则登录成功,跳转到首页. 二.问题 1.微信扫码授权有几种实现方式? 2.说一下这几种实现方式的原理 ...
- MySQL8.0 ERROR 1045 (28000)
第一步:关闭服务 net stop mysql 这个需要在管理员权限才行 ,具体怎么用管理员打开cmd略过 第二步:进入到安装的bin目录 执行 :mysqld --console --skip-gr ...
- es通过时间聚合查询一周中每天的数据平均值
场景回顾:设备上传的数据保存在es中,大屏模块要统计本周的数据折线图(一个设备三分总上传一次,所以拟定每天聚合求个平均值) kibana查询请求 GET xxxx_2022-10/_search { ...