Hologres揭秘:如何支持超高QPS在线服务(点查)场景
Hologres(中文名交互式分析)是阿里云自研的一站式实时数仓,这个云原生系统融合了实时服务和分析大数据的场景,全面兼容PostgreSQL协议并与大数据生态无缝打通,能用同一套数据架构同时支持实时写入实时查询以及实时离线联邦分析。它的出现简化了业务的架构,为业务提供实时决策的能力,让大数据发挥出更大的商业价值。从阿里集团诞生到云上商业化,随着业务的发展和技术的演进,Hologres也在持续不断优化核心技术竞争力,为了让大家更加了解Hologres,我们计划持续推出Hologres底层技术原理揭秘系列,从高性能存储引擎到高效率查询引擎,高吞吐写入到高QPS查询等,全方位解读Hologres,请大家持续关注!
往期精彩内容:
- 2020年VLDB的论文《Alibaba Hologres: A cloud-Native Service for Hybrid Serving/Analytical Processing》
- Hologres揭秘:首次公开!阿里巴巴云原生实时数仓核心技术揭秘
- Hologres揭秘:首次揭秘云原生Hologres存储引擎
- Hologres揭秘:Hologres高效率分布式查询引擎
- Hologres揭秘:高性能原生加速MaxCompute核心原理
- Hologres揭秘:优化COPY,批量导入性能提升5倍+
本期我们将揭秘Hologres如何支持超高QPS点查。
传统的 OLAP 系统在业务中往往扮演着比较静态的角色,以通过分析海量的数据得到业务的洞察(比如说预计算好的视图、模型等),从这些海量数据分析到的结果再通过另外一个系统提供在线数据服务(比如HBase、Redis、MySQL等)。这里的服务(Serving)和分析(Analytical)是个割裂的过程。与此不同的是,实际的业务决策过程往往是一个持续优化的在线过程。服务的过程会产生大量的新数据,我们需要对这些新数据进行复杂的分析。分析产生的洞察实时反馈到服务,让业务的决策更实时,从而创造更大的商业价值。
Hologres定位是一站式实时数仓,融合分析能力(Analytical)与在线服务(Serving)为一体,减少数据的割裂和移动。本文的内容将会针对Hologres的服务能力(核心为点查能力),介绍Hologres到底具备哪些服务能力,以及背后的实现原理。
通常我们所说的点查场景是指Key/Value查询的场景,广泛用于在线服务。由于点查场景的广泛需求,市场上存在多种KV数据库定位于支持高吞吐、低延时的点查场景,例如被大家广而熟知的HBase,它通过自定义的一套API来提供点查的能力,在许多业务场景都能够获得较好的效果。但是HBase在实际使用中也会存在一定的缺点,这也使得很多业务从HBase迁移至Hologres,主要有以下几点:
- 当数据规模大到一定程度的时候,HBase在性能方面将会有所下降,无法满足大规模的点查计算,同时在稳定性上也变得不如人意,需要有经验的运维支持
- HBase提供的是自定义API,上手有一定的成本。Hologres直接通过SQL提供高吞吐、低延时的点查服务。相比于其它KV系统提供自定义API,SQL接口无疑更加的简单易用。
- HBase采用Schema Free设计,没有数据类型,对于检查数据质量,修正数据质量也带来了复杂度,查错难,修正难。Hologres具备与Postgres兼容的几乎所有主流数据类型,可以通过Insert/Select/Update/Delete标准SQL语句对数据进行查看、更新。
- 在Hologres中的点查场景是指行存表基于主键(PK)的查询。
--建行存表
BEGIN;
CREATE TABLE public.holotest (
"a" text NOT NULL,
"b" text NOT NULL,
"c" text NOT NULL,
"d" text NOT NULL,
"e" text NOT NULL,
PRIMARY KEY (a,b)
);
CALL SET_TABLE_PROPERTY('public.holotest', 'orientation', 'row');
CALL SET_TABLE_PROPERTY('public.holotest', 'time_to_live_in_seconds', '3153600000');
COMMIT; -- Hologres通过SQL进行点查
select * from table where pk = ?; -- 一次查询单个点
select * from table where pk in (?, ?, ?, ?, ?); -- 一次查询多个点
点查场景技术实现难点
正常情况下,一条SQL语句的执行,需要经过SQL Parser进行解析成AST(抽象语法树),再由Query Optimizer处理生成Plan(可执行计划),最终通过执行Plan拿到计算结果。而要想通过SQL做到高吞吐、低延时、稳定的点查服务,则必须要克服如下困难:
- 在不破坏PostgreSQL生态的情况下,SQL接口如何做到高QPS?
- 如何做低甚至避免SQL解析与优化器的开销
- 一套高效的Client SDK如何与后端存储进行交互?
- 如何在低消耗的情况下,做到高并发的交互
- 如何减少消息传递过程中的开销
- 如何感知后端的压力、配合做到最好的吞吐与延迟
- 后端存储如何在高性能的情况下更加稳定?
- 如何最大化利用cpu资源
- 如何减少各种内存的分配与拷贝、避免热点key等问题对系统带来的不稳定性
- 如何减少冷数据IO的影响
在克服上述3大类困难后,整体的工作方式就可以非常的简洁:在接入层(FrontEnd)上直接通过Client SDK与后端存储通信。
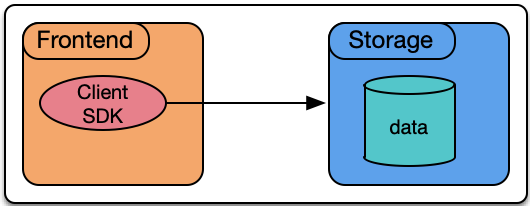
下面将会介绍Hologres是如何克服以上3大困难,从而实现高吞吐低延时的点查。
降低、避免SQL解析与优化器的开销
Query Optimizer进行Short Cut
由于点查的Query足够简单,Hologres的Query Optimizer进行了相应的short cut,点查Query并不会进入Opimizer的完整流程。Query进入FrontEnd后它会交由Fixed Planner进行处理,并由其生成对于的Fixed Plan(点查的物理Plan),Fixed Planner非常轻,无需经过任何的等价变换、逻辑优化、物理优化等步骤,仅仅是基于AST树进行了一些简单的分析并构建出对应的Fixed Plan,从而尽量规避掉优化器的开销。
Prepared Statement
尽管Query Optimizer对点查Query进行了short cut,但是Query进入到FrontEnd后的解析开销依然存在、Query Optimizer的开销也没有完全避免。
Hologres兼容Postgres,Postgres的前、后端通信协议有extended协议与simple协议两种:
- simple协议:是一次性交互的协议,Client每次会直接发送待执行的SQL给Server,Server收到SQL后直接进行解析、执行,并将结果返回给Client。simple协议里Server无可避免的至少需要对收到的SQL进行解析才能理解其语义。
- extended协议:Client与Server的交互分多阶段完成,整体大致可以分成两大阶段。
- 第一阶段:Client在Server端定义了一个带名字的Statement,并且生成了该Statement所对应的generic plan(不与特定的参数绑定的通用plan)。
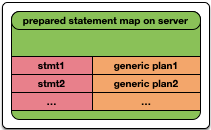
- 第二阶段:用户通过发送具体的参数来执行第一阶段中定义的Statement。第二阶段可以重复执行多次,每次通过带上第一阶段中所定义的Statement名字,以及执行所需要的参数,使用第一阶段生成的generic plan进行执行。由于第二阶段可以通过Statement名字和附带的参数来反复执行第一个阶段所准备好的generic plan,因此第二个段在Frontend的开销几乎等同于0。
为此Hologres基于Postgres的extended协议,支持了Prepared Statement,做到了点查Query在Frontend上的开销接近于0。
高性能的内部通信
BHClient是Hologres实现的一套用于与后端存储直接通信的高效Private Client SDK,主要有以下几个优势:
1)Reactor模型、全程无锁的异步操作
BHClient工作方式类似reactor模型,每个目标shard对应一个eventloop,以“死循环”的方式处理该shard上的请求。由于HOS对调度执行单元的抽象,即使是shard很多的情况下,这种工作方式的基础消耗也足够低。
2)高效的数据交换协议binary row
通过自定义一套内部的数据通信协议binary row来减少整个交互链路上的内存的分配与拷贝。
3)反压与凑批
BHClient可以感知后端的压力,进行自适应的反压与凑批,在不影响原有Latency的情况下提升系统吞吐。
稳定可靠的后端存储
1)LSM(Log Structured Merge Tree)
Hologres的行存表采取LSM进行存储,相比于传统的B+树,LSM能够提供更高的写吞吐,因为它不会出现任何的随机写,Append Only的操作保证了其只会顺序的写盘。
- 一个行存tablet上会存在一个memtable,和多个immutable memtable。
- 数据更新都会写入到memtable中,当memtable写满后会转变为immtable memtable,immutable memtable会Flush成Key有序的SST(Sorted String Table)文件,SST文件一旦生成则不能修改,因此不会发生随机写的操作。
- SST文件在文件系统里面按层组织,除了level 0上的SST文件间无序,且存在overlap外,其它level上的SST文件间有序,且无overlap。因此查询的时候,对于level 0上的文件需要逐个遍历,而其它level的文件可以二分查找。底层的SST文件通过Compaction成新的SST文件去到更高层,因此低层的数据要比高层的新,所以一旦在某层上找到了满足条件的key则无需往更高层去查询。
2)基于C++纯异步的开发
采用LSM对数据进行组织存储的系统并不仅仅只有Hologres,LSM在谷歌的"BigTable"论文中被提出后,很多的系统都对其进行了借鉴采用,例如HBase。Hologres采用C++进行开发,相较于Java,native语言使得我们能够追求到更极致的性能。同时基于HOS(Hologres Operation System)提供的异步接口进行纯异步开发,HOS通过抽象ExecutionContext来自我管理CPU的调度执行,能够最大化的利用硬件资源、达到吞吐最大化。
3)IO优化与丰富的Cache机制
Hologres实现了非常丰富的Cache机制row cache、block cache、iterator cache、meta cache等,来加速热数据的查找、减少IO访问、避免新内存分配。当无可避免的需要发生IO时,Hologres会对并发IO进行合并、通过wait/notice机制确保只访问一次IO,减少IO处理量。通过生成文件级别的词典及压缩,减少文件物理存储成本及IO访问。
总结
Hologres致力于一站式实时数仓,除了具备处理复杂OLAP分析场景的能力之外,还支持超高QPS在线点查服务,通过使用标准的Postgres SDK接口,就能通过SQL获得低延时、高吞吐的在线服务能力,简化学习成本,提升开发效率。
作者:周思华(花名:思召),阿里巴巴技术专家,现从事交互式分析引擎Hologres研发工作。
本文为阿里云原创内容,未经允许不得转载。
Hologres揭秘:如何支持超高QPS在线服务(点查)场景的更多相关文章
- 基于Java的支持可变QPS的http负载生成器,提供交互界面和RMI接口
Load generator The load generator is a Java maven project which is implemented using httpclient+thre ...
- UVa 11987 Almost Union-Find(支持删除操作的并查集)
传送门 Description I hope you know the beautiful Union-Find structure. In this problem, you’re to imple ...
- MongoDB + Spark: 完整的大数据解决方案
Spark介绍 按照官方的定义,Spark 是一个通用,快速,适用于大规模数据的处理引擎. 通用性:我们可以使用Spark SQL来执行常规分析, Spark Streaming 来流数据处理, 以及 ...
- MongoDB + Spark结合使用方案
MongoDB上海的活动已经结束快1个月了,我们再来回顾一下TJ在大会上进行的精彩分享吧~ MongoDB + Spark: 完整的大数据计算解决方案. Spark介绍 按照官方的定义,Spark 是 ...
- 阿里云云盾抗下全球最大DDoS攻击(5亿次请求,95万QPS HTTPS CC攻击) ,阿里百万级QPS资源调度系统,一般的服务器qps多少? QPS/TPS/并发量/系统吞吐量
阿里云云盾抗下全球最大DDoS攻击(5亿次请求,95万QPS HTTPS CC攻击) 作者:用户 来源:互联网 时间:2016-03-30 13:32:40 安全流量事件https互联网资源 摘要: ...
- Nginx 单机百万QPS环境搭建
一.背景 最近公司在做一些物联网产品,物物通信用的是MQTT协议,内部权限与内部关系等业务逻辑准备用HTTP实现.leader要求在本地测试中要模拟出百万用户同时在线的需求.虽然该产品最后不一定有这么 ...
- 迎难而上,QPS提高22+倍
简介 记录1次性能提升的经历,它最大的挑战不在于性能提升,而在于时间急,涉及的面广(比如:机房F5的SSL/TLS性能,机房互联网流量费和项目投入产出比等).性能指标:至少支持10K QPS,10ms ...
- Django 1.9 支持中文(转)
昨天Django1.9发布了,今天我才刚开始学习Django,然后有一个问题就卡住了——如何支持中文?上网上查了好多资料都不好使,最后我搜索Django文件夹才发现,在1.9版本里,简体中文代码是zh ...
- iOS应用支持IPV6,就那点事儿
原文连接 果然是苹果打个哈欠,iOS行业内就得起一次风暴呀.自从5月初Apple明文规定所有开发者在6月1号以后提交新版本需要支持IPV6-Only的网络,大家便开始热火朝天的研究如何支持IPV6 ...
- iOS应用支持IPV6
一.IPV6-Only支持是啥? 首先IPV6,是对IPV4地址空间的扩充.目前当我们用iOS设备连接上Wifi.4G.3G等网络时,设备被分配的地址均是IPV4地址,但是随着运营商和企业逐渐部署IP ...
随机推荐
- 项目性能优化—使用JMeter压测SpringBoot项目
项目性能优化-使用JMeter压测SpringBoot项目 我们的压力测试架构图如下: 配置JMeter 在JMeter的bin目录,双击jmeter.bat 新建一个测试计划,并右键添加线程组: 进 ...
- 工作记录:8个有用的JS技巧
这里给大家分享我最近学习到的8个有用的js小技巧,废话不多说,我们上代码 1. 确保数组值 使用 grid ,需要重新创建原始数据,并且每行的列长度可能不匹配, 为了确保不匹配行之间的长度相等,可以使 ...
- 记录--前端实现电子签名(web、移动端)通用
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 前言 在现在的时代发展中,从以前的手写签名,逐渐衍生出了电子签名.电子签名和纸质手写签名一样具有法律效应.电子签名目前主要还是在需要个人确 ...
- Markdown的习题
markdown的使用说明 习题1: 将这段话改为2级标题 习题2 试着在你的'Typora'中编辑下面的内容: 这是第一行 这是第2行 这是补充内容 这是第3行 习题3 将下面的内容改为指定的格式要 ...
- .net 开源混淆器 ConfuserEx
官网:http://yck1509.github.io/ConfuserEx/ 下载地址:https://github.com/yck1509/ConfuserEx/releases 使用参考:htt ...
- GFLV2:边界框不确定性的进一步融合,提点神器 | CVPR 2021
GFLV2基于GFLV1的bbox分布进行改进,将分布的统计信息融入到定位质量估计中,整体思想十分创新和完备,从实验结果来看,效果还是挺不错的 来源:晓飞的算法工程笔记 公众号 论文: Gener ...
- S锁,X锁,乐观锁和悲观锁
S锁:S锁也叫共享锁,读锁,数据只能被读取不能被修改. X锁:X锁也叫排他锁,写锁,一个事务对表加锁后,其他事务就不能对其进行加锁与增删查改操作. 乐观锁:总是假设是最好的情况,每次去操作的时候都不会 ...
- #KD-Tree,替罪羊树#洛谷 6224 [BJWC2014]数据
题目 平面上有 \(N\) 个点.需要实现以下三种操作: 在点集里添加一个点: 给出一个点,查询它到点集里所有点的曼哈顿距离的最小值: 给出一个点,查询它到点集里所有点的曼哈顿距离的最大值. 分析 用 ...
- 80+产品正通过兼容性测试,OpenHarmony生态蓬勃发展
4 月 25 日,开放原子开源基金会举办了 OpenAtom OpenHarmony(以下简称"OpenHarmony")技术日活动,OpenHarmony PMC 委员代表首次对 ...
- OpenHarmony轻量系统中内核资源主要管理方式
一.背景 OpenAtom OpenHarmony(以下简称"OpenHarmony")轻量系统面向MCU类处理器例如ARM Cortex-M.RISC-V 32位的设备,硬件资源 ...