Prometheus 快速入门
Prometheus&Grafana快速入门
一、prometheus简介
prometheus是监控多个大数据组件的监控系统。Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB)。Prometheus使用Go语言开发,是Google BorgMon监控系统的开源版本。
2016年由Google发起Linux基金会旗下的原生云基金会(Cloud Native Computing Foundation), 将Prometheus纳入其下第二大开源项目。
Prometheus性能也足够支撑上万台规模的集群。
官网:https://prometheus.io/
- 监控分类
google指出,监控分为白盒监控和黑盒监控之分。
白盒监控:通过监控内部的运行状态及指标判断可能会发生的问题,从而做出预判或对其进 行优化。
黑盒监控:监控系统或服务,在发生异常时做出相应措施。
监控目的是:根据历史监控数据,对为了做出预测。发生异常时,即使报警,或做出相应措施。根据监控报警及时定位问题根源。通过可视化表展示,便于直观获取信息。
二、时序数据库
时序数据库全称为时间序列数据库。时间序列数据库指主要用于处理带时间标签的数据,带时间标签的数据也称为时间序列数据。
时序数据是基于时间的一系列的数据。在有时间的坐标中将这些数据点连成线,往过去看可以做成多纬度报表,揭示其趋势性、规律性、异常性;往未来看可以做大数据分析,机器学习,实现预测 和预警等功能。
对比传统数据库仅仅记录了数据的当前值,时序数据库则记录了所有的历史数据。同时时序数据的 查询也总是会带上时间作为过滤条件。
特点:1、多是写入操作。2、写入操作几乎是时间顺序添加。3、写操作很少写入之前的数据,很少更新数据。4、删除数据一般是区块删除。5、基本数据量大,超过内存大小。6、读操作是典型的升序或降序读。7、高并发读操作十分常见。
应用场景:时间序列数据主要由电力行业、化工行业、气象行业、地理信息等各类型实时监测、检查与分析设 备所采集、产生的数据,这些工业数据的典型特点是:产生频率快(每一个监测点一秒钟内可产生 多条数据)、严重依赖于采集时间(每一条数据均要求对应唯一的时间)、测点多信息量大(常规 的实时监测系统均有成千上万的监测点,监测点每秒钟都产生数据,每天产生几十GB的数据 量)。
- 举例说明
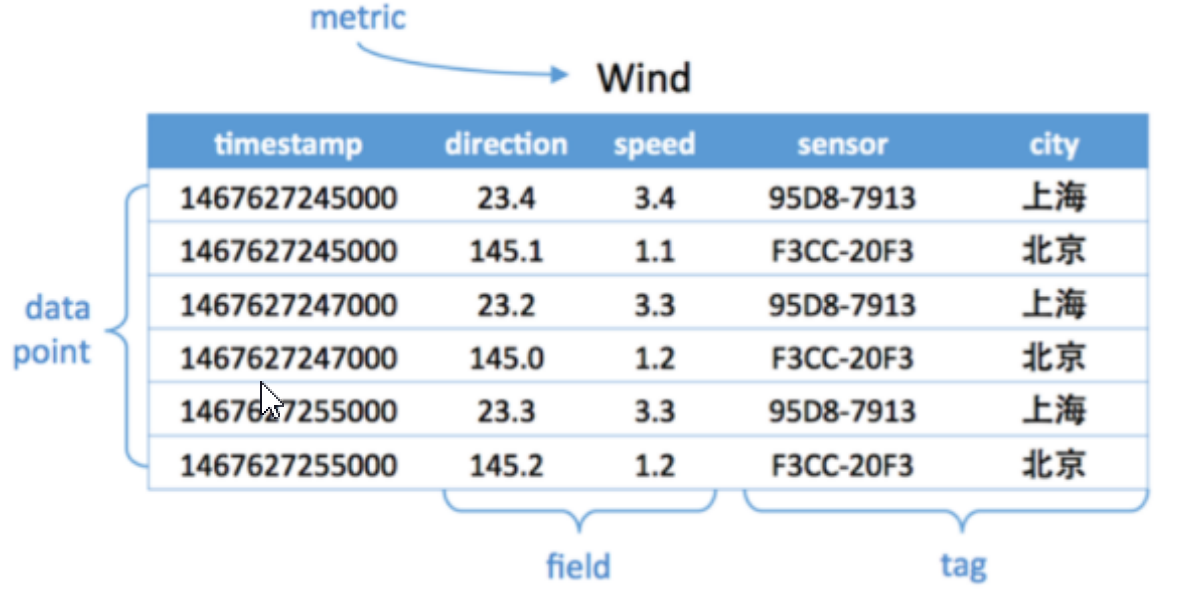
如图度量是Wind,每一个数据点都具有一个timestamp,两个field:direction和speed,两个tag:sensor、city。
它的第一行和第三行,存放都是sensor号码为95D8-7913的设备,属性城市是上海。
随着时间变化,风向和风速都发生了变化,风向从23.4变成23.2,风速从3.4变成了3.3。
三、软件架构
核心服务:prometheus server它本身就是一款时序数据库,它的数据都存储在磁盘上,它要去拉取数据,基于服务发现找到目标服务器,然后将数据拉取到TSDB,它既然是数据库就要支持数据的查询,PromQL就是查询语言。
读取数据:长声明周期每个任务专门有一个xxxExporter,作用就是收集指标,这个Exporter接口是每个软件自己开发的,根据自己的需要也可以自定义自己的Exporter。短生命周期的任务存活时间不可控,需要任务将自己重要的指标发送给pushGateway。
告警系统:当prometheus的数据达到阈值,就会进行告警,将告警信息推送给alterManager告警系统会发送邮件等信息给管理者。
信息查询:监控监控每隔一段时间使用PromQL查询TSDB,就可以获取最新的任务的执行状况,最终将信息呈现给WebUI或者Grafana。
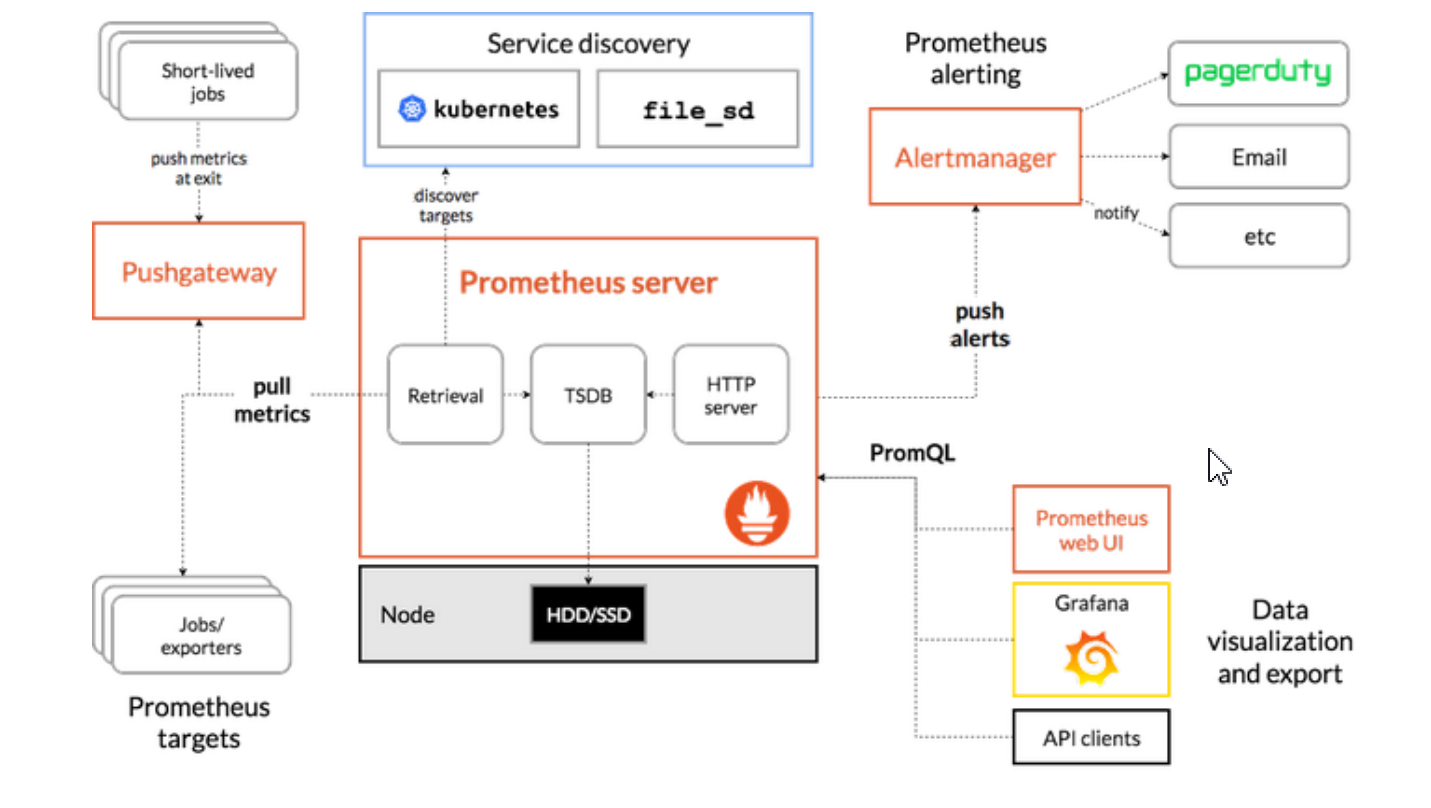
四、生态圈组件
Prometheus Server 是 Prometheus 组件中的核心部分,负责实现对监控数据的获取,存储以 及查询。
Client Library:客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
Push Gateway:主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失 了。为此,这次 jobs 可以直接向 Prometheusserver 端推送它们的 metrics。这种方式主要用于 服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。
Exporters:用于暴露已有的第三方服务的 metrics 给 Prometheus。
主要用来采集数据,并通过 HTTP 服务的形式暴露给 Prometheus Server,Prometheus Server 通过访问该 Exporter 提供的接口,即可获取到需要采集的监控数据。常见的Exporter有很 多,例node_exporter、mysqld_exporter、haproxy_exporter 等,支持如 HAProxy、StatsD、 Graphite、Redis 此类的服务监控;
Alertmanager:从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受 方式,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等。
五、数据存储

promethus提供两种存储方式:本地存储和远端存储。
本地存储:一种是本地存储,通过Prometheus自带的TSDB(时序数 据库),将数据保存到本地磁盘,为了性能考虑,建议使用SSD。但本地存储的容量毕竟有限,建 议不要保存超过一个月的数据。Prometheus本地存储经过多年改进,自Prometheus 2.0后提供的V3 版本TSDB性能已经非常高,可以支持单机每秒1000w个指标的收集。
远端存储:适用于大量历史监控数据的存储和查询。通过中间层的适配器的转化, Prometheus将数据保存到远端存储。目前远端存储包括:OpenTSDB、InfluxDB、Elasticsearch、M3DB最受欢迎后端存储是M3DB。
- 数据模型
prometheus采集到的监控数据均以metric(指标)形式保存在时序数据库中(TSDB),属于同一 指标名称,同一标签集合的、有时间戳标记的数据流。
每一条时间序列由 metric 和 labels 组成,每条时间序列按照时间的先后顺序存储它的样本值。
样本由三部分组成=>指标(metric):指标名称和描述当前样本特征的 labelsets;
时间戳(timestamp):一个精确到毫秒的时间戳;
样本值(value): 一个 folat64 的浮点型数据表示当前样本的值。

- 指标格式
格式:<指标名>

- 指标类型
四种核心指标类型:Counter、Gauge、Histogram、Summary
Counter:一种累加的 metric,典型的应用如:请求的个数,结束的任务数, 出现的错误数等等。
Gauge:一种常规的 metric,典型的应用如:温度,运行的 goroutines 的个数。可以任意加减。
Histogram:可以理解为柱状图,典型的应用如:请求持续时间,响应大小。可以对观察结果采样,分组 及统计。
Summary:在客户端直接聚合生成的百分位数,即可以按百分比划分跟踪结果。
六、PromQL
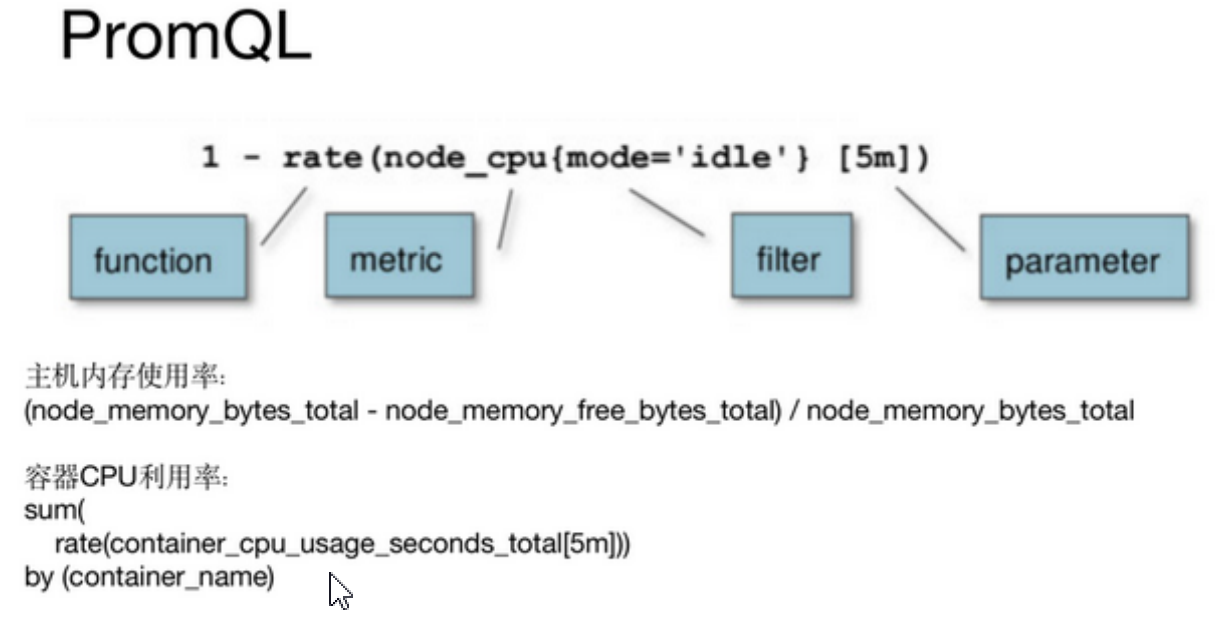
Prometheus数据展现除了自带的WebUI还可以通过Grafana,他们本质上都是通过HTTP + PromQL 的方式查询Prometheus数据。和关系型数据库的SQL类似,Prometheus也内置了数据查询语言 PromQL,它提供对时间序列数据丰富的查询,聚合以及逻辑运算的能力。
七、软件安装
在官网下载好prometheus服务组件。
https://prometheus.io/download/把下载好的软件包上传到root目录下,然后解压到自定义目录中。
tar -zvxf prometheus-2.8.2-linux-arm64.tar.gz - C /usr/local/promethus
- 修改配置文件
vim /usr/local/promethus/prometheus-2.8.2/prometheus.yml
- 配置信息如下(由于是yml文件,配置时主要缩进!)
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.147.110:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "/usr/local/prometheus/prometheus-2.30.3.linux-amd64/rules/*.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["192.168.147.110:9090"]
- job_name: "server_node"
static_configs:
- targets: ['192.168.147.120:9100','192.168.147.130:9100','192.168.147.110:9100']
- 添加环境变量
vim /etc/systemd/system/prometheus.service
- 配置信息
[Unit]
Description=prometheus
Wants=network-online.target
After=network-online.target
[Service]
Type=simple
User=root
ExecStart=/usr/local/prometheus/prometheus-2.30.3.linux-amd64/prometheus \
--config.file=/usr/local/prometheus/prometheus-2.30.3.linux-amd64/prometheus.yml \
--storage.tsdb.path=/usr/local/prometheus/prometheus-2.30.3.linux-amd64/data/ \
--web.enable-lifecycle
[Install]
WantedBy=multi-user.target
- 重新加载服务
systemctl daemon-reload #重新加载服务
systemctl start prometheus #启动服务
systemctl status prometheus #查看服务状态
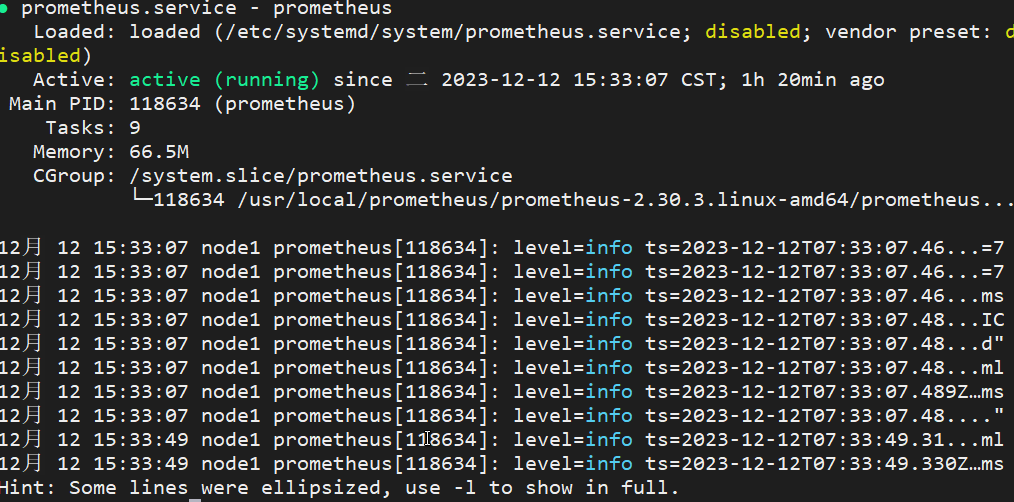
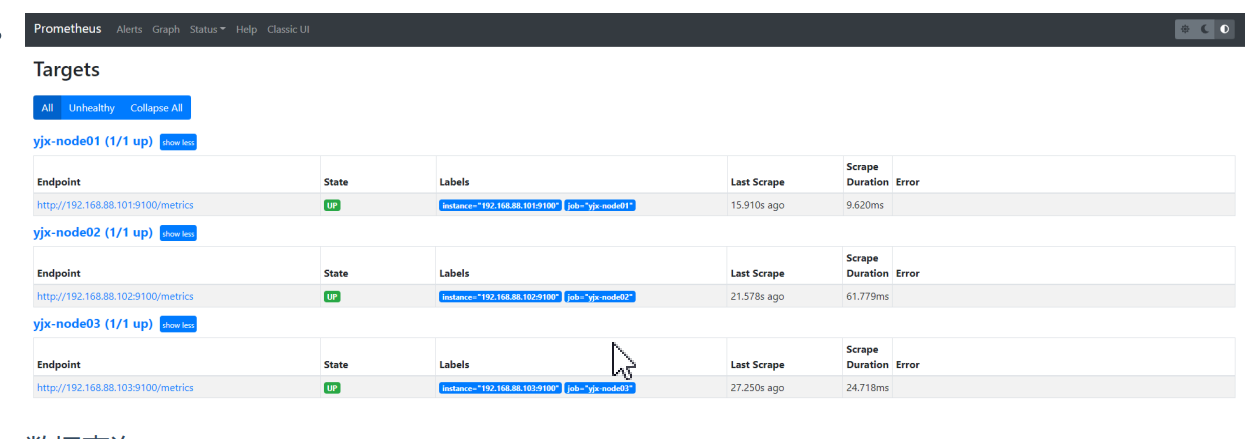
浏览器访问:
http://192.168.147.110:9090/(进入页面就算配置成功!)
- Exporter数据采集工具配置
下载 node_exporter-1.2.2.linux-amd64.tar.gz压缩包,上传到所有需要被监控的服务器节点上!官网下载:(https://prometheus.io/docs/instrumenting/exporters/或者https://github.com/prometheus
- 解压到指定文件目录
tar -zxvf node_exporter-1.2.2.linux-amd64.tar.gz -C /usr/local/node_exporter/
## 分发到其他节点
rsync -av node_exporter-1.2.2.linux-amd64.tar.gz root@node2:/usr/local/node_exporter/
rsync -av node_exporter-1.2.2.linux-amd64.tar.gz root@master:/usr/local/node_exporter/
- 设置开机自启动
[Unit]
Description=node_exporter
After=network.target
[Service]
Type=simple
User=root
ExecStart=/usr/local/node_exporter-1.2.2.linux-amd64/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target
- 加载启动服务
systemctl daemon-reload #重新加载服务
systemctl start node_exporter #启动服务
systemctl status node_exporter #查看服务状态
- 在prometheus上配置数据拉取
vim /usr/local/promethus/prometheus-2.8.2/prometheus.yml
- 配置信息(注意缩进)
- job_name: "server_node"
static_configs:
- targets: ['192.168.147.120:9100','192.168.147.130:9100','192.168.147.110:9100']
- 软件热加载
curl -XPOST http://192.168.147.110:9090/-/reload
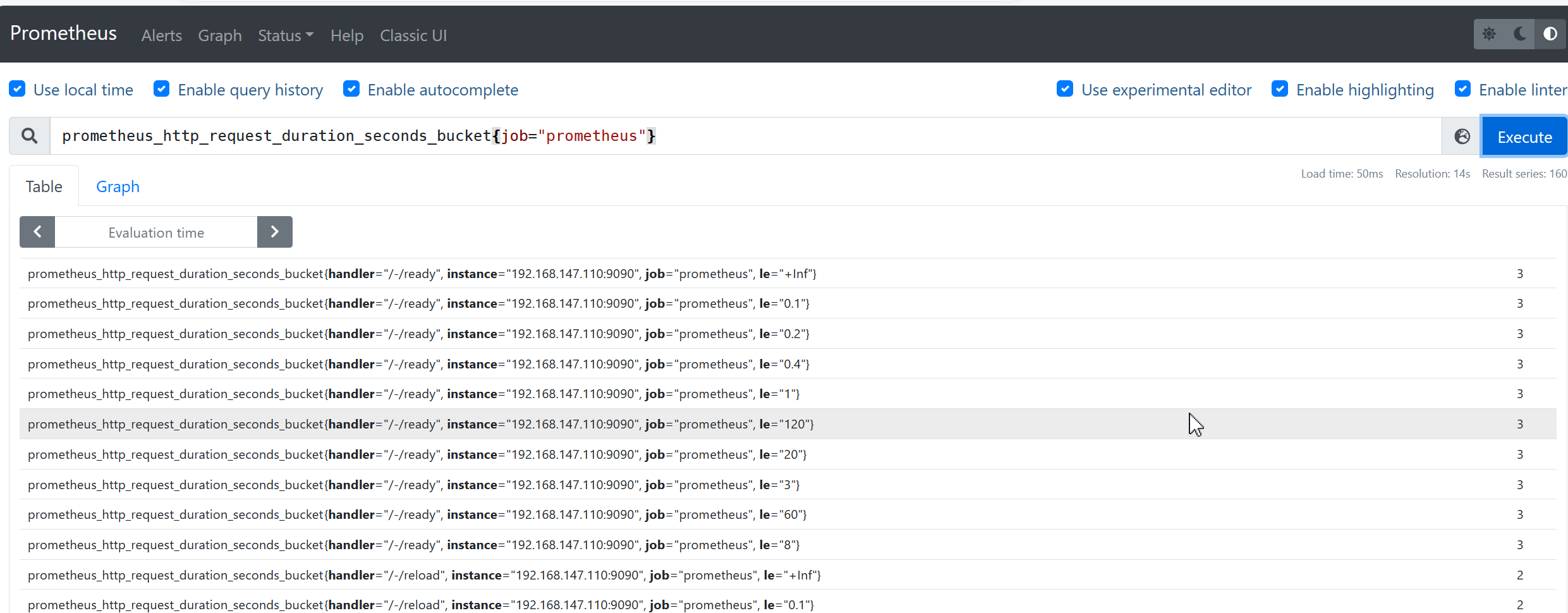
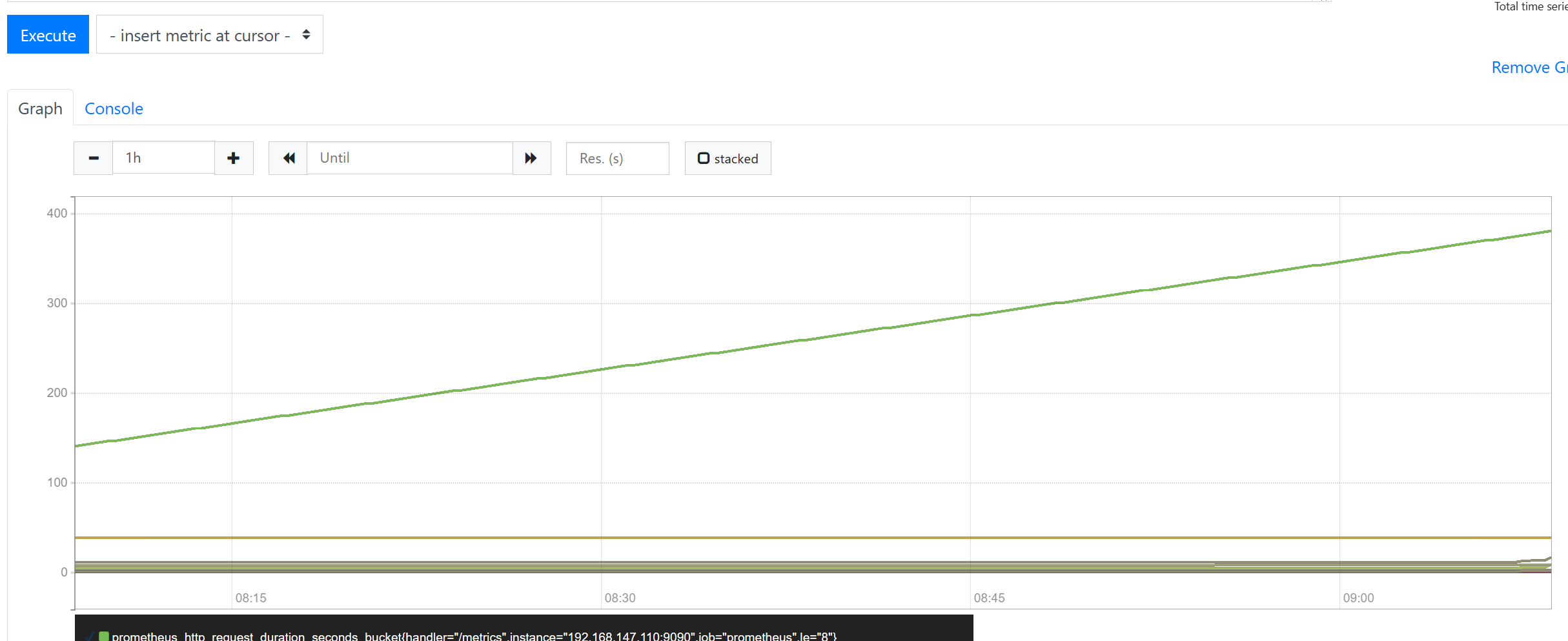
- 在WebUi界面中使用prometheusQL语言查询数据
prometheus_http_request_duration_seconds_bucket{job="prometheus"}
- 配置告警管理组件

Alertmanager是一个独立的告警模块,接收Prometheus等客户端发来的警报,之后通过分组、删除 重复等处理,并将它们通过路由发送给正确的接收器;告警方式可以按照不同的规则发送给不同的 模块负责人,Alertmanager支持Email, Slack,等告警方式, 也可以通过webhook接入钉钉等国内IM 工具。
Prometheus的警报分为两个部分。Prometheus服务器中的警报规则将警报发送到Alertmanager。该 Alertmanager 然后管理这些警报,包括沉默,抑制,聚集和通过的方法,如电子邮件发出通知,对 呼叫通知系统,以及即时通讯平台。
- 软件安装
#在prometheus中开启告警功能
vim /usr/local/promethus/prometheus-2.8.2/prometheus.yml
- 配置文件如下
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.147.110:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "/usr/local/prometheus/prometheus-2.30.3.linux-amd64/rules/*.yml"
- 在prometheus软件根目录下创建rules文件夹
mkdir -p /usr/local/promethus/prometheus-2.8.2/rules

- 以下为内存大小、磁盘大小、cpu使用率大小、node可用性四个配置文件模板(yml文件注意空格缩进)
## 文件名是node_alived.yml
groups:
- name: 实例存活告警规则
rules:
- alert: 实例存活告警
expr: up == 0
for: 1m
labels:
user: prometheus
severity: warning
annotations:
summary: "主机宕机!!"
description: "该实例主机已经宕机超过一分钟了。"
## 文件名是:memory_over.yml
groups:
- name: 内存报警规则
rules:
- alert: 内存使用率告警
expr: (1 - (node_memory_MemAvailable_bytes/(node_memory_MemTotal_bytes)))*100 > 50
for: 1m
labels:
user: prometheus
severity: warning
annotations:
summary: "服务器内存不足!"
description: "服务器内存使用率已经超过百分之50,(当前值:{{$value}}%)"
## 文件名是:cpu_over.yml
groups:
- name: CPU报警规则
rules:
- alert: CPU使用率警告
expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[1m]) )) * 100 > 50
for: 1m
labels:
severity: warning
annotations:
summary: "CPU使用率正在飙升。"
description: "CPU使用率超过50%(当前值{{$value}}%)"
## 文件名是:disk_over.yml
groups:
- name: 磁盘使用率报警规则
rules:
- alert: 磁盘使用率告警
expr: 100 - node_filesystem_free_bytes{fstype=~"xfs|ext4"}/node_filesystem_size_bytes{fstype=~"xfs|ext4"} * 100 > 80
for: 20m
labels:
severity: warning
annotations:
summary: "硬盘分区使用率过高"
description: "分区使用大于80%(当前值:{{ $value }}%)"
把以上四个文件移动到
/usr/local/promethus/prometheus-2.8.2/rules目录下
mv node_alived.yml /usr/local/promethus/prometheus-2.8.2/rules/
mv memory_over.yml /usr/local/promethus/prometheus-2.8.2/rules/
mv cpu_over.yml /usr/local/promethus/prometheus-2.8.2/rules/
mv disk_over.yml /usr/local/promethus/prometheus-2.8.2/rules/
- 重启Prometheus热加载
curl -XPOST http://192.168.147.110:9090/-/reload

- 安装alertmanager
下载alertmanager-0.23.0.linux-amd64.tar.gz上传到服务器,并解压到自定义文件夹中!
tar -zvxf alertmanager-0.23.0.linux-amd64.tar.gz -C /usr/local/altermanager/
- 配置全局配置文件内容
vim /usr/local/alertmanager-0.23.0.linux-amd64/alertmanager.yml
- 配置文件内容
global:
resolve_timeout: 5m #超时,默认5min
smtp_smarthost: 'smtp.qq.com:465' #邮箱smtp服务
smtp_from: '187***@qq.com'
smtp_auth_username: '187***@qq.com'
smtp_auth_password: '自己填写'
smtp_require_tls: false
templates:
- '/usr/local/alertmanager-0.23.0.linux-amd64/template/*.tmpl' # 路径
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'mail'
receivers:
- name: 'mail'
email_configs:
- to: '{{ template "email.to" . }}' #接收警报的email
html: '{{ template "email.to.html" . }}' # 模板
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
- 创建存放模板文件的目录
mkdir -p /usr/local/alertmanager-0.23.0.linux-amd64/template/
- 编辑模板文件内容
vim /usr/local/alertmanager-0.23.0.linux-amd64/template/email.tmpl
- 模板文件内容
{{ define "email.from" }}863****@qq.com{{ end }}
{{ define "email.to" }}54066***@qq.com{{ end }}
{{ define "email.to.html" }}
{{ range .Alerts }}
=========start==========<br>
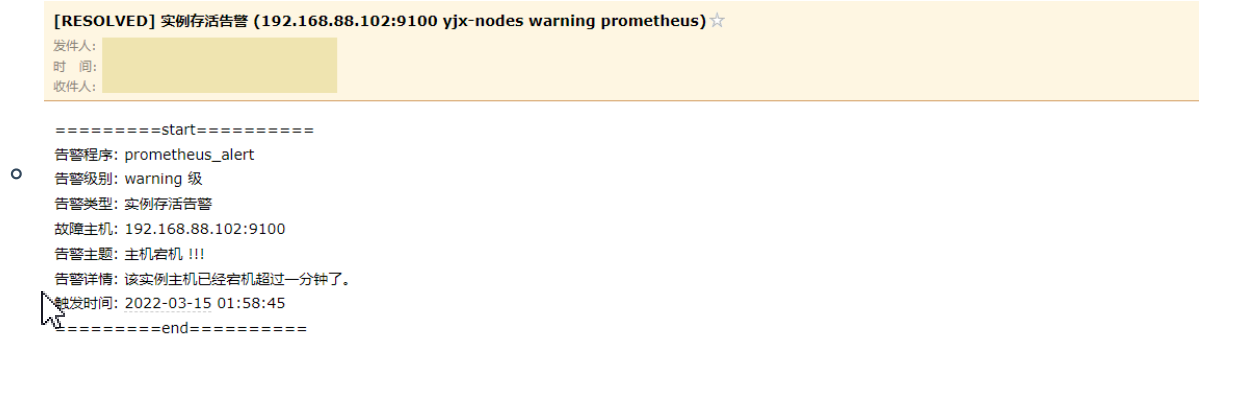
告警程序: yjxxt_prometheus_alert <br>
告警级别: {{ .Labels.severity }} 级 <br>
告警类型: {{ .Labels.alertname }} <br>
故障主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Format "2023-12-12 15:04:05" }} <br>
=========end==========<br>
{{ end }}
{{ end }}
- 添加环境变量
vim /etc/systemd/system/alertmanager.service
[Unit]
Description=alertmanager
Wants=network-online.target
After=network-online.target
[Service]
Type=simple
User=root
ExecStart=/usr/local/alertmanager-0.23.0.linux-amd64/alertmanager \
--config.file /usr/local/alertmanager-0.23.0.linux-amd64/alertmanager.yml \
--storage.path /usr/local/alertmanager-0.23.0.linux-amd64/data/
[Install]
WantedBy=multi-user.target
- 加载和启动环境变量
systemctl daemon-reload #重新加载服务
systemctl start alertmanager #启动服务
systemctl status alertmanager #查看服务状态
- 浏览器访问
http://192.168.147.110:9093
八、Grafana简介
Grafana是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的
展示,并及时通知。它主要有以下六大特点:
1、展示方式:快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方
库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式;
2、数据源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB等;
3、通知提醒:以可视方式定义最重要指标的警报规则,Grafana将不断计算并发送通知,在数据达到阈值时通过Slack、PagerDuty等获得通知;
4、混合展示:在同一图表中混合使用不同的数据源,可以基于每个查询指定数据源,甚至自定义数据源;
5、注释:使用来自不同数据源的丰富事件注释图表,将鼠标悬停在事件上会显示完整的事件元数据和标记;
6、过滤器:Ad-hoc过滤器允许动态创建新的键/值过滤器,这些过滤器会自动应用于使用该
数据源的所有查询。
下载地址:https://grafana.com/grafana/download
九、Grafana软件安装
- 在线安装
wget https://dl.grafana.com/enterprise/release/grafana-enterprise-8.2.1-1.x86_64.rpm
sudo rpm -Uvh grafana-enterprise-8.2.1-1.x86_64.rpm
- 本地安装
先在`https://dl.grafana.com/enterprise/release/grafana-enterprise-8.2.1-1.x86_64.rpm`下载grafana-enterprise-8.2.1-1.x86_64.rpm文件上传到服务器上。
## yum 在线安装
yum install localinstall grafana-enterprise-8.2.1-1.x86_64.rpm
- 访问服务
http://192.168.147.110:3000/
首次登录账户和密码:admin admin
- 添加数据源


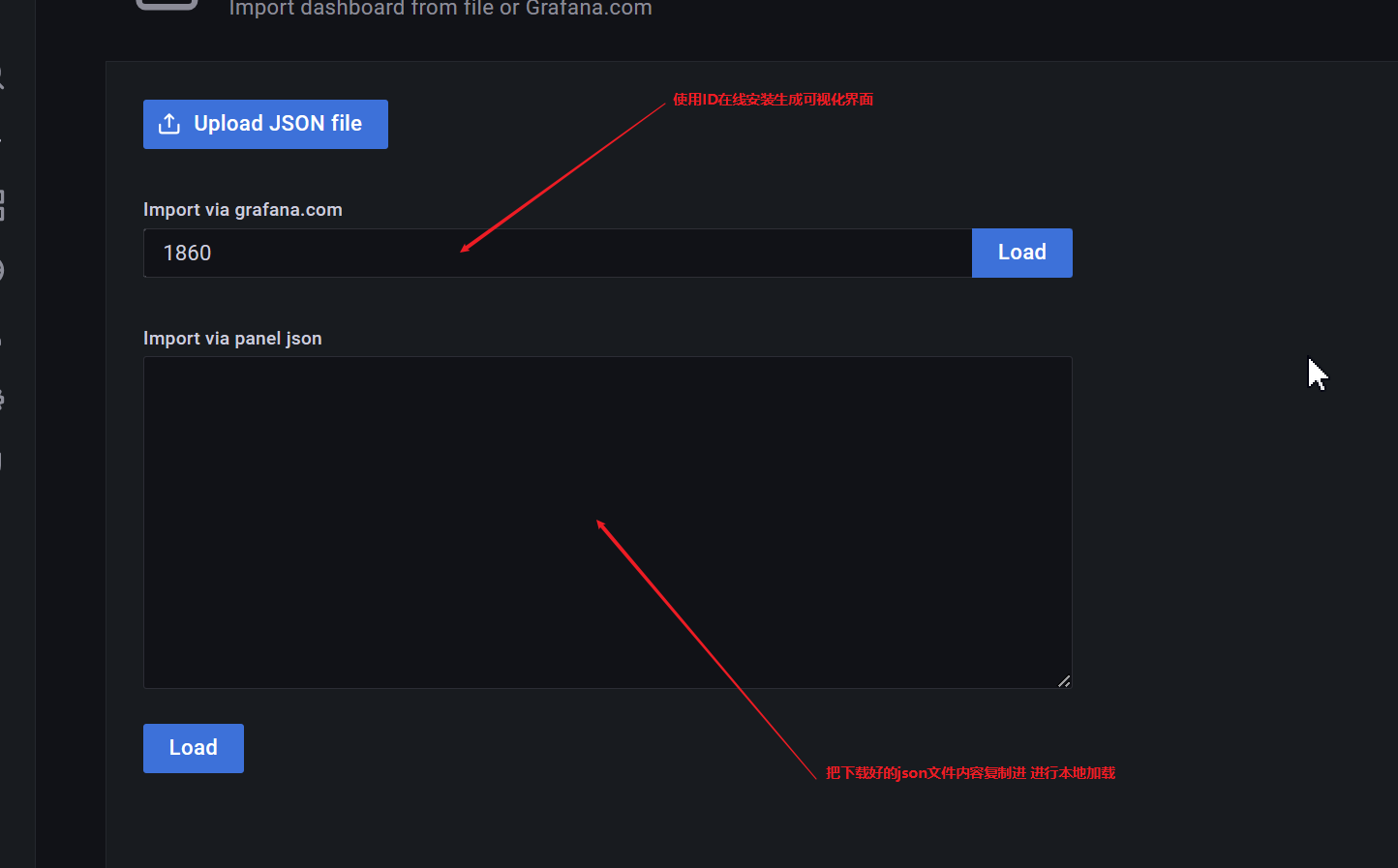
- 加载可视化界面
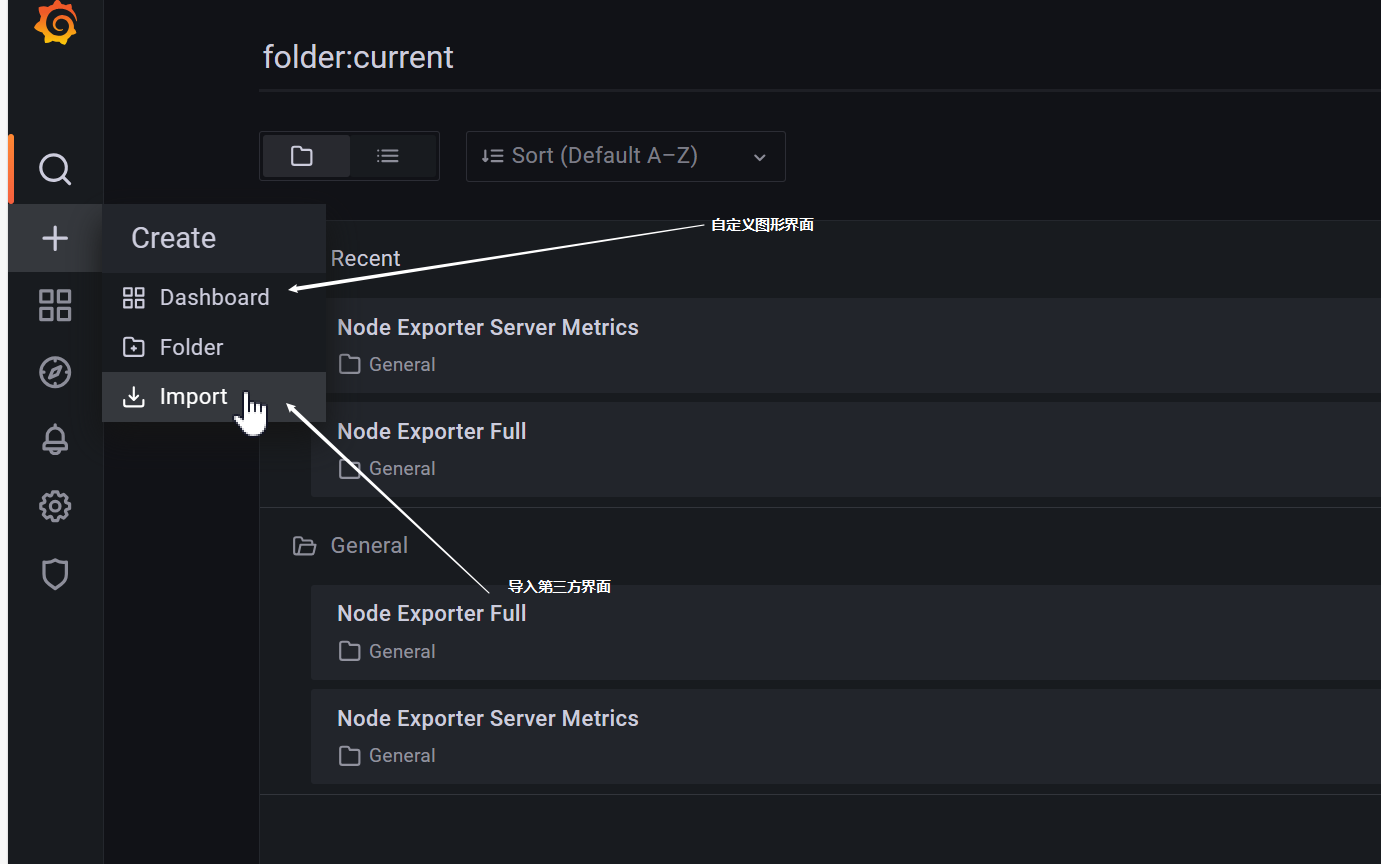
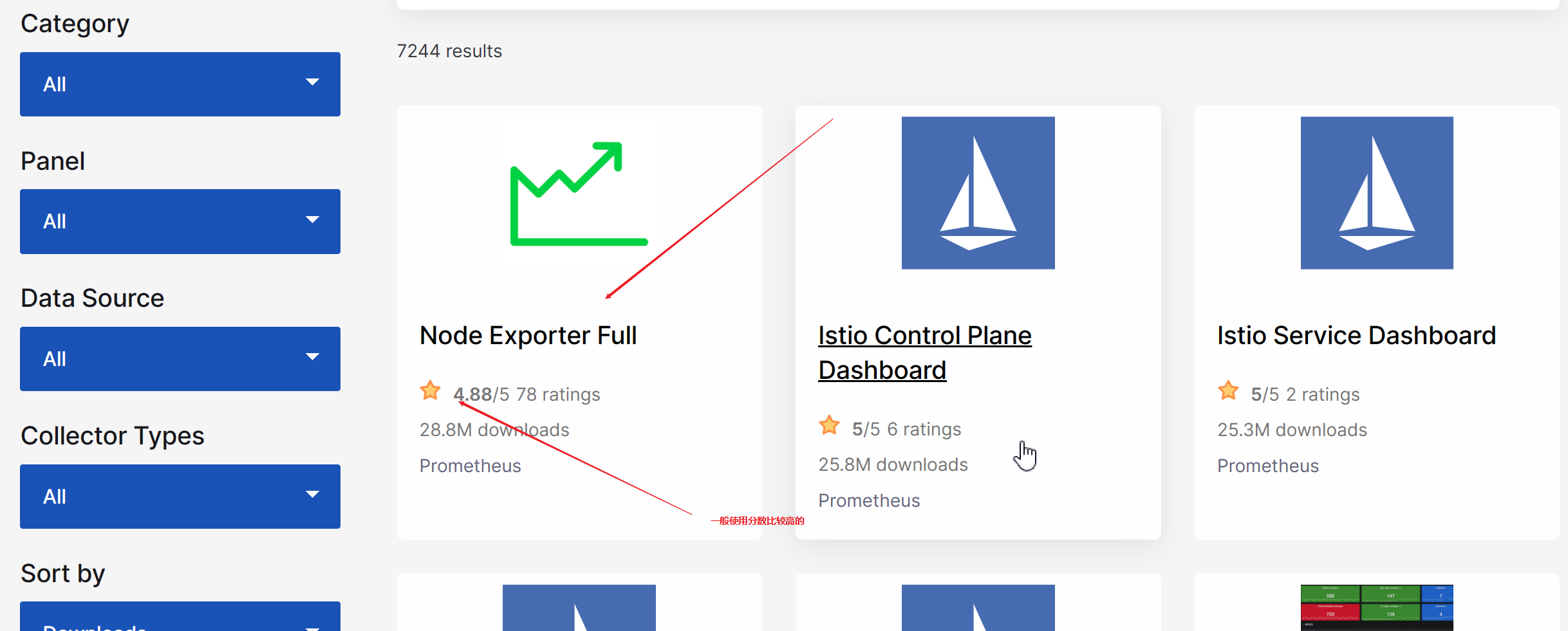
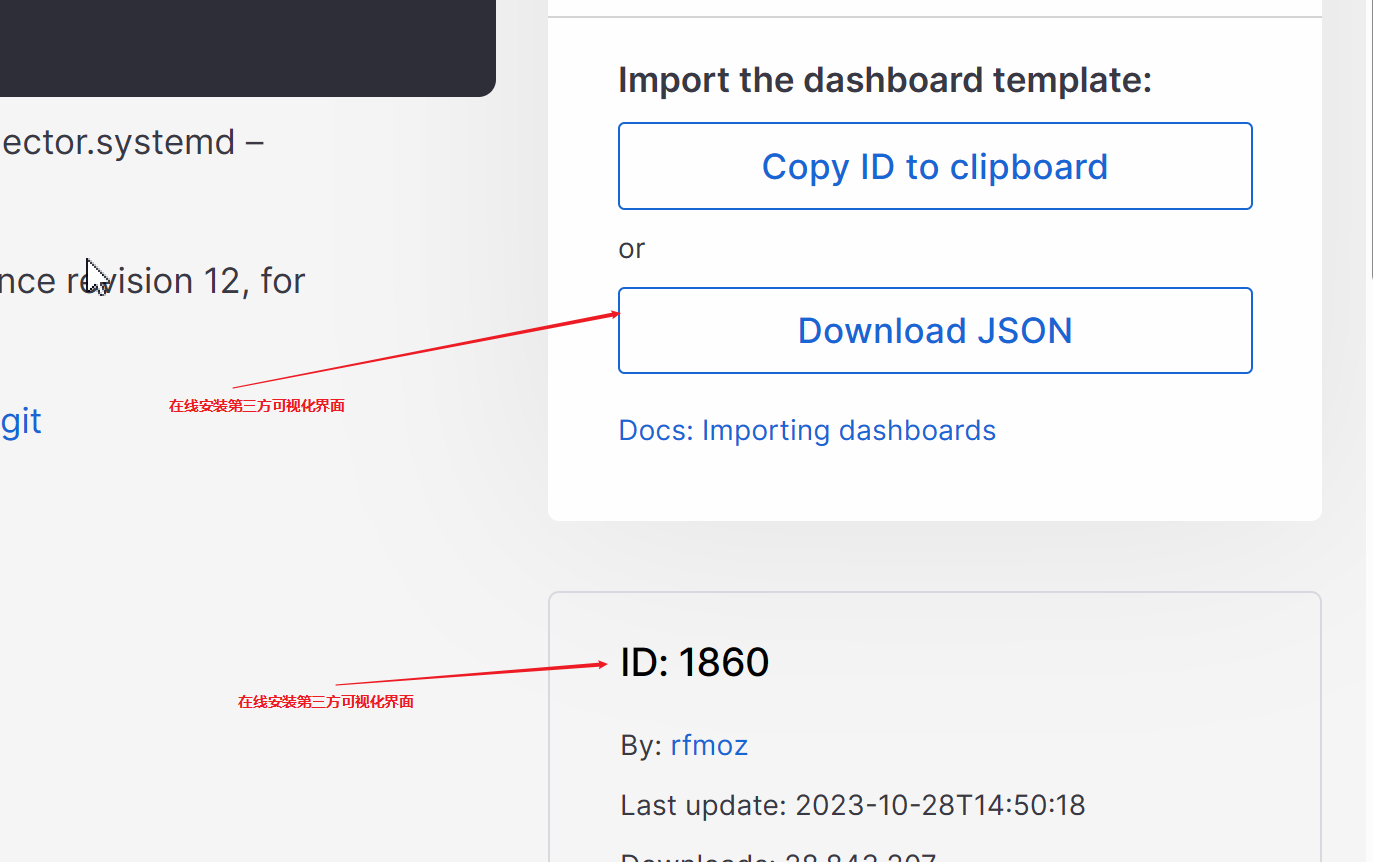
- 查找使用第三方模板
分为用户自定义和模板
十、node_exporte配置(附录)
- 基本信息配置
--web.listen-address=":9100"
#node_exporter监听的端口,默认是9100,若需要修改则通过此参数。
--web.telemetry-path="/metrics"
#获取metric信息的url,默认是/metrics,若需要修改则通过此参数
--log.level="info"
#设置日志级别
--log.format="logger:stderr"
#设置打印日志的格式,若有自动化日志提取工具可以使用这个参数规范日志打印的格式
-----------------------------------------------------------------------------------------
--collector.diskstats.ignored-devices="^(ram|loop|fd|(h|s|v|xv)d[az]|nvme\\d+n\\d+p)\\d+$"
#通过正则表达式忽略某些磁盘的信息收集
--collector.filesystem.ignored-mount-points="^/(dev|proc|sys|var/lib/docker/.+)
($|/)"
#通过正则表达式忽略某些文件系统挂载点的信息收集
--collector.filesystem.ignored-fs-types="^(autofs|binfmt_misc|bpf|cgroup2?
|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|mqueue|nsfs|overlay|proc|proc
fs|pstore|rpc_pipefs|securityfs|selinuxfs|squashfs|sysfs|tracefs)$"
#通过正则表达式忽略某些文件系统类型的信息收集
--collector.netclass.ignored-devices="^$"
#通过正则表达式忽略某些网络类的信息收集
--collector.netdev.ignored-devices="^$"
#通过正则表达式忽略某些网络设备的信息收集
--collector.netstat.fields="^$"
#通过正则表达式配置需要获取的网络状态信息
--collector.vmstat.fields="^(oom_kill|pgpg|pswp|pg.*fault).*"
#通过正则表达式配置vmstat返回信息中需要收集的选项
Prometheus 快速入门的更多相关文章
- Prometheus 入门教程(一):Prometheus 快速入门
文章首发于[陈树义]公众号,点击跳转到原文:https://mp.weixin.qq.com/s/ZXlBPHGcWeYh2hjBzacc3A Prometheus 是任何一个高级工程师必须要掌握的技 ...
- Prometheus快速入门
Prometheus是一个开源的,基于metrics(度量)的一个开源监控系统,它有一个简单而强大的数据模型和查询语言,让我们分析应用程序.Prometheus诞生于2012年主要是使用go语言编写的 ...
- Docker三十分钟快速入门(下)
一.背景 上篇文章我们进行了Docker的快速入门,基本命令的讲解,以及简单的实战,那么本篇我们就来实战一个真实的项目,看看怎么在产线上来通过容器技术来运行我们的项目,来达到学会容器间通信以及dock ...
- 私有仓库GitLab快速入门篇
私有仓库GitLab快速入门篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 安装文档请参考官网:https://about.gitlab.com/installation/#ce ...
- Kubernetes快速入门
二.Kubernetes快速入门 (1)Kubernetes集群的部署方法及部署要点 (2)部署Kubernetes分布式集群 (3)kubectl使用基础 1.简介 kubectl就是API ser ...
- gorm概述与快速入门
特性 全功能 ORM 关联 (Has One,Has Many,Belongs To,Many To Many,多态,单表继承) Create,Save,Update,Delete,Find 中钩子方 ...
- Web Api 入门实战 (快速入门+工具使用+不依赖IIS)
平台之大势何人能挡? 带着你的Net飞奔吧!:http://www.cnblogs.com/dunitian/p/4822808.html 屁话我也就不多说了,什么简介的也省了,直接简单概括+demo ...
- SignalR快速入门 ~ 仿QQ即时聊天,消息推送,单聊,群聊,多群公聊(基础=》提升)
SignalR快速入门 ~ 仿QQ即时聊天,消息推送,单聊,群聊,多群公聊(基础=>提升,5个Demo贯彻全篇,感兴趣的玩才是真的学) 官方demo:http://www.asp.net/si ...
- 前端开发小白必学技能—非关系数据库又像关系数据库的MongoDB快速入门命令(2)
今天给大家道个歉,没有及时更新MongoDB快速入门的下篇,最近有点小忙,在此向博友们致歉.下面我将简单地说一下mongdb的一些基本命令以及我们日常开发过程中的一些问题.mongodb可以为我们提供 ...
- 【第三篇】ASP.NET MVC快速入门之安全策略(MVC5+EF6)
目录 [第一篇]ASP.NET MVC快速入门之数据库操作(MVC5+EF6) [第二篇]ASP.NET MVC快速入门之数据注解(MVC5+EF6) [第三篇]ASP.NET MVC快速入门之安全策 ...
随机推荐
- MySQL5.7版本单节点大数据量迁移到PXC8.0版本集群全记录-2
本文主要记录57版本升级80版本的过程,供参考. ■ 57版本升级80版本注意事项 默认字符集由latin1变为utf8mb4 MyISAM系统表全部换成InnoDB表 sql_mode参数默认值变化 ...
- 【Postman】以命令行形式执行Postman脚本(使用newman)
以命令行形式执行Postman脚本(使用Newman) 目录 以命令行形式执行Postman脚本(使用Newman) 一.背景 二.Newman的安装 1.Node.js 2.Newman 三.脚本准 ...
- DPDK-22.11.2 [四] Virtio_user as Exception Path
因为dpdk是把网卡操作全部拿到用户层,与原生系统驱动不再兼容,所以被dpdk接管的网卡从系统层面(ip a/ifconfig)无法看到,同样数据也不再经过系统内核. 如果想把数据再发送到系统,就要用 ...
- 聊聊Maven的依赖传递、依赖管理、依赖作用域
1. 依赖传递 在Maven中,依赖是会传递的,假如在业务项目中引入了spring-boot-starter-web依赖: <dependency> <groupId>org. ...
- Nuxt.js 生成sitemap站点地图文件
Nuxt.js 生成sitemap站点地图文件 背景介绍 使用nuxt框架生成静态文件支持SEO优化,打包之后需要生成一个 sitemap.xml 文件方便提交搜索引擎进行收录.官网有提供一个插件 ...
- log4j漏洞CVE-2021-44228复现-排雷篇
一.环境搭建(用相同的环境才能保证一定成功) 下载vulhub,其他环境可能存在GET请求无效问题: git clone https://github.com/vulhub/vulhub.git 切换 ...
- ELK-日志收集-Kibana WEB安全认证
1.ELK收集MYSQL日志实战: 日志收集存放目录位置: /usr/local/logstash/config/etc/ 1)日志采集-存入redis缓存数据库:mysql-redis.conf ...
- docker 安装、升级、修改数据目录
1.查看系统要求 Docker 要求 CentOS 系统的内核版本高于 3.10 ,查看CentOS的内核版本. uname -a 2.删除旧版本 yum remove docker docker-c ...
- java——1.变量和数据类型
变量和数据类型 字符.字节.位之间的关系 1.字符:人类可以阅读的文本内容最小单位 字符编码:utf-8,gbk 2.字节:1字符=2字节:1字符=4字节 3.位:1字节=8位 位指的是二进制位, ...
- [Python]常用知识
Python 常用知识 编译型语言 和 解释性语言 解释性语言 编译型语言 概念 计算机不能直接的理解高级语言,只能直接理解机器语言,所以必须要把高级语言翻译成机器语言,计算机才能执行高级语言的编写的 ...